Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/McCloudS/subgen
Autogenerate subtitles using OpenAI Whisper Model via Jellyfin, Plex, Emby, Tautulli, or Bazarr
https://github.com/McCloudS/subgen
Last synced: 19 days ago
JSON representation
Autogenerate subtitles using OpenAI Whisper Model via Jellyfin, Plex, Emby, Tautulli, or Bazarr
- Host: GitHub
- URL: https://github.com/McCloudS/subgen
- Owner: McCloudS
- License: mit
- Created: 2023-01-28T17:36:37.000Z (over 1 year ago)
- Default Branch: main
- Last Pushed: 2024-06-03T21:06:27.000Z (19 days ago)
- Last Synced: 2024-06-03T23:07:04.868Z (19 days ago)
- Language: Python
- Homepage:
- Size: 998 KB
- Stars: 413
- Watchers: 6
- Forks: 42
- Open Issues: 1
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Lists
- awesome-jellyfin - subgen - Autogenerate subtitles using OpenAI Whisper Model via Jellyfin. (👾 Other)
- awesome-stars - McCloudS/subgen - Autogenerate subtitles using OpenAI Whisper Model via Jellyfin, Plex, Emby, Tautulli, or Bazarr (Python)
README
[](https://www.paypal.com/donate/?hosted_button_id=SU4QQP6LH5PF6)

Updates:
21 Apr 2024: Fixed queuing with thanks to https://github.com/xhzhu0628 @ https://github.com/McCloudS/subgen/pull/85. Bazarr intentionally doesn't follow `CONCURRENT_TRANSCRIPTIONS` because it needs a time sensitive response.
31 Mar 2024: Removed `/subsync` endpoint and general refactoring. Open an issue if you were using it!
24 Mar 2024: Added a 'webui' to configure environment variables. You can use this instead of manually editing the script or using Environment Variables in your OS or Docker (if you want). The config will prioritize OS Env Variables, then the .env file, then the defaults. You can access it at `http://subgen:9000/`
23 Mar 2024: Added `CUSTOM_REGROUP` to try to 'clean up' subtitles a bit.
22 Mar 2024: Added LRC capability via see: `'LRC_FOR_AUDIO_FILES' | True | Will generate LRC (instead of SRT) files for filetypes: '.mp3', '.flac', '.wav', '.alac', '.ape', '.ogg', '.wma', '.m4a', '.m4b', '.aac', '.aiff' |`
21 Mar 2024: Added a 'wizard' into the launcher that will help standalone users get common Bazarr variables configured. See below in Launcher section. Removed 'Transformers' as an option. While I usually don't like to remove features, I don't think anyone is using this and the results are wildly unpredictable and often cause out of memory errors. Added two new environment variables called `USE_MODEL_PROMPT` and `CUSTOM_MODEL_PROMPT`. If `USE_MODEL_PROMPT` is `True` it will use `CUSTOM_MODEL_PROMPT` if set, otherwise will default to using the pre-configured language pairings, such as: `"en": "Hello, welcome to my lecture.",
"zh": "你好,欢迎来到我的讲座。"` These pre-configurated translations are geared towards fixing some audio that may not have punctionation. We can prompt it to try to force the use of punctuation during transcription.
19 Mar 2024: Added a `MONITOR` environment variable. Will 'watch' or 'monitor' your `TRANSCRIBE_FOLDERS` for changes and run on them. Useful if you just want to paste files into a folder and get subtitles.
6 Mar 2024: Added a `/subsync` endpoint that can attempt to align/synchronize subtitles to a file. Takes audio_file, subtitle_file, language (2 letter code), and outputs an srt.
5 Mar 2024: Cleaned up logging. Added timestamps option (if Debug = True, timestamps will print in logs).
4 Mar 2024: Updated Dockerfile CUDA to 12.2.2 (From CTranslate2). Added endpoint `/status` to return Subgen version. Can also use distil models now! See variables below!
29 Feb 2024: Changed sefault port to align with whisper-asr and deconflict other consumers of the previous port.
11 Feb 2024: Added a 'launcher.py' file for Docker to prevent huge image downloads. Now set UPDATE to True if you want pull the latest version, otherwise it will default to what was in the image on build. Docker builds will still be auto-built on any commit. If you don't want to use the auto-update function, no action is needed on your part and continue to update docker images as before. Fixed bug where detect-langauge could return an empty result. Reduced useless debug output that was spamming logs and defaulted DEBUG to True. Added APPEND, which will add f"Transcribed by whisperAI with faster-whisper ({whisper_model}) on {datetime.now()}" at the end of a subtitle.
10 Feb 2024: Added some features from JaiZed's branch such as skipping if SDH subtitles are detected, functions updated to also be able to transcribe audio files, allow individual files to be manually transcribed, and a better implementation of forceLanguage. Added `/batch` endpoint (Thanks JaiZed). Allows you to navigate in a browser to http://subgen_ip:9000/docs and call the batch endpoint which can take a file or a folder to manually transcribe files. Added CLEAR_VRAM_ON_COMPLETE, HF_TRANSFORMERS, HF_BATCH_SIZE. Hugging Face Transformers boast '9x increase', but my limited testing shows it's comparable to faster-whisper or slightly slower. I also have an older 8gb GPU. Simplest way to persist HF Transformer models is to set "HF_HUB_CACHE" and set it to "/subgen/models" for Docker (assuming you have the matching volume).
8 Feb 2024: Added FORCE_DETECTED_LANGUAGE_TO to force a wrongly detected language. Fixed asr to actually use the language passed to it.
5 Feb 2024: General housekeeping, minor tweaks on the TRANSCRIBE_FOLDERS function.
28 Jan 2024: Fixed issue with ffmpeg python module not importing correctly. Removed separate GPU/CPU containers. Also removed the script from installing packages, which should help with odd updates I can't control (from other packages/modules). The image is a couple gigabytes larger, but allows easier maintenance.
19 Dec 2023: Added the ability for Plex and Jellyfin to automatically update metadata so the subtitles shows up properly on playback. (See https://github.com/McCloudS/subgen/pull/33 from Rikiar73574)
31 Oct 2023: Added Bazarr support via Whipser provider.
25 Oct 2023: Added Emby (IE http://192.168.1.111:9000/emby) support and TRANSCRIBE_FOLDERS, which will recurse through the provided folders and generate subtitles. It's geared towards attempting to transcribe existing media without using a webhook.
23 Oct 2023: There are now two docker images, ones for CPU (it's smaller): mccloud/subgen:latest, mccloud/subgen:cpu, the other is for cuda/GPU: mccloud/subgen:cuda. I also added Jellyfin support and considerable cleanup in the script. I also renamed the webhooks, so they will require new configuration/updates on your end. Instead of /webhook they are now /plex, /tautulli, and /jellyfin.
22 Oct 2023: The script should have backwards compability with previous envirionment settings, but just to be sure, look at the new options below. If you don't want to manually edit your environment variables, just edit the script manually. While I have added GPU support, I haven't tested it yet.
19 Oct 2023: And we're back! Uses faster-whisper and stable-ts. Shouldn't break anything from previous settings, but adds a couple new options that aren't documented at this point in time. As of now, this is not a docker image on dockerhub. The potential intent is to move this eventually to a pure python script, primarily to simplify my efforts. Quick and dirty to meet dependencies: pip or `pip3 install flask requests stable-ts faster-whisper`
This potentially has the ability to use CUDA/Nvidia GPU's, but I don't have one set up yet. Tesla T4 is in the mail!
2 Feb 2023: Added Tautulli webhooks back in. Didn't realize Plex webhooks was PlexPass only. See below for instructions to add it back in.
31 Jan 2023 : Rewrote the script substantially to remove Tautulli and fix some variable handling. For some reason my implementation requires the container to be in host mode. My Plex was giving "401 Unauthorized" when attempt to query from docker subnets during API calls. (**Fixed now, it can be in bridge**)
# What is this?
This will transcribe your personal media on a Plex, Emby, or Jellyfin server to create subtitles (.srt) from audio/video files with the following languages: https://github.com/McCloudS/subgen#audio-languages-supported-via-openai and transcribe or translate them into english. It can also be used as a Whisper provider in Bazarr (See below instructions). It technically has support to transcribe from a foreign langauge to itself (IE Japanese > Japanese, see [TRANSCRIBE_OR_TRANSLATE](https://github.com/McCloudS/subgen#variables)). It is currently reliant on webhooks from Jellyfin, Emby, Plex, or Tautulli. This uses stable-ts and faster-whisper which can use both Nvidia GPUs and CPUs.
# Why?
Honestly, I built this for me, but saw the utility in other people maybe using it. This works well for my use case. Since having children, I'm either deaf or wanting to have everything quiet. We watch EVERYTHING with subtitles now, and I feel like I can't even understand the show without them. I use Bazarr to auto-download, and gap fill with Plex's built-in capability. This is for everything else. Some shows just won't have subtitles available for some reason or another, or in some cases on my H265 media, they are wildly out of sync.
# What can it do?
* Create .srt subtitles when a media file is added or played which triggers off of Jellyfin, Plex, or Tautulli webhooks. It can also be called via the Whisper provider inside Bazarr.
# How do I set it up?
## Install/Setup
You can now configure all environment variables via `http://subgen:9000/` (fill in your appropriate IP and port). You can still use Docker variables or OS Env Variables if you prefer. A small snapshot of it below:

### Standalone/Without Docker
Install python3 and ffmpeg ~~and run `pip3 install numpy stable-ts fastapi requests faster-whisper uvicorn python-multipart python-ffmpeg whisper transformers optimum accelerate watchdog`~~. Then run it: `python3 launcher.py -u -i -s`. You need to have matching paths relative to your Plex server/folders, or use USE_PATH_MAPPING. Paths are not needed if you are only using Bazarr. You will need the appropriate NVIDIA drivers installed (12.2.0): https://developer.nvidia.com/cuda-12-2-0-download-archive?target_os=Windows&target_arch=x86_64
#### Using Launcher
launcher.py can launch subgen for you and automate the setup and can take the following options:

Using `-s` for Bazarr setup:

### Docker
The dockerfile is in the repo along with an example docker-compose file, and is also posted on dockerhub (mccloud/subgen).
If using Subgen without Bazarr, you MUST mount your media volumes in subgen the same way Plex (or your media server) sees them. For example, if Plex uses "/Share/media/TV:/tv" you must have that identical volume in subgen.
`"${APPDATA}/subgen/models:/subgen/models"` is just for storage of the language models. This isn't necessary, but you will have to redownload the models on any new image pulls if you don't use it.
`"${APPDATA}/subgen/subgen.py:/subgen/subgen.py"` If you want to control the version of subgen.py by yourself. Launcher.py can still be used to download a newer version.
If you want to use a GPU, you need to map it accordingly.
## Plex
Create a webhook in Plex that will call back to your subgen address, IE: http://192.168.1.111:9000/plex see: https://support.plex.tv/articles/115002267687-webhooks/ You will also need to generate the token to use it.
## Emby
All you need to do is create a webhook in Emby pointing to your subgen IE: http://192.168.154:9000/emby
Emby was really nice and provides good information in their responses, so we don't need to add an API token or server url to query for more information.
## Bazarr
You only need to confiure the Whisper Provider as shown below:
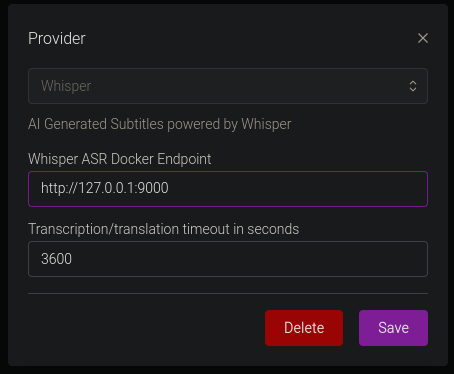
The Docker Endpoint is the ip address and port of your subgen container (IE http://192.168.1.111:9000) See https://wiki.bazarr.media/Additional-Configuration/Whisper-Provider/ for more info. I recomend not enabling this with other webhooks, or you will likely be generating duplicate subtitles. If you are using Bazarr, path mapping isn't necessary, as Bazarr sends the file over http.
## Tautulli
Create the webhooks in Tautulli with the following settings:
Webhook URL: http://yourdockerip:9000/tautulli
Webhook Method: Post
Triggers: Whatever you want, but you'll likely want "Playback Start" and "Recently Added"
Data: Under Playback Start, JSON Header will be:
```json
{ "source":"Tautulli" }
```
Data:
```json
{
"event":"played",
"file":"{file}",
"filename":"{filename}",
"mediatype":"{media_type}"
}
```
Similarly, under Recently Added, Header is:
```json
{ "source":"Tautulli" }
```
Data:
```json
{
"event":"added",
"file":"{file}",
"filename":"{filename}",
"mediatype":"{media_type}"
}
```
## Jellyfin
First, you need to install the Jellyfin webhooks plugin. Then you need to click "Add Generic Destination", name it anything you want, webhook url is your subgen info (IE http://192.168.1.154:9000/jellyfin). Next, check Item Added, Playback Start, and Send All Properties. Last, "Add Request Header" and add the Key: `Content-Type` Value: `application/json`
Click Save and you should be all set!
## Variables
You can define the port via environment variables, but the endpoints are static.
The following environment variables are available in Docker. They will default to the values listed below.
| Variable | Default Value | Description |
|---------------------------|------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| TRANSCRIBE_DEVICE | 'cpu' | Can transcribe via gpu (Cuda only) or cpu. Takes option of "cpu", "gpu", "cuda". |
| WHISPER_MODEL | 'medium' | Can be:'tiny', 'tiny.en', 'base', 'base.en', 'small', 'small.en', 'medium', 'medium.en', 'large-v1','large-v2', 'large-v3', 'large', 'distil-large-v2', 'distil-large-v3', 'distil-medium.en', 'distil-small.en' |
| CONCURRENT_TRANSCRIPTIONS | 2 | Number of files it will transcribe in parallel |
| WHISPER_THREADS | 4 | number of threads to use during computation |
| MODEL_PATH | './models' | This is where the WHISPER_MODEL will be stored. This defaults to placing it where you execute the script in the folder 'models' |
| PROCADDEDMEDIA | True | will gen subtitles for all media added regardless of existing external/embedded subtitles (based off of SKIPIFINTERNALSUBLANG) |
| PROCMEDIAONPLAY | True | will gen subtitles for all played media regardless of existing external/embedded subtitles (based off of SKIPIFINTERNALSUBLANG) |
| NAMESUBLANG | 'aa' | allows you to pick what it will name the subtitle. Instead of using EN, I'm using AA, so it doesn't mix with exiting external EN subs, and AA will populate higher on the list in Plex. |
| SKIPIFINTERNALSUBLANG | 'eng' | Will not generate a subtitle if the file has an internal sub matching the 3 letter code of this variable (See https://en.wikipedia.org/wiki/List_of_ISO_639-1_codes) |
| WORD_LEVEL_HIGHLIGHT | False | Highlights each words as it's spoken in the subtitle. See example video @ https://github.com/jianfch/stable-ts |
| PLEXSERVER | 'http://plex:32400' | This needs to be set to your local plex server address/port |
| PLEXTOKEN | 'token here' | This needs to be set to your plex token found by https://support.plex.tv/articles/204059436-finding-an-authentication-token-x-plex-token/ |
| JELLYFINSERVER | 'http://jellyfin:8096' | Set to your Jellyfin server address/port |
| JELLYFINTOKEN | 'token here' | Generate a token inside the Jellyfin interface |
| WEBHOOKPORT | 9000 | Change this if you need a different port for your webhook |
| USE_PATH_MAPPING | False | Similar to sonarr and radarr path mapping, this will attempt to replace paths on file systems that don't have identical paths. Currently only support for one path replacement. Examples below. |
| PATH_MAPPING_FROM | '/tv' | This is the path of my media relative to my Plex server |
| PATH_MAPPING_TO | '/Volumes/TV' | This is the path of that same folder relative to my Mac Mini that will run the script |
| TRANSCRIBE_FOLDERS | '' | Takes a pipe '\|' separated list (For example: /tv\|/movies\|/familyvideos) and iterates through and adds those files to be queued for subtitle generation if they don't have internal subtitles |
| TRANSCRIBE_OR_TRANSLATE | 'transcribe' | Takes either 'transcribe' or 'translate'. Transcribe will transcribe the audio in the same language as the input. Translate will transcribe and translate into English. |
| COMPUTE_TYPE | 'auto' | Set compute-type using the following information: https://github.com/OpenNMT/CTranslate2/blob/master/docs/quantization.md |
| DEBUG | True | Provides some debug data that can be helpful to troubleshoot path mapping and other issues. Fun fact, if this is set to true, any modifications to the script will auto-reload it (if it isn't actively transcoding). Useful to make small tweaks without re-downloading the whole file. |
| FORCE_DETECTED_LANGUAGE_TO | '' | This is to force the model to a language instead of the detected one, takes a 2 letter language code. For example, your audio is French but keeps detecting as English, you would set it to 'fr' |
| CLEAR_VRAM_ON_COMPLETE | True | This will delete the model and do garbage collection when queue is empty. Good if you need to use the VRAM for something else. |
| UPDATE | False | Will pull latest subgen.py from the repository if True. False will use the original subgen.py built into the Docker image. Standalone users can use this with launcher.py to get updates. |
| APPEND | False | Will add the following at the end of a subtitle: "Transcribed by whisperAI with faster-whisper ({whisper_model}) on {datetime.now()}"
| MONITOR | False | Will monitor `TRANSCRIBE_FOLDERS` for real-time changes to see if we need to generate subtitles |
| USE_MODEL_PROMPT | False | When set to `True`, will use the default prompt stored in greetings_translations "Hello, welcome to my lecture." to try and force the use of punctuation in transcriptions that don't. Automatic `CUSTOM_MODEL_PROMPT` will only work with ASR, but can still be set manually like so: `USE_MODEL_PROMPT=True and CUSTOM_MODEL_PROMPT=Hello, welcome to my lecture.` |
| CUSTOM_MODEL_PROMPT | '' | If `USE_MODEL_PROMPT` is `True`, you can override the default prompt (See: https://medium.com/axinc-ai/prompt-engineering-in-whisper-6bb18003562d for great examples). |
| LRC_FOR_AUDIO_FILES | True | Will generate LRC (instead of SRT) files for filetypes: '.mp3', '.flac', '.wav', '.alac', '.ape', '.ogg', '.wma', '.m4a', '.m4b', '.aac', '.aiff' |
| CUSTOM_REGROUP | 'cm_sl=84_sl=42++++++1' | Attempts to regroup some of the segments to make a cleaner looking subtitle. See https://github.com/McCloudS/subgen/issues/68 for discussion. Set to blank if you want to use Stable-TS default regroups algorithm of `cm_sp=,* /,_sg=.5_mg=.3+3_sp=.* /。/?/?` |
| DETECT_LANGUAGE_LENGTH | 30 | Detect language on the first x seconds of the audio. |
### Images:
`mccloud/subgen:latest` is GPU or CPU
`mccloud/subgen:cpu` is for CPU only (slightly smaller image)
# What are the limitations/problems?
* I made it and know nothing about formal deployment for python coding.
* It's using trained AI models to transcribe, so it WILL mess up
# What's next?
Fix documentation and make it prettier!
# Audio Languages Supported (via OpenAI)
Afrikaans, Arabic, Armenian, Azerbaijani, Belarusian, Bosnian, Bulgarian, Catalan, Chinese, Croatian, Czech, Danish, Dutch, English, Estonian, Finnish, French, Galician, German, Greek, Hebrew, Hindi, Hungarian, Icelandic, Indonesian, Italian, Japanese, Kannada, Kazakh, Korean, Latvian, Lithuanian, Macedonian, Malay, Marathi, Maori, Nepali, Norwegian, Persian, Polish, Portuguese, Romanian, Russian, Serbian, Slovak, Slovenian, Spanish, Swahili, Swedish, Tagalog, Tamil, Thai, Turkish, Ukrainian, Urdu, Vietnamese, and Welsh.
# Additional reading:
* https://github.com/openai/whisper (Original OpenAI project)
* https://en.wikipedia.org/wiki/List_of_ISO_639-1_codes (2 letter subtitle codes)
# Credits:
* Whisper.cpp (https://github.com/ggerganov/whisper.cpp) for original implementation
* Google
* ffmpeg
* https://github.com/jianfch/stable-ts
* https://github.com/guillaumekln/faster-whisper
* Whipser ASR Webservice (https://github.com/ahmetoner/whisper-asr-webservice) for how to implement Bazarr webhooks.