Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/networkop/cue-networking
Example of using CUE to model baremetal network configurations
https://github.com/networkop/cue-networking
cuelang networking
Last synced: 18 days ago
JSON representation
Example of using CUE to model baremetal network configurations
- Host: GitHub
- URL: https://github.com/networkop/cue-networking
- Owner: networkop
- Created: 2021-12-27T20:28:32.000Z (over 2 years ago)
- Default Branch: main
- Last Pushed: 2021-12-30T15:03:59.000Z (over 2 years ago)
- Last Synced: 2024-03-20T18:04:35.765Z (3 months ago)
- Topics: cuelang, networking
- Language: CUE
- Homepage:
- Size: 18.6 KB
- Stars: 46
- Watchers: 3
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Lists
- awesome-stars - networkop/cue-networking - Example of using CUE to model baremetal network configurations (networking)
- awesome-cue - CUE for Network Configurations - Example of using CUE to model baremetal network configurations. (Resources)
README
# CUE For Network Configurations
In network automation, a typical device configuration is represented as a structured document. This could be YAML that is fed into a Jinja template to produce a flat (text) device config or it could be JSON that follows the device's YANG/OpenAPI model. In either case, this structured data needs to be generated by humans either manually or through code, both of which can be complex and error-prone processes.
In this repo, you'll see how to use [CUE](https://cuelang.org/) to solve the following network data configuration problems:
* Validate data models based on statically-typed schemas.
* Reduce configuration boilerplate (we'll shrink the total number of lines by 60%).
* Separate values from data models and simplify input data structs.
* Enforce policies and design decisions via value constrains.

## Sample Input
The original configs are taken from the NVIDIA Networking [EVPN Multihoming guide](
https://docs.nvidia.com/networking-ethernet-software/cumulus-linux-50/Network-Virtualization/Ethernet-Virtual-Private-Network-EVPN/EVPN-Multihoming/#evpn-mh-with-head-end-replication). They are designed to configure MH EVPN in the following topology:
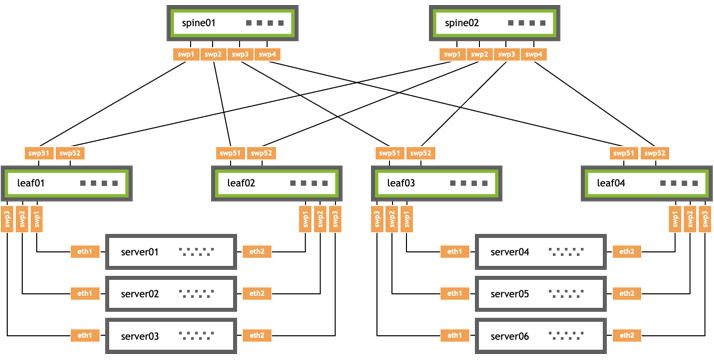
Only two changes were made to the configs taken from the above guide:
* Hostname definition was added to each config.
* The initial `-` symbol was removed to convert data from list to YAML object/struct.
## Prerequisites
1. This guide assumes basic knowledge of CUE.
* For a quick introduction into the language, see the [official documentation](https://cuelang.org/docs/tutorials/).
* For additional tutorials and documentation see [cuetorials.com](https://cuetorials.com/).
2. CUE tool must be installed:
```
go install cuelang.org/go/cmd/cue@latest
```
3. [Dyff](https://github.com/homeport/dyff) needs to be installed (used to compare the generated and the original YAML files):
```
go install github.com/homeport/dyff/cmd/dyff@latest
```
## Walkthrought
### Environment Setup
From the current repository, reinitialize CUE and Go modules
```
rm -rf cue.mod/
rm -rf go.*
cue mod init github.com/networkop/cue-networking
go mod init github.com/networkop/cue-networking
```
Create a new directory layout to store all CUE files. This is a hierarchical layout to allow for configuration schema to be shared in top-level directories and device-specific configs to go into leaf directories. Read [this section](https://cuelang.org/docs/concepts/packages/#file-organization) for more explanation.
```
for d in leaf1 leaf2 leaf3 leaf4 spine1 spine2; do
mkdir -p tmp/$d
done
cd tmp
```
Now, as the first step, we'll import one of the device's configs and start creating a schema for it. The following command will ingest the original config in YAML format and produce the corresponding CUE structs with all values fully populated:
```
cue import ../originals/spine1.yml -o spine1/input.cue -p nvue -f -l '"config"' -l 'set.system.hostname'
```
This is how the result of `head spine1/input.cue` would look like:
```
package nvue
config: spine1: set: {
system: hostname: "spine1"
interface: {
lo: {
ip: address: "10.10.10.101/32": {}
type: "loopback"
}
swp1: type: "swp"
```
We can use the `cue eval spine1/input.cue` command to evaluate and use `--out` flag to produce the resulting YAML or JSON document. The following command will compare the YAML file generated from CUE with the original YAML file:
```
cue eval spine1/input.cue --out json | jq .config.spine1 | dyff between -b ../originals/spine1.yml -
```
### Building A Schema
If we compare configurations of both spine switches, we would see that only a few fields are different. Let's create a separate struct to store those variable parameters and put it at the top of the directory hierarchy. The following schema defines constraints on the values we expect to see and provides a concrete values for `PeerGroup` and `BridgeDomain` which hard-codes it for all device configs.
```
cat < top.cue
package nvue
import (
"net"
)
_Input: {
Hostname: string
ASN: <=65535 & >=64512
RouterID: net.IPv4 & string
LoopbackIP: "\(RouterID)/32"
EnableIntfs: [...string]
BGPIntfs: [...string]
VRFs: [...{name: string }]
PeerGroup: "underlay"
BridgeDomain: "br_default"
}
EOF
```
CUE will not output values for fields that start with an underscore and we're using this to define schema structs that can be used to provide values but will not be visible in the final configuration. To help simplify data access in the future, we group all device configs in a `config` map with device names (strings) as its keys.
```
cat <> top.cue
config: [string]: set: {}
_input: _Input
EOF
```
Now let's populate the input values for `spine1` and add the device-specific config to the global `config` struct. As we've seen in the previous config snippet, `_input` is a subtype of `_Input` so all the constraints and type definitions we've defined before will apply automatically.
> Note that in this step we're also removing all of the previously imported CUE definitions for `spine1`.
```
cat < spine1/input.cue
_input: {
Hostname: "spine1"
RouterID: "10.10.10.101"
EnableIntfs: ["swp1", "swp2", "swp3", "swp4"]
BGPIntfs: EnableIntfs
VRFs: [{name: "default"}]
ASN: 65199
}
config: "\(_input.Hostname)": set: _nvue
EOF
```
It's time to start defining how the `_nvue` struct would look like. We'll put its definition in the top-level CUE file `top.cue`, so that all devices inherit the same schema. The easiest way to define the `_nvue` model is to mimic the original device configuration data model. Where necessary, we are taking concrete values from the `_input` struct and plugging them into the main model.
```
cat <> top.cue
_nvue: {
system: _system
interface: _interfaces
router: bgp: {
_global_bgp
}
vrf: _vrf
}
_system: hostname: _input.Hostname
_global_bgp: {
"autonomous-system": _input.ASN
enable: "on"
"router-id": _input.RouterID
}
_interfaces: {
lo: {
ip: address: "\(_input.LoopbackIP)": {}
type: "loopback"
}
for intf in _input.EnableIntfs {"\(intf)": type: "swp"}
}
_vrf: {
for vrf in _input.VRFs {
"\(vrf.name)": {
router: bgp: _vrf_bgp
router: bgp: neighbor: _neighbor
router: bgp: "peer-group": _peer_group
}
}
}
_vrf_bgp: {
"address-family": {
"ipv4-unicast": {
enable: "on"
redistribute: connected: enable: "on"
}
"l2vpn-evpn": enable: "on"
}
enable: "on"
}
_neighbor: {
for intf in _input.BGPIntfs {
"\(intf)": {
"peer-group": "\(_input.PeerGroup)"
type: string | *"unnumbered"
}
}
}
_peer_group: "\(_input.PeerGroup)": {
"address-family": "l2vpn-evpn": enable: "on"
"remote-as": string | *"external"
}
EOF
```
With the above schema and concrete values defined for `spine1`, we can re-run the `dyff` command to confirm that we're still generating the same exact YAML document:
```
cue eval top.cue spine1/input.cue --out json | jq .config.spine1 | dyff between -b ../originals/spine1.yml -
```
### Adding Another Device
Right now we are roughly at the same (or even higher) total number of lines as the original YAML. However, we already have the benefit of having our input values validated against a schema. From here on, adding another device with a similar schema becomes really easy. We just make a copy of `spine2`'s `input.cue` and adjust some of the input values:
```
cp spine1/input.cue spine2
sed -i 's/spine1/spine2/' spine2/input.cue
sed -i 's/101/102/' spine2/input.cue
```
Re-running the `dyff` command against spine2 should show no differences! We've just eliminated roughly 40 lines of config with just a few commands.
```
cue eval top.cue spine2/input.cue --out json | jq .config.spine2 | dyff between -b ../originals/spine2.yml -
```
However we can do even better. Notice how some of the input values of both spines are the same? We can move them into a shared cue file by combining both spines under the same directory:
```
mkdir spine
mv spine1 spine
mv spine2 spine
cat < spine/spine.cue
package nvue
_input: {
EnableIntfs: ["swp1", "swp2", "swp3", "swp4"]
BGPIntfs: EnableIntfs
VRFs: [{name: "default"}]
ASN: 65199
}
EOF
sed -i '/EnableIntfs/d' spine/spine1/input.cue
sed -i '/EnableIntfs/d' spine/spine2/input.cue
sed -i '/BGPIntfs/d' spine/spine1/input.cue
sed -i '/BGPIntfs/d' spine/spine2/input.cue
sed -i '/VRFs/d' spine/spine1/input.cue
sed -i '/VRFs/d' spine/spine2/input.cue
sed -i '/ASN/d' spine/spine1/input.cue
sed -i '/ASN/d' spine/spine2/input.cue
```
Since CUE uses hierarchical directory layout to unify structs, the resulting values are not changed.
### Scripting with CUE
At the stage we could've re-run the `dyff` command for both spine switching, adjusting it slightly to account for the new directory structure. However, CUE has a special feature that allows us to automate all tedious and repetitive commands. Let's define a new cue subcommand:
```
cat < nvue_tool.cue
package nvue
import (
"tool/exec"
"tool/cli"
"encoding/yaml"
)
host: *"spine1" | string @tag(host)
command: diff: {
diff: exec.Run & {
cmd: ["dyff", "between", "-b", "../originals/\(host).yml", "-"]
stdin: yaml.Marshal(config[host])
stdout: string
}
display: cli.Print & {
text: diff.stdout
}
}
EOF
```
Now we can use a much simpler CLI command to view `dyff` for a particular device:
```
cue -t host=spine1 diff ./...
cue -t host=spine2 diff ./...
```
CUE scripting allows more than just shell command automation. Using scripting we can print data on a screen or save it in files. Let's copy the pre-created tool file and demonstrate a couple of extra commands:
```
cue ls ./...
- Identified Devices -
spine1
spine2
cue save ./...
saving spine1 in ../new/spine1.yml
saving spine2 in ../new/spine2.yml
```
### Adding New Device Types
So far we've dealt with two device configs that were relatively similar. Now let's add another device type that will have a much greater variability. The process of splitting the values and schema is very similar, so we'll simply copy the pre-created files, without much explanation. You can check the contents of [`leaf.cue`](./cues/leaf/leaf.cue) file to see how the top-level schema has been expanded.
```
rm -rf leaf*
cp -a ../cues/leaf .
```
Another comparison between the original and generated YAML documents should indicate some discrepancies between the top-level schema in `top.cue` and what leaf switches are expecting to see.
```
cue cmp ./...
diff for spine2:
diff for spine1:
diff for leaf2:
set.vrf.BLUE.router.bgp
+ two map entries added:
neighbor:
swp51:
type: unnumbered
peer-group: underlay
swp52:
type: unnumbered
peer-group: underlay
peer-group:
underlay:
address-family:
l2vpn-evpn:
enable: on
remote-as: external
set.vrf.BLUE.router.bgp.address-family
+ one map entry added:
l2vpn-evpn:
enable: on
set.vrf.RED.router.bgp
+ two map entries added:
neighbor:
swp51:
type: unnumbered
peer-group: underlay
swp52:
type: unnumbered
peer-group: underlay
peer-group:
underlay:
address-family:
l2vpn-evpn:
enable: on
remote-as: external
...
```
A closer examination of the device config should tell use that some fields are only defined for the `default` VRF and not present for others. This can be quite easily recitified with a conditional statement.
```diff
~/cue-nvue/tmp main !7 ❯ diff top.cue ../cues/top.cue
52,53c52,55
< router: bgp: neighbor: _neighbor
< router: bgp: "peer-group": _peer_group
---
> if vrf.name == "default" {
> router: bgp: neighbor: _neighbor
> router: bgp: "peer-group": _peer_group
> }
```
Instead of showing individual changes here, let's just copy the final version of `top.cue` over the existing one:
```
cp ../cues/top.cue .
cp ../cues/spine/spine.cue spine
```
Re-running the `dyff` should confirm that all files now have the right structure and values.
```
cue cmp ./...
diff for spine1:
diff for spine2:
diff for leaf1:
diff for leaf3:
diff for leaf2:
diff for leaf4:
```
At this point we can save the generated YAML files in a new directory and use them to configure individual devices.
```
cue save ./...
saving leaf2 in ../new/leaf2.yml
saving leaf1 in ../new/leaf1.yml
saving leaf4 in ../new/leaf4.yml
saving spine1 in ../new/spine1.yml
saving spine2 in ../new/spine2.yml
saving leaf3 in ../new/leaf3.yml
```
### Boilerplate Reduction
Finally, let's see by how much we have reduced the total number of configuration lines. In the original format we had close to 1000 lines of configuration:
```
cat ../originals/* | wc -l
974
```
With CUE, we've managed to reduce that number to 416, which could've been even less if we discounted all of the empty lines.
```
mv nvue_tool.cue nvue_tool
find ./ -type f -name "*.cue" -exec cat {} + | wc -l
416
mv nvue_tool nvue_tool.cue
```
Needless to say that the relative reduction becomes higher as we get more devices of similar kind, e.g. more than 4 leaf switches.
## Conclusions
Here's a brief summary of what we've managed to achieve by modelling our network configuration in CUE:
* Create a statically-typed schema for network device configs.
* Optimised device configs and reduced the total number of config lines.
* Split concrete values from a common data model.
* Added validation constraints for input values to make sure things like BGP ASNs and IP addresses have correct format.
> This document is inspired by the official [Kubernetes tutorial](https://github.com/cue-lang/cue/blob/v0.4.0/doc/tutorial/kubernetes/README.md).