Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/upgini/upgini
Data search & enrichment library for Machine Learning → Easily find and add relevant features to your ML & AI pipeline from hundreds of public and premium external data sources, including open & commercial LLMs
https://github.com/upgini/upgini
automated-feature-engineering automl automl-pipeline chatgpt data-enrichment data-science feature-engineering feature-extraction feature-selection features kaggle kaggle-solution large-language-models llm machine-learning open-data open-datasets public-data python-library scikit-learn
Last synced: about 1 month ago
JSON representation
Data search & enrichment library for Machine Learning → Easily find and add relevant features to your ML & AI pipeline from hundreds of public and premium external data sources, including open & commercial LLMs
- Host: GitHub
- URL: https://github.com/upgini/upgini
- Owner: upgini
- License: bsd-3-clause
- Created: 2021-12-08T21:53:58.000Z (over 2 years ago)
- Default Branch: main
- Last Pushed: 2024-05-17T13:24:26.000Z (about 1 month ago)
- Last Synced: 2024-05-17T14:43:26.623Z (about 1 month ago)
- Topics: automated-feature-engineering, automl, automl-pipeline, chatgpt, data-enrichment, data-science, feature-engineering, feature-extraction, feature-selection, features, kaggle, kaggle-solution, large-language-models, llm, machine-learning, open-data, open-datasets, public-data, python-library, scikit-learn
- Language: Python
- Homepage: https://upgini.com
- Size: 161 MB
- Stars: 290
- Watchers: 5
- Forks: 24
- Open Issues: 6
-
Metadata Files:
- Readme: README.md
- Funding: .github/FUNDING.yml
- License: LICENSE
- Code of conduct: CODE_OF_CONDUCT.md
- Citation: CITATION.cff
- Codeowners: CODEOWNERS
Lists
- awesome-stars - upgini/upgini - Free automated data enrichment library for machine learning → searches through thousands of ready-to-use features from public and community shared data sources (Python)
- awesome-production-machine-learning - Upgini - Free automated data & feature enrichment library for machine learning: automatically searches through thousands of ready-to-use features from public and community shared data sources and enriches your training dataset with only the accuracy improving features. (AutoML)
- awesome-mlops - Upgini - Enriches training datasets with features from public and community shared data sources. (Data Enrichment)
- awesome-machine-learning - Upgini - automatically searches through thousands of ready-to-use features from public and community shared data sources and enriches your training dataset with only the accuracy improving features. (Python / General-Purpose Machine Learning)
- best-of-python - GitHub
- awesome-llmops - Upgini - to-use features from public and community shared data sources and enriches your training dataset with only the accuracy improving features |  | (Data / Data/Feature enrichment)
- awesome-machine-learning - Upgini - automatically searches through thousands of ready-to-use features from public and community shared data sources and enriches your training dataset with only the accuracy improving features. (Python / General-Purpose Machine Learning)
- awesome-machine-learning - Upgini - automatically searches through thousands of ready-to-use features from public and community shared data sources and enriches your training dataset with only the accuracy improving features. (Python / General-Purpose Machine Learning)
- awesome-machine-learning - Upgini - automatically searches through thousands of ready-to-use features from public and community shared data sources and enriches your training dataset with only the accuracy improving features. (Python / General-Purpose Machine Learning)
- awesome-stars - upgini/upgini - Data search & enrichment library for Machine Learning → Easily find and add relevant features to your ML & AI pipeline from hundreds of public and premium external data sources, including open & comme (Python)
- awesome-open-source-mlops - Upgini - Free automated data & feature enrichment library for machine learning: automatically searches through thousands of ready-to-use features from public and community shared data sources and enriches your training dataset with only the accuracy improving features (Data & Feature enrichment)
- Awesome-LLMOps - Upgini - Free automated data & feature enrichment library for machine learning: automatically searches through thousands of ready-to-use features from public and community shared data sources and enriches your training dataset with only the accuracy improving features (Data/Feature enrichment)
README
Upgini • Intelligent data search & enrichment for Machine Learning
Easily find and add relevant features to your ML pipeline from hundreds of public, community and premium external data sources, optimized for ML models with LLMs and other neural networks
Quick Start in Colab » |
Register / Sign In |
Slack Community |
Propose new Data source





## ❔ Overview
**Upgini** is an intelligent data search engine with a Python library that helps you find and add relevant features to your ML pipeline from hundreds of public, community, and premium external data sources. Under the hood, Upgini automatically optimizes all connected data sources by [generating an optimal set of machine ML features from the source data using large language models (LLMs), GraphNNs and recurrent neural networks (RNNs)](https://upgini.com/#optimized_external_data).
**Motivation:** for most supervised ML models external data & features boost accuracy significantly better than any hyperparameters tuning. But lack of automated and time-efficient enrichment tools for external data blocks massive adoption of external features in ML pipelines. We want radically simplify features search and enrichment to make external data a standard approach. Like a hyperparameter tuning for machine learning nowadays.
**Mission:** Democratize access to data sources for data science community.
## 🚀 Awesome features
⭐️ Automatically find only relevant features that *give accuracy improvement for ML model*. Not just correlated with target variable, what 9 out of 10 cases gives zero accuracy improvement
⭐️ Data source optimizations: automated feature generation with Large Language Models' data augmentation, RNNs, GraphNN; multiple data source ensembling
⭐️ *Automatic search key augmentation* from all connected sources. If you do not have all search keys in your search request, such as postal/zip code, Upgini will try to add those keys based on the provided set of search keys. This will broaden the search across all available data sources
⭐️ Calculate *accuracy metrics and uplifts* after enrichment existing ML model with external features
⭐️ Check the stability of accuracy gain from external data on out-of-time intervals and verification datasets. Mitigate risks of unstable external data dependencies in ML pipeline
⭐️ Easy to use - single request to enrich training dataset with [*all of the keys at once*](#-search-key-types-we-support-more-to-come):
date / datetime
phone number
postal / ZIP code
hashed email / HEM
country
IP-address
⭐️ Scikit-learn compatible interface for quick data integration with existing ML pipelines
⭐️ Support for most common supervised ML tasks on tabular data:
☑️ binary classification
☑️ multiclass classification
☑️ regression
☑️ time series prediction
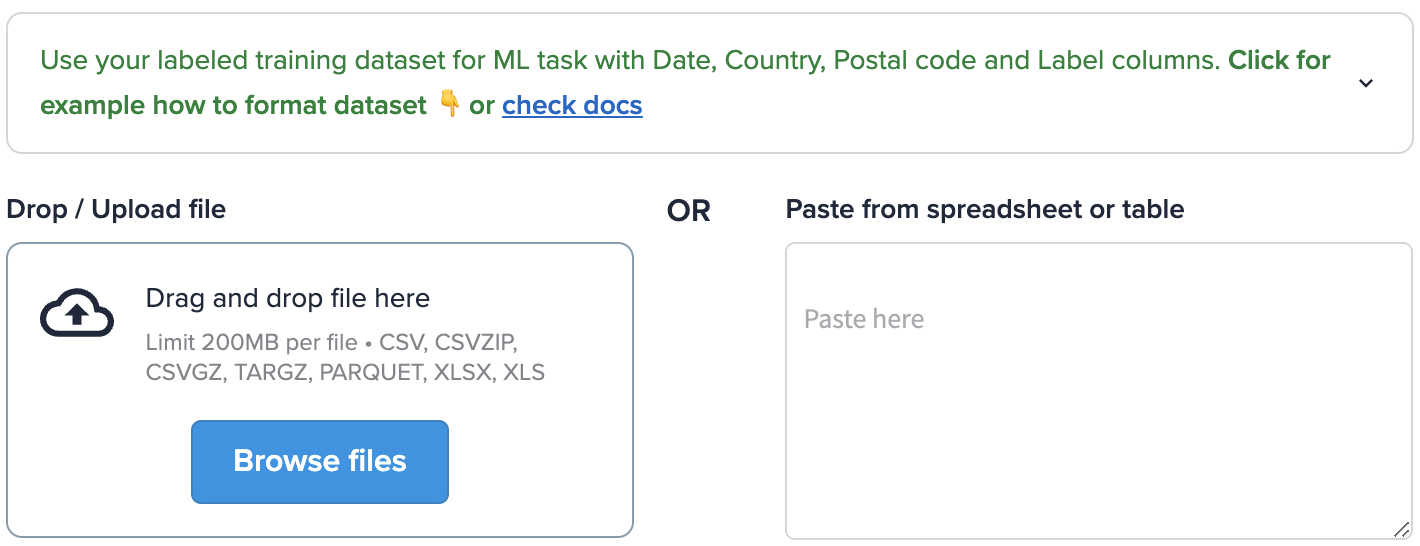
⭐️ [Simple Drag & Drop Search UI](https://appwidget-uragwvgykrk4sbmropphpy.streamlit.app/~/+/):
## 🌎 Connected data sources and coverage
- **Public data** : public sector, academic institutions, other sources through open data portals. Curated and updated by the Upgini team
- **Community shared data**: royalty / license free datasets or features from Data science community (our users). It's both a public and a scraped data
- **Premium data providers**: commercial data sources verified by the Upgini team in real-world use cases
👉 [**Details on datasets and features**](https://upgini.com/#data_sources)
#### 📊 Total: **239 countries** and **up to 41 years** of history
|Data sources|Countries|History, years|# sources for ensemble|Update|Search keys|API Key required
|--|--|--|--|--|--|--|
|Historical weather & Climate normals | 68 |22|-|Monthly|date, country, postal/ZIP code|No
|Location/Places/POI/Area/Proximity information from OpenStreetMap | 221 |2|-|Monthly|date, country, postal/ZIP code|No
|International holidays & events, Workweek calendar| 232 |22|-|Monthly|date, country|No
|Consumer Confidence index| 44 |22|-|Monthly|date, country|No
|World economic indicators|191 |41|-|Monthly|date, country|No
|Markets data|-|17|-|Monthly|date, datetime|No
|World mobile & fixed broadband network coverage and perfomance |167|-|3|Monthly|country, postal/ZIP code|No
|World demographic data |90|-|2|Annual|country, postal/ZIP code|No
|World house prices |44|-|3|Annual|country, postal/ZIP code|No
|Public social media profile data |104|-|-|Monthly|date, email/HEM, phone |Yes
|Car ownership data and Parking statistics|3|-|-|Annual|country, postal/ZIP code, email/HEM, phone|Yes
|Geolocation profile for phone & IPv4 & email|239|-|6|Monthly|date, email/HEM, phone, IPv4|Yes
|🔜 Email/WWW domain profile|-|-|-|-
❓**Know other useful data sources for machine learning?** [Give us a hint and we'll add it for free](https://forms.gle/pH99gb5hPxBEfNdR7).
## 💼 Tutorials
### [Search of relevant external features & Automated feature generation for Salary predicton task (use as a template)](https://github.com/upgini/upgini/blob/main/notebooks/Upgini_Features_search%26generation.ipynb)
* The goal is to predict salary for data science job postning based on information about employer and job description.
* Following this guide, you'll learn how to **search & auto generate new relevant features with Upgini library**
* The evaluation metric is [Mean Absolute Error (MAE)](https://en.wikipedia.org/wiki/Mean_absolute_error).
Run [Feature search & generation notebook](https://github.com/upgini/upgini/blob/main/notebooks/Upgini_Features_search%26generation.ipynb) inside your browser:
[](https://colab.research.google.com/github/upgini/upgini/blob/main/notebooks/Upgini_Features_search%26generation.ipynb)
### ❓ [Simple sales prediction for retail stores](https://github.com/upgini/upgini/blob/main/notebooks/kaggle_example.ipynb)
* The goal is to **predict future sales of different goods in stores** based on a 5-year history of sales.
* Kaggle Competition [Store Item Demand Forecasting Challenge](https://www.kaggle.com/c/demand-forecasting-kernels-only) is a product sales forecasting. The evaluation metric is [SMAPE](https://en.wikipedia.org/wiki/Symmetric_mean_absolute_percentage_error).
### ❓ [How to boost ML model accuracy for Kaggle TOP1 Leaderboard in 10 minutes](https://www.kaggle.com/code/romaupgini/more-external-features-for-top1-private-lb-4-54/notebook)
* The goal is **accuracy improvement for TOP1 winning Kaggle solution** from new relevant external features & data.
* [Kaggle Competition](https://www.kaggle.com/competitions/tabular-playground-series-jan-2022/) is a product sales forecasting, evaluation metric is [SMAPE](https://en.wikipedia.org/wiki/Symmetric_mean_absolute_percentage_error).
### ❓ [How to do low-code feature engineering for AutoML tools](https://www.kaggle.com/code/romaupgini/zero-feature-engineering-with-upgini-pycaret/notebook)
* **Save time on feature search and engineering**. Use ready-to-use external features and data sources to maximize overall AutoML accuracy, right out of the box.
* [Kaggle Competition](https://www.kaggle.com/competitions/tabular-playground-series-jan-2022/) is a product sales forecasting, evaluation metric is [SMAPE](https://en.wikipedia.org/wiki/Symmetric_mean_absolute_percentage_error).
* Low-code AutoML tools: [Upgini](https://github.com/upgini/upgini) and [PyCaret](https://github.com/pycaret/pycaret)
### ❓ [How to improve accuracy of Multivariate Time Series forecast from external features & data](https://www.kaggle.com/code/romaupgini/guide-external-data-features-for-multivariatets/notebook)
* The goal is **accuracy improvement of Multivariate Time Series prediction** from new relevant external features & data. The main challenge here is a strategy of data & feature enrichment, when a component of Multivariate TS depends not only on its past values but also has **some dependency on other components**.
* [Kaggle Competition](https://www.kaggle.com/competitions/tabular-playground-series-jan-2022/) is a product sales forecasting, evaluation metric is [RMSLE](https://www.kaggle.com/code/carlmcbrideellis/store-sales-using-the-average-of-the-last-16-days#Note-regarding-calculating-the-average).
### ❓ [How to speed up feature engineering hypothesis tests with ready-to-use external features](https://www.kaggle.com/code/romaupgini/statement-dates-to-use-or-not-to-use/notebook)
* **Save time on external data wrangling and feature calculation code** for hypothesis tests. The key challenge here is a time-dependent representation of information in a training dataset, which is uncommon for credit default prediction tasks. As a result, special data enrichment strategy is used.
* [Kaggle Competition](https://www.kaggle.com/competitions/amex-default-prediction) is a credit default prediction, evaluation metric is [normalized Gini coefficient](https://www.kaggle.com/competitions/amex-default-prediction/discussion/327464).
## 🏁 Quick start
### 1. Install from PyPI
```python
%pip install upgini
```
🐳 Docker-way
Clone $ git clone https://github.com/upgini/upgini or download upgini git repo locally
and follow steps below to build docker container 👇
1. Build docker image from cloned git repo:
cd upgini
docker build -t upgini .
...or directly from GitHub:
DOCKER_BUILDKIT=0 docker build -t upgini [email protected]:upgini/upgini.git#main
2. Run docker image:
docker run -p 8888:8888 upgini
3. Open http://localhost:8888?token="<"your_token_from_console_output">" in your browser
### 2. 💡 Use your labeled training dataset for search
You can use your labeled training datasets "as is" to initiate the search. Under the hood, we'll search for relevant data using:
- **[search keys](#-search-key-types-we-support-more-to-come)** from training dataset to match records from potential data sources with a new features
- **labels** from training dataset to estimate relevancy of feature or dataset for your ML task and calculate feature importance metrics
- **your features** from training dataset to find external datasets and features which only give accuracy improvement to your existing data and estimate accuracy uplift ([optional](#find-features-only-give-accuracy-gain-to-existing-data-in-the-ml-model))
Load training dataset into pandas dataframe and separate features' columns from label column in a Scikit-learn way:
```python
import pandas as pd
# labeled training dataset - customer_churn_prediction_train.csv
train_df = pd.read_csv("customer_churn_prediction_train.csv")
X = train_df.drop(columns="churn_flag")
y = train_df["churn_flag"]
```
⚠️ Requirements for search initialization dataset
We do dataset verification and cleaning under the hood, but still there are some requirements to follow:
1. pandas.DataFrame, pandas.Series or numpy.ndarray representation;
2. correct label column types: boolean/integers/strings for binary and multiclass labels, floats for regression;
3. at least one column selected as a search key;
4. min size after deduplication by search key column and NaNs removal: 100 records
### 3. 🔦 Choose one or multiple columns as a search keys
*Search keys* columns will be used to match records from all potential external data sources / features.
Define one or multiple columns as a search keys with `FeaturesEnricher` class initialization.
```python
from upgini import FeaturesEnricher, SearchKey
enricher = FeaturesEnricher(
search_keys={
"subscription_activation_date": SearchKey.DATE,
"country": SearchKey.COUNTRY,
"zip_code": SearchKey.POSTAL_CODE,
"hashed_email": SearchKey.HEM,
"last_visit_ip_address": SearchKey.IP,
"registered_with_phone": SearchKey.PHONE
})
```
#### ✨ Search key types we support (more to come!)
Search Key
Meaning Type
Description
Allowed pandas dtypes (python types)
Example
SearchKey.EMAIL
e-mail
object(str)
string
[email protected]
SearchKey.HEM
sha256(lowercase(email))
object(str)
string
0e2dfefcddc929933dcec9a5c7db7b172482814e63c80b8460b36a791384e955
SearchKey.IP
IP address (version 4)
object(str, ipaddress.IPv4Address)
string
int64
192.168.0.1
SearchKey.PHONE
phone number, E.164 standard
object(str)
string
int64
float64
443451925138
SearchKey.DATE
date
object(str)
string
datetime64[ns]
period[D]
2020-02-12 (ISO-8601 standard)
12.02.2020 (non standard notation)
SearchKey.DATETIME
datetime
object(str)
string
datetime64[ns]
period[D]
2020-02-12 12:46:18
12:46:18 12.02.2020
SearchKey.COUNTRY
Country ISO-3166 code, Country name
object(str)
string
GB
US
IN
SearchKey.POSTAL_CODE
Postal code a.k.a. ZIP code. Could be used only with SearchKey.COUNTRY
object(str)
string
21174
061107
SE-999-99
For the meaning types SearchKey.DATE/SearchKey.DATETIME with dtypes object or string you have to clarify date/datetime format by passing date_format parameter to `FeaturesEnricher`. For example:
```python
from upgini import FeaturesEnricher, SearchKey
enricher = FeaturesEnricher(
search_keys={
"subscription_activation_date": SearchKey.DATE,
"country": SearchKey.COUNTRY,
"zip_code": SearchKey.POSTAL_CODE,
"hashed_email": SearchKey.HEM,
"last_visit_ip_address": SearchKey.IP,
"registered_with_phone": SearchKey.PHONE
},
date_format = "%Y-%d-%m"
)
```
To use datetime not in UTC timezone, you can cast datetime column explicitly to your timezone (example for Warsaw):
```python
df["date"] = df.date.astype("datetime64").dt.tz_localize("Europe/Warsaw")
```
Single country for the whole training dataset can be passed with `country_code` parameter:
```python
from upgini import FeaturesEnricher, SearchKey
enricher = FeaturesEnricher(
search_keys={
"subscription_activation_date": SearchKey.DATE,
"zip_code": SearchKey.POSTAL_CODE,
},
country_code = "US",
date_format = "%Y-%d-%m"
)
```
### 4. 🔍 Start your first feature search!
The main abstraction you interact is `FeaturesEnricher`, a Scikit-learn compatible estimator. You can easily add it into your existing ML pipelines.
Create instance of the `FeaturesEnricher` class and call:
- `fit` to search relevant datasets & features
- than `transform` to enrich your dataset with features from search result
Let's try it out!
```python
import pandas as pd
from upgini import FeaturesEnricher, SearchKey
# load labeled training dataset to initiate search
train_df = pd.read_csv("customer_churn_prediction_train.csv")
X = train_df.drop(columns="churn_flag")
y = train_df["churn_flag"]
# now we're going to create `FeaturesEnricher` class
enricher = FeaturesEnricher(
search_keys={
"subscription_activation_date": SearchKey.DATE,
"country": SearchKey.COUNTRY,
"zip_code": SearchKey.POSTAL_CODE
})
# everything is ready to fit! For 200к records fitting should take around 10 minutes,
# we send email notification, just register on profile.upgini.com
enricher.fit(X, y)
```
That's all). We've fitted `FeaturesEnricher`.
### 5. 📈 Evaluate feature importances (SHAP values) from the search result
`FeaturesEnricher` class has two properties for feature importances, which will be filled after fit - `feature_names_` and `feature_importances_`:
- `feature_names_` - feature names from the search result, and if parameter `keep_input=True` was used, initial columns from search dataset as well
- `feature_importances_` - SHAP values for features from the search result, same order as in `feature_names_`
Method `get_features_info()` returns pandas dataframe with features and full statistics after fit, including SHAP values and match rates:
```python
enricher.get_features_info()
```
Get more details about `FeaturesEnricher` at runtime using docstrings via `help(FeaturesEnricher)` or `help(FeaturesEnricher.fit)`.
### 6. 🏭 Enrich Production ML pipeline with relevant external features
`FeaturesEnricher` is a Scikit-learn compatible estimator, so any pandas dataframe can be enriched with external features from a search result (after `fit` ).
Use `transform` method of `FeaturesEnricher` , and let magic to do the rest 🪄
```python
# load dataset for enrichment
test_x = pd.read_csv("test.csv")
# enrich it!
enriched_test_features = enricher.transform(test_x)
```
#### 6.1 Reuse completed search for enrichment without 'fit' run
`FeaturesEnricher` can be initiated with a `search_id` parameter from completed search after fit method call.
Just use `enricher.get_search_id()` or copy search id string from the `fit()` output.
Search keys and features in X should be the same as for `fit()`
```python
enricher = FeaturesEnricher(
#same set of a search keys as for the fit step
search_keys={"date": SearchKey.DATE},
api_key="", # if you fit enricher with api_key then you should use it here
search_id = "abcdef00-0000-0000-0000-999999999999"
)
enriched_prod_dataframe=enricher.transform(input_dataframe)
```
#### 6.2 Enrichment with an updated external data sources and features
For most of the ML cases, training step requires labeled dataset with a historical observations from the past. But for production step you'll need an updated and actual data sources and features for the present time, to calculate a prediction.
`FeaturesEnricher`, when initiated with set of search keys which includes `SearchKey.DATE`, will match records from all potential external data sources **exactly on a the specific date/datetime** based on `SearchKey.DATE`. To avoid enrichment with features "form the future" for the `fit` step.
And then, for `transform` in a production ML pipeline, you'll get enrichment with relevant features, actual for the present date.
⚠️ Initiate `FeaturesEnricher` with `SearchKey.DATE` search key in a key set to get actual features for production and avoid features from the future for the training:
```python
enricher = FeaturesEnricher(
search_keys={
"subscription_activation_date": SearchKey.DATE,
"country": SearchKey.COUNTRY,
"zip_code": SearchKey.POSTAL_CODE,
},
)
```
## 💻 How it works?
### 🧹 Search dataset validation
We validate and clean search initialization dataset under the hood:
- сheck you **search keys** columns format;
- check zero variance for label column;
- check dataset for full row duplicates. If we find any, we remove duplicated rows and make a note on share of row duplicates;
- check inconsistent labels - rows with the same features and keys but different labels, we remove them and make a note on share of row duplicates;
- remove columns with zero variance - we treat any non **search key** column in search dataset as a feature, so columns with zero variance will be removed
### ❔ Supervised ML tasks detection
We detect ML task under the hood based on label column values. Currently we support:
- ModelTaskType.BINARY
- ModelTaskType.MULTICLASS
- ModelTaskType.REGRESSION
But for certain search datasets you can pass parameter to `FeaturesEnricher` with correct ML taks type:
```python
from upgini import ModelTaskType
enricher = FeaturesEnricher(
search_keys={"subscription_activation_date": SearchKey.DATE},
model_task_type=ModelTaskType.REGRESSION
)
```
#### ⏰ Time Series prediction support
*Time series prediction* supported as `ModelTaskType.REGRESSION` or `ModelTaskType.BINARY` tasks with time series specific cross-validation split:
* [Scikit-learn time series cross-validation](https://scikit-learn.org/stable/modules/cross_validation.html#time-series-split) - `CVType.time_series` parameter
* [Blocked time series cross-validation](https://goldinlocks.github.io/Time-Series-Cross-Validation/#Blocked-and-Time-Series-Split-Cross-Validation) - `CVType.blocked_time_series` parameter
To initiate feature search you can pass cross-validation type parameter to `FeaturesEnricher` with time series specific CV type:
```python
from upgini.metadata import CVType
enricher = FeaturesEnricher(
search_keys={"sales_date": SearchKey.DATE},
cv=CVType.time_series
)
```
⚠️ **Pre-process search dataset** in case of time series prediction:
sort rows in dataset according to observation order, in most cases - ascending order by date/datetime.
### 🆙 Accuracy and uplift metrics calculations
`FeaturesEnricher` automaticaly calculates model metrics and uplift from new relevant features either using `calculate_metrics()` method or `calculate_metrics=True` parameter in `fit` or `fit_transform` methods (example below).
You can use any model estimator with scikit-learn compartible interface, some examples are:
* [All Scikit-Learn supervised models](https://scikit-learn.org/stable/supervised_learning.html)
* [Xgboost](https://xgboost.readthedocs.io/en/stable/python/python_api.html#module-xgboost.sklearn)
* [LightGBM](https://lightgbm.readthedocs.io/en/latest/Python-API.html#scikit-learn-api)
* [CatBoost](https://catboost.ai/en/docs/concepts/python-quickstart)
👈 Evaluation metric should be passed to calculate_metrics() by scoring parameter,
out-of-the box Upgini supports
Metric
Description
explained_variance
Explained variance regression score function
r2
R2 (coefficient of determination) regression score function
max_error
Calculates the maximum residual error (negative - greater is better)
median_absolute_error
Median absolute error regression loss
mean_absolute_error
Mean absolute error regression loss
mean_absolute_percentage_error
Mean absolute percentage error regression loss
mean_squared_error
Mean squared error regression loss
mean_squared_log_error (or aliases: msle, MSLE)
Mean squared logarithmic error regression loss
root_mean_squared_log_error (or aliases: rmsle, RMSLE)
Root mean squared logarithmic error regression loss
root_mean_squared_error
Root mean squared error regression loss
mean_poisson_deviance
Mean Poisson deviance regression loss
mean_gamma_deviance
Mean Gamma deviance regression loss
accuracy
Accuracy classification score
top_k_accuracy
Top-k Accuracy classification score
roc_auc
Area Under the Receiver Operating Characteristic Curve (ROC AUC)
from prediction scores
roc_auc_ovr
Area Under the Receiver Operating Characteristic Curve (ROC AUC)
from prediction scores (multi_class="ovr")
roc_auc_ovo
Area Under the Receiver Operating Characteristic Curve (ROC AUC)
from prediction scores (multi_class="ovo")
roc_auc_ovr_weighted
Area Under the Receiver Operating Characteristic Curve (ROC AUC)
from prediction scores (multi_class="ovr", average="weighted")
roc_auc_ovo_weighted
Area Under the Receiver Operating Characteristic Curve (ROC AUC)
from prediction scores (multi_class="ovo", average="weighted")
balanced_accuracy
Compute the balanced accuracy
average_precision
Compute average precision (AP) from prediction scores
log_loss
Log loss, aka logistic loss or cross-entropy loss
brier_score
Compute the Brier score loss
In addition to that list, you can define custom evaluation metric function using [scikit-learn make_scorer](https://scikit-learn.org/0.15/modules/model_evaluation.html#defining-your-scoring-strategy-from-score-functions), for example [SMAPE](https://en.wikipedia.org/wiki/Symmetric_mean_absolute_percentage_error).
By default, `calculate_metrics()` method calculates evaluation metric with the same cross-validation split as selected for `FeaturesEnricher.fit()` by parameter `cv = CVType.`.
But you can easily define new split by passing child of BaseCrossValidator to parameter `cv` in `calculate_metrics()`.
Example with more tips-and-tricks:
```python
from upgini import FeaturesEnricher, SearchKey
enricher = FeaturesEnricher(search_keys={"registration_date": SearchKey.DATE})
# Fit with default setup for metrics calculation
# CatBoost will be used
enricher.fit(X, y, eval_set=eval_set, calculate_metrics=True)
# LightGBM estimator for metrics
custom_estimator = LGBMRegressor()
enricher.calculate_metrics(estimator=custom_estimator)
# Custom metric function to scoring param (callable or name)
custom_scoring = "RMSLE"
enricher.calculate_metrics(scoring=custom_scoring)
# Custom cross validator
custom_cv = TimeSeriesSplit(n_splits=5)
enricher.calculate_metrics(cv=custom_cv)
# All this custom parameters could be combined in both methods: fit, fit_transform and calculate_metrics:
enricher.fit(X, y, eval_set, calculate_metrics=True, estimator=custom_estimator, scoring=custom_scoring, cv=custom_cv)
```
## ✅ More tips-and-tricks
### 🤖 Automated feature generation from columns in a search dataset
If a training dataset has a text column, you can generate additional embeddings from it using instructed embeddings generation with LLMs and data augmentation from external sources, just like Upgini does for all records from connected data sources.
For most cases, this gives better results than direct embeddings generation from a text field. Currently, Upgini has two LLMs connected to a search engine - GPT-3.5 from OpenAI and GPT-J.
To use this feature, pass the column names as arguments to the `generate_features` parameter. You can use up to 2 columns.
Here's an example for generating features from the "description" and "summary" columns:
```python
enricher = FeaturesEnricher(
search_keys={"date": SearchKey.DATE},
generate_features=["description", "summary"]
)
```
With this code, Upgini will generate LLM embeddings from text columns and then check them for predictive power for your ML task.
Finally, Upgini will return a dataset enriched by only relevant components of LLM embeddings.
### Find features only give accuracy gain to existing data in the ML model
If you already have features or other external data sources, you can specifically search new datasets & features only give accuracy gain "on top" of them.
Just leave all these existing features in the labeled training dataset and Upgini library automatically use them during feature search process and as a baseline ML model to calculate accuracy metric uplift. Only features which improve accuracy will return.
### Check robustness of accuracy improvement from external features
You can validate external features robustness on out-of-time dataset using `eval_set` parameter:
```python
# load train dataset
train_df = pd.read_csv("train.csv")
train_ids_and_features = train_df.drop(columns="label")
train_label = train_df["label"]
# load out-of-time validation dataset
eval_df = pd.read_csv("validation.csv")
eval_ids_and_features = eval_df.drop(columns="label")
eval_label = eval_df["label"]
# create FeaturesEnricher
enricher = FeaturesEnricher(search_keys={"registration_date": SearchKey.DATE})
# now we fit WITH eval_set parameter to calculate accuracy metrics on Out-of-time dataset.
# the output will contain quality metrics for both the training data set and
# the eval set (validation OOT data set)
enricher.fit(
train_ids_and_features,
train_label,
eval_set = [(eval_ids_and_features, eval_label)]
)
```
#### ⚠️ Requirements for out-of-time dataset
- Same data schema as for search initialization dataset
- Pandas dataframe representation
### Use custom loss function in feature selection & metrics calculation
`FeaturesEnricher` can be initialized with additional string parameter `loss`.
Depending on ML-task, you can use the following loss functions:
- `regression`: regression, regression_l1, huber, poisson, quantile, mape, gamma, tweedie;
- `binary`: binary;
- `multiclass`: multiclass, multiclassova.
For instance, if your target variable has a Poisson distribution (count of events, number of customers in the shop and so on), you should try to use `loss="poisson"` to improve quality of feature selection and get better evaluation metrics.
Usage example:
```python
enricher = FeaturesEnricher(
search_keys={"date": SearchKey.DATE},
loss="poisson",
model_task_type=ModelTaskType.REGRESSION
)
enriched_dataframe.fit(X, y)
```
### Return initial dataframe enriched with TOP external features by importance
`transform` and `fit_transform` methods of `FeaturesEnricher` can be used with two additional parameters:
- `importance_threshold`: float = 0 - only features with *importance >= threshold* will be added to the output dataframe
- `max_features`: int - only first TOP N features by importance will be returned, where *N = max_features*
And `keep_input=True` will keep all initial columns from search dataset X:
```python
enricher = FeaturesEnricher(
search_keys={"subscription_activation_date": SearchKey.DATE}
)
enriched_dataframe.fit_transform(X, y, keep_input=True, max_features=2)
```
### Exclude premium data sources from fit, transform and metrics calculation
`fit`, `fit_transform`, `transform` and `calculate_metrics` methods of `FeaturesEnricher` can be used with parameter `exclude_features_sources` that allows to exclude Trial or Paid features from Premium data sources:
```python
enricher = FeaturesEnricher(
search_keys={"subscription_activation_date": SearchKey.DATE}
)
enricher.fit(X, y, calculate_metrics=False)
trial_features = enricher.get_features_info()[enricher.get_features_info()["Feature type"] == "Trial"]["Feature name"].values.tolist()
paid_features = enricher.get_features_info()[enricher.get_features_info()["Feature type"] == "Paid"]["Feature name"].values.tolist()
enricher.calculate_metrics(exclude_features_sources=(trial_features + paid_features))
enricher.transform(X, exclude_features_sources=(trial_features + paid_features))
```
### Turn off autodetection for search key columns
Upgini has autodetection of search keys on by default.
To turn off use `detect_missing_search_keys=False`:
```python
enricher = FeaturesEnricher(
search_keys={"date": SearchKey.DATE},
detect_missing_search_keys=False,
)
enricher.fit(X, y)
```
## Turn off removing of target outliers
Upgini detect rows with target outlier for regression tasks. By default such rows are dropped on metrics calculation. To turn off removing of target outlier rows use parameter `remove_outliers_calc_metrics=False` in fit, fit_transform or calculate_metrics methods:
```python
enricher = FeaturesEnricher(
search_keys={"date": SearchKey.DATE},
)
enricher.fit(X, y, remove_outliers_calc_metrics=False)
```
## 🔑 Open up all capabilities of Upgini
[Register](https://profile.upgini.com) and get a free API key for exclusive data sources and features: 600 mln+ phone numbers, 350 mln+ emails, 2^32 IP addresses
|Benefit|No Sign-up | Registered user |
|--|--|--|
|Enrichment with **date/datetime, postal/ZIP code and country keys** | Yes | Yes |
|Enrichment with **phone number, hashed email/HEM and IP-address keys** | No | Yes |
|Email notification on **search task completion** | No | Yes |
|Automated **feature generation with LLMs** from columns in a search dataset| Yes, *till 12/05/23* | Yes |
|Email notification on **new data source activation** 🔜 | No | Yes |
## 👩🏻💻 How to share data/features with a community ?
You may publish ANY data which you consider as royalty / license free ([Open Data](http://opendatahandbook.org/guide/en/what-is-open-data/)) and potentially valuable for ML applications for **community usage**:
1. Please Sign Up [here](https://profile.upgini.com)
2. Copy *Upgini API key* from profile and upload your data from Upgini python library with this key:
```python
import pandas as pd
from upgini import SearchKey
from upgini.ads import upload_user_ads
import os
os.environ["UPGINI_API_KEY"] = "your_long_string_api_key_goes_here"
#you can define custom search key which might not be supported yet, just use SearchKey.CUSTOM_KEY type
sample_df = pd.read_csv("path_to_data_sample_file")
upload_user_ads("test", sample_df, {
"city": SearchKey.CUSTOM_KEY,
"stats_date": SearchKey.DATE
})
```
3. After data verification, search results on community data will be available usual way.
## 🛠 Getting Help & Community
Please note, that we are still in a beta stage.
Requests and support, in preferred order
[](https://4mlg.short.gy/join-upgini-community)
[](https://github.com/upgini/upgini/issues)
❗Please try to create bug reports that are:
- **reproducible** - include steps to reproduce the problem.
- **specific** - include as much detail as possible: which Python version, what environment, etc.
- **unique** - do not duplicate existing opened issues.
- **scoped to a Single Bug** - one bug per report.
## 🧩 Contributing
We are a **very** small team and this is a part-time project for us, thus most probably we won't be able:
- implement smooth integration with most common low-code ML libraries and platforms ([PyCaret](https://www.github.com/pycaret/pycaret), [H2O AutoML](https://github.com//h2oai/h2o-3/blob/master/h2o-docs/src/product/automl.rst), etc. )
- implement all possible data verification and normalization capabilities for different types of search keys (we just started with current 6 types)
And we need some help from community)
So, we'll be happy about every **pull request** you open and **issue** you find to make this library **more incredible**. Please note that it might sometimes take us a while to get back to you.
**For major changes**, please open an issue first to discuss what you would like to change
#### Developing
Some convenient ways to start contributing are:
⚙️ [**Open in Visual Studio Code**](https://open.vscode.dev/upgini/upgini) You can remotely open this repo in VS Code without cloning or automatically clone and open it inside a docker container.
⚙️ **Gitpod** [](https://gitpod.io/#https://github.com/upgini/upgini) You can use Gitpod to launch a fully functional development environment right in your browser.
## 🔗 Useful links
- [Simple sales predictions as a template notebook](#-simple-sales-predictions-use-as-a-template)
- [Full list of Kaggle Guides & Examples](https://www.kaggle.com/romaupgini/code)
- [Project on PyPI](https://pypi.org/project/upgini)
- [More perks for registered users](https://profile.upgini.com)
😔 Found mistype or a bug in code snippet? Our bad!
Please report it here.