Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/erikbern/ann-benchmarks
Benchmarks of approximate nearest neighbor libraries in Python
https://github.com/erikbern/ann-benchmarks
benchmark docker nearest-neighbors
Last synced: 6 days ago
JSON representation
Benchmarks of approximate nearest neighbor libraries in Python
- Host: GitHub
- URL: https://github.com/erikbern/ann-benchmarks
- Owner: erikbern
- License: mit
- Created: 2015-05-28T13:21:43.000Z (about 9 years ago)
- Default Branch: main
- Last Pushed: 2024-05-22T11:17:09.000Z (about 1 month ago)
- Last Synced: 2024-05-22T11:56:19.352Z (about 1 month ago)
- Topics: benchmark, docker, nearest-neighbors
- Language: Python
- Homepage: http://ann-benchmarks.com
- Size: 21.4 MB
- Stars: 4,658
- Watchers: 117
- Forks: 701
- Open Issues: 62
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Lists
- awesome-stars - erikbern/ann-benchmarks - Benchmarks of approximate nearest neighbor libraries in Python (Python)
- awesome-stars - erikbern/ann-benchmarks - Benchmarks of approximate nearest neighbor libraries in Python (Python)
- awesome-genai - Vector DB/ANN Benchmark
- awesome-stars - ann-benchmarks
- my-awesome - erikbern/ann-benchmarks - neighbors pushed_at:2024-06 star:4.7k fork:0.7k Benchmarks of approximate nearest neighbor libraries in Python (Python)
- graph-networks - Benchmarks of approximate nearest neighbor libraries
- my-stars - erikbern/ann-benchmarks - Benchmarks of approximate nearest neighbor libraries in Python (Python)
- awesome-list - ann-benchmarks - Benchmarks of approximate nearest neighbor libraries in Python. (Machine Learning Framework / Nearest Neighbors & Similarity)
- awesome-stars - erikbern/ann-benchmarks - Benchmarks of approximate nearest neighbor libraries in Python (Python)
- awesome-stars - erikbern/ann-benchmarks - `★4696` Benchmarks of approximate nearest neighbor libraries in Python (Python)
README
Benchmarking nearest neighbors
==============================
[](https://github.com/erikbern/ann-benchmarks/actions/workflows/benchmarks.yml)
Doing fast searching of nearest neighbors in high dimensional spaces is an increasingly important problem with notably few empirical attempts at comparing approaches in an objective way, despite a clear need for such to drive optimization forward.
This project contains tools to benchmark various implementations of approximate nearest neighbor (ANN) search for selected metrics. We have pre-generated datasets (in HDF5 format) and prepared Docker containers for each algorithm, as well as a [test suite](https://github.com/erikbern/ann-benchmarks/actions) to verify function integrity.
Evaluated
=========
* [Annoy](https://github.com/spotify/annoy) 
* [FLANN](http://www.cs.ubc.ca/research/flann/) 
* [scikit-learn](http://scikit-learn.org/stable/modules/neighbors.html): LSHForest, KDTree, BallTree
* [Weaviate](https://github.com/weaviate/weaviate) 
* [PANNS](https://github.com/ryanrhymes/panns) 
* [NearPy](http://pixelogik.github.io/NearPy/) 
* [KGraph](https://github.com/aaalgo/kgraph) 
* [NMSLIB (Non-Metric Space Library)](https://github.com/nmslib/nmslib) : SWGraph, HNSW, BallTree, MPLSH
* [hnswlib (a part of nmslib project)](https://github.com/nmslib/hnsw) 
* [RPForest](https://github.com/lyst/rpforest) 
* [FAISS](https://github.com/facebookresearch/faiss) 
* [DolphinnPy](https://github.com/ipsarros/DolphinnPy) 
* [Datasketch](https://github.com/ekzhu/datasketch) 
* [nndescent](https://github.com/brj0/nndescent) 
* [PyNNDescent](https://github.com/lmcinnes/pynndescent) 
* [MRPT](https://github.com/teemupitkanen/mrpt) 
* [NGT](https://github.com/yahoojapan/NGT) : ONNG, PANNG, QG
* [SPTAG](https://github.com/microsoft/SPTAG) 
* [PUFFINN](https://github.com/puffinn/puffinn) 
* [N2](https://github.com/kakao/n2) 
* [ScaNN](https://github.com/google-research/google-research/tree/master/scann)
* [Vearch](https://github.com/vearch/vearch) 
* [Elasticsearch](https://github.com/elastic/elasticsearch) : HNSW
* [Elastiknn](https://github.com/alexklibisz/elastiknn) 
* [OpenSearch KNN](https://github.com/opensearch-project/k-NN) 
* [DiskANN](https://github.com/microsoft/diskann) : Vamana, Vamana-PQ
* [Vespa](https://github.com/vespa-engine/vespa) 
* [scipy](https://docs.scipy.org/doc/scipy/reference/spatial.html): cKDTree
* [vald](https://github.com/vdaas/vald) 
* [Qdrant](https://github.com/qdrant/qdrant) 
* [HUAWEI(qsgngt)](https://github.com/WPJiang/HWTL_SDU-ANNS.git)
* [Milvus](https://github.com/milvus-io/milvus) : [Knowhere](https://github.com/milvus-io/knowhere)
* [Zilliz(Glass)](https://github.com/hhy3/pyglass)
* [pgvector](https://github.com/pgvector/pgvector) 
* [pgvecto.rs](https://github.com/tensorchord/pgvecto.rs) 
* [RediSearch](https://github.com/redisearch/redisearch) 
* [pg_embedding](https://github.com/neondatabase/pg_embedding) 
* [Descartes(01AI)](https://github.com/xiaoming-01ai/descartes)
Data sets
=========
We have a number of precomputed data sets in HDF5 format. All data sets have been pre-split into train/test and include ground truth data for the top-100 nearest neighbors.
| Dataset | Dimensions | Train size | Test size | Neighbors | Distance | Download |
| ----------------------------------------------------------------- | ---------: | ---------: | --------: | --------: | --------- | -------------------------------------------------------------------------- |
| [DEEP1B](http://sites.skoltech.ru/compvision/noimi/) | 96 | 9,990,000 | 10,000 | 100 | Angular | [HDF5](http://ann-benchmarks.com/deep-image-96-angular.hdf5) (3.6GB)
| [Fashion-MNIST](https://github.com/zalandoresearch/fashion-mnist) | 784 | 60,000 | 10,000 | 100 | Euclidean | [HDF5](http://ann-benchmarks.com/fashion-mnist-784-euclidean.hdf5) (217MB) |
| [GIST](http://corpus-texmex.irisa.fr/) | 960 | 1,000,000 | 1,000 | 100 | Euclidean | [HDF5](http://ann-benchmarks.com/gist-960-euclidean.hdf5) (3.6GB) |
| [GloVe](http://nlp.stanford.edu/projects/glove/) | 25 | 1,183,514 | 10,000 | 100 | Angular | [HDF5](http://ann-benchmarks.com/glove-25-angular.hdf5) (121MB) |
| GloVe | 50 | 1,183,514 | 10,000 | 100 | Angular | [HDF5](http://ann-benchmarks.com/glove-50-angular.hdf5) (235MB) |
| GloVe | 100 | 1,183,514 | 10,000 | 100 | Angular | [HDF5](http://ann-benchmarks.com/glove-100-angular.hdf5) (463MB) |
| GloVe | 200 | 1,183,514 | 10,000 | 100 | Angular | [HDF5](http://ann-benchmarks.com/glove-200-angular.hdf5) (918MB) |
| [Kosarak](http://fimi.uantwerpen.be/data/) | 27,983 | 74,962 | 500 | 100 | Jaccard | [HDF5](http://ann-benchmarks.com/kosarak-jaccard.hdf5) (33MB) |
| [MNIST](http://yann.lecun.com/exdb/mnist/) | 784 | 60,000 | 10,000 | 100 | Euclidean | [HDF5](http://ann-benchmarks.com/mnist-784-euclidean.hdf5) (217MB) |
| [MovieLens-10M](https://grouplens.org/datasets/movielens/10m/) | 65,134 | 69,363 | 500 | 100 | Jaccard | [HDF5](http://ann-benchmarks.com/movielens10m-jaccard.hdf5) (63MB) |
| [NYTimes](https://archive.ics.uci.edu/ml/datasets/bag+of+words) | 256 | 290,000 | 10,000 | 100 | Angular | [HDF5](http://ann-benchmarks.com/nytimes-256-angular.hdf5) (301MB) |
| [SIFT](http://corpus-texmex.irisa.fr/) | 128 | 1,000,000 | 10,000 | 100 | Euclidean | [HDF5](http://ann-benchmarks.com/sift-128-euclidean.hdf5) (501MB) |
| [Last.fm](https://github.com/erikbern/ann-benchmarks/pull/91) | 65 | 292,385 | 50,000 | 100 | Angular | [HDF5](http://ann-benchmarks.com/lastfm-64-dot.hdf5) (135MB) |
Results
=======
These are all as of April 2023, running all benchmarks on a r6i.16xlarge machine on AWS with `--parallelism 31` and hyperthreading disabled. All benchmarks are single-CPU.
glove-100-angular
-----------------

sift-128-euclidean
------------------

fashion-mnist-784-euclidean
---------------------------

nytimes-256-angular
-------------------

gist-960-euclidean
-------------------
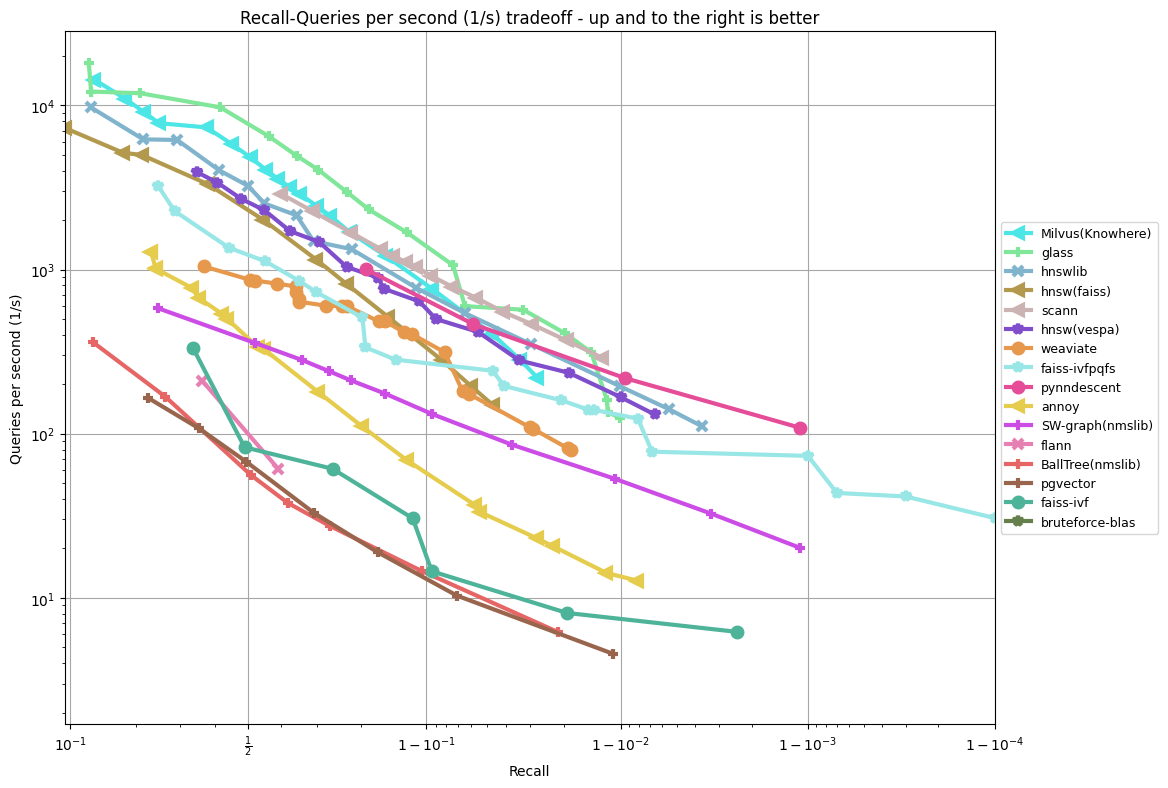
glove-25-angular
----------------

TODO: update plots on .
Install
=======
The only prerequisite is Python (tested with 3.10.6) and Docker.
1. Clone the repo.
2. Run `pip install -r requirements.txt`.
3. Run `python install.py` to build all the libraries inside Docker containers (this can take a while, like 10-30 minutes).
Running
=======
1. Run `python run.py` (this can take an extremely long time, potentially days)
2. Run `python plot.py` or `python create_website.py` to plot results.
3. Run `python data_export.py --out res.csv` to export all results into a csv file for additional post-processing.
You can customize the algorithms and datasets as follows:
* Check that `ann_benchmarks/algorithms/{YOUR_IMPLEMENTATION}/config.yml` contains the parameter settings that you want to test
* To run experiments on SIFT, invoke `python run.py --dataset glove-100-angular`. See `python run.py --help` for more information on possible settings. Note that experiments can take a long time.
* To process the results, either use `python plot.py --dataset glove-100-angular` or `python create_website.py`. An example call: `python create_website.py --plottype recall/time --latex --scatter --outputdir website/`.
Including your algorithm
========================
Add your algorithm in the folder `ann_benchmarks/algorithms/{YOUR_IMPLEMENTATION}/` by providing
- [ ] A small Python wrapper in `module.py`
- [ ] A Dockerfile named `Dockerfile`
- [ ] A set of hyper-parameters in `config.yml`
- [ ] A CI test run by adding your implementation to `.github/workflows/benchmarks.yml`
Check the [available implementations](./ann_benchmarks/algorithms/) for inspiration.
Principles
==========
* Everyone is welcome to submit pull requests with tweaks and changes to how each library is being used.
* In particular: if you are the author of any of these libraries, and you think the benchmark can be improved, consider making the improvement and submitting a pull request.
* This is meant to be an ongoing project and represent the current state.
* Make everything easy to replicate, including installing and preparing the datasets.
* Try many different values of parameters for each library and ignore the points that are not on the precision-performance frontier.
* High-dimensional datasets with approximately 100-1000 dimensions. This is challenging but also realistic. Not more than 1000 dimensions because those problems should probably be solved by doing dimensionality reduction separately.
* Single queries are used by default. ANN-Benchmarks enforces that only one CPU is saturated during experimentation, i.e., no multi-threading. A batch mode is available that provides all queries to the implementations at once. Add the flag `--batch` to `run.py` and `plot.py` to enable batch mode.
* Avoid extremely costly index building (more than several hours).
* Focus on datasets that fit in RAM. For billion-scale benchmarks, see the related [big-ann-benchmarks](https://github.com/harsha-simhadri/big-ann-benchmarks) project.
* We mainly support CPU-based ANN algorithms. GPU support exists for FAISS, but it has to be compiled with GPU support locally and experiments must be run using the flags `--local --batch`.
* Do proper train/test set of index data and query points.
* Note that we consider that set similarity datasets are sparse and thus we pass a **sorted** array of integers to algorithms to represent the set of each user.
Authors
=======
Built by [Erik Bernhardsson](https://erikbern.com) with significant contributions from [Martin Aumüller](http://itu.dk/people/maau/) and [Alexander Faithfull](https://github.com/ale-f).
Related Publication
==================
Design principles behind the benchmarking framework are described in the following publications:
- M. Aumüller, E. Bernhardsson, A. Faithfull:
[ANN-Benchmarks: A Benchmarking Tool for Approximate Nearest Neighbor Algorithms](https://arxiv.org/abs/1807.05614). Information Systems 2019. DOI: [10.1016/j.is.2019.02.006](https://doi.org/10.1016/j.is.2019.02.006)
- M. Aumüller, E. Bernhardsson, A. Faithfull: [Reproducibility protocol for ANN-Benchmarks: A benchmarking tool for approximate nearest neighbor search algorithms](https://itu.dk/people/maau/additional/2022-ann-benchmarks-reproducibility.pdf), [Artifacts](https://doi.org/10.5281/zenodo.4607761).
Related Projects
================
- [big-ann-benchmarks](https://github.com/harsha-simhadri/big-ann-benchmarks) is a benchmarking effort for billion-scale approximate nearest neighbor search as part of the [NeurIPS'21 Competition track](https://neurips.cc/Conferences/2021/CompetitionTrack).