Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/ChenRocks/UNITER
Research code for ECCV 2020 paper "UNITER: UNiversal Image-TExt Representation Learning"
https://github.com/ChenRocks/UNITER
pre-training pytorch transformers vision-and-language
Last synced: 13 days ago
JSON representation
Research code for ECCV 2020 paper "UNITER: UNiversal Image-TExt Representation Learning"
- Host: GitHub
- URL: https://github.com/ChenRocks/UNITER
- Owner: ChenRocks
- Created: 2020-01-28T00:09:59.000Z (over 4 years ago)
- Default Branch: master
- Last Pushed: 2021-06-30T21:46:55.000Z (about 3 years ago)
- Last Synced: 2023-10-20T18:47:52.066Z (9 months ago)
- Topics: pre-training, pytorch, transformers, vision-and-language
- Language: Python
- Homepage: https://arxiv.org/abs/1909.11740
- Size: 172 KB
- Stars: 743
- Watchers: 18
- Forks: 108
- Open Issues: 45
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Lists
- StarryDivineSky - ChenRocks/UNITER - VE 、](https://github.com/necla-ml/SNLI-VE) [COCO](https://cocodataset.org/#home)和 [Flickr30k](http://shannon.cs.illinois.edu/DenotationGraph/)的图像文本检索以及 [引用表达式理解](https://github.com/lichengunc/refer)(RefCOCO、RefCOCO+ 和 RefCOCO-g)上微调 UNITER。UNITER-base 和 UNITER-large 的预训练检查点均已发布。还可以使用域内数据进行基于 UNITER 的预训练。 (其他_机器视觉 / 网络服务_其他)
README
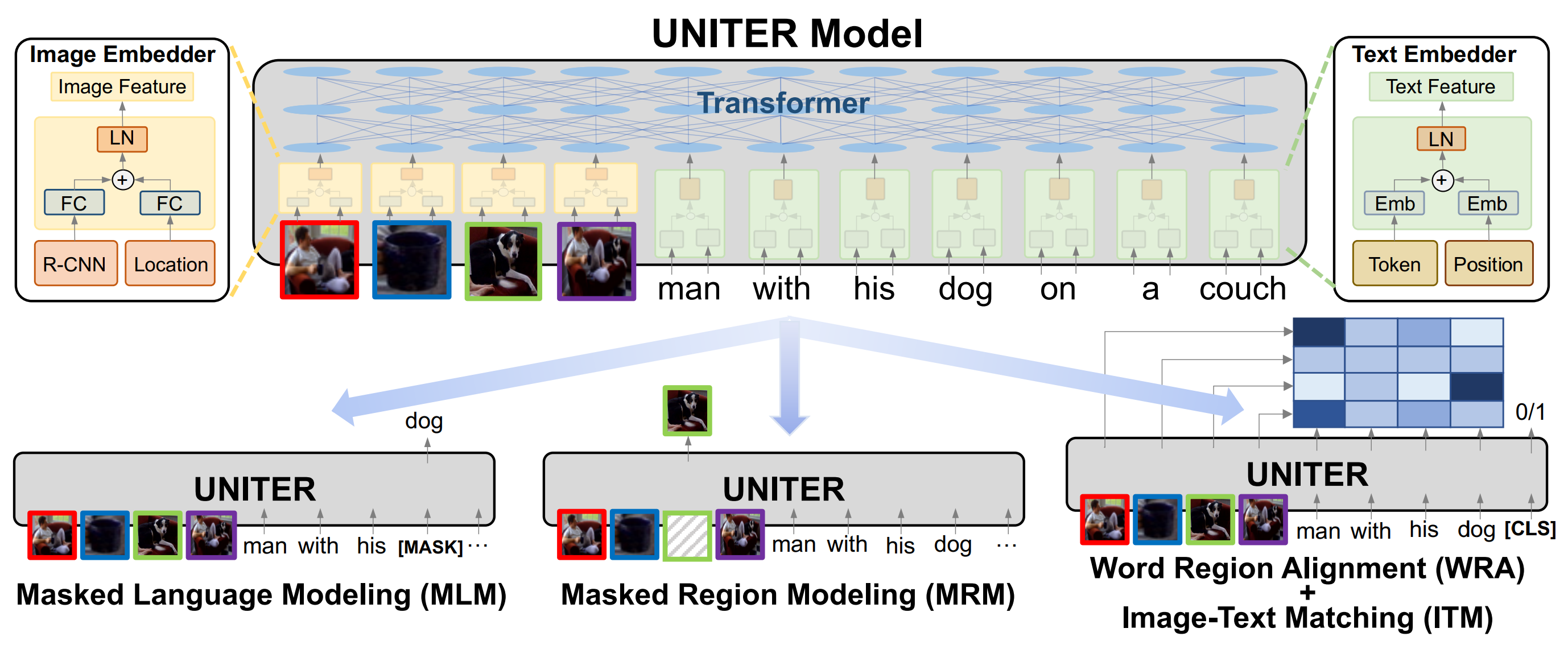
# UNITER: UNiversal Image-TExt Representation Learning
This is the official repository of [UNITER](https://arxiv.org/abs/1909.11740) (ECCV 2020).
This repository currently supports finetuning UNITER on
[NLVR2](http://lil.nlp.cornell.edu/nlvr/), [VQA](https://visualqa.org/), [VCR](https://visualcommonsense.com/),
[SNLI-VE](https://github.com/necla-ml/SNLI-VE),
Image-Text Retrieval for [COCO](https://cocodataset.org/#home) and
[Flickr30k](http://shannon.cs.illinois.edu/DenotationGraph/), and
[Referring Expression Comprehensions](https://github.com/lichengunc/refer) (RefCOCO, RefCOCO+, and RefCOCO-g).
Both UNITER-base and UNITER-large pre-trained checkpoints are released.
UNITER-base pre-training with in-domain data is also available.
Some code in this repo are copied/modified from opensource implementations made available by
[PyTorch](https://github.com/pytorch/pytorch),
[HuggingFace](https://github.com/huggingface/transformers),
[OpenNMT](https://github.com/OpenNMT/OpenNMT-py),
and [Nvidia](https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch).
The image features are extracted using [BUTD](https://github.com/peteanderson80/bottom-up-attention).
## Requirements
We provide Docker image for easier reproduction. Please install the following:
- [nvidia driver](https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#package-manager-installation) (418+),
- [Docker](https://docs.docker.com/install/linux/docker-ce/ubuntu/) (19.03+),
- [nvidia-container-toolkit](https://github.com/NVIDIA/nvidia-docker#quickstart).
Our scripts require the user to have the [docker group membership](https://docs.docker.com/install/linux/linux-postinstall/)
so that docker commands can be run without sudo.
We only support Linux with NVIDIA GPUs. We test on Ubuntu 18.04 and V100 cards.
We use mixed-precision training hence GPUs with Tensor Cores are recommended.
## Quick Start
*NOTE*: Please run `bash scripts/download_pretrained.sh $PATH_TO_STORAGE` to get our latest pretrained
checkpoints. This will download both the base and large models.
We use NLVR2 as an end-to-end example for using this code base.
1. Download processed data and pretrained models with the following command.
```bash
bash scripts/download_nlvr2.sh $PATH_TO_STORAGE
```
After downloading you should see the following folder structure:
```
├── ann
│ ├── dev.json
│ └── test1.json
├── finetune
│ ├── nlvr-base
│ └── nlvr-base.tar
├── img_db
│ ├── nlvr2_dev
│ ├── nlvr2_dev.tar
│ ├── nlvr2_test
│ ├── nlvr2_test.tar
│ ├── nlvr2_train
│ └── nlvr2_train.tar
├── pretrained
│ └── uniter-base.pt
└── txt_db
├── nlvr2_dev.db
├── nlvr2_dev.db.tar
├── nlvr2_test1.db
├── nlvr2_test1.db.tar
├── nlvr2_train.db
└── nlvr2_train.db.tar
```
2. Launch the Docker container for running the experiments.
```bash
# docker image should be automatically pulled
source launch_container.sh $PATH_TO_STORAGE/txt_db $PATH_TO_STORAGE/img_db \
$PATH_TO_STORAGE/finetune $PATH_TO_STORAGE/pretrained
```
The launch script respects $CUDA_VISIBLE_DEVICES environment variable.
Note that the source code is mounted into the container under `/src` instead
of built into the image so that user modification will be reflected without
re-building the image. (Data folders are mounted into the container separately
for flexibility on folder structures.)
3. Run finetuning for the NLVR2 task.
```bash
# inside the container
python train_nlvr2.py --config config/train-nlvr2-base-1gpu.json
# for more customization
horovodrun -np $N_GPU python train_nlvr2.py --config $YOUR_CONFIG_JSON
```
4. Run inference for the NLVR2 task and then evaluate.
```bash
# inference
python inf_nlvr2.py --txt_db /txt/nlvr2_test1.db/ --img_db /img/nlvr2_test/ \
--train_dir /storage/nlvr-base/ --ckpt 6500 --output_dir . --fp16
# evaluation
# run this command outside docker (tested with python 3.6)
# or copy the annotation json into mounted folder
python scripts/eval_nlvr2.py ./results.csv $PATH_TO_STORAGE/ann/test1.json
```
The above command runs inference on the model we trained. Feel free to replace
`--train_dir` and `--ckpt` with your own model trained in step 3.
Currently we only support single GPU inference.
5. Customization
```bash
# training options
python train_nlvr2.py --help
```
- command-line argument overwrites JSON config files
- JSON config overwrites `argparse` default value.
- use horovodrun to run multi-GPU training
- `--gradient_accumulation_steps` emulates multi-gpu training
6. Misc.
```bash
# text annotation preprocessing
bash scripts/create_txtdb.sh $PATH_TO_STORAGE/txt_db $PATH_TO_STORAGE/ann
# image feature extraction (Tested on Titan-Xp; may not run on latest GPUs)
bash scripts/extract_imgfeat.sh $PATH_TO_IMG_FOLDER $PATH_TO_IMG_NPY
# image preprocessing
bash scripts/create_imgdb.sh $PATH_TO_IMG_NPY $PATH_TO_STORAGE/img_db
```
In case you would like to reproduce the whole preprocessing pipeline.
## Downstream Tasks Finetuning
### VQA
NOTE: train and inference should be ran inside the docker container
1. download data
```
bash scripts/download_vqa.sh $PATH_TO_STORAGE
```
2. train
```
horovodrun -np 4 python train_vqa.py --config config/train-vqa-base-4gpu.json \
--output_dir $VQA_EXP
```
3. inference
```
python inf_vqa.py --txt_db /txt/vqa_test.db --img_db /img/coco_test2015 \
--output_dir $VQA_EXP --checkpoint 6000 --pin_mem --fp16
```
The result file will be written at `$VQA_EXP/results_test/results_6000_all.json`, which can be
submitted to the evaluation server
### VCR
NOTE: train and inference should be ran inside the docker container
1. download data
```
bash scripts/download_vcr.sh $PATH_TO_STORAGE
```
2. train
```
horovodrun -np 4 python train_vcr.py --config config/train-vcr-base-4gpu.json \
--output_dir $VCR_EXP
```
3. inference
```
horovodrun -np 4 python inf_vcr.py --txt_db /txt/vcr_test.db \
--img_db "/img/vcr_gt_test/;/img/vcr_test/" \
--split test --output_dir $VCR_EXP --checkpoint 8000 \
--pin_mem --fp16
```
The result file will be written at `$VCR_EXP/results_test/results_8000_all.csv`, which can be
submitted to VCR leaderboard for evluation.
### VCR 2nd Stage Pre-training
NOTE: pretrain should be ran inside the docker container
1. download VCR data if you haven't
```
bash scripts/download_vcr.sh $PATH_TO_STORAGE
```
2. 2nd stage pre-train
```
horovodrun -np 4 python pretrain_vcr.py --config config/pretrain-vcr-base-4gpu.json \
--output_dir $PRETRAIN_VCR_EXP
```
### Visual Entailment (SNLI-VE)
NOTE: train should be ran inside the docker container
1. download data
```
bash scripts/download_ve.sh $PATH_TO_STORAGE
```
2. train
```
horovodrun -np 2 python train_ve.py --config config/train-ve-base-2gpu.json \
--output_dir $VE_EXP
```
### Image-Text Retrieval
download data
```
bash scripts/download_itm.sh $PATH_TO_STORAGE
```
NOTE: Image-Text Retrieval is computationally heavy, especially on COCO.
#### Zero-shot Image-Text Retrieval (Flickr30k)
```
# every image-text pair has to be ranked; please use as many GPUs as possible
horovodrun -np $NGPU python inf_itm.py \
--txt_db /txt/itm_flickr30k_test.db --img_db /img/flickr30k \
--checkpoint /pretrain/uniter-base.pt --model_config /src/config/uniter-base.json \
--output_dir $ZS_ITM_RESULT --fp16 --pin_mem
```
#### Image-Text Retrieval (Flickr30k)
- normal finetune
```
horovodrun -np 8 python train_itm.py --config config/train-itm-flickr-base-8gpu.json
```
- finetune with hard negatives
```
horovodrun -np 16 python train_itm_hard_negatives.py \
--config config/train-itm-flickr-base-16gpu-hn.jgon
```
#### Image-Text Retrieval (COCO)
- finetune with hard negatives
```
horovodrun -np 16 python train_itm_hard_negatives.py \
--config config/train-itm-coco-base-16gpu-hn.json
```
### Referring Expressions
1. download data
```
bash scripts/download_re.sh $PATH_TO_STORAGE
```
2. train
```
python train_re.py --config config/train-refcoco-base-1gpu.json \
--output_dir $RE_EXP
```
3. inference and evaluation
```
source scripts/eval_refcoco.sh $RE_EXP
```
The result files will be written under `$RE_EXP/results_test/`
Similarly, change corresponding configs/scripts for running RefCOCO+/RefCOCOg.
## Pre-tranining
download
```
bash scripts/download_indomain.sh $PATH_TO_STORAGE
```
pre-train
```
horovodrun -np 8 python pretrain.py --config config/pretrain-indomain-base-8gpu.json \
--output_dir $PRETRAIN_EXP
```
Unfortunately, we cannot host CC/SBU features due to their large size. Users will need to process
them on their own. We will provide a smaller sample for easier reference to the expected format soon.
## Citation
If you find this code useful for your research, please consider citing:
```
@inproceedings{chen2020uniter,
title={Uniter: Universal image-text representation learning},
author={Chen, Yen-Chun and Li, Linjie and Yu, Licheng and Kholy, Ahmed El and Ahmed, Faisal and Gan, Zhe and Cheng, Yu and Liu, Jingjing},
booktitle={ECCV},
year={2020}
}
```
## License
MIT