Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/related-sciences/articat
articat: data artifact catalog
https://github.com/related-sciences/articat
data-catalog data-discovery data-management data-platform
Last synced: 3 months ago
JSON representation
articat: data artifact catalog
- Host: GitHub
- URL: https://github.com/related-sciences/articat
- Owner: related-sciences
- License: apache-2.0
- Created: 2021-06-19T00:29:12.000Z (about 3 years ago)
- Default Branch: main
- Last Pushed: 2024-03-27T17:39:58.000Z (3 months ago)
- Last Synced: 2024-03-27T18:44:17.108Z (3 months ago)
- Topics: data-catalog, data-discovery, data-management, data-platform
- Language: Python
- Homepage:
- Size: 182 KB
- Stars: 16
- Watchers: 4
- Forks: 2
- Open Issues: 19
-
Metadata Files:
- Readme: README.md
- Contributing: docs/contributing.md
- License: LICENSE
Lists
- awesome-stars - related-sciences/articat - articat: data artifact catalog (Python)
README
# articat
[](https://github.com/related-sciences/articat/actions/workflows/build.yml)
[](https://pypi.org/project/articat/)
Minimal metadata catalog to store and retrieve metadata about data artifacts.
## Getting started
At a high level, *articat* is simply a key-value store. Value being the Artifact metadata.
Key a.k.a. "Artifact Spec" being:
* globally unique `id`
* optional timestamp: `partition`
* optional arbitrary string: `version`
To publish a file system Artifact (`FSArtifact`):
```python
from articat import FSArtifact
from pathlib import Path
from datetime import date
# Apart from being a metadata containers, Artifact classes have optional
# convenience methods to help in data publishing flow:
with FSArtifact.partitioned("foo", partition=date(1643, 1, 4)) as fsa:
# To create a new Artifact, always use `with` statement, and
# either `partitioned` or `versioned` methods. Use:
# * `partitioned(...)`, for Artifacts with explicit `datetime` partition
# * `versioned(...)`, for Artifacts with explicit `str` version
# Next we produce some local data, this could be a Spark job,
# ML model etc.
data_path = Path("/tmp/data")
data_path.write_text("42")
# Now let's stage that data, temporary and final data directories/buckets
# are configurable (see below)
fsa.stage(data_path)
# Additionally let's provide some description, here we could also
# save some extra arbitrary metadata like model metrics, hyperparameters etc.
fsa.metadata.description = "Answer to the Ultimate Question of Life, the Universe, and Everything"
```
To retrieve the metadata about the Artifact above:
```python
from articat.fs_artifact import FSArtifact
from datetime import date
from pathlib import Path
# To retrieve the metadata, use Artifact object, and `fetch` method:
fsa = FSArtifact.partitioned("foo", partition=date(1643, 1, 4)).fetch()
fsa.id # "foo"
fsa.created #
fsa.partition #
fsa.metadata.description # "Answer to the Ultimate Question of Life, the Universe, and Everything"
fsa.main_dir # Data directory, this is where the data was stored after staging
Path(fsa.joinpath("data")).read_text() # 42
```
## Features
* store and retrieve metadata about your data artifacts
* no long running services (low maintenance)
* data publishing utils builtin
* IO/data format agnostic
* immutable metadata
* development mode
## Artifact flavours
Currently available Artifact flavours:
* `FSArtifact`: metadata/utils for files or objects (supports: local FS, GCS, S3 and more)
* `BQArtifact`: metadata/utils for BigQuery tables
* `NotebookArtifact`: metadata/utils for Jupyter Notebooks
## Development mode
To ease development of Artifacts, *articat* supports development/dev mode.
Development Artifact can be indicated by `dev` parameter (preferred), or
`_dev` prefix in the Artifact `id`. Dev mode supports:
* overwriting Artifact metadata
* configure separate locations (e.g. `dev_prefix` for `FSArtifact`), with
potentially different retention periods etc
## Backend
* `local`: mostly for testing/demo, metadata is stored locally (configurable, default: `~/.config/articat/local`)
* `gcp_datastore`: metadata is stored in the Google Cloud Datastore
## Configuration
*articat* configuration can be provided in the API, or configuration files. By default configuration
is loaded from `~/.config/articat/articat.cfg` and `articat.cfg` in current working directory. You
can also point at the configuration file via environment variable `ARTICAT_CONFIG`.
You use `local` mode without configuration file. Available options:
```toml
[main]
# local or gcp_datastore, default: local
# mode =
# local DB directory, default: ~/.config/articat/local
# local_db_dir =
[fs]
# temporary directory/prefix
# tmp_prefix =
# development data directory/prefix
# dev_prefix =
# production data directory/prefix
# prod_prefix =
[gcp]
# GCP project
# project =
[bq]
# development data BigQuery dataset
# dev_dataset =
# production data BigQuery dataset
# prod_dataset =
```
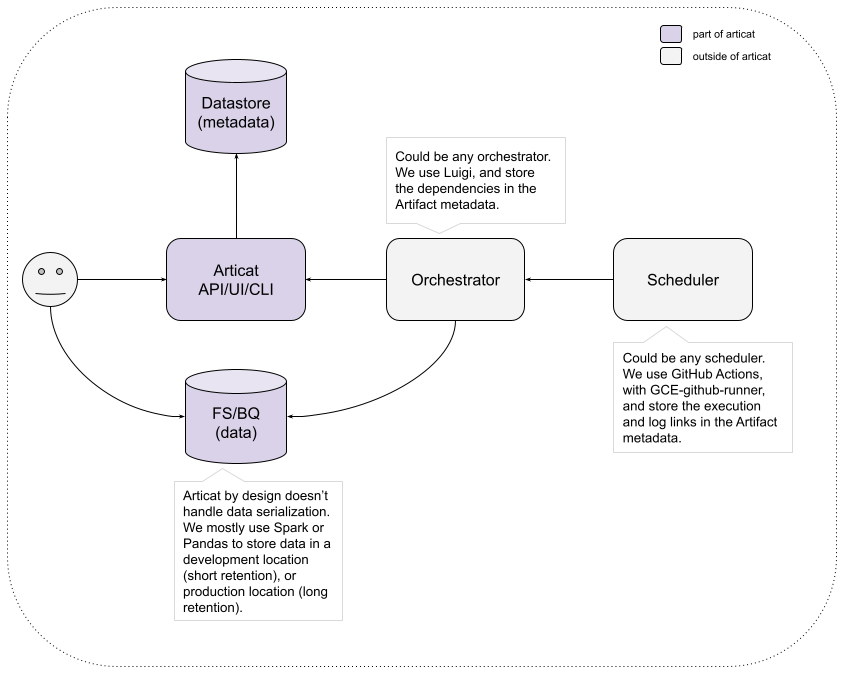
## Our/example setup
Below you can see a diagram of our setup, Articat is just one piece of our system, and solves a specific problem. This should give you an idea where it might fit into your environment: