Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/callat-qcd/espressodb
Science database interface using Django as the content manager.
https://github.com/callat-qcd/espressodb
Last synced: 4 months ago
JSON representation
Science database interface using Django as the content manager.
- Host: GitHub
- URL: https://github.com/callat-qcd/espressodb
- Owner: callat-qcd
- License: bsd-3-clause
- Created: 2019-09-18T17:55:35.000Z (almost 5 years ago)
- Default Branch: master
- Last Pushed: 2021-05-04T13:16:41.000Z (about 3 years ago)
- Last Synced: 2024-03-09T22:47:30.187Z (4 months ago)
- Language: Python
- Homepage: https://espressodb.readthedocs.io
- Size: 23.3 MB
- Stars: 8
- Watchers: 7
- Forks: 3
- Open Issues: 7
-
Metadata Files:
- Readme: README.md
- Contributing: CONTRIBUTING.md
- License: LICENSE.md
Lists
- awesome-stars - callat-qcd/espressodb - Science database interface using Django as the content manager. (Python)
README

[](https://pypi.org/project/espressodb/)
[](https://github.com/callat-qcd/espressodb/actions)
[](https://espressodb.readthedocs.io/en/latest/?badge=latest)
[](https://joss.theoj.org/papers/d0342f15684b9a464faed7c59784f734)
# EspressoDB
EspressoDB is a Python framework designed to organize (relational) data without losing flexibility.
Its objective is to be intuitive and fast.
More specifically, EspressoDB is built on top of the Object-Relational Mapping web framework [Django](https://docs.djangoproject.com) and adds additional convenience functionalities to easily set up your project.
Additionally, EspressoDB provides an extended framework of data consistency checks, giving users the freedom to define data tables and their relationships which uniquely mirror the underlying computation.
## What does EspressoDB provide?
EspressoDB provides an easy to use database interface which helps you make educated decisions fast.
Once you have created your Python project (e.g., `my_project`) with EspressoDB
* you can use it in all your Python apps to query your data. For example,
```python
import numpy as np
from my_project.hamiltonian.models import Contact as ContactHamiltonian
# Ask the database for specific entries
hamiltonian = ContactHamiltonian.objects.filter(n_sites=20).first()
# Use class methods for an intuitive interface
## Print a formatted summary of the table entry
print(hamiltonian)
## Allocate an actual matrix for the given entry and use it in computations
eigs, vecs = np.linalg.eigh(hamiltonian.matrix)
```
`models` classes are regular classes in Python.
They can provide additional methods for convenience.
Also, they know how to talk to the database, e.g., you can query (read) and update (write) your data to a central database.
* you can generate web views which summarize your tables and data.
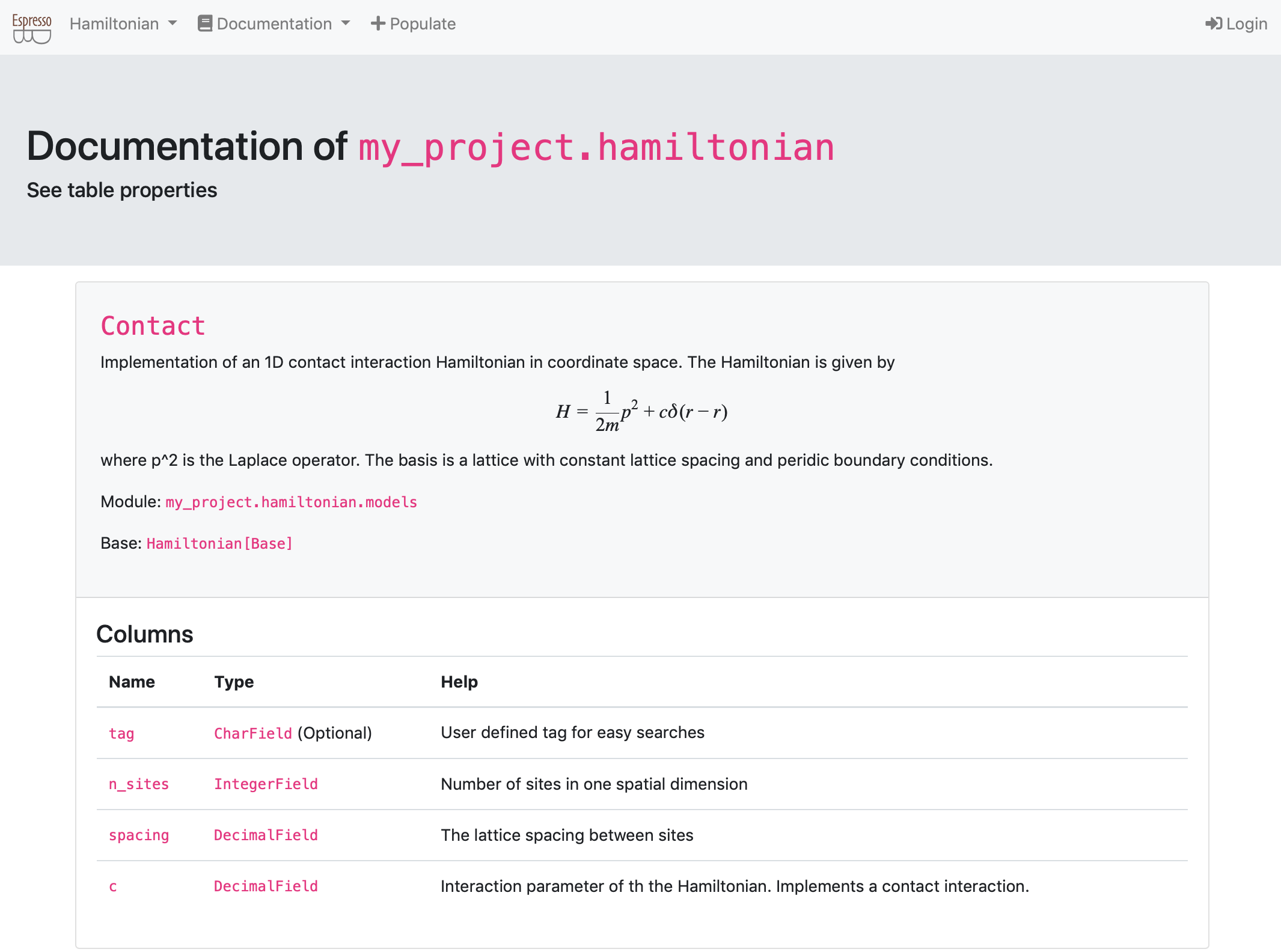
Because the web pages use a Python API as well, you can completely customize views with code you have already developed.
E.g., you can automate plots and display summaries in your browser.
If you want to, you can also make your web app public (with different layers of accessibility) and share results with others.
See also the [Documentation](https://espressodb.readthedocs.io/en/latest/) for more detailed usage instructions.
## How to install it?
EspressoDB can be installed via pip:
```bash
pip install [--user] espressodb
```
## Run the Tests
Since EspressoDB is about creating projects, the tests are implemented for the example project.
To run the tests, clone this repo, install the dependencies:
```bash
pip install .
pip install -r requirements-dev.txt
pip install -r example/my_project/requirements.txt
```
and run `pytest` (or the regular test) in `example/my_project`:
```bash
cd example/my_project
pytest [--cov=espressodb]
```
## What's the story behind it?
EspressoDB was developed when we created [LatteDB](https://www.github.com/callat-qcd/lattedb) -- a database for organizing Lattice Quantum Chromodynamics research.
We intended to create a database for several purposes, e.g. to optimize the scheduling of architecture-dependent many-node jobs and to help in the eventual analysis process.
For this reason, we started to abstract our thinking of how to organize physics objects.
It was the goal to have easily shareable and completely reproducible snapshots of our workflow while being flexible and not restricting ourselves too much -- in the end science is full of surprises.
The challenges we encountered were:
1. How can we program a table structure which can be easily extended in the future?
2. How do we write a database such that users not familiar with the database concept can start using this tool with minimal effort?
The core module of LatteDB, EspressoDB, is trying to address those challenges.
## Who is responsible for it?
* [@ckoerber](https://www.ckoerber.com) (Feel free to contact me for questions)
* [@cchang5](https://github.com/cchang5)
## Comparison to related technologies
1. [SQLAlchemy](https://www.sqlalchemy.org) - SQLAlchemy is a minimal low-level Python-SQL interface. While it also provides an ORM (Data Mapper implementation), setting up projects, establishing access to the database and migrating changes are not automated and thus interfacing to an existing project is less beginner-friendly than, e.g., interfacing with an existing Django project.
2. [Django](https://www.djangoproject.com) - Django is the parent of EspressoDB. It uses an active record implementation (direct correspondence between table rows and Python objects). While Django is intended to serve as a web framework, EspressoDB reinterprets and expands Django to be directly used in computational projects. To do so, EspressoDB streamlines the project creation, automates the setup components and provides additional cross-checks needed for multi-user scenarios.
## Contributing
Thanks for your interest in contributing! There are many ways to contribute to this project.
[Get started here](CONTRIBUTING.md).
## License
BSD 3-Clause License. See also the [LICENSE](LICENSE.md) file.