Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/peterk/warcworker
A dockerized, queued high fidelity web archiver based on Squidwarc
https://github.com/peterk/warcworker
archiving high-fidelity-preservation preservation webarchives webarchiving
Last synced: about 2 months ago
JSON representation
A dockerized, queued high fidelity web archiver based on Squidwarc
- Host: GitHub
- URL: https://github.com/peterk/warcworker
- Owner: peterk
- License: gpl-3.0
- Created: 2018-07-21T08:31:18.000Z (almost 6 years ago)
- Default Branch: master
- Last Pushed: 2020-07-19T20:33:15.000Z (almost 4 years ago)
- Last Synced: 2024-02-04T04:14:46.529Z (5 months ago)
- Topics: archiving, high-fidelity-preservation, preservation, webarchives, webarchiving
- Language: Python
- Homepage:
- Size: 175 KB
- Stars: 52
- Watchers: 6
- Forks: 9
- Open Issues: 7
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Lists
- awesome-web-archiving - Warcworker - An open source, dockerized, queued, high fidelity web archiver based on Squidwarc with a simple web GUI. *(Stable)* (Tools & Software / Acquisition)
- awesome-stars - peterk/warcworker - A dockerized, queued high fidelity web archiver based on Squidwarc (Python)
- awesome-web-archiving - Warcworker - An open source, dockerized, queued, high fidelity web archiver based on Squidwarc with a simple web GUI. (Stable) (Tools & Software / Acquisition)
README
# Warcworker
A dockerized queued high fidelity web archiver based on [Squidwarc](https://github.com/N0taN3rd/Squidwarc) (Chrome headless), RabbitMQ and a small web frontend. Using the scripting abilities of Squidwarc, you can add scripts that should be run for a specific job (e.g. src-set enrichment, comment expansion etc). Please note that Warcworker is not a crawler (it will not crawl a website automatically - you have to use other software to build lists of URL:s to send to Warcworker).
## Installation
Copy .env_example to .env. Update information in .env.
Start with `docker-compose up -d --scale worker=3` (wait a minute for everything to start up)
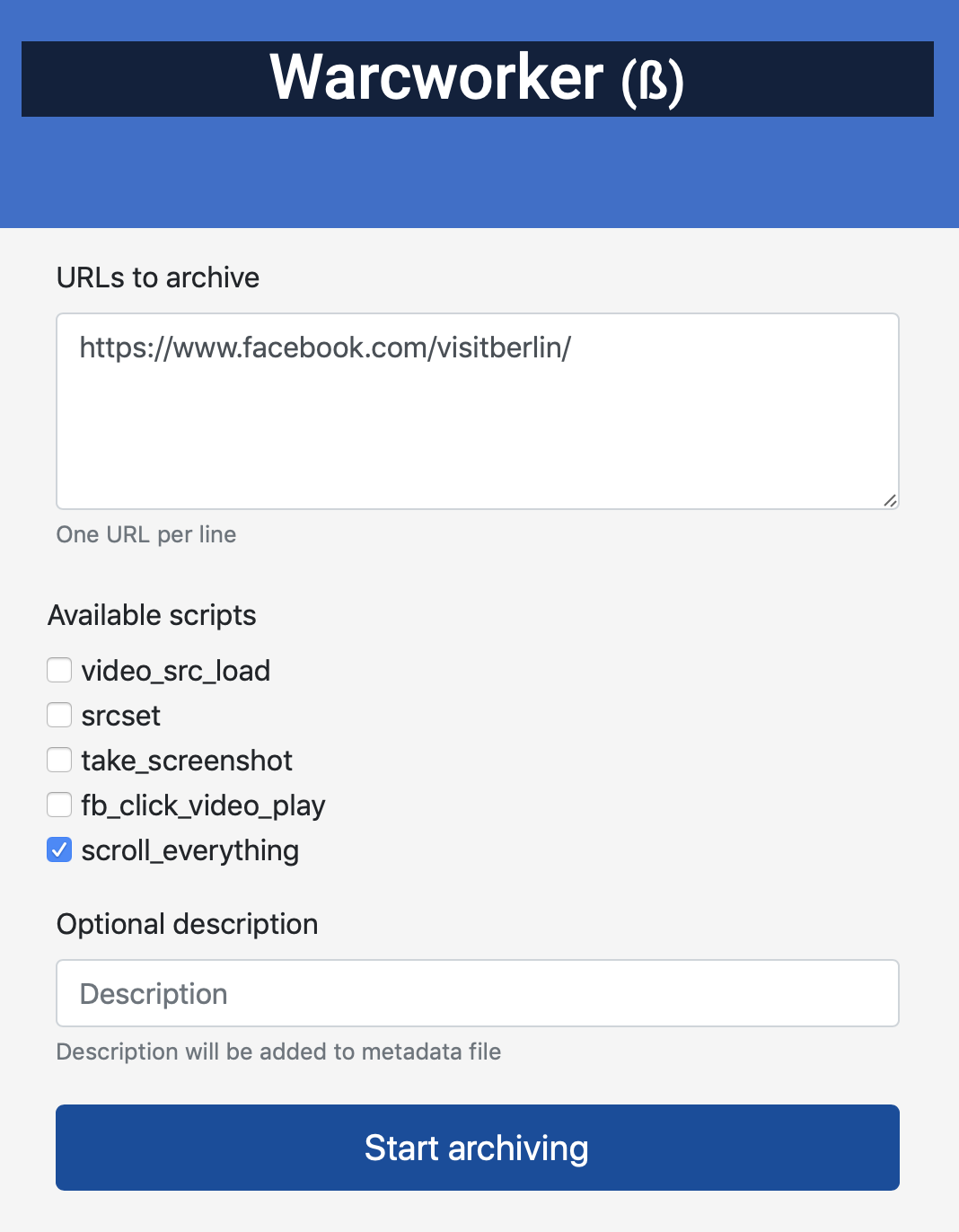
## Archiving and playback
Open web front end at http://0.0.0.0:5555 to enter URLs for archiving. You can prefill the text fields with the `url` and `description` request parameters. Play back the resulting WARC-files with [Webrecorder Player](https://github.com/webrecorder/webrecorderplayer-electron)
## Using
### Bookmarklet
Add a bookmarklet to your browser with the following link:
`javascript:window.open('http://0.0.0.0:5555?url='+encodeURIComponent(location.href) + '&description=' + encodeURIComponent(document.title));window.focus();`
Now you have two-click web archiving from your browser.
### Command line
To use from the command line with curl:
`curl -d "scripts=srcset&scripts=scroll_everything&url=https://www.peterkrantz.com/" -X POST http://0.0.0.0:5555/process/`
### Archivenow handler
To use from [archivenow](https://github.com/oduwsdl/archivenow) add a handler file `handlers/ww_handler.py` like this:
```python
import requests
import json
class WW_handler(object):
def __init__(self):
self.enabled = True
self.name = 'Warcworker'
self.api_required = False
def push(self, uri_org, p_args=[]):
msg = ''
try:
# add scripts in the order you want them to be run on the page
payload = {"url":uri_org, "scripts":["scroll_everything", "srcset"]}
r = requests.post('http://0.0.0.0:5555/process/', timeout=120,
data=payload,
allow_redirects=True)
r.raise_for_status()
return "%s added to queue" % uri_org
except Exception as e:
msg = "Error (" + self.name+ "): " + str(e)
return msg
```