Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/WenjieDu/TSDB
Time Series Data Beans: a Python toolbox loads 169 public time-series datasets for machine learning/deep learning with a single line of code.
https://github.com/WenjieDu/TSDB
classification database deep-learning forecasting imputation machine-learning partially-observed-time-series time-series time-series-analysis time-series-database time-series-datasets
Last synced: about 1 month ago
JSON representation
Time Series Data Beans: a Python toolbox loads 169 public time-series datasets for machine learning/deep learning with a single line of code.
- Host: GitHub
- URL: https://github.com/WenjieDu/TSDB
- Owner: WenjieDu
- License: bsd-3-clause
- Created: 2022-04-01T09:44:47.000Z (over 2 years ago)
- Default Branch: main
- Last Pushed: 2024-03-17T04:44:08.000Z (4 months ago)
- Last Synced: 2024-05-02T04:05:08.501Z (2 months ago)
- Topics: classification, database, deep-learning, forecasting, imputation, machine-learning, partially-observed-time-series, time-series, time-series-analysis, time-series-database, time-series-datasets
- Language: Python
- Homepage: https://pypots.com/ecosystem/#TSDB
- Size: 218 KB
- Stars: 113
- Watchers: 6
- Forks: 12
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
- Code of conduct: CODE_OF_CONDUCT.md
- Citation: CITATION.cff
Lists
- awesome-time-series - TSDB: A Python Toolbox to Ease Loading Open-Source Time-Series Datasets (supporting 119 datasets)
- awesome-time-series - TSDB - Series DataBase: A Python toolbox helping load time-series datasets easily. (📦 Packages / Python)
README

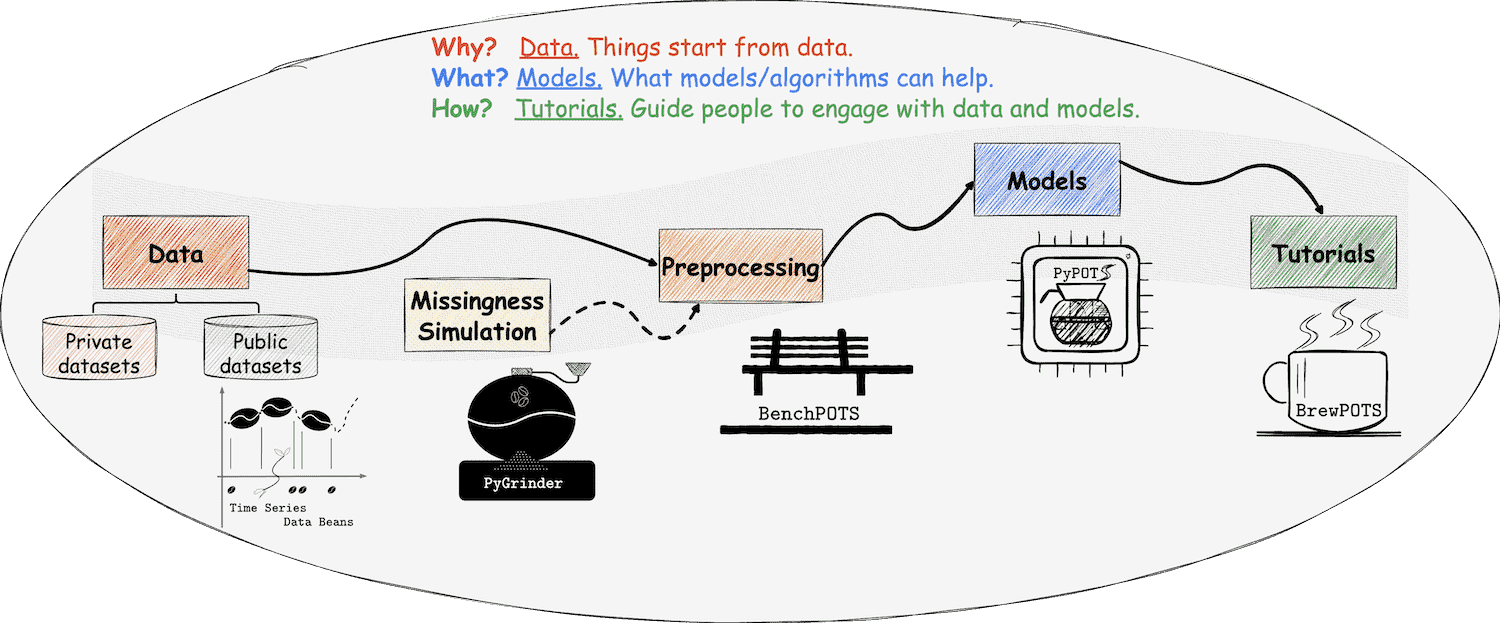
Welcome to TSDB
*
a Python toolbox to ease loading public time-series datasets
*













> 📣 TSDB now supports a total of 1️⃣6️⃣9️⃣ time-series datasets ‼️

TSDB is a part of
PyPOTS 
(a Python toolbox for data mining on Partially-Observed Time Series), and was separated from PyPOTS for decoupling datasets from learning algorithms.
TSDB is created to help researchers and engineers get rid of data collecting and downloading, and focus back on data processing details. TSDB provides all-in-one-stop convenience for downloading and loading open-source time-series datasets (available datasets listed [below](https://github.com/WenjieDu/TSDB#-list-of-available-datasets)).
❗️Please note that due to people have very different requirements for data processing, data-loading functions in TSDB only contain the most general steps (e.g. removing invalid samples) and won't process the data (not even normalize it). So, no worries, TSDB won't affect your data preprocessing. If you only want the raw datasets, TSDB can help you download and save raw datasets as well (take a look at [Usage Examples](https://github.com/WenjieDu/TSDB#-usage-example) below).
🤝 If you need TSDB to integrate an open-source dataset or want to add it into TSDB yourself, please feel free to request for it by creating an issue or make a PR to merge your code.
🤗 **Please** star this repo to help others notice TSDB if you think it is a useful toolkit.
**Please** properly [cite TSDB and PyPOTS](https://github.com/WenjieDu/TSDB#-citing-tsdbpypots) in your publications
if it helps with your research. This really means a lot to our open-source research. Thank you!
## ❖ Usage Examples
TSDB now is available on  ❗️
❗️
Install it with `conda install tsdb `, you may need to specify the channel with option `-c conda-forge`
or install via PyPI:
> pip install tsdb
or install from source code:
> pip install `https://github.com/WenjieDu/TSDB/archive/main.zip`
```python
import tsdb
# list all available datasets in TSDB
tsdb.list()
# select the dataset you need and load it, TSDB will download, extract, and process it automatically
data = tsdb.load('physionet_2012')
# if you need the raw data, use download_and_extract()
tsdb.download_and_extract('physionet_2012', './save_it_here')
# datasets you once loaded are cached, and you can check them with list_cached_data()
tsdb.list_cache()
# you can delete only one specific dataset and preserve others
tsdb.delete_cache(dataset_name='physionet_2012')
# or you can delete all cache with delete_cached_data() to free disk space
tsdb.delete_cache()
# to avoid taking up too much space if downloading many datasets,
# TSDB cache directory can be migrated to an external disk
tsdb.migrate_cache("/mnt/external_disk/TSDB_cache")
```
That's all. Simple and efficient. Enjoy it! 😃
## ❖ List of Available Datasets
| Name | Main Tasks |
|---------------------------------------------------------------------------------------------------|-----------------------------------------|
| [PhysioNet Challenge 2012](dataset_profiles/physionet_2012) | Forecasting, Imputation, Classification |
| [PhysioNet Challenge 2019](dataset_profiles/physionet_2019) | Forecasting, Imputation, Classification |
| [Beijing Multi-Site Air-Quality](dataset_profiles/beijing_multisite_air_quality) | Forecasting, Imputation |
| [Electricity Load Diagrams](dataset_profiles/electricity_load_diagrams) | Forecasting, Imputation |
| [Electricity Transformer Temperature (ETT)](dataset_profiles/electricity_transformer_temperature) | Forecasting, Imputation |
| [Vessel AIS](dataset_profiles/vessel_ais) | Forecasting, Imputation, Classification |
| [UCR & UEA Datasets](dataset_profiles/ucr_uea_datasets) (all 163 datasets) | Classification |
## ❖ Citing TSDB/PyPOTS
The paper introducing PyPOTS project is available on arXiv at [this URL](https://arxiv.org/abs/2305.18811),
and we are pursuing to publish it in prestigious academic venues, e.g. JMLR (track for
[Machine Learning Open Source Software](https://www.jmlr.org/mloss/)). If you use TSDB in your work,
please cite PyPOTS project as below and 🌟star this repository to make others notice this library. 🤗 Thank you!
``` bibtex
@article{du2023pypots,
title={{PyPOTS: a Python toolbox for data mining on Partially-Observed Time Series}},
author={Wenjie Du},
year={2023},
eprint={2305.18811},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2305.18811},
doi={10.48550/arXiv.2305.18811},
}
```
> Wenjie Du. (2023).
> PyPOTS: a Python toolbox for data mining on Partially-Observed Time Series.
> arXiv, abs/2305.18811.https://arxiv.org/abs/2305.18811
🏠 Visits
