Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/BBuf/how-to-optim-algorithm-in-cuda
how to optimize some algorithm in cuda.
https://github.com/BBuf/how-to-optim-algorithm-in-cuda
cuda llm
Last synced: 23 days ago
JSON representation
how to optimize some algorithm in cuda.
- Host: GitHub
- URL: https://github.com/BBuf/how-to-optim-algorithm-in-cuda
- Owner: BBuf
- Created: 2018-07-18T07:55:40.000Z (almost 6 years ago)
- Default Branch: master
- Last Pushed: 2024-05-18T14:44:14.000Z (about 1 month ago)
- Last Synced: 2024-05-18T15:40:46.870Z (about 1 month ago)
- Topics: cuda, llm
- Language: Cuda
- Homepage:
- Size: 406 KB
- Stars: 1,026
- Watchers: 16
- Forks: 87
- Open Issues: 4
-
Metadata Files:
- Readme: README.md
Lists
- my-awesome-stars - BBuf/how-to-optim-algorithm-in-cuda - how to optimize some algorithm in cuda. (Cuda)
- awesome-stars - BBuf/how-to-optim-algorithm-in-cuda - how to optimize some algorithm in cuda. (Cuda)
- awesome-cuda-tensorrt-fpga - BBuf/how-to-optim-algorithm-in-cuda - to-optim-algorithm-in-cuda?style=social"/> : This is a series of GPU optimization topics. Here we will introduce how to optimize the CUDA kernel in detail. I will introduce several basic kernel optimizations, including: elementwise, reduce, sgemv, sgemm, etc. The performance of these kernels is basically at or near the theoretical limit. (Learning Resources)
- awesome-cs-tutorial - https://github.com/BBuf/how-to-optim-algorithm-in-cuda
README
## how-to-optim-algorithm-in-cuda
> 我也维护了一个学习深度学习框架(PyTorch和OneFlow)的仓库 https://github.com/BBuf/how-to-learn-deep-learning-framework 以及一个如何学习深度学习编译器(TVM/MLIR/LLVM)的学习仓库 https://github.com/BBuf/tvm_mlir_learn , 有需要的小伙伴可以**点一点star**
本工程记录如何基于 cuda 优化一些常见的算法。请注意,下面的介绍都分别对应了子目录的代码实现,所以想复现性能的话请查看对应子目录下面的 README 。
### 0. how-to-compile-pytorch-from-source
记录如何手动编译 PyTorch 源码,学习 PyTorch 的一些 cuda 实现。
### 1. reduce
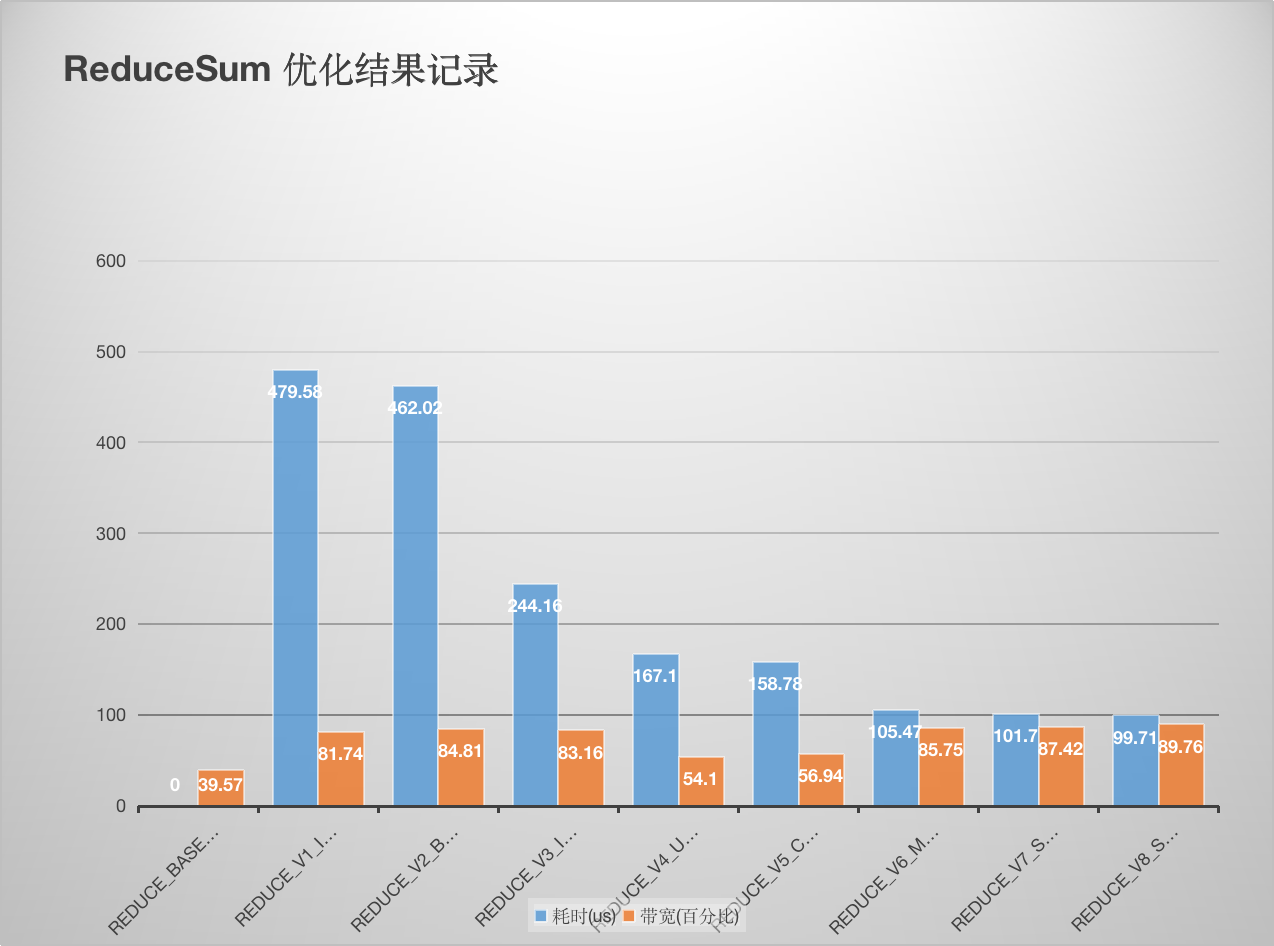
这里记录学习 NIVDIA 的[reduce优化官方博客](https://developer.download.nvidia.com/assets/cuda/files/reduction.pdf) 做的笔记。完整实验代码见[这里](https://github.com/BBuf/how-to-optim-algorithm-in-cuda/tree/master/reduce) , 原理讲解请看:[【BBuf的CUDA笔记】三,reduce优化入门学习笔记](https://zhuanlan.zhihu.com/p/596012674) 。后续又添加了 PyTorch BlockReduce 模板以及在这个模板的基础上额外加了一个数据 Pack ,又获得了一些带宽的提升。详细数据如下:
性能和带宽的测试情况如下 (A100 PCIE 40G):
### 2. elementwise
将 oneflow 的 elementwise 模板抽出来方便大家使用,这个 elementwise 模板实现了高效的性能和带宽利用率,并且用法非常灵活。完整实验代码见[这里](https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/elementwise/elementwise.cu) ,原理讲解请看:[【BBuf 的CUDA笔记】一,解析OneFlow Element-Wise 算子实现](https://zhuanlan.zhihu.com/p/591058808) 。这里以逐点乘为例,性能和带宽的测试情况如下 (A100 PCIE 40G):
|优化手段|数据类型|耗时(us)|带宽利用率|
|--|--|--|--|
|naive elementwise|float|298.46us|85.88%|
|oneflow elementwise|float|284us|89.42%|
|naive elementwise|half|237.28us|52.55%|
|oneflow elementwise|half|140.74us|87.31%|
可以看到无论是性能还是带宽,使用 oneflow 的 elementwise 模板相比于原始实现都有较大提升。
### 3. FastAtomicAdd
实现的脚本是针对half数据类型做向量的内积,用到了atomicAdd,保证数据的长度以及gridsize和blocksize都是完全一致的。一共实现了3个脚本:
1. https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/FastAtomicAdd/atomic_add_half.cu 纯half类型的atomicAdd。
2. https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/FastAtomicAdd/atomic_add_half_pack2.cu half+pack,最终使用的是half2类型的atomicAdd。
3. https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/FastAtomicAdd/fast_atomic_add_half.cu 快速原子加,虽然没有显示的pack,但本质上也是通过对单个half补0使用上了half2的原子加。
性能和带宽的测试情况如下 (A100 PCIE 40G):
|原子加方式|性能(us)|
|--|--|
|纯half类型|422.36ms|
|pack half2类型|137.02ms|
|fastAtomicAdd|137.01ms|
可以看到使用pack half的方式和直接使用half的fastAtomicAdd方式得到的性能结果一致,均比原始的half的原子加快3-4倍。
### 4. UpsampleNearest2D
upsample_nearest_2d.cu 展示了 oneflow 对 upsample_nearest2d 的前后向的优化 kernel 的用法,性能和带宽的测试情况如下 (A100 PCIE 40G):
|框架|数据类型|Op类型|带宽利用率|耗时|
|--|--|--|--|--|
| PyTorch | Float32 | UpsampleNearest2D forward | 28.30% | 111.42us |
| PyTorch | Float32 | UpsampleNearest2D backward | 60.16% | 65.12us |
| OneFlow | Float32 |UpsampleNearest2D forward | 52.18% | 61.44us |
| OneFlow | Float32 |UpsampleNearest2D backward | 77.66% | 50.56us |
| PyTorch | Float16 | UpsampleNearest2D forward | 16.99% | 100.38us |
| PyTorch | Float16 | UpsampleNearest2D backward | 31.56% | 57.38us |
| OneFlow | Float16 |UpsampleNearest2D forward | 43.26% | 35.36us |
| OneFlow | Float16 |UpsampleNearest2D backward | 44.82% | 40.26us |
可以看到基于 oneflow upsample_nearest2d 的前后向的优化 kernel 可以获得更好的带宽利用率和性能。注意这里的 profile 使用的是 oneflow 脚本,而不是 upsample_nearest_2d.cu ,详情请看 [UpsampleNearest2D/README.md](UpsampleNearest2D/README.md) 。
### 5. indexing
在 PyTorch 中对 index_add 做了极致的优化,我这里将 [PyTorch 的 index_add 实现](indexing/index_add_cuda_pytorch_impl.cu) 进行了剥离,方便大家应用于其它框架。具体请看 indexing 文件夹的 README 。其中还有和 oneflow 的 index_add 实现的各个 case 的性能比较结果。整体来说 PyTorch 在 index Tensor元素很小,但Tensor很大的情况下有较大的性能提升,其它情况和 OneFlow 基本持平。详情请看 [indexing/README.md](indexing/README.md) 。
### 6. oneflow-cuda-optimize-skills
OneFlow 深度学习框架中基于 cuda 做的优化工作,动态更新中。
### 7. FastTransformer
总结 FastTransformer 相关的 cuda 优化技巧。[README_BERT.md](FastTransformer/README_BERT.md) 总结了 BERT 相关的优化技巧。
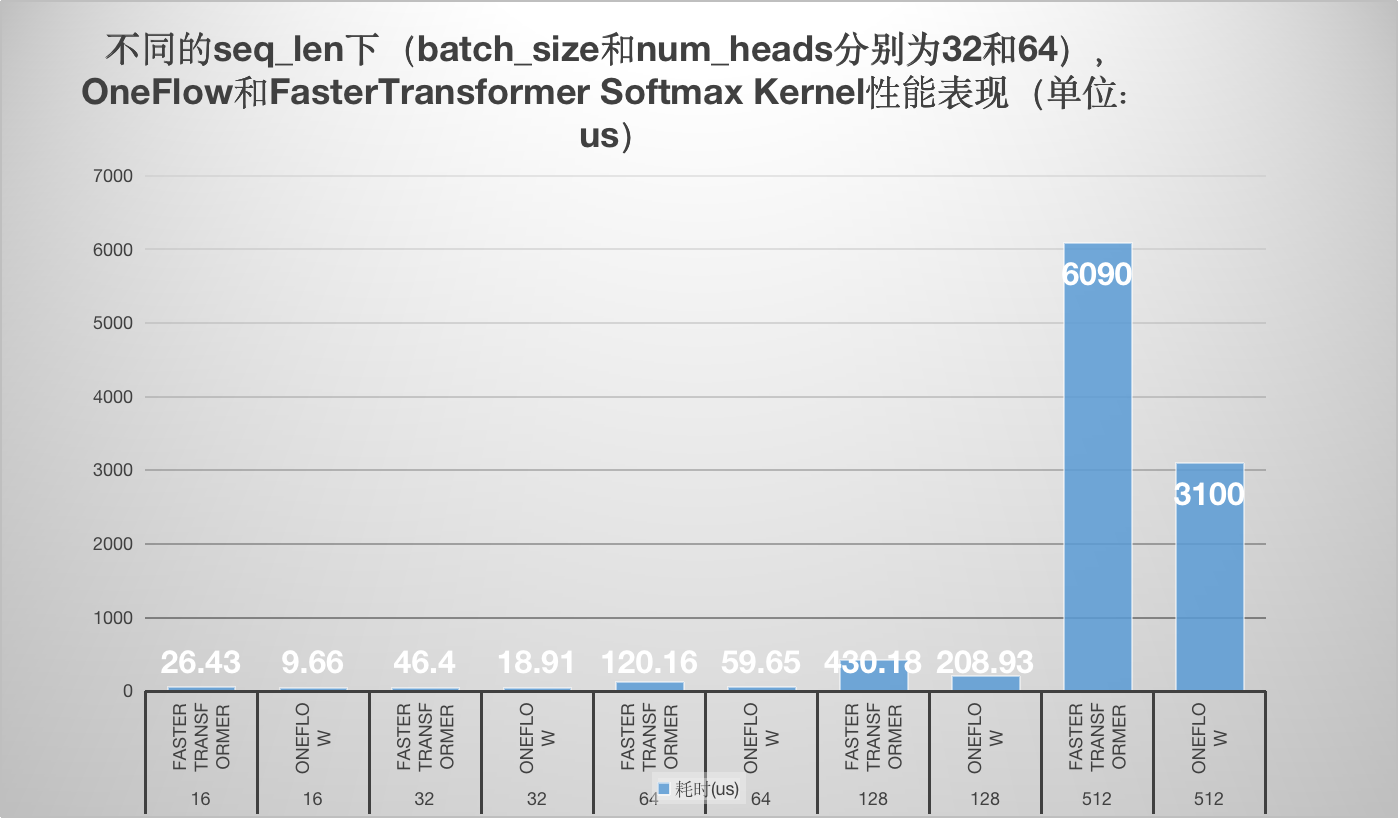
### 8. softmax
学习了oneflow的softmax kernel实现以及Faster Transformer softmax kernel的实现,并以个人的角度分别解析了原理和代码实现,最后对性能做一个对比方便大家直观的感受到oneflow softmax kernel相比于FasterTransformer的优越性。
### 9. linear-attention
学习一些 linear attention 的 cuda 优化技巧。
### 10. large-language-model-note
收集了和大语言模型原理,训练,推理,数据标注的相关文章。
### 11. mlsys-paper
前研的大模型训练相关 AI-Infra 论文收集以及阅读笔记。
### 12. triton
Triton 学习过程中的代码记录。
### 13. meagtron-lm
Meagtron-LM 学习笔记。
### 13. 原创学习笔记
- [【BBuf的CUDA笔记】一,解析OneFlow Element-Wise 算子实现](https://zhuanlan.zhihu.com/p/591058808)
- [【BBuf的CUDA笔记】二,解析 OneFlow BatchNorm 相关算子实现](https://zhuanlan.zhihu.com/p/593483751)
- [【BBuf的CUDA笔记】三,reduce优化入门学习笔记](https://zhuanlan.zhihu.com/p/596012674)
- [【BBuf的CUDA笔记】四,介绍三个高效实用的CUDA算法实现(OneFlow ElementWise模板,FastAtomicAdd模板,OneFlow UpsampleNearest2d模板)](https://zhuanlan.zhihu.com/p/597435971)
- [【BBuf的CUDA笔记】五,解读 PyTorch index_add 操作涉及的优化技术](https://zhuanlan.zhihu.com/p/599085070)
- [【BBuf的CUDA笔记】六,总结 FasterTransformer Encoder(BERT) 的cuda相关优化技巧](https://zhuanlan.zhihu.com/p/601130731)
- [【BBuf的CUDA笔记】七,总结 FasterTransformer Decoder(GPT) 的cuda相关优化技巧](https://zhuanlan.zhihu.com/p/603611192)
- [【BBuf的CUDA笔记】八,对比学习OneFlow 和 FasterTransformer 的 Softmax Cuda实现](https://zhuanlan.zhihu.com/p/609198294)
- [【BBuf的CUDA笔记】九,使用newbing(chatgpt)解析oneflow softmax相关的fuse优化](https://zhuanlan.zhihu.com/p/615619524)
- [CodeGeeX百亿参数大模型的调优笔记:比FasterTransformer更快的解决方案](https://zhuanlan.zhihu.com/p/617027615)
- [【BBuf的cuda学习笔记十】Megatron-LM的gradient_accumulation_fusion优化](https://mp.weixin.qq.com/s/neP8faIXIvj-XlyFjXjWBg)
- [【BBuf的CUDA笔记】十,Linear Attention的cuda kernel实现解析](https://mp.weixin.qq.com/s/1EPeU5hsOhB7rNAmmXrZRw)
- [【BBuf的CUDA笔记】十一,Linear Attention的cuda kernel实现补档](https://mp.weixin.qq.com/s/qDVKclf_AvpZ5qb2Obf4aA)
- [【BBuf的CUDA笔记】十二,LayerNorm/RMSNorm的重计算实现](https://mp.weixin.qq.com/s/G_XvnB4CeEBWTLNefi0Riw)
- [【BBuf的CUDA笔记】十三,OpenAI Triton 入门笔记一](https://mp.weixin.qq.com/s/RMR_n1n6nBqpdMl6tdd7pQ)
- [【BBuf的CUDA笔记】十四,OpenAI Triton入门笔记二](https://mp.weixin.qq.com/s/ZjADeYg5LCyGaLx0chpSZw)
- [【BBuf的CUDA笔记】十五,OpenAI Triton入门笔记三 FusedAttention](https://mp.weixin.qq.com/s/NKShFDrfDGsb0G6PAkUCGw)
- [AI Infra论文阅读之通过打表得到训练大模型的最佳并行配置](https://mp.weixin.qq.com/s/D-14J482SFQf-zh-EFa-1w)
- [AI Infra论文阅读之将流水线并行气泡几乎降到零(附基于Meagtron-LM的ZB-H1开源代码实现解读)](https://mp.weixin.qq.com/s/PXjYm9dN8C9B8svMQ7nOvw)
- [AI Infra论文阅读之LIGHTSEQ(LLM长文本训练的Infra工作)](https://mp.weixin.qq.com/s/u4gG1WZ73mgH9mEKQQCRww)
- [AI Infra论文阅读之《在LLM训练中减少激活值内存》](https://mp.weixin.qq.com/s/WRUmZT5NIbiHSnNrK1vLOw)
- [系统调优助手,PyTorch Profiler TensorBoard 插件教程](https://mp.weixin.qq.com/s/dG-wlwi8oLg8YMQe_A87qQ)
- [在GPU上加速RWKV6模型的Linear Attention计算](https://mp.weixin.qq.com/s/YXtvafdxB1rVeoy0qJmjyA)
- [flash-linear-attention的fused_recurrent_rwkv6 Triton实现精读](https://mp.weixin.qq.com/s/H6wWBxwIJNCzkIlH_uIuiw)
- [flash-linear-attention中的Chunkwise并行算法的理解](https://mp.weixin.qq.com/s/7utRk157_TFxF8gNRCyIyA)
### 14. 学习资料收集
#### 专栏
- [CUDA编程入门及优化 专栏by jie.hang](https://www.zhihu.com/column/c_1522503697624346624)
- [深入浅出GPU优化 专栏by 有了琦琦的棍子](https://www.zhihu.com/column/c_1437330196193640448)
- [CUDA 编程入门](https://www.zhihu.com/column/c_1699097150611595264)
#### 文章
- [如果你是一个C++面试官,你会问哪些问题?](https://www.zhihu.com/question/451327108/answer/3299498791)
- [推理部署工程师面试题库](https://zhuanlan.zhihu.com/p/673046520)
- [[C++特性]对std::move和std::forward的理解](https://zhuanlan.zhihu.com/p/469607144)
- [论文阅读:Mimalloc Free List Sharding in Action](https://zhuanlan.zhihu.com/p/665602526)
- [在 C++ 中,RAII 有哪些妙用?](https://zhuanlan.zhihu.com/p/687230917)
- [AI/HPC面试问题整理](https://zhuanlan.zhihu.com/p/663917237)
- [Roofline Model与深度学习模型的性能分析](https://zhuanlan.zhihu.com/p/34204282)
- [FlashAttention核心逻辑以及V1 V2差异总结](https://zhuanlan.zhihu.com/p/665170554)
- [flash attention 1和flash attention 2算法的python和triton实现](https://zhuanlan.zhihu.com/p/662759306)
- [Flash Attention 推公式](https://zhuanlan.zhihu.com/p/646697716)
- [图解大模型计算加速系列:FlashAttention V1,从硬件到计算逻辑](https://zhuanlan.zhihu.com/p/669926191)
- [flash attention完全解析和CUDA零基础实现](https://zhuanlan.zhihu.com/p/658947627)
- [FlashAttention图解(如何加速Attention)](https://zhuanlan.zhihu.com/p/626079753)
- [FlashAttention:加速计算,节省显存, IO感知的精确注意力](https://zhuanlan.zhihu.com/p/639228219)
- [FlashAttention 反向传播运算推导](https://zhuanlan.zhihu.com/p/631106302)
- [比标准Attention提速5-9倍,大模型都在用的FlashAttention v2来了](https://zhuanlan.zhihu.com/p/644324647)
- [FlashAttention 的速度优化原理是怎样的?](https://www.zhihu.com/question/611236756/answer/3134408839)
- [FlashAttention 的速度优化原理是怎样的?](https://www.zhihu.com/question/611236756/answer/3132304304)
- [FlashAttention2详解(性能比FlashAttention提升200%)](https://zhuanlan.zhihu.com/p/645376942)
- [FlashAttenion-V3: Flash Decoding详解](https://zhuanlan.zhihu.com/p/661478232)
- [速通PageAttention2](https://zhuanlan.zhihu.com/p/671293276)
- [PageAttention代码走读](https://zhuanlan.zhihu.com/p/668736097)
- [大模型推理加速之FlashDecoding++:野生Flash抵达战场](https://zhuanlan.zhihu.com/p/665361668)
- [学习Flash Attention和Flash Decoding的一些思考与疑惑](https://zhuanlan.zhihu.com/p/664704050)
- [大模型推理加速之Flash Decoding:更小子任务提升并行度](https://zhuanlan.zhihu.com/p/664264445)
- [FlashAttention与Multi Query Attention](https://zhuanlan.zhihu.com/p/640312259)
- [动手Attention优化1:Flash Attention 2优化点解析](https://zhuanlan.zhihu.com/p/634427617)
- [Flash Attention推理性能探究](https://zhuanlan.zhihu.com/p/652691133)
- [记录Flash Attention2-对1在GPU并行性和计算量上的一些小优化](https://zhuanlan.zhihu.com/p/650947918)
- [[LLM] FlashAttention 加速attention计算[理论证明|代码解读]](https://zhuanlan.zhihu.com/p/646084771)
- [FlashAttention核心逻辑以及V1 V2差异总结](https://zhuanlan.zhihu.com/p/665170554)
- [【手撕LLM-FlashAttention】从softmax说起,保姆级超长文!!](https://zhuanlan.zhihu.com/p/663932651)
- [动手Attention优化2:图解基于PTX的Tensor Core矩阵分块乘法实现](https://zhuanlan.zhihu.com/p/650374808)
- [flash attention 的几个要点](https://zhuanlan.zhihu.com/p/663381513)
- [GPU内存(显存)的理解与基本使用](https://zhuanlan.zhihu.com/p/462191421)
- [图文并茂,超详细解读nms cuda拓展源码](https://zhuanlan.zhihu.com/p/466169614)
- [大模型的好伙伴,浅析推理加速引擎FasterTransformer](https://zhuanlan.zhihu.com/p/626008090)
- [简单读读WeightOnly](https://zhuanlan.zhihu.com/p/622334595)
- [LLM Inference CookBook(持续更新)](https://zhuanlan.zhihu.com/p/619596323)
- [NVIDIA的custom allreduce](https://zhuanlan.zhihu.com/p/611229620)
- [[论文速读] FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness](https://zhuanlan.zhihu.com/p/548811565)
- [CUDA随笔之Stream的使用](https://zhuanlan.zhihu.com/p/51402722)
- [简单读读FasterTransformer](https://zhuanlan.zhihu.com/p/589442432)
- [cutlass FusedMultiheadAttention代码解读](https://zhuanlan.zhihu.com/p/600373700)
- [简单谈谈CUDA Reduce](https://zhuanlan.zhihu.com/p/559549740)
- [GridReduce - CUDA Reduce 部分结果归约](https://zhuanlan.zhihu.com/p/635456406)
- [CUTLASS: Fast Linear Algebra in CUDA C++](https://zhuanlan.zhihu.com/p/461060382)
- [cutlass源码导读(1)——API与设计理念](https://zhuanlan.zhihu.com/p/588953452)
- [cutlass源码导读(2)——Gemm的计算流程](https://zhuanlan.zhihu.com/p/592689326)
- [CUDA GroupNorm NHWC优化](https://zhuanlan.zhihu.com/p/596871310)
- [传统 CUDA GEMM 不完全指北](https://zhuanlan.zhihu.com/p/584236348)
- [怎么评估内存带宽的指标,并进行优化?](https://www.zhihu.com/question/424477202/answer/2322341112)
- [TensorRT Diffusion模型优化点](https://zhuanlan.zhihu.com/p/592713879)
- [NVIDIA GPU性能优化基础](https://zhuanlan.zhihu.com/p/577412348)
- [一文理解 PyTorch 中的 SyncBatchNorm](https://zhuanlan.zhihu.com/p/555881100)
- [如何开发机器学习系统:高性能GPU矩阵乘法](https://zhuanlan.zhihu.com/p/531498210)
- [CUDA SGEMM矩阵乘法优化笔记——从入门到cublas](https://zhuanlan.zhihu.com/p/518857175)
- [Dropout算子的bitmask优化](https://zhuanlan.zhihu.com/p/517766170)
- [面向 Tensor Core 的算子自动生成](https://zhuanlan.zhihu.com/p/502935328)
- [PICASSO论文学习](https://zhuanlan.zhihu.com/p/500026086)
- [CUDA翻译:How to Access Global Memory Efficiently in CUDA C/C++ Kernels](https://zhuanlan.zhihu.com/p/473133201)
- [CUDA Pro Tips翻译:Write Flexible Kernels with Grid-Stride Loops](https://zhuanlan.zhihu.com/p/472952257)
- [[施工中] CUDA GEMM 理论性能分析与 kernel 优化](https://zhuanlan.zhihu.com/p/441146275)
- [CUDA Ampere Tensor Core HGEMM 矩阵乘法优化笔记 —— Up To 131 TFLOPS!](https://zhuanlan.zhihu.com/p/555339335)
- [Nvidia Tensor Core-CUDA HGEMM优化进阶](https://zhuanlan.zhihu.com/p/639297098)
- [CUDA C++ Best Practices Guide Release 12.1笔记(一)](https://zhuanlan.zhihu.com/p/636103380)
- [CUDA 矩阵乘法终极优化指南](https://zhuanlan.zhihu.com/p/410278370)
- [如何用CUDA写有CuBLAS 90%性能的GEMM Kernel](https://zhuanlan.zhihu.com/p/631227862)
- [如何理解Nvidia英伟达的Multi-GPU多卡通信框架NCCL?](https://www.zhihu.com/question/63219175/answer/2768301153)
- [如何理解Nvidia英伟达的Multi-GPU多卡通信框架NCCL?](https://www.zhihu.com/question/63219175/answer/206697974)
- [如何理解Nvidia英伟达的Multi-GPU多卡通信框架NCCL?](https://www.zhihu.com/question/63219175/answer/3487108775)
- [使用FasterTransformer实现LLM分布式推理](https://zhuanlan.zhihu.com/p/644322962)
- [细粒度GPU知识点详细总结](https://zhuanlan.zhihu.com/p/349185459)
- [https://siboehm.com/articles/22/CUDA-MMM](https://siboehm.com/articles/22/CUDA-MMM)
- [【CUDA编程】OneFlow Softmax算子源码解读之BlockSoftmax](https://zhuanlan.zhihu.com/p/646998408)
- [【CUDA编程】OneFlow Softmax 算子源码解读之WarpSoftmax](https://zhuanlan.zhihu.com/p/646994689)
- [【CUDA编程】OneFlow Element-Wise 算子源码解读](https://zhuanlan.zhihu.com/p/646990764)
- [【CUDA编程】Faster Transformer v1.0 源码详解](https://zhuanlan.zhihu.com/p/647012855)
- [【CUDA编程】Faster Transformer v2.0 源码详解](https://zhuanlan.zhihu.com/p/650462095)
- [FasterTransformer Decoding 源码分析(七)-FFNLayer MoE(上篇)](https://zhuanlan.zhihu.com/p/670916589)
- [FasterTransformer Decoding 源码分析(八)-FFNLayer MoE(下篇)](https://zhuanlan.zhihu.com/p/672189305)
- [从roofline模型看CPU矩阵乘法优化](https://zhuanlan.zhihu.com/p/655421318)
- [性能优化的终极手段之 Profile-Guided Optimization (PGO)](https://zhuanlan.zhihu.com/p/652814504)
- [有没有大模型推理加速引擎FasterTransformer入门级教程?](https://www.zhihu.com/question/602468960/answer/3203088852)
- [深入浅出GPU优化系列:gemv优化](https://zhuanlan.zhihu.com/p/494144694)
- [NVIDIA Hopper架构TensorCore分析(4)](https://zhuanlan.zhihu.com/p/654067822)
- [GPU host+device的编译流程](https://zhuanlan.zhihu.com/p/655850951)
- [Tensor Core 优化半精度矩阵乘揭秘](https://zhuanlan.zhihu.com/p/658306956)
- [无痛CUDA实践:μ-CUDA 自动计算图生成](https://zhuanlan.zhihu.com/p/658080362)
- [CUDA(三):通用矩阵乘法:从入门到熟练](https://zhuanlan.zhihu.com/p/657632577)
- [自己写的CUDA矩阵乘法能优化到多快?](https://www.zhihu.com/question/41060378/answer/2645323107)
- [高效CUDA Scan算法浅析](https://zhuanlan.zhihu.com/p/499963645)
- [一次 CUDA Graph 调试经历](https://zhuanlan.zhihu.com/p/661451140)
- [CUDA中的radix sort算法](https://zhuanlan.zhihu.com/p/488016994)
- [NVIDIA Tensor Core微架构解析](https://zhuanlan.zhihu.com/p/660531822)
- [cutlass cute 101](https://zhuanlan.zhihu.com/p/660379052)
- [在GPU避免分支的方法](https://zhuanlan.zhihu.com/p/143571980)
- [Pytorch-CUDA从入门到放弃(二)](https://zhuanlan.zhihu.com/p/48463543)
- [腾讯机智团队分享--AllReduce算法的前世今生](https://zhuanlan.zhihu.com/p/79030485)
- [cute 之 Layout](https://zhuanlan.zhihu.com/p/661182311)
- [cute Layout 的代数和几何解释](https://zhuanlan.zhihu.com/p/662089556)
- [cute 之 GEMM流水线](https://zhuanlan.zhihu.com/p/665082713)
- [Using CUDA Warp-Level Primitives](https://zhuanlan.zhihu.com/p/664395938)
- [CUDA Pro Tip: Increase Performance with Vectorized Memory Access](https://zhuanlan.zhihu.com/p/666480387)
- [cute 之 简单GEMM实现](https://zhuanlan.zhihu.com/p/667521327)
- [cute 之 MMA抽象](https://zhuanlan.zhihu.com/p/663092747)
- [cute 之 Tensor](https://zhuanlan.zhihu.com/p/663093816)
- [cute Swizzle细谈](https://zhuanlan.zhihu.com/p/684250988)
- [基于 CUTE 的 GEMM 优化【2】—— 高效 GEMM 实现,超越 Cublas 20%](https://zhuanlan.zhihu.com/p/696028389)
- [CUDA单精度矩阵乘法(sgemm)优化笔记](https://zhuanlan.zhihu.com/p/638820727)
- [HPC(高性能计算第一篇) :一文彻底搞懂并发编程与内存屏障(第一篇)](https://zhuanlan.zhihu.com/p/670350655)
- [GPU CUDA 编程的基本原理是什么? 怎么入门?](https://www.zhihu.com/question/613405221/answer/3129776636)
- [如何入门 OpenAI Triton 编程?](https://www.zhihu.com/question/622685131/answer/3217107882)
- [CUDA(二):GPU的内存体系及其优化指南](https://zhuanlan.zhihu.com/p/654027980)
- [nvitop: 史上最强GPU性能实时监测工具](https://zhuanlan.zhihu.com/p/614024375)
- [使用Triton在模型中构建自定义算子](https://zhuanlan.zhihu.com/p/670326958)
- [CUDA笔记 内存合并访问](https://zhuanlan.zhihu.com/p/641639133)
- [GPGPU架构,编译器和运行时](https://zhuanlan.zhihu.com/p/592975749)
- [GPGPU的memory 体系理解](https://zhuanlan.zhihu.com/p/658081469)
- [nvlink那些事……](https://zhuanlan.zhihu.com/p/639228770)
- [对NVidia Hopper GH100 的一些理解](https://zhuanlan.zhihu.com/p/486224812)
- [黑科技:用cutlass进行低成本、高性能卷积算子定制开发](https://zhuanlan.zhihu.com/p/258931422)
- [乱谈Triton Ampere WMMA (施工中)](https://zhuanlan.zhihu.com/p/675925978)
- [可能是讲的最清楚的WeightonlyGEMM博客](https://zhuanlan.zhihu.com/p/675427125)
- [GPU 底层机制分析:kernel launch 开销](https://zhuanlan.zhihu.com/p/544492099)
- [GPU内存(显存)的理解与基本使用](https://zhuanlan.zhihu.com/p/462191421)
- [超越AITemplate,打平TensorRT,SD全系列模型加速框架stable-fast隆重登场](https://zhuanlan.zhihu.com/p/669610362)
- [[手把手带你入门CUTLASS系列] 0x00 cutlass基本认知---为什么要用cutlass](https://zhuanlan.zhihu.com/p/677616101)
- [[手把手带你入门CUTLASS系列] 0x02 cutlass 源码分析(一) --- block swizzle 和 tile iterator (附tvm等价code)](https://zhuanlan.zhihu.com/p/679929705)
- [[手把手带你入门CUTLASS系列] 0x03 cutlass 源码分析(二) --- bank conflict free 的shared memory layout (附tvm等价pass)](https://zhuanlan.zhihu.com/p/681966685)
- [[深入分析CUTLASS系列] 0x04 cutlass 源码分析(三) --- 多级流水线(software pipeline)](https://zhuanlan.zhihu.com/p/687397095)
- [GPU 内存概念浅析](https://zhuanlan.zhihu.com/p/651179378)
- [NV_GPU tensor core 算力/带宽/编程模型分析](https://zhuanlan.zhihu.com/p/638129792)
- [Nsight Compute - Scheduler Statistics](https://zhuanlan.zhihu.com/p/673770855)
- [NVidia GPU指令集架构-前言](https://zhuanlan.zhihu.com/p/686198447)
- [搞懂 CUDA Shared Memory 上的 bank conflicts 和向量化指令(LDS.128 / float4)的访存特点](https://zhuanlan.zhihu.com/p/690052715)
- [窥探Trition的lower(二)](https://zhuanlan.zhihu.com/p/695255185)
- [窥探Trition的lower(三)](https://zhuanlan.zhihu.com/p/696133729)
- [ops(2):SoftMax 算子的 CUDA 实现与优化](https://zhuanlan.zhihu.com/p/695307283)
- [cuda学习日记(6) nsight system / nsight compute](https://zhuanlan.zhihu.com/p/640344249)
- [ops(3):Cross Entropy 的 CUDA 实现](https://zhuanlan.zhihu.com/p/695594396)
- [cuda的ldmatrix指令的详细解释](https://zhuanlan.zhihu.com/p/697228676)
- [揭秘 Tensor Core 底层:如何让AI计算速度飞跃](https://mp.weixin.qq.com/s/UL7CLWp3cmdUgGILr4iVzA)
- [NCCL(NVIDIA Collective Communication Library)的来龙去脉](https://zhuanlan.zhihu.com/p/667221519)
- [ldmatrix与swizzle(笔记)](https://zhuanlan.zhihu.com/p/696231622)
- [GPU上GEMM的边界问题以及优化](https://zhuanlan.zhihu.com/p/699776368)
## Star History
