https://github.com/2227324689/production-faq
https://github.com/2227324689/production-faq
Last synced: 4 days ago
JSON representation
- Host: GitHub
- URL: https://github.com/2227324689/production-faq
- Owner: 2227324689
- Created: 2022-08-18T07:32:04.000Z (about 3 years ago)
- Default Branch: main
- Last Pushed: 2022-08-18T07:57:14.000Z (about 3 years ago)
- Last Synced: 2025-09-14T23:40:00.059Z (about 1 month ago)
- Size: 1000 Bytes
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# production-faq
生产环境遇到了问题,解决完就不管了? 那下次面试官问你难点的时候,你怎么回答?
工作中学习了新的东西,没有写总结? 那怎么会印象深刻?
程序上遇到了bug,你通过搜索引擎解决了,可是,下次再遇到,怎么办?
学会总结和沉淀,才能更好的成长,欢迎大家提交你们的成长和收获
## 模版要求
1. 逻辑清晰、言简意赅
2. 2000字以内
3. 复杂流程需要有图片表述
# 提交模版
## Mybatis是如何进行分页的
在工作上,遇到了分页的需求,当时用Mybatis-Plus自带的分页插件解决了
在空闲下来之后,特意去分析了Mybatis实现分页的原理如下:
数据进行分页是最基础的功能,一般可以把分页分成两类:
* 逻辑分页,先查询出所有的数据缓存到内存,再根据业务相关需求,从内存数据中筛选出合适的数据进行分页。
* 物理分页 ,直接利用数据库支持的分页语法来实现,比如Mysql里面提供了分页关键词Limit
Mybatis提供了四种分页方式:
* 在Mybatis Mapper配置文件里面直接写分页SQL,这种方式比较灵活,实现也简单。
* RowBounds实现逻辑分页,也就是一次性加载所有符合查询条件的目标数据,根据分页参数值在内存中实现分页。
当然,在数据量比较大的情况下,JDBC驱动本身会做一些优化,也就是不会把所有结果存储在ResultSet里面,
而是只加载一部分数据,再根据需求去数据库里面加载。
这种方式不适合数据量较大的场景,而且有可能会频繁访问数据库造成比较大的压力。
* Interceptor拦截器实现,通过拦截需要分页的select语句,然后在这个sql语句里面动态拼接分页关键字,从而实现分页查询。
(如图)Interceptor是Mybatis提供的一种针对不同生命周期的拦截器,比如:
* 拦截执行器方法
* 拦截参数的处理
* 拦截结果集的处理
* 拦截SQL语法构建的处理
我们可以拦截不同阶段的处理,来实现Mybatis相关功能的扩展。
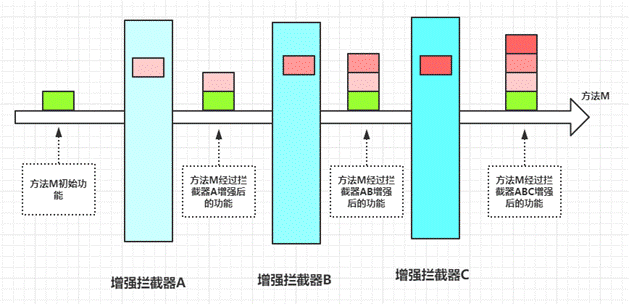
这种方式的好处,就是可以提供统一的处理机制,不需要我们再单独去维护分页相关的功能。
* 插件(PageHelper)及(MyBaits-Plus、tkmybatis)框架实现
这些插件本质上也是使用Mybatis的拦截器来实现的。
只是他们帮我们实现了扩展和封装,节省了分页扩展封装的工作量,在实际开发中,只需要拿来即用即可。
总结一下,对于任何ORM框架,分页的实现逻辑无外乎两种,不管怎么包装,最终给到开发者的,只是使用上
的差异而已。