https://github.com/42Shawn/LLaVA-PruMerge
LLaVA-PruMerge: Adaptive Token Reduction for Efficient Large Multimodal Models
https://github.com/42Shawn/LLaVA-PruMerge
Last synced: 5 months ago
JSON representation
LLaVA-PruMerge: Adaptive Token Reduction for Efficient Large Multimodal Models
- Host: GitHub
- URL: https://github.com/42Shawn/LLaVA-PruMerge
- Owner: 42Shawn
- License: apache-2.0
- Created: 2024-03-25T00:01:45.000Z (about 1 year ago)
- Default Branch: main
- Last Pushed: 2024-05-15T18:26:38.000Z (about 1 year ago)
- Last Synced: 2024-05-16T06:31:20.260Z (about 1 year ago)
- Language: Python
- Size: 11.7 MB
- Stars: 48
- Watchers: 2
- Forks: 2
- Open Issues: 4
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- awesome-token-merge-for-mllms - [Code
- awesome-token-merge-for-mllms - [Code
README
# LLaVA-PruMerge: Adaptive Token Reduction for Efficient Large Multimodal Models
[Yuzhang Shang](https://42shawn.github.io/)\*, [Mu Cai](https://pages.cs.wisc.edu/~mucai/)\*, Bingxin Xu, [Yong Jae Lee](https://pages.cs.wisc.edu/~yongjaelee/)^, [Yan Yan](https://tomyan555.github.io/)^
\*Equal Contribution, ^Equal Advising
[[Paper](https://arxiv.org/abs/2403.15388)] [[Project Page](https://llava-prumerge.github.io/)]
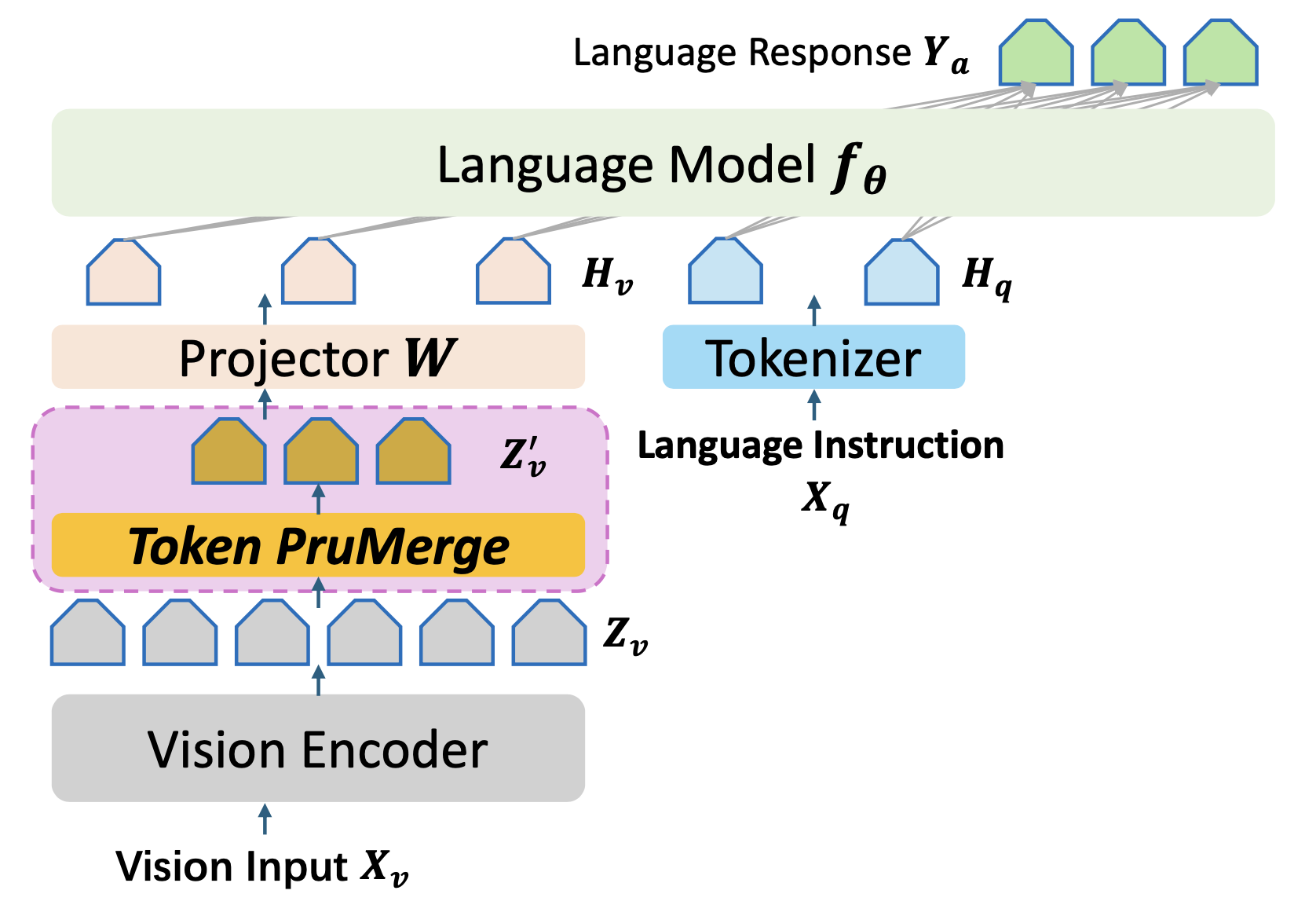
## How to run
### Step.0: Set the environment the same as LLaVA-1.5
Note that the core of our proposed module is [here](https://github.com/42Shawn/LLaVA-PruMerge/blob/main/llava/model/multimodal_encoder/clip_encoder.py#L85) in the CLIP image encoder.
### Step.1 (for inference): Download Checkpoints
Download the checkpoints (LoRA Version) from [Yuzhang's Huggingface Homepage](https://huggingface.co/yuzhang) to checkpoints/llava-v1.5-7b-lora-prunemerge.
### Step.2 (for inference): Change the methods (PruMerge or PruMerge+).
Change the call function of token reduction from [here](https://github.com/42Shawn/LLaVA-PruMerge/blob/main/llava/model/multimodal_encoder/clip_encoder.py#L295) in the CLIP image encoder.
### Step.3 (for inference): Run the script.
For example, the evaluation for TextVQA is:
```shell
CUDA_VISIBLE_DEVICES=7 XDG_CACHE_HOME='/data/shangyuzhang/' bash scripts/v1_5/eval/testvqa.sh
```
For other inference scripts, refer to [LLaVA Evaluation](https://github.com/haotian-liu/LLaVA/blob/main/docs/Evaluation.md).