Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/4kaforever11/images-speak
使用开源项目ComfyUI文生图+ChatTTs生成音频+SadTalker让图片说话,实现让自己的虚拟人图片说话
https://github.com/4kaforever11/images-speak
Last synced: 6 days ago
JSON representation
使用开源项目ComfyUI文生图+ChatTTs生成音频+SadTalker让图片说话,实现让自己的虚拟人图片说话
- Host: GitHub
- URL: https://github.com/4kaforever11/images-speak
- Owner: 4KAForever11
- Created: 2024-11-18T11:15:20.000Z (about 2 months ago)
- Default Branch: main
- Last Pushed: 2024-11-19T02:21:16.000Z (about 2 months ago)
- Last Synced: 2024-11-19T02:54:30.733Z (about 2 months ago)
- Homepage:
- Size: 4.88 MB
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
### ComfyUI文生图+ChatTTs生成音频+SadTalker让图片说话
让自己生成的虚拟人图片说话
[SadTalker-项目地址](https://github.com/OpenTalker/SadTalker?tab=readme-ov-file)
[SadTalker - 让照片说话安装教程](https://www.learnprompt.pro/zh-Hans/docs/ai-human-generators/sadtalker-speaking-photos/)
[ComfyUI项目地址](https://github.com/comfyanonymous/ComfyUI)
[ChatTTS-ui项目地址](https://github.com/jianchang512/ChatTTS-ui)
本人笔记本配置对于跑这个来说不高,跑起来有点吃力(显卡3060 6G显存,16G运行内存)
使用的clip模型:`t5xxl_fp8_e4m3fn.safetensors`和`clip_l.safetensors`
使用的Flux模型:`flux1-schnell.safetensors`
### 生成模型Flux.1
Flux 模型总共有3个,分别是:`Flux Pro`、`Flux Dev`、`Flux Schnell`
1. `[pro]` 是最顶级的模型,但是只能通过 API 调用;
2. `[dev]` 是由`[pro]`提炼,开源但非商用,质量和效果与`[pro]`类似;
3. `[schnell]` 是经过蒸馏的 4 步模型,速度比 `[dev]` 快 10 倍,Apache 2 开源许可。
### 安装使用ComfyUI生成真实的图片
1. 下载最新版 ComfyUI: [官方下载](https://github.com/comfyanonymous/ComfyUI) ,下载后解压出来待用
2. 设置中文语言:[点击下载](https://github.com/AIGODLIKE/AIGODLIKE-ComfyUI-Translation),中文语言包,将 ZIP 包解压到 ComfyUI\custom_nodes 目录中(英语好的可用跳过这一步)
3. 下载 Flux 模型:FLUX 模型有四个可选,FLUX.1 [dev] 、FLUX.1 [dev] fp8、FLUX.1 [schnell]、FLUX.1 [schnell] fp8;
- FLUX.1 [dev]:官方满配版,最低显存要求24G;[点击下载](https://huggingface.co/black-forest-labs/FLUX.1-dev/tree/main)
- FLUX.1 [dev] fp8:大佬优化[dev]后版本,最低12G显存可跑;[点击下载](https://huggingface.co/Kijai/flux-fp8/blob/main/flux1-dev-fp8.safetensors)
- FLUX.1 [schnell]:4步蒸馏模型,大多数显卡可跑。[点击下载](https://huggingface.co/black-forest-labs/FLUX.1-schnell/blob/main/flux1-schnell.safetensors)
- FLUX.1 [schnell] fp8:优化版本,适应更低的显卡配置[点击下载](https://huggingface.co/Kijai/flux-fp8/blob/main/flux1-schnell-fp8-e4m3fn.safetensors)
**不管你下载上面的哪个模型,都存放在这个:ComfyUI/models/unet/ 目录下**
4.下载 CLIP 模型:需下载 t5xxl_fp16.safetensors 或 t5xxl_fp8_e4m3fn.safetensors (建议选择fp8 版本,如果你显存超过 32G 可选择 fp16 版本)
还有 clip_l.safetensors 放到 ComfyUI/models/clip/ 目录中:[点击前往](https://huggingface.co/comfyanonymous/flux_text_encoders/tree/main)
5.下载 VAE 模型:[点击下载](https://huggingface.co/black-forest-labs/FLUX.1-schnell/blob/main/ae.safetensors) 存放至 ComfyUI/models/vae/ 目录
6.下载Lora 真人模型 [点击下载](https://pan.tuio.cc/s/KKYtL),放到ComfyUI/models/loras目录
7.下载工作流 [点击下载](https://pan.tuio.cc/s/qE2fL),使用的时候根据需要的版本选择工作流,打开了ComfyUI把工作流拖进去就可以使用
全部模型下载好,放到指定目录就可以在ComfyUI的文件根目录下运行cpu或者gpu的bat脚本来打开ComfyUI
打开之后把对应版本的工作流拖到ComfyUI的网页里面就会自动加载工作流
模型和我下载的一样的,这些选项和参数都和我一样就行

这里可以改生成图片的分辨率(也就是改宽度和高度)和一次要生成多少张图片(也就是改批次大小)
建议显存小于8G的分辨率不要设太高了
然后我们修改提示词让电脑给我们生成我们想要的图片就行了(提示词最好用英语,英语不好,中文翻译一下就好了)
这里我的提示词翻译过来就是:`这是一张高分辨率的照片,一个时尚的美女站在一个安静的图书馆里,她的皮肤晶莹剔透,匀称的脸,她的身材穿着柔软的针织毛衣和飘逸的裙子,她仔细阅读书架时的表情若有感触,她的姿势优雅而镇定`
英语:`This is a high-resolution photograph, a fashionable beauty with clear, dewy skin and a symmetrical face stands in a tranquil library, her figure adorned in a soft, cable-knit sweater and a flowing skirt, her expression thoughtful as she peruses the shelves, her posture elegant and poised,Young Asian woman.`

所有的设置都完成之后,点击右上角的【`添加提示词队列`】就开始文生图了,具体要跑多久出图主要还是看你的显卡和内存给不给力了
跑完之后右键保存图像就好了

看CMD的控制台显示我用我的笔记本生成这张分辨率为1024×1536的图片用了1552秒,大概25.8分钟将近26分钟(跑的确实很慢啊😂)

### ChatTTS-ui生成音频
windows版本 [一键包下载](https://github.com/jianchang512/chatTTS-ui/releases)
进入项目作者github发行页下载`v1.0完整包下载(1.7G含模型)`和最新的升级补丁包
下载完后解压这2个压缩包,然后把解压出来的补丁包里面的文件复制到v1.0完整包解压出来的文件夹根目录下面进行全部替换
默认将在第一次运行时自动下载模型,如果网络问题下载失败,请手动下载
GitHub 下载地址: https://github.com/jianchang512/ChatTTS-ui/releases/download/v1.0/all-models.7z
百度网盘下载: https://pan.baidu.com/s/1yGDZM9YNN7kW9e7SFo8lLw?pwd=ct5x
下载后解压后,会看到asset文件夹,该文件夹内有多个pt文件,将所有pt文件复制到本目录下,然后重启软件
最后点击根目录下的`app.exe`运行程序

在文本框输入想说的话和选择好想要的音色就行
ChatTTS可以通过设置提示词:口语化、 笑声、停顿,合理使用让合成的语音更加逼真自然!
口语化 :`[oral]`
笑声:`[laugh]`
停顿:`[break]`
使用的时候建议调整参数`temperature`为最低,这是生成音频的底噪,如果调太高背景音会很吵,很杂和把`跳过refine text`的对勾去掉,其他参数看自己进行调整(一般除了`音色相关`和`Prompt`之外都保持默认就好了)

### 安装SadTalker-让照片说话
#### 前置工作
**需要git,科学上网, python3.8+ 环境**
1. **下载ffmpeg**
打开[ffmpeg官网]([Download FFmpeg](https://ffmpeg.org/download.html)),然后点击`Windows`,选`gyan.dev`
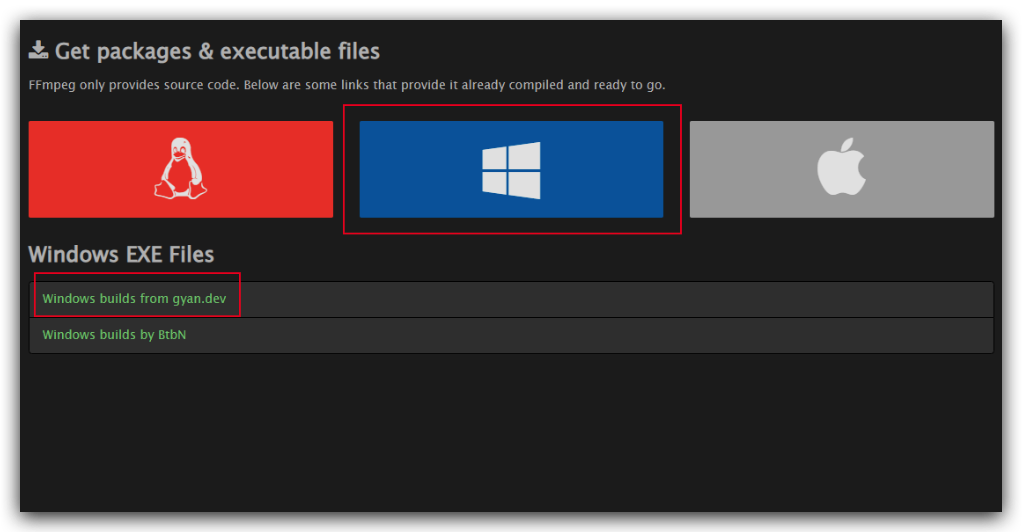
2.**下载Windows构建全版本的FFmpeg**
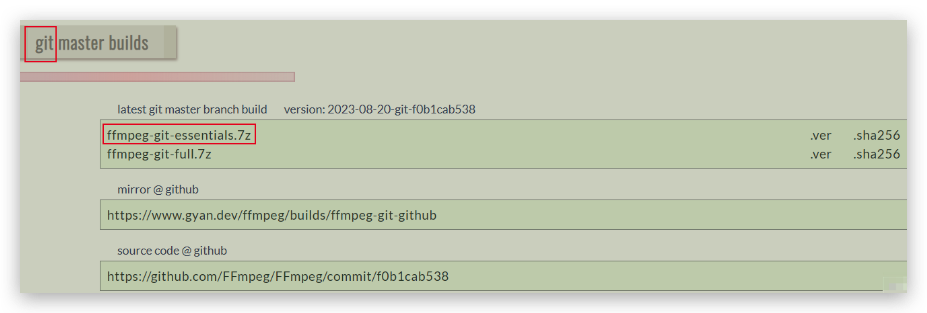
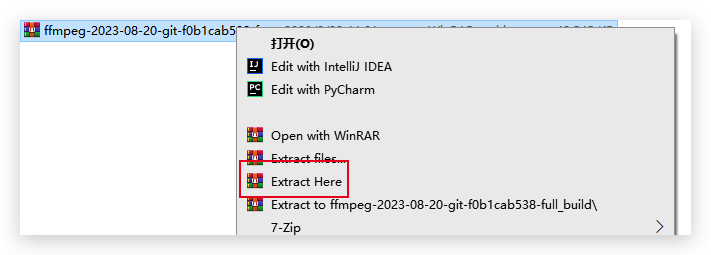
3. **解压,重命名解压后文件夹为FFmpeg**
p.s. 解压需要[安装7zip](https://www.7-zip.org/download.html),好用的轻量级压缩工具。
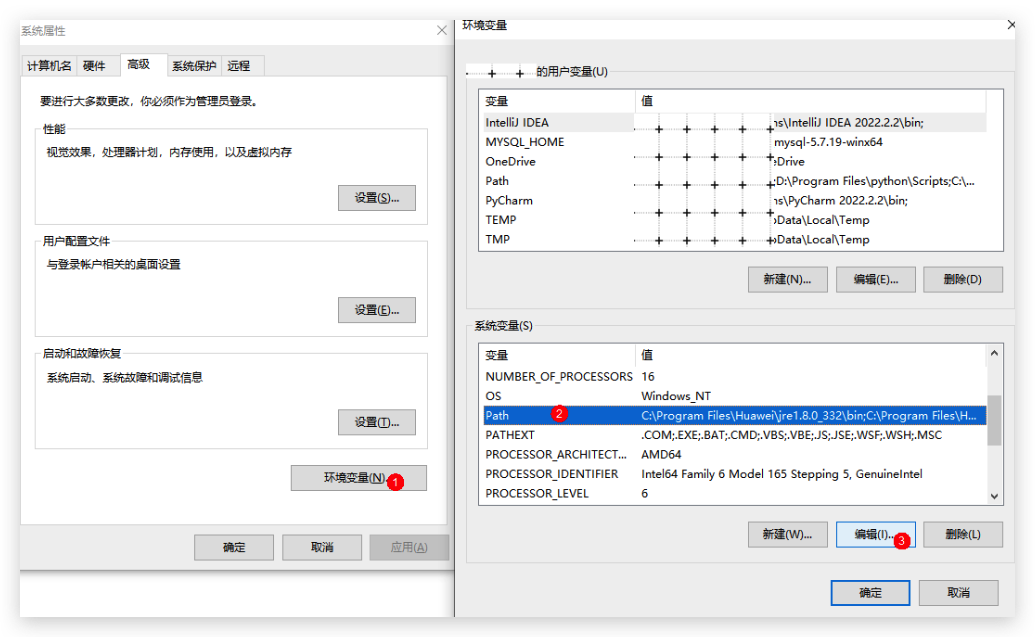
4. **配置PATH环境变量,添加完后记得点确定**
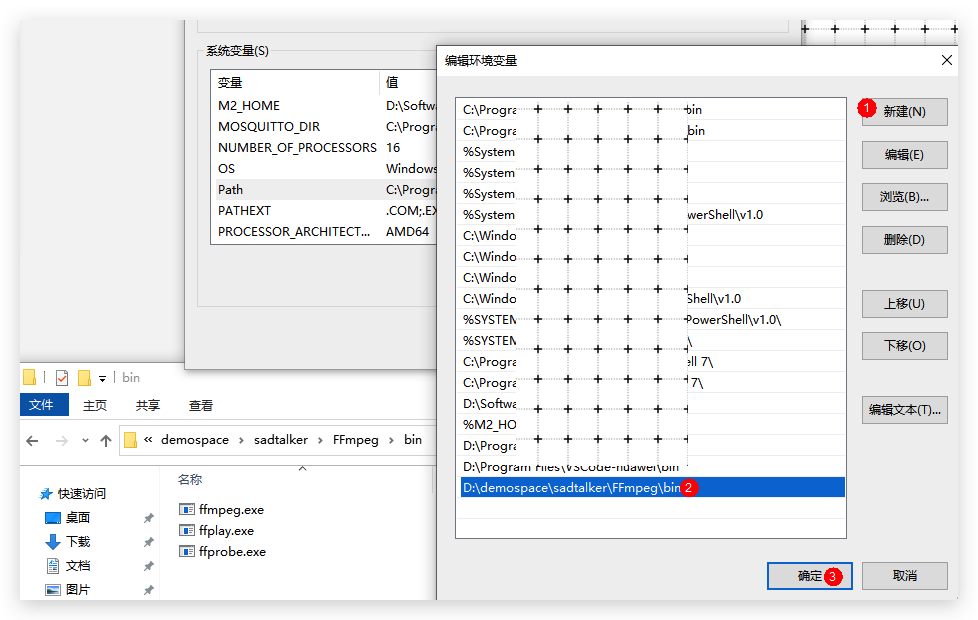
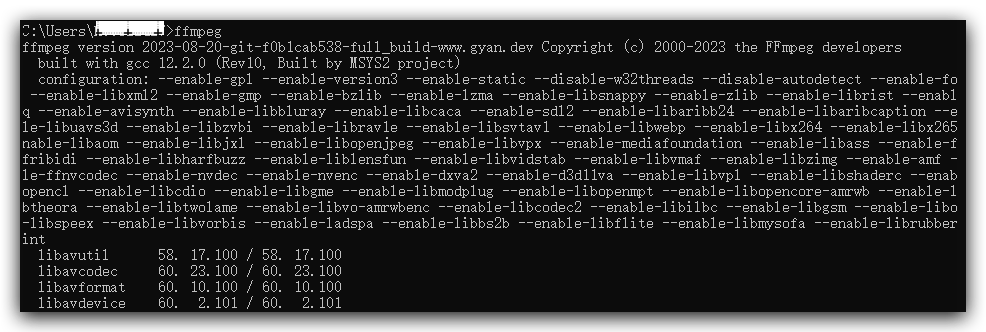
5. **检查是否安装成功**
`打开【命令提示符】,输入ffmpeg,如图所示`
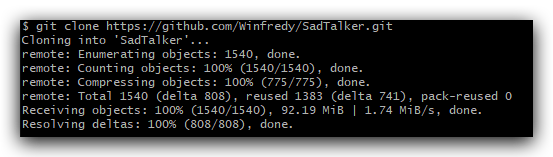
### **二、下载SadTalker代码**
如果电脑没有git下载去 [官网下载]([Git - Downloading Package](https://git-scm.com/downloads/win)) windows版的git,同样的设置系统环境变量之后在cmd里面进入你需要下载到目录里面再运行下面命令git仓库文件
`git clone https://github.com/Winfredy/SadTalker.git`
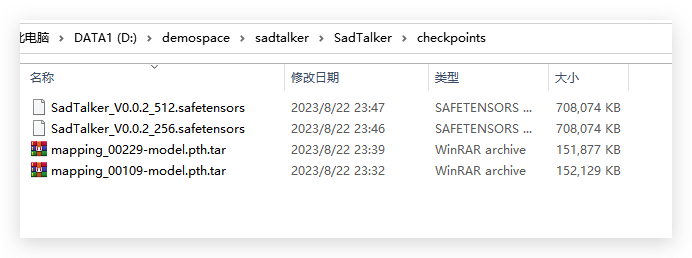
### 三、下载SadTalker模型文件
参照[《官方文档》](https://github.com/OpenTalker/SadTalker)有三种方式,其中百度网盘是不用翻墙的,模型文件涉及以下两个文件夹:
- [checkpoints](https://pan.baidu.com/s/1P4fRgk9gaSutZnn8YW034Q?pwd=sadt), 提取码: sadt
- [gfpgan](https://pan.baidu.com/s/1kb1BCPaLOWX1JJb9Czbn6w?pwd=sadt), 提取码: sadt
把下载好的模型文件放到checkpoints和weights下面
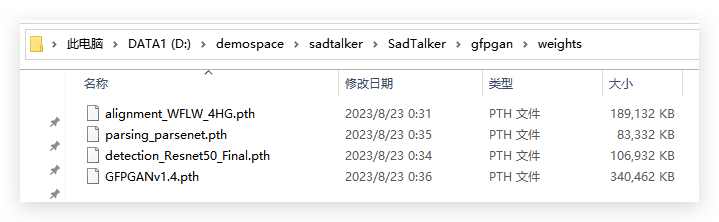
### 四、启动webUI
第一次运行需要下载依赖,会很慢
建议去自己下载好它需要的pytorch版本,手动安装,[点我下载](https://download.pytorch.org/whl/cu113/torch-1.12.1%2Bcu113-cp310-cp310-win_amd64.whl)
cmd进入`SadTalker\venv\Scripts`目录,然后pip install torch-1.12.1+cu113-cp310-cp310-win_amd64.whl
之后应该会有一个`gradio`库报错,因为默认安装最新版,这个错误是由于`Gradio`库的版本问题导致的。`gr.Row().style(equal_height=False)` 这种写法在较新的`Gradio`版本中可能不再适用
我们安装指定版本就行`pip install gradio==3.46.1`
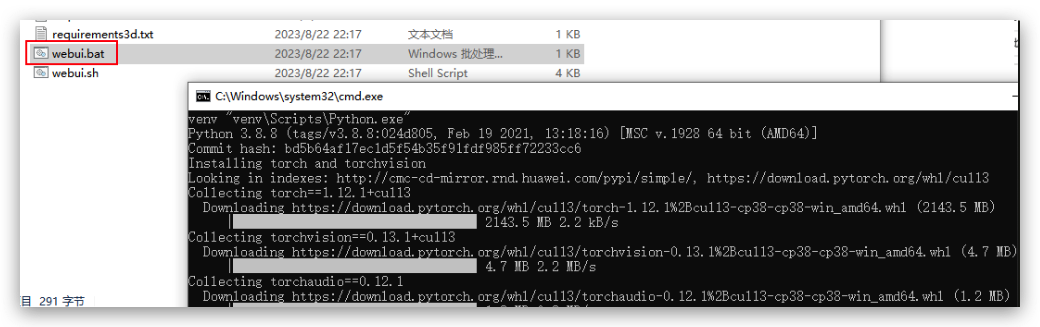
### 五、浏览器运行demo
默认地址为 127.0.0.1:7860,拖入图像和语音,点击Generate即可进行合成(注:`SadTalker/example`下有样例可以拖进来试)
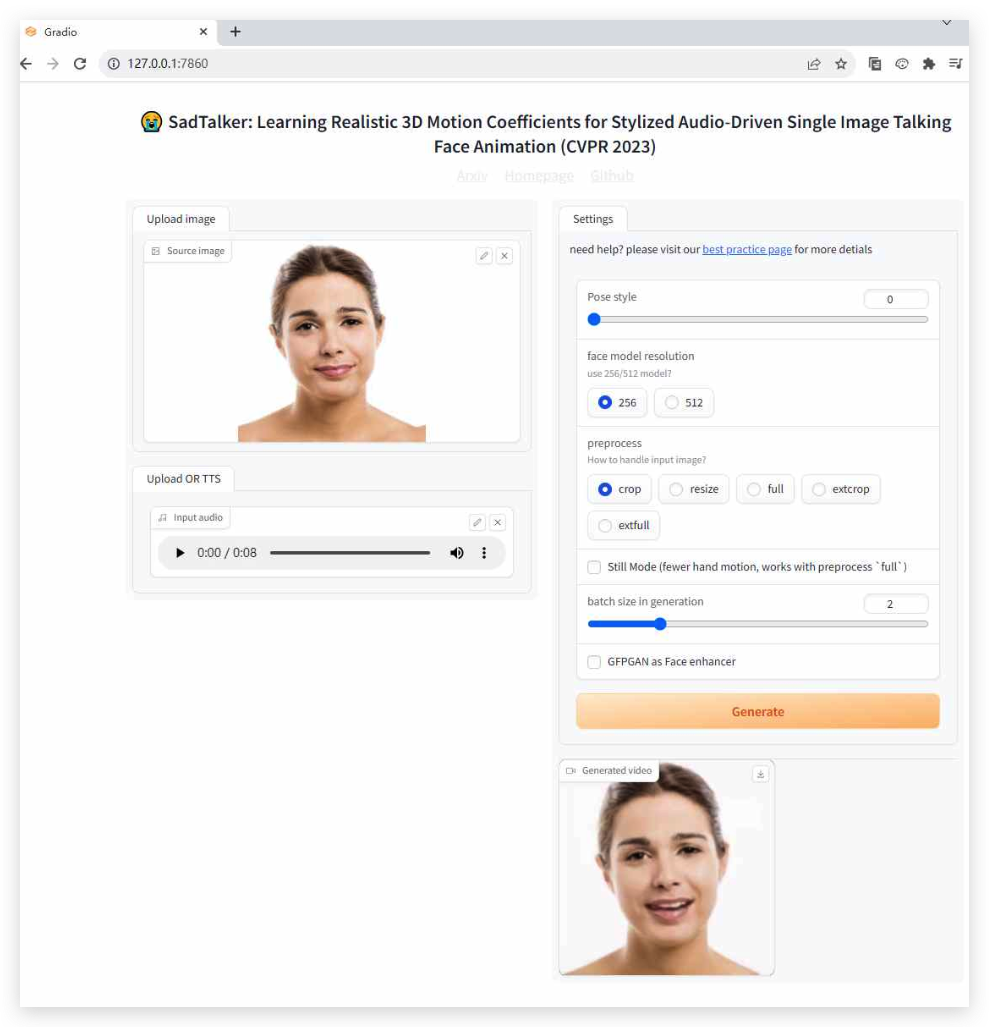
现在所有的项目都本地部署完成了,现在把我之前在`ComfyUI`生成的图片和`ChatTTs`生成的音频在`SadTalker`上传等待一会就会生成图片说话的视频了,不过我生成的音频没用女声,影响不大,后面用`ChatTTs`生成音频的时候记得换需要的音色就行
[成品演示视频](https://www.youtube.com/shorts/H4IK-rwcBE4)