https://github.com/Alpha-VLLM/Lumina-T2X
Lumina-T2X is a unified framework for Text to Any Modality Generation
https://github.com/Alpha-VLLM/Lumina-T2X
aigc diffusion diffusion-model diffusion-models diffusion-transformer generation-models transformer transformers
Last synced: over 1 year ago
JSON representation
Lumina-T2X is a unified framework for Text to Any Modality Generation
- Host: GitHub
- URL: https://github.com/Alpha-VLLM/Lumina-T2X
- Owner: Alpha-VLLM
- License: mit
- Created: 2024-03-28T13:23:28.000Z (over 2 years ago)
- Default Branch: main
- Last Pushed: 2024-08-06T02:20:09.000Z (almost 2 years ago)
- Last Synced: 2024-10-29T15:39:32.282Z (over 1 year ago)
- Topics: aigc, diffusion, diffusion-model, diffusion-models, diffusion-transformer, generation-models, transformer, transformers
- Language: Python
- Homepage:
- Size: 58 MB
- Stars: 2,062
- Watchers: 30
- Forks: 87
- Open Issues: 52
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- ai-game-devtools - Lumina-T2X - T2X is a unified framework for Text to Any Modality Generation. |[arXiv](https://arxiv.org/abs/2405.05945) | | Tool | (Project List / <span id="tool">LLM (LLM & Tool)</span>)
- AiTreasureBox - Alpha-VLLM/Lumina-T2X - 11-03_2236_0](https://img.shields.io/github/stars/Alpha-VLLM/Lumina-T2X.svg)|Lumina-T2X is a unified framework for Text to Any Modality Generation| (Repos)
README
# $\textbf{Lumina-T2X}$: Transforming Text into Any Modality, Resolution, and Duration via Flow-based Large Diffusion Transformers
###
ICLR 2025 Spotlight & NeurIPS 2024
[](https://arxiv.org/abs/2406.18583)
[](https://arxiv.org/abs/2405.05945)
[](https://arxiv.org/abs/2408.02657)
[](http://imagebind-llm.opengvlab.com/qrcode/)
[](https://mp.weixin.qq.com/s/NwwbaeRujh-02V6LRs5zMg)
[](https://www.zhihu.com/org/opengvlab)
[](https://twitter.com/opengvlab/status/1788949243383910804)

[](https://www.youtube.com/watch?v=K0-AJa33Rw4)
[](https://www.youtube.com/watch?v=KFtHmS5eUCM)
[-6B88E3?logo=youtubegaming&label=Demo%20Lumina-Next-SFT)](http://106.14.2.150:10020/)
[-6B88E3?logo=youtubegaming&label=Demo%20Lumina-Next-SFT)](http://106.14.2.150:10021/)
[-6B88E3?logo=youtubegaming&label=Demo%20Lumina-Next-SFT)](http://106.14.2.150:10022/)
[-6B88E3?logo=youtubegaming&label=Demo%20Lumina-Next-T2I)](http://106.14.2.150:10023/)
[-violet?logo=youtubegaming&label=Demo%20Lumina-Text2Music)](http://139.196.83.164:8000/)
[](https://huggingface.co/spaces/Alpha-VLLM/Lumina-Next-T2I)
[-purple?logoColor=#571482&label=%F0%9F%A4%97%20Lumina-Next-SFT%20checkpoints)](https://wisemodel.cn/models/Alpha-VLLM/Lumina-Next-SFT)
[-purple?logoColor=#571482&label=%F0%9F%A4%97%20Lumina-Next-SFT%20checkpoints)](https://wisemodel.cn/models/Alpha-VLLM/Lumina-Next-T2I)
[-yellow?logoColor=violet&label=%F0%9F%A4%97%20Lumina-Next-Diffusers%20checkpoints)](https://huggingface.co/Alpha-VLLM/Lumina-Next-SFT-diffusers)
[-yellow?logoColor=violet&label=%F0%9F%A4%97%20Lumina-Next-SFT%20checkpoints)](https://huggingface.co/Alpha-VLLM/Lumina-Next-SFT)
[-yellow?logoColor=violet&label=%F0%9F%A4%97%20Lumina-Next-T2I%20checkpoints)](https://huggingface.co/Alpha-VLLM/Lumina-Next-T2I)
[-yellow?logoColor=violet&label=%F0%9F%A4%97%20Lumina-T2I%20checkpoints)](https://huggingface.co/Alpha-VLLM/Lumina-T2I)

## 📰 News
- **[2024-08-06] 🎉🎉🎉 We have released [Lumina-mGPT](https://arxiv.org/abs/2408.02657), the next-generation of generative models in our Lumina family! Lumina-mGPT is an autoregressive transformer capable of photorealistic image generation and other vision-language tasks, e.g., controllable generation, multi-turn dialog, depth/normal/segmentation map estimation.**
- **[2024-07-08] 🎉🎉🎉 Lumina-Next is now supported in the [diffusers](https://github.com/huggingface/diffusers)! Thanks to [@yiyixuxu](https://github.com/yiyixuxu) and [@sayakpaul](https://github.com/sayakpaul)! [HF Model Repo](https://huggingface.co/Alpha-VLLM/Lumina-Next-SFT-diffusers).**
- [2024-06-26] We have released the inference code for img2img translation using `Lumina-Next-T2I`. [CODE](https://github.com/Alpha-VLLM/Lumina-T2X/tree/main/lumina_next_t2i_mini/scripts/sample_img2img.sh) [ComfyUI](https://github.com/kijai/ComfyUI-LuminaWrapper)
- [2024-06-21] 🥰🥰🥰 Lumina-Next has a jupyter nootbook for inference, thanks to [canenduru](https://github.com/camenduru)! [LINK](https://github.com/camenduru/Lumina-Next-jupyter)
- [2024-06-21] We have uploaded the `Lumina-Next-SFT` and `Lumina-Next-T2I` to [wisemodel.cn](https://wisemodel.cn/models). [wisemodel repo](https://wisemodel.cn/models/Alpha-VLLM/Lumina-Next-SFT)
- [2024-06-19] We have released the `Lumina-T2Audio` (Text-to-Audio) code and model for music generation. [MODEL](https://huggingface.co/Alpha-VLLM/Lumina-T2Audio)
- [2024-06-17] 🚀🚀🚀 We have support both inference and training (including Dreambooth) of SD3, implemented in our Lumina framework! [CODE](https://github.com/Alpha-VLLM/Lumina-T2X/tree/main/lumina_next_t2i_mini)
- **[2024-06-17] 🥰🥰🥰 Lumina-Next supports ComfyUI now, thanks to [Kijai](https://github.com/kijai)! [LINK](https://github.com/kijai/ComfyUI-LuminaWrapper)**
- **[2024-06-08] 🚀🚀🚀 We have released the `Lumina-Next-SFT` model, demonstrating better visual quality! [MODEL](https://huggingface.co/Alpha-VLLM/Lumina-Next-SFT)**
- [2024-06-07] We have released the `Lumina-T2Music` (Text-to-Music) code and model for music generation. [MODEL](https://huggingface.co/Alpha-VLLM/Lumina-T2Music) [DEMO](http://139.196.83.164:8000/)
- [2024-06-03] We have released the `Compositional Generation` version of `Lumina-Next-T2I`, which enables compositional generation with multiple captions for different regions. [model](https://huggingface.co/Alpha-VLLM/Lumina-Next-T2I). [DEMO](http://106.14.2.150:10023/)
- [2024-05-29] We updated the new `Lumina-Next-T2I` [Code](https://github.com/Alpha-VLLM/Lumina-T2X/tree/main/lumina_next_t2i) and [HF Model](https://huggingface.co/Alpha-VLLM/Lumina-Next-T2I). Supporting 2K Resolution image generation and Time-aware Scaled RoPE.
- [2024-05-25] We released training scripts for Flag-DiT and Next-DiT, and we have reported the comparison results between Next-DiT and Flag-DiT. [Comparsion Results](https://github.com/Alpha-VLLM/Lumina-T2X/blob/main/Next-DiT-ImageNet/README.md#results)
- [2024-05-21] Lumina-Next-T2I supports a higher-order solver. It can generate images in just 10 steps without any distillation. Try our demos [DEMO](http://106.14.2.150:10021/).
- [2024-05-18] We released training scripts for Lumina-T2I 5B. [README](https://github.com/Alpha-VLLM/Lumina-T2X/tree/main/lumina_t2i#training)
- [2024-05-16] ❗❗❗ We have converted the `.pth` weights to `.safetensors` weights. Please pull the latest code and use `demo.py` for inference.
- [2024-05-14] Lumina-Next now supports simple **text-to-music** generation ([examples](#text-to-music-generation)), **high-resolution (1024*4096) Panorama** generation conditioned on text ([examples](#panorama-generation)), and **3D point cloud** generation conditioned on labels ([examples](#point-cloud-generation)).
- [2024-05-13] We give [examples](#multilingual-generation) demonstrating Lumina-T2X's capability to support **multilingual prompts**, and even support prompts containing **emojis**.
- **[2024-05-12] We excitedly released our `Lumina-Next-T2I` model ([checkpoint](https://huggingface.co/Alpha-VLLM/Lumina-Next-T2I)) which uses a 2B Next-DiT model as the backbone and Gemma-2B as the text encoder. Try it out at [demo1](http://106.14.2.150:10020/) & [demo2](http://106.14.2.150:10021/) & [demo3](http://106.14.2.150:10022/). Please refer to the paper [Lumina-Next](assets/lumina-next.pdf) for more details.**
- [2024-05-10] We released the technical report on [arXiv](https://arxiv.org/abs/2405.05945).
- [2024-05-09] We released `Lumina-T2A` (Text-to-Audio) Demos. [Examples](#text-to-audio-generation)
- [2024-04-29] We released the 5B model [checkpoint](https://huggingface.co/Alpha-VLLM/Lumina-T2I) and demo built upon it for text-to-image generation.
- [2024-04-25] Support 720P video generation with arbitrary aspect ratio. [Examples](#text-to-video-generation)
- [2024-04-19] Demo examples released.
- [2024-04-05] Code released for `Lumina-T2I`.
- [2024-04-01] We release the initial version of `Lumina-T2I` for text-to-image generation.
## 🚀 Quick Start
> [!Warning]
> **Since we are updating the code frequently, please pull the latest code:**
>
> ```bash
> git pull origin main
> ```
### Fast Demo
We have supported Lumina-Next in the [diffusers](https://github.com/huggingface/diffusers).
> [!Note]
> You should install the development version of diffusers (`main` branch) before diffusers releasing the new version.
> ```bash
> pip install git+https://github.com/huggingface/diffusers
and you can try the code below:
```python
from diffusers import LuminaText2ImgPipeline
import torch
pipeline = LuminaText2ImgPipeline.from_pretrained(
"/mnt/hdd1/xiejunlin/checkpoints/Lumina-Next-SFT-diffusers", torch_dtype=torch.bfloat16
).to("cuda")
image = pipeline(prompt="Upper body of a young woman in a Victorian-era outfit with brass goggles and leather straps. Background shows an industrial revolution ciyscape with smoky skies and tall, metal structures", height=1024, width=768).images[0]
```
For more details about training and inference of Lumina framework, please refer to [Lumina-T2I](./lumina_t2i/README.md#Installation), [Lumina-Next-T2I](./lumina_next_t2i/README.md#Installation), and [Lumina-Next-T2I-Mini](./lumina_next_t2i_mini/README.md#Installation). We highly recommend you to use the **[Lumina-Next-T2I-Mini](./lumina_next_t2i_mini/README.md#Installation)** for training and inference, which is an extremely simplified version of Lumina-Next-T2I with full functionalities.
### GUI Demo
In order to quickly get you guys using our model, we built different versions of the GUI demo site.
#### Lumina-Next-T2I model demo:
Image Generation: [[node1](http://106.14.2.150:10020/)] [[node2](http://106.14.2.150:10021/)] [[node3](http://106.14.2.150:10022/)]
Image Compositional Generation: [[node1](http://106.14.2.150:10023/)]
Music Generation: [[node1](http://139.196.83.164:8000)]
### Installation
Using `Lumina-T2X` as a library, using installation command on your environment:
```bash
pip install git+https://github.com/Alpha-VLLM/Lumina-T2X
```
### Development
If you want to contribute to the code, you should run command below to install `pre-commit` library:
```bash
git clone https://github.com/Alpha-VLLM/Lumina-T2X
cd Lumina-T2X
pip install -e ".[dev]"
pre-commit install
pre-commit
```
## 📑 Open-source Plan
- [X] Lumina-Text2Image (Demos✅, Training✅, Inference✅, Checkpoints✅, Diffusers✅)
- [ ] Lumina-Text2Video (Demos✅)
- [X] Lumina-Text2Music (Demos✅, Inference✅, Checkpoints✅)
- [X] Lumina-Text2Audio (Demos✅, Inference✅, Checkpoints✅)
## 📜 Index of Content
- [$\\textbf{Lumina-T2X}$: Transforming Text into Any Modality, Resolution, and Duration via Flow-based Large Diffusion Transformers](#textbflumina-t2x-transforming-text-into-any-modality-resolution-and-duration-via-flow-based-large-diffusion-transformers)
- [📰 News](#-news)
- [🚀 Quick Start](#-quick-start)
- [GUI Demo](#gui-demo)
- [Lumina-Next-T2I model demo:](#lumina-next-t2i-model-demo)
- [Installation](#installation)
- [Development](#development)
- [📑 Open-source Plan](#-open-source-plan)
- [📜 Index of Content](#-index-of-content)
- [Introduction](#introduction)
- [📽️ Demo Examples](#️-demo-examples)
- [Demos of Lumina-Next-SFT](#demos-of-lumina-next-sft)
- [Demos of Lumina-T2I](#demos-of-lumina-t2i)
- [Panorama Generation](#panorama-generation)
- [Text-to-Video Generation](#text-to-video-generation)
- [Text-to-3D Generation](#text-to-3d-generation)
- [Point Cloud Generation](#point-cloud-generation)
- [Text-to-Audio Generation](#text-to-audio-generation)
- [Text-to-music Generation](#text-to-music-generation)
- [Multilingual Generation](#multilingual-generation)
- [⚙️ Diverse Configurations](#️-diverse-configurations)
- [Contributors](#contributors)
- [📄 Citation](#-citation)
## Introduction
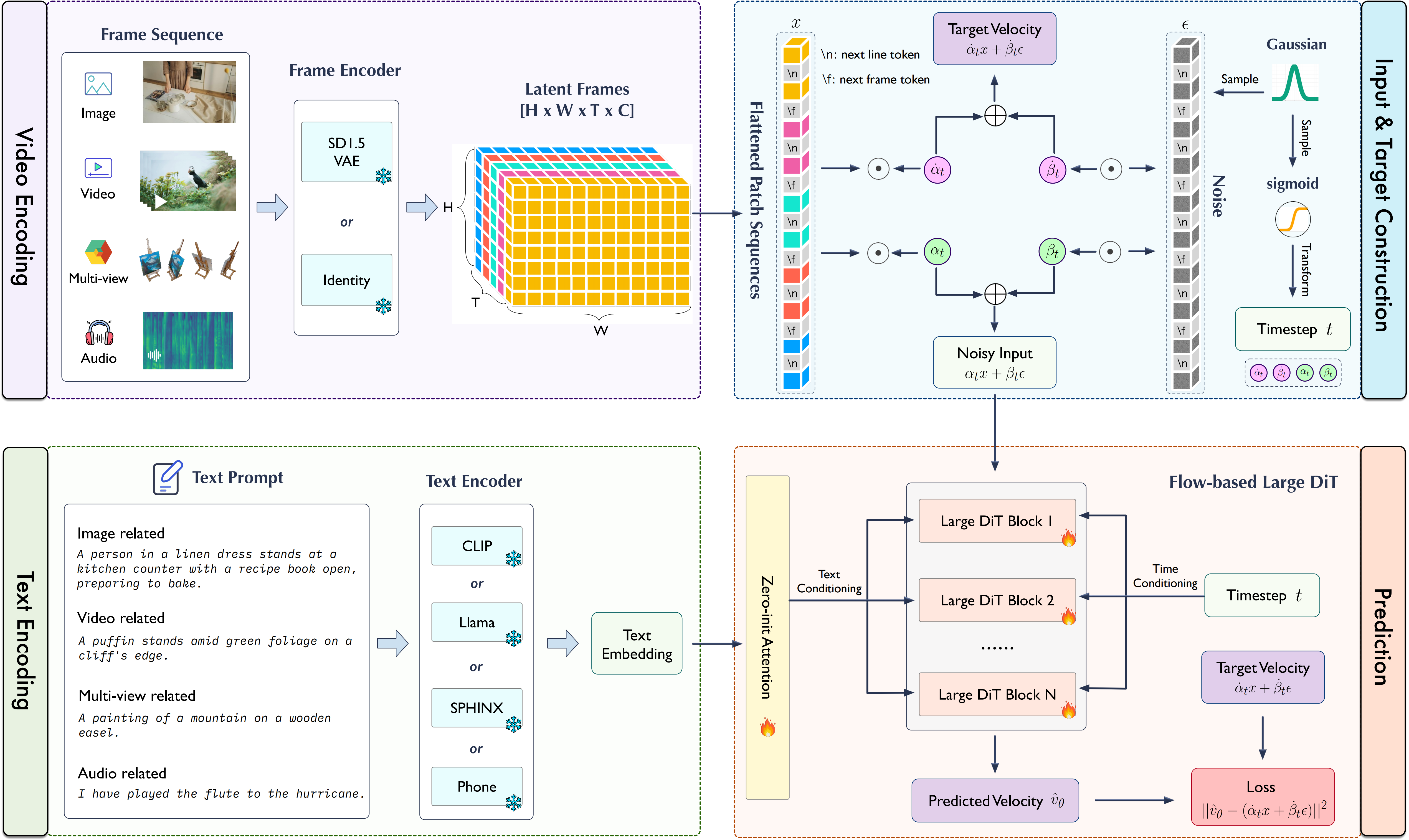
We introduce the $\textbf{Lumina-T2X}$ family, a series of text-conditioned Diffusion Transformers (DiT) capable of transforming textual descriptions into vivid images, dynamic videos, detailed multi-view 3D images, and synthesized speech. At the core of Lumina-T2X lies the **Flow-based Large Diffusion Transformer (Flag-DiT)**—a robust engine that supports up to **7 billion parameters** and extends sequence lengths to **128,000** tokens. Drawing inspiration from Sora, Lumina-T2X integrates images, videos, multi-views of 3D objects, and speech spectrograms within a spatial-temporal latent token space, and can generate outputs at **any resolution, aspect ratio, and duration**.
🌟 **Features**:
- **Flow-based Large Diffusion Transformer (Flag-DiT)**: Lumina-T2X adopts the **flow matching** formulation and is equipped with many advanced techniques, such as RoPE, RMSNorm, and KQ-norm, **demonstrating faster training convergence, stable training dynamics, and a simplified pipeline**.
- **Any Modalities, Resolution, and Duration within One Framework**:
1. $\textbf{Lumina-T2X}$ can **encode any modality, including mages, videos, multi-views of 3D objects, and spectrograms into a unified 1-D token sequence at any resolution, aspect ratio, and temporal duration.**
2. By introducing the `[nextline]` and `[nextframe]` tokens, our model can **support resolution extrapolation**, i.e., generating images/videos with out-of-domain resolutions **not encountered during training**, such as images from 768x768 to 1792x1792 pixels.
- **Low Training Resources**: Our empirical observations indicate that employing larger models,
high-resolution images, and longer-duration video clips can **significantly accelerate the convergence**
**speed** of diffusion transformers. Moreover, by employing meticulously curated text-image and text-video pairs featuring high aesthetic quality frames and detailed captions, our $\textbf{Lumina-T2X}$ model is learned to generate high-resolution images and coherent videos with minimal computational demands. Remarkably, the default Lumina-T2I configuration, equipped with a 5B Flag-DiT and a 7B LLaMA as the text encoder, **requires only 35% of the computational resources compared to Pixelart-**$\alpha$.
## 📽️ Demo Examples
### Demos of Lumina-Next-SFT

### Demos of Visual Anagrams


### Demos of Lumina-T2I

#### Panorama Generation

### Text-to-Video Generation
**720P Videos:**
**Prompt:** The majestic beauty of a waterfall cascading down a cliff into a serene lake.
https://github.com/Alpha-VLLM/Lumina-T2X/assets/54879512/17187de8-7a07-49a8-92f9-fdb8e2f5e64c
https://github.com/Alpha-VLLM/Lumina-T2X/assets/54879512/0a20bb39-f6f7-430f-aaa0-7193a71b256a
**Prompt:** A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. She wears a black leather jacket, a long red dress, and black boots, and carries a black purse. She wears sunglasses and red lipstick. She walks confidently and casually. The street is damp and reflective, creating a mirror effect of the colorful lights. Many pedestrians walk about.
https://github.com/Alpha-VLLM/Lumina-T2X/assets/54879512/7bf9ce7e-f454-4430-babe-b14264e0f194
**360P Videos:**
https://github.com/Alpha-VLLM/Lumina-T2X/assets/54879512/d7fec32c-3655-4fd1-aa14-c0cb3ace3845
### Text-to-3D Generation
https://github.com/Alpha-VLLM/Lumina-T2X/assets/54879512/cd061b8d-c47b-4c0c-b775-2cbaf8014be9
#### Point Cloud Generation

### Text-to-Audio Generation
> [!Note]
> **Attention: Mouse over the playbar and click the audio button on the playbar to unmute it.**
**Prompt:** Semiautomatic gunfire occurs with slight echo
**Generated Audio:**
https://github.com/Alpha-VLLM/Lumina-T2X/assets/54879512/25f2a6a8-0386-41e8-ab10-d1303554b944
**Groundtruth:**
https://github.com/Alpha-VLLM/Lumina-T2X/assets/54879512/6722a68a-1a5a-4a44-ba9c-405372dc27ef
**Prompt:** A telephone bell rings
**Generated Audio:**
https://github.com/Alpha-VLLM/Lumina-T2X/assets/54879512/7467dd6d-b163-4436-ac5b-36662d1f9ddf
**Groundtruth:**
https://github.com/Alpha-VLLM/Lumina-T2X/assets/54879512/703ea405-6eb4-4161-b5ff-51a93f81d013
**Prompt:** An engine running followed by the engine revving and tires screeching
**Generated Audio:**
https://github.com/Alpha-VLLM/Lumina-T2X/assets/54879512/5d9dd431-b8b4-41a0-9e78-bb0a234a30b9
**Groundtruth:**
https://github.com/Alpha-VLLM/Lumina-T2X/assets/54879512/9ca4af9e-cee3-4596-b826-d6c25761c3c1
**Prompt:** Birds chirping with insects buzzing and outdoor ambiance
**Generated Audio:**
https://github.com/Alpha-VLLM/Lumina-T2X/assets/54879512/b776aacb-783b-4f47-bf74-89671a17d38d
**Groundtruth:**
https://github.com/Alpha-VLLM/Lumina-T2X/assets/54879512/a11333e4-695e-4a8c-8ea1-ee5b83e34682
### Text-to-music Generation
> [!Note]
> **Attention: Mouse over the playbar and click the audio button on the playbar to unmute it.**
> For more details check out [this](./lumina_music/README.md)
**Prompt:** An electrifying ska tune with prominent saxophone riffs, energetic e-guitar and acoustic drums, lively percussion, soulful keys, groovy e-bass, and a fast tempo that exudes uplifting energy.
**Generated Music:**
https://github.com/Alpha-VLLM/Lumina-T2X/assets/86041420/fef8f6b9-1e77-457e-bf4b-fb0cccefa0ec
**Prompt:** A high-energy synth rock/pop song with fast-paced acoustic drums, a triumphant brass/string section, and a thrilling synth lead sound that creates an adventurous atmosphere.
**Generated Music:**
https://github.com/Alpha-VLLM/Lumina-T2X/assets/86041420/1f796046-64ab-44ed-a4d8-0ebc0cfc484f
**Prompt:** An uptempo electronic pop song that incorporates digital drums, digital bass and synthpad sounds.
**Generated Music:**
https://github.com/Alpha-VLLM/Lumina-T2X/assets/86041420/4768415e-436a-4d0e-af53-bf7882cb94cd
**Prompt:** A medium-tempo digital keyboard song with a jazzy backing track featuring digital drums, piano, e-bass, trumpet, and acoustic guitar.
**Generated Music:**
https://github.com/Alpha-VLLM/Lumina-T2X/assets/86041420/8994a573-e776-488b-a86c-4398a4362398
**Prompt:** This low-quality folk song features groovy wooden percussion, bass, piano, and flute melodies, as well as sustained strings and shimmering shakers that create a passionate, happy, and joyful atmosphere.
**Generated Music:**
https://github.com/Alpha-VLLM/Lumina-T2X/assets/86041420/e0b5d197-589c-47d6-954b-b9c1d54feebb
### Multilingual Generation
We present three multilingual capabilities of Lumina-Next-2B.
**Generating Images conditioned on Chinese poems:**

**Generating Images with multilingual prompts:**


**Generating Images with emojis:**

## ⚙️ Diverse Configurations
We support diverse configurations, including text encoders, DiTs of different parameter sizes, inference methods, and VAE encoders.AAdditionally, we offer features such as 1D-RoPE, image enhancement, and more.

## Contributors
Core member for code developlement and maintence:
Dongyang Liu, Le Zhuo, Junlin Xie, Ruoyi Du, Peng Gao

## 📄 Citation
```
@article{gao2024lumina-next,
title={Lumina-Next: Making Lumina-T2X Stronger and Faster with Next-DiT},
author={Zhuo, Le and Du, Ruoyi and Han, Xiao and Li, Yangguang and Liu, Dongyang and Huang, Rongjie and Liu, Wenze and others},
journal={arXiv preprint arXiv:2406.18583},
year={2024}
}
```
```
@article{gao2024lumin-t2x,
title={Lumina-T2X: Transforming Text into Any Modality, Resolution, and Duration via Flow-based Large Diffusion Transformers},
author={Gao, Peng and Zhuo, Le and Liu, Chris and and Du, Ruoyi and Luo, Xu and Qiu, Longtian and Zhang, Yuhang and others},
journal={arXiv preprint arXiv:2405.05945},
year={2024}
}
```