https://github.com/Cartucho/OpenLabeling
Label images and video for Computer Vision applications
https://github.com/Cartucho/OpenLabeling
bounding-boxes darkflow darknet gui labeling-tool object-detection opencv pascal-voc training-yolo yolo
Last synced: about 1 year ago
JSON representation
Label images and video for Computer Vision applications
- Host: GitHub
- URL: https://github.com/Cartucho/OpenLabeling
- Owner: Cartucho
- License: apache-2.0
- Created: 2018-01-19T14:30:09.000Z (over 8 years ago)
- Default Branch: master
- Last Pushed: 2022-07-06T19:58:48.000Z (almost 4 years ago)
- Last Synced: 2025-04-09T10:04:02.989Z (about 1 year ago)
- Topics: bounding-boxes, darkflow, darknet, gui, labeling-tool, object-detection, opencv, pascal-voc, training-yolo, yolo
- Language: Python
- Homepage:
- Size: 7.37 MB
- Stars: 936
- Watchers: 32
- Forks: 270
- Open Issues: 16
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- awesome-object-detection-datasets - Cartucho/OpenLabeling
- awesome-production-machine-learning - OpenLabeling - Open source tool for labelling images with support for labels, edges, as well as image resizing and zooming in. (Data Labelling and Synthesis)
- awesome-dataset-tools - OpenLabeling - Labeling in multiple annotation formats (Labeling Tools / Images)
- awesome-yolo-object-detection - Cartucho/OpenLabeling
- awesome-production-machine-learning - OpenLabeling - Open source tool for labelling images with support for labels, edges, as well as image resizing and zooming in. (Data Labelling Tools and Frameworks)
README
# OpenLabeling: open-source image and video labeler
[](https://github.com/Cartucho/OpenLabeling)
Image labeling in multiple annotation formats:
- PASCAL VOC (= [darkflow](https://github.com/thtrieu/darkflow))
- [YOLO darknet](https://github.com/pjreddie/darknet)
- ask for more (create a new issue)...

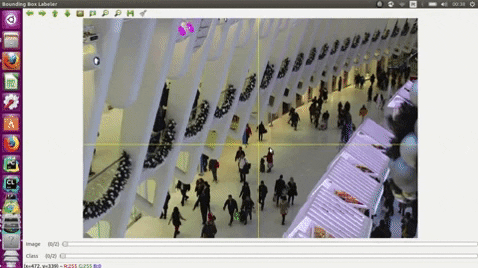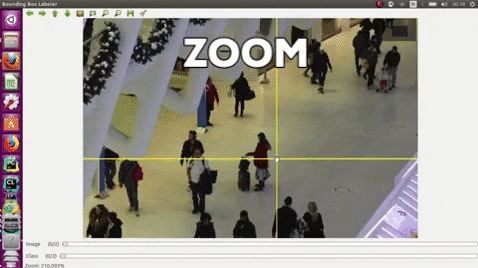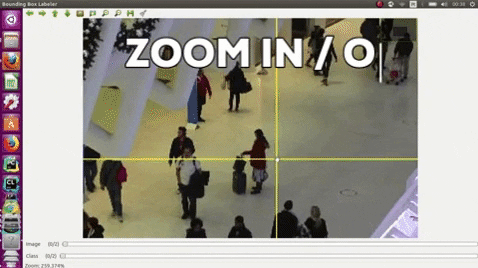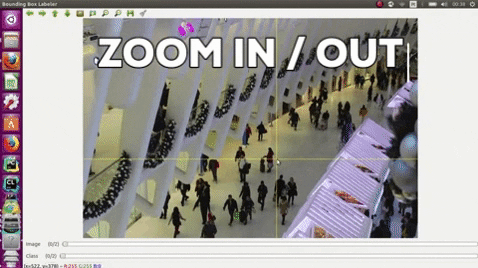
## Citation
This project was developed for the following paper, please consider citing it:
```bibtex
@INPROCEEDINGS{8594067,
author={J. {Cartucho} and R. {Ventura} and M. {Veloso}},
booktitle={2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
title={Robust Object Recognition Through Symbiotic Deep Learning In Mobile Robots},
year={2018},
pages={2336-2341},
}
```
## Latest Features
- Jun 2019: Deep Learning Object Detection Model
- May 2019: [ECCV2018] Distractor-aware Siamese Networks for Visual Object Tracking
- Jan 2019: easy and quick bounding-boxe's resizing!
- Jan 2019: video object tracking with OpenCV trackers!
- TODO: Label photos via Google drive to allow "team online labeling".
[New Features Discussion](https://github.com/Cartucho/OpenLabeling/issues/3)
## Table of contents
- [Quick start](#quick-start)
- [Prerequisites](#prerequisites)
- [Run project](#run-project)
- [GUI usage](#gui-usage)
- [Authors](#authors)
## Quick start
To start using the YOLO Bounding Box Tool you need to [download the latest release](https://github.com/Cartucho/OpenLabeling/archive/v1.3.zip) or clone the repo:
```
git clone --recurse-submodules git@github.com:Cartucho/OpenLabeling.git
```
### Prerequisites
You need to install:
- [Python](https://www.python.org/downloads/)
- [OpenCV](https://opencv.org/) version >= 3.0
1. `python -mpip install -U pip`
1. `python -mpip install -U opencv-python`
1. `python -mpip install -U opencv-contrib-python`
- numpy, tqdm and lxml:
1. `python -mpip install -U numpy`
1. `python -mpip install -U tqdm`
1. `python -mpip install -U lxml`
Alternatively, you can install everything at once by simply running:
```
python -mpip install -U pip
python -mpip install -U -r requirements.txt
```
- [PyTorch](https://pytorch.org/get-started/locally/)
Visit the link for a configurator for your setup.
### Run project
Step by step:
1. Open the `main/` directory
2. Insert the input images and videos in the folder **input/**
3. Insert the classes in the file **class_list.txt** (one class name per line)
4. Run the code:
5. You can find the annotations in the folder **output/**
python main.py [-h] [-i] [-o] [-t] [--tracker TRACKER_TYPE] [-n N_FRAMES]
optional arguments:
-h, --help Show this help message and exit
-i, --input Path to images and videos input folder | Default: input/
-o, --output Path to output folder (if using the PASCAL VOC format it's important to set this path correctly) | Default: output/
-t, --thickness Bounding box and cross line thickness (int) | Default: -t 1
--tracker tracker_type tracker_type being used: ['CSRT', 'KCF','MOSSE', 'MIL', 'BOOSTING', 'MEDIANFLOW', 'TLD', 'GOTURN', 'DASIAMRPN']
-n N_FRAMES number of frames to track object for
To use DASIAMRPN Tracker:
1. Install the [DaSiamRPN](https://github.com/foolwood/DaSiamRPN) submodule and download the model (VOT) from [google drive](https://drive.google.com/drive/folders/1BtIkp5pB6aqePQGlMb2_Z7bfPy6XEj6H)
2. copy it into 'DaSiamRPN/code/'
3. set default tracker in main.py or run it with --tracker DASIAMRPN
#### How to use the deep learning feature
- Download one or some deep learning models from https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md
and put it into `object_detection/models` directory (you need to create the `models` folder by yourself). The outline of `object_detection` looks like that:
+ `tf_object_detection.py`
+ `utils.py`
+ `models/ssdlite_mobilenet_v2_coco_2018_05_09`
Download the pre-trained model by clicking this link http://download.tensorflow.org/models/object_detection/ssdlite_mobilenet_v2_coco_2018_05_09.tar.gz and put it into `object_detection/models`. Create the `models` folder if necessary. Make sure to extract the model.
**Note**: Default model used in `main_auto.py` is `ssdlite_mobilenet_v2_coco_2018_05_09`. We can
set `graph_model_path` in file `main_auto.py` to change the pretrain model
- Using `main_auto.py` to automatically label data first
TODO: explain how the user can
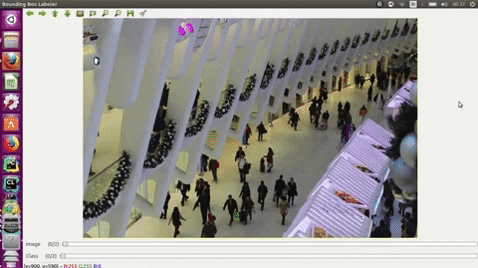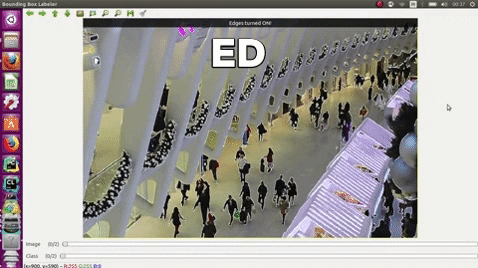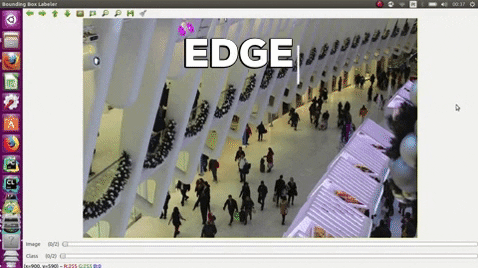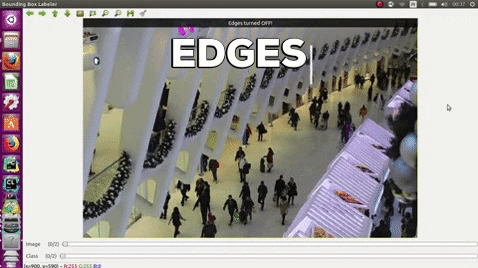
### GUI usage
Keyboard, press:

| Key | Description |
| --- | --- |
| a/d | previous/next image |
| s/w | previous/next class |
| e | edges |
| h | help |
| q | quit |
Video:
| Key | Description |
| --- | --- |
| p | predict the next frames' labels |
Mouse:
- Use two separate left clicks to do each bounding box
- **Right-click** -> **quick delete**!
- Use the middle mouse to zoom in and out
- Use double click to select a bounding box
## Authors
* **João Cartucho**
Feel free to contribute
[](https://github.com/Cartucho/OpenLabeling/graphs/contributors)