https://github.com/DataCanvasIO/HyperGBM
A full pipeline AutoML tool for tabular data
https://github.com/DataCanvasIO/HyperGBM
adversarial-validation automl catboost dask dask-distributed datacleaning distributed-training ensemble-learning fullpipeline gbm gpu-acceleration lightgbm preprocessing pseudo-labeling rapidsai semi-supervised-learning sklearn tabular-data xgboost
Last synced: about 1 year ago
JSON representation
A full pipeline AutoML tool for tabular data
- Host: GitHub
- URL: https://github.com/DataCanvasIO/HyperGBM
- Owner: DataCanvasIO
- License: apache-2.0
- Created: 2020-10-22T02:37:35.000Z (over 5 years ago)
- Default Branch: main
- Last Pushed: 2024-06-23T13:58:35.000Z (about 2 years ago)
- Last Synced: 2024-11-15T10:56:45.975Z (over 1 year ago)
- Topics: adversarial-validation, automl, catboost, dask, dask-distributed, datacleaning, distributed-training, ensemble-learning, fullpipeline, gbm, gpu-acceleration, lightgbm, preprocessing, pseudo-labeling, rapidsai, semi-supervised-learning, sklearn, tabular-data, xgboost
- Language: Python
- Homepage: https://hypergbm.readthedocs.io/
- Size: 11 MB
- Stars: 336
- Watchers: 15
- Forks: 46
- Open Issues: 8
-
Metadata Files:
- Readme: README.md
- Contributing: CONTRIBUTING.md
- License: LICENSE
Awesome Lists containing this project
- StarryDivineSky - DataCanvasIO/HyperGBM
README

[](https://pypi.org/project/hypergbm)
[](https://pepy.tech/project/hypergbm)
[](https://pypi.org/project/hypergbm)
[中文](README_zh_CN.md)
## We Are Hiring!
Dear folks, we are offering challenging opportunities located in Beijing for both professionals and students who are keen on AutoML/NAS. Come be a part of DataCanvas! Please send your CV to yangjian@zetyun.com. (Application deadline: TBD.)
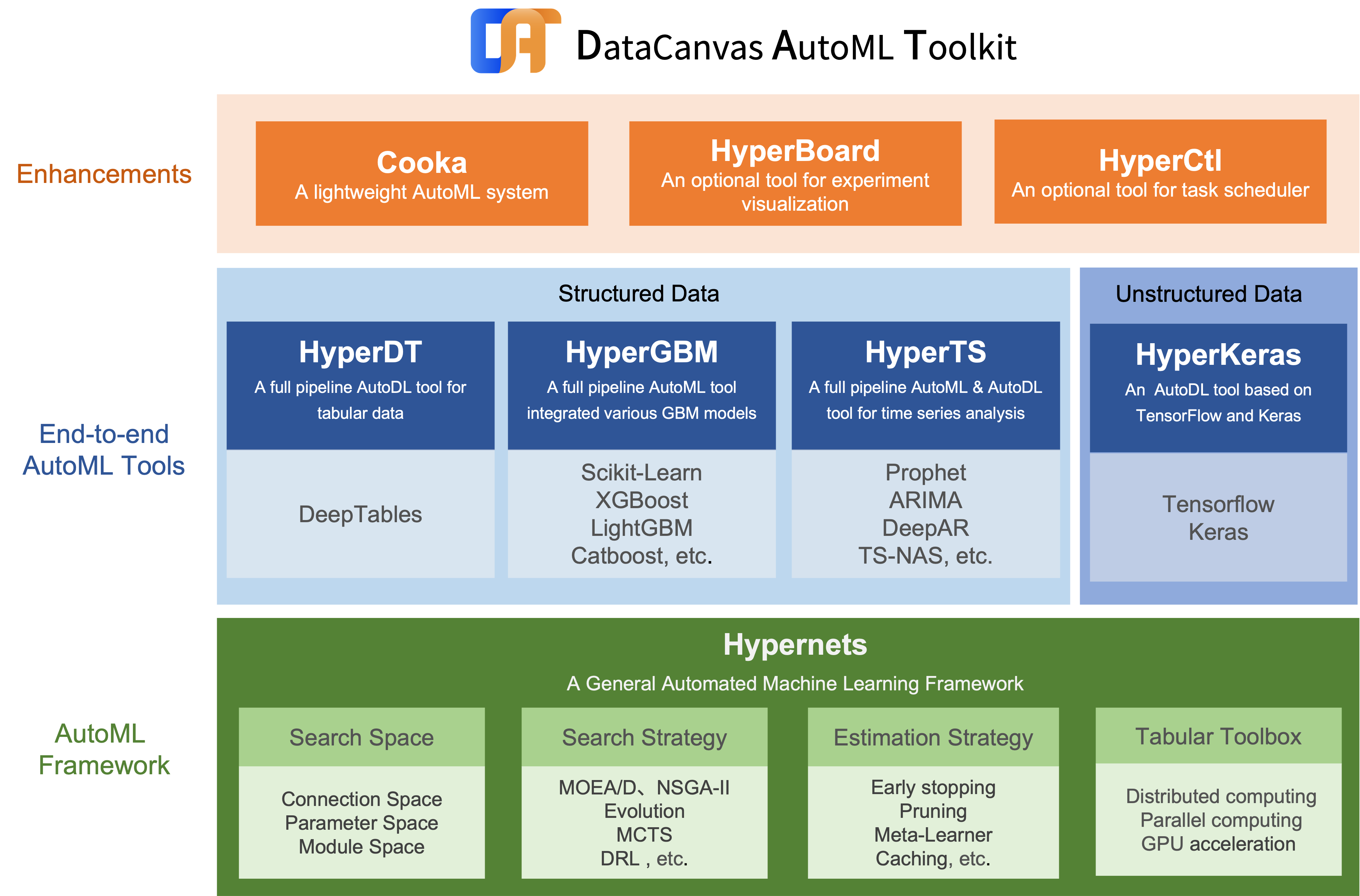
## What is HyperGBM
HyperGBM is a full pipeline automated machine learning (AutoML) toolkit designed for tabular data. It covers the complete end-to-end ML processing stages, consisting of data cleaning, preprocessing, feature generation and selection, model selection and hyperparameter optimization.
## Overview
HyperGBM optimizes the end-to-end ML processing stages within one search space, which differs from most existing AutoML approaches that only tackle partial stages, for instance, hyperparameter optimazation. This full pipeline optimization process is very similar to a sequential decision process (SDP). Therefore, HyperGBM utilizes reinforcement learning, Monte Carlo Tree Search, evolution algorithm combined with a meta-learner to efficiently solve the pipeline optimization problem.
HyperGBM, as indicated in the name, involves several gradient boosting tree models (GBM), namely, XGBoost, LightGBM and Catboost. What's more, it could access the [Hypernets](https://github.com/DataCanvasIO/Hypernets), a general automated machine learning framework, and introduce its advanced characteristics in data cleaning, feature engineering and model ensemble. Additionally, the search space representation and search algorithm inside Hyper GBM are also supported by Hypernets.
## Installation
### Conda
Install HyperGBM with `conda` from the channel *conda-forge*:
```bash
conda install -c conda-forge hypergbm
```
### Pip
Install HyperGBM with different `pip` options:
* Typical installation:
```bash
pip install hypergbm
```
* To run HyperGBM in JupyterLab/Jupyter notebook, install with command:
```bash
pip install hypergbm[notebook]
```
* To support experiment visualization base on web, install with command:
```bash
pip install hypergbm[board] # Temporarily unavailable in version 0.3.x
```
* To run HyperGBM in distributed Dask cluster, install with command:
```bash
pip install hypergbm[dask]
```
* To support dataset with simplified Chinese in feature generation,
* Install `jieba` package before running HyperGBM.
* OR install with command:
```bash
pip install hypergbm[zhcn]
```
* Install all above with one command:
```bash
pip install hypergbm[all]
```
## Examples
* Use HyperGBM with Python
Users can quickly create and run an experiment with `make_experiment`, which only needs one required input parameter `train_data`. The example shown below is using the `blood` dataset as `train_data` from `hypernet.tabular`. If the target column of the dataset is not `y`, it needs to be manually set through the argument `target`.
An example codes:
```python
from hypergbm import make_experiment
from hypernets.tabular.datasets import dsutils
train_data = dsutils.load_blood()
experiment = make_experiment(train_data, target='Class')
estimator = experiment.run()
print(estimator)
```
This training experiment returns a pipeline with two default steps, `data_clean` and `estimator`. In particular, the `estimator` returns a final model which consists of various models. The outputs:
```
Pipeline(steps=[('data_clean',
DataCleanStep(...),
('estimator',
GreedyEnsemble(...)])
```
To see more examples, please read [Quick Start](https://hypergbm.readthedocs.io/en/latest/quick_start_python.html#create-experiment-with-make-experiment) and [Examples](https://hypergbm.readthedocs.io/en/latest/example.html).
* Use HyperGBM with Command line tools
Hypergbm also supports command line tools to perform model training, evaluation and prediction. The following codes enable the user to view command line help:
```
hypergbm -h
usage: hypergbm [-h] [--log-level LOG_LEVEL] [-error] [-warn] [-info] [-debug]
[--verbose VERBOSE] [-v] [--enable-gpu ENABLE_GPU] [-gpu]
[--enable-dask ENABLE_DASK] [-dask] [--overload OVERLOAD]
{train,evaluate,predict} ...
```
The example of training a model for dataset [blood.csv](https://github.com/DataCanvasIO/Hypernets/blob/master/hypernets/tabular/datasets/blood.csv) is shown below:
```shell script
hypergbm train --train-file=blood.csv --target=Class --model-file=model.pkl
```
For more details, please read [Quick Start](https://hypergbm.readthedocs.io/en/latest/quick_start_cmdline.html).
## GPU Acceleration
Hypergbm supports full pipeline GPU acceleration, including all steps from data processing to model training. In our experiments, we got a 50x performance improvement! Most importantly, the model trained on GPU could be deployed to the environment without GPU hardware and software (e.g.,CUDA and cuML), which greatly reduces the cost of model deployment.

## Documents
* [Overview](https://hypergbm.readthedocs.io/en/latest/overview.html)
* [Installation](https://hypergbm.readthedocs.io/en/latest/installation.html)
* [Quick Start](https://hypergbm.readthedocs.io/en/latest/quick_start.html)
* [Examples](https://hypergbm.readthedocs.io/en/latest/example.html)
* [How-To](https://hypergbm.readthedocs.io/en/latest/how_to.html)
* [Release Notes](https://hypergbm.readthedocs.io/en/latest/release_note.html)
## HyperGBM related projects
* [Hypernets](https://github.com/DataCanvasIO/Hypernets): A general automated machine learning (AutoML) framework.
* [HyperGBM](https://github.com/DataCanvasIO/HyperGBM): A full pipeline AutoML tool integrated various GBM models.
* [HyperDT/DeepTables](https://github.com/DataCanvasIO/DeepTables): An AutoDL tool for tabular data.
* [HyperTS](https://github.com/DataCanvasIO/HyperTS): A full pipeline AutoML&AutoDL tool for time series datasets.
* [HyperKeras](https://github.com/DataCanvasIO/HyperKeras): An AutoDL tool for Neural Architecture Search and Hyperparameter Optimization on Tensorflow and Keras.
* [HyperBoard](https://github.com/DataCanvasIO/HyperBoard): A visualization tool for Hypernets.
* [Cooka](https://github.com/DataCanvasIO/Cooka): Lightweight interactive AutoML system.
## Citation
If you use HyperGBM in your research, please cite us as follows:
Jian Yang, Xuefeng Li, Haifeng Wu.
**HyperGBM: A full pipeline AutoML tool integrated with various GBM models.** https://github.com/DataCanvasIO/HyperGBM. 2020. Version 0.2.x.
BibTex:
```
@misc{hypergbm,
author={Jian Yang, Xuefeng Li, Haifeng Wu},
title={{HyperGBM}: { A Full Pipeline AutoML Tool Integrated With Various GBM Models}},
howpublished={https://github.com/DataCanvasIO/HyperGBM},
note={Version 0.2.x},
year={2020}
}
```
## DataCanvas
HyperGBM is an open source project created by [DataCanvas](https://www.datacanvas.com/).