Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/DeSinc/SallyBot
AI Chatbot coded in Discord.net C#
https://github.com/DeSinc/SallyBot
Last synced: 3 months ago
JSON representation
AI Chatbot coded in Discord.net C#
- Host: GitHub
- URL: https://github.com/DeSinc/SallyBot
- Owner: DeSinc
- License: mit
- Created: 2023-04-01T14:02:05.000Z (almost 2 years ago)
- Default Branch: main
- Last Pushed: 2024-06-12T05:29:56.000Z (8 months ago)
- Last Synced: 2024-08-01T21:41:53.731Z (7 months ago)
- Language: C#
- Size: 246 KB
- Stars: 298
- Watchers: 13
- Forks: 51
- Open Issues: 1
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# SallyBot
AI Chatbot that uses locally-ran large language models to talk to you (No Chat-GPT! Runs on your PC! It even runs on a raspberry pi 4B!)
It also utilises [Stable Diffusion](https://github.com/AUTOMATIC1111/stable-diffusion-webui) to take real selfies, running on your local GPU
Coded in Discord.net C#
Context: [I Made a Discord Chat Bot that Can Take Selfies](https://www.youtube.com/watch?v=KM4a7RGG270)
[](https://youtu.be/KM4a7RGG270)
### Supported LLM interfaces:
[Oobabooga Text Generation Web UI](https://github.com/oobabooga/text-generation-webui)
[Google Gemini-Pro API (totally free 60 messages per minute)](https://ai.google.dev/)
[Dalai Alpaca (older abandonware deprecated method but still works - NOT recommended)](https://github.com/cocktailpeanut/dalai)
### Examples
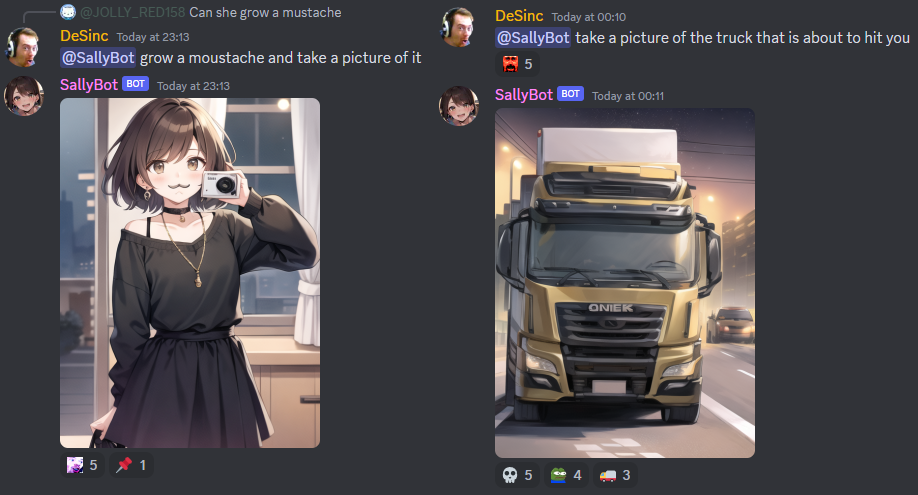
## USAGE
Either clone the repository using git (look up how to do so if unsure)
or
Click the green 'Code' drop-down at the top right corner of this webpage and select 'Download ZIP' and place the contents into a folder called SallyBot (changing the name risks issues with the Visual Studio environment)
Download and install Visual Studio Community WITH C# dotNET development modules ticked. Look up guides if you are confused - when installing Visual Studio Community, it will ask with big squares with tickboxes in the corners which types of coding packages you want to install. Pick the C#/Dot NET ones.
Double click on the sallybot.sln file and open with Visual Studio Community
(If that doesn't work try open sallybot.csproj with Visual Studio Community. It should open up the whole project and make a .sln file, etc.)
(If that doesn't work you likely need to install the C# dotNET packages with the Visual Studio Installer window. You can run this by typing Visual Studio Installer into the start menu and hitting enter.)
If you don't have a bot already:
* Create a new Discord bot on the Discord Developer Portal and make an API key (takes about 2 mins) https://discord.com/developers/applications
* Make sure you enable message intents and other intents for this bot or you won't see any message content etc.
Use this guide: https://autocode.com/discord/threads/what-are-discord-privileged-intents-and-how-do-i-enable-them-tutorial-0c3f9977/
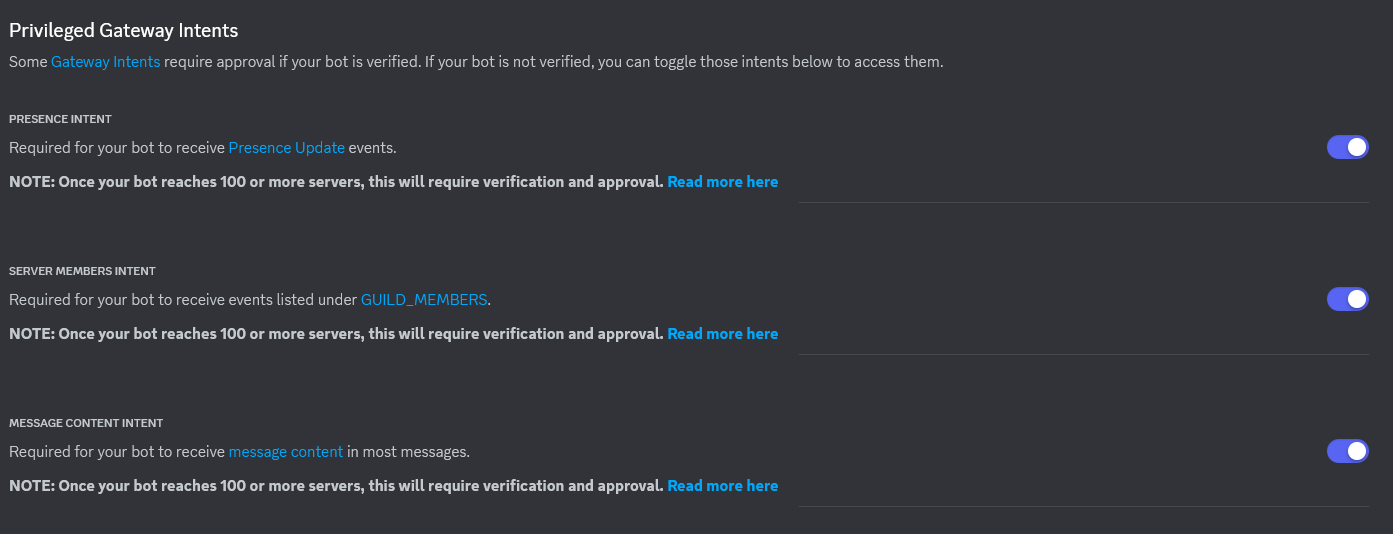
* Join the bot to your server, follow this guide if you don't know how: https://discordjs.guide/preparations/adding-your-bot-to-servers.html#bot-invite-links
Put your bot API key and your server's ID in the MainGlobal.cs file (they will error out until you fill them in to show you where to put them)
Press F5 to build it and run and see what happens (it should work first try)
## Using Google's Gemini-Pro model (60 API calls per minute free) (keep scrolling for open source CPU/GPU models)
By far the easiest way to use this bot, and it's totally free with no payments or anything.
Go to Google's AI studio by clicking this link: https://ai.google.dev/


Get your API key and then copy and paste it into the MainGlobal.cs file (inside the folder where you cloned SallyBot into)
Now just start up the bot and type in any discord chat that the bot can see and it will switch over to google's API and be ready to go! To enable or disable gemini explicity you can type ``enable gemini`` or ``disable gemini`` and it will try to use other sources like Text-gen-webui or dalai if present.
## Using Oobabooga Text Generation Webui -- Runs on the GPU - much faster - OR the CPU depending on what you choose in the installer
Warning: For the average 7B model, it requires a card with at least 6GB of VRAM. If you're running on CPU you need at least 6-8GB of ram.
If you're willing to run on the inferior smaller parameter count models like a 7B Q3_K_S model or something then it'll work on less RAM/VRAM, but the output is untested and frankly likely to be bad.
The current 'meta' is to use GGUF models, which can use up your RAM to load, but offload some of it to your GPU. That way you can run models that are slightly bigger than your VRAM and still get decent speeds.
Download and install [Oobabooga from their repo here](https://github.com/oobabooga/text-generation-webui). Their README has information on how to install it, with two methods: 1-click installer and manual. I heavily recommend the 1-click installer.
After downloading and unzipping the 1-click installer, run `start_windows.bat`. The installer is interactive and you will need to enter your GPU device when prompted, or select CPU mode. I do not recommend CPU mode.
Once the install script is installed, you will need to download a model.
Search for a language model yourself on HuggingFace. Once you have found one to your liking, copy the username/modelname.
Here's an example of what a 13B model looks like on HuggingFace and where to click to copy the username/modelname:

Note: The 13B model listed here requires a 10GB VRAM card to run.
'GPTQ' is the GPU variant. For CPU, find the 'GGUF' variant instead, which can run on CPU with your system RAM and also has the option of offloading parts of it to your GPU to help speed up processing.
IMO GGUF models are better. As of writing at 2023/12/18 the best type to download for balance of quality and saving space is Q4_K_M. If you need more space you can pick one that is lower but quality takes a big hit at the Q3 variants.
For lower VRAM usage (6-8GB cards), find a '7B' model to run as this will fit on your card. You could possibly get away with something like a 13B GGUF model if you get a Q3_K_S or Q4_K_S variant but quality and speed will both suffer.
You then download the model with the web interface:
* Make sure of course that it is running from the start-windows.bat file you ran earlier
* Once loaded, open a browser and go to 127.0.0.1:7682 in the URL address bar and hit enter
* Click the 'Models' tab at the top of the page
* Paste the ``UserName/ModelName`` of the model to download from Huggingface in the Download Model box
* Hit 'Download' and wait for the model to finish downloading
* Click the little blue 'Refresh' icon next to the model selection drop-down box at the top left corner of the webpage
* Select the model from the drop-down list, as it should now be present
Updated information: Text Gen Webui moved to the OpenAI API format and this bot now uses that standardised format.
After the installing has finished you need to set up the arguments in the `start_windows.bat` or `start_linux.sh` file to allow SallyBot to communicate with Oobabooga.
It can be found near the bottom of the file on the following line: `call python one_click.py`

Arguments to be added here include:
`--chat` sets the web interface to chat mode which is better. This arg isn't necessary it just makes the web interface look nicer if you choose to browse to it on localhost:7862 in your web browser.
`--model ` specifies which model Oobabooga should use, replace `` it is the name of the folder in text-generation-webui/models.
`--api` tells Oobabooga to turn on the OpenAI API format to listen to SallyBot requests.
`--listen-port 7862` is set to 7862 to not overlap with stable diffusion. `--api` opens a separate port for sallybot to interface with which runs on port 5000. Port 7862 can still be used to view the web interface if you like.
See the following example of args:
`call python one_click.py --api --verbose --listen-port 7862 %*`
## AI Text Generation with Dalai Alpaca (Run on the CPU) -- Easier to install, but has long-standing bugs that are not likely to be fixed (project seems abandoned)
The Dalai section is mostly defunct now but still works on older models like the original Alpaca Native models trained on Llama 1. It sends out json requests to a Dalai server in the format for [Dalai Alpaca 7B](https://github.com/cocktailpeanut/dalai) which is a CPU-only program.
Just install [this](https://nodejs.org/en/download) first and then follow the quick and easy 2-step instructions on the Dalai github link above. The bot will automatically connect and start sending Dalai requests when you ping the bot.
If you wish to modify the LLM parameters, it's this section here for Dalai:
```c#
var dalaiRequest = new
{
seed = -1,
threads = 4, <--(btw, change this to your thread count minus 2 for more speed)
n_predict = 200,
top_k = 40,
top_p = 0.9,
temp = 0.8,
repeat_last_n = 64,
repeat_penalty = 1.1,
debug = false,
model = "alpaca.7B",
prompt = inputPrompt
};
```
## Other AI text generators as yet unsupported
If you're using another AI text generator, check its github page for instructions on how to format the data and change the format of the request to what it needs. You might also need to change the way it sends the request in, which could be a lot of code changes depending.
The format it sends requests in is technically compatible with Kobold AI, but it currently doesn't work as there is a bit of an issue receiving the json response back from Kobold that I haven't worked on yet. It is likely a very simple solve if anyone out there wanted Kobold compatibility desperately.
## Generate images with Stable Diffusion (runs on the GPU and needs probably minimum 3GB vram with some hackery, more like 6GB to not have to hack around getting it to work)
Download [stable-diffusion-webui](https://github.com/AUTOMATIC1111/stable-diffusion-webui)
Follow their installation steps, then find either `webui-user.bat` on Windows or `webui-user.sh` on Linux.
Edit the file and modify the `COMMANDLINE_ARGS` line.
Windows:
```bat
set COMMANDLINE_ARGS=--api --xformers
```
Linux:
```sh
export COMMANDLINE_ARGS="--api --xformers"
```
Save the file and run it. The API is now ready to receive request right from SallyBot. If you get an error with xformers just remove --xformers from the args and save the file and run it again.
It will send it to a default model of some kind, most likely it comes with Stable Diffusion 1.5 model which is a real-life images model.
Go to https://civitai.com/ and then look for an image model you like on the homepage. You can pick an anime or even a realism one if you want.
Download that model, put it in \models\stablediffusion\ where the text file is that says "Place checkpoints here.txt"
Open the stable diffusion web UI by going to localhost:7860 in your web browser URL/address bar
Select the drop-down at the top left and pick the model you just downloaded. (You might need to click the refresh symbol to reload the list of models)
Now the next image request you send to SallyBot will automatically generate with that image model!
## Known Issues
### Stable Diffusion needs to use an older version of Python. Follow the steps in their repo and install Python 3.10.7 making sure to add it to your system PATH.
Afterwards, assuming you did not change the default install location, modify the `PYTHON` line in your `webui-user.bat` file.
```bat
set PYTHON="%LOCALAPPDATA%\Programs\Python\Python310\python.exe"
```
### Dalai Alpaca needs to be run in Command Prompt (cmd.exe) and not PowerShell (powershell.exe).
With Windows 11, Microsoft made PowerShell the default terminal, make sure to use Command Prompt to start it instead, an easy way to do that is `WIN + R` `cmd.exe` and then use `cd` to navigate to the Dalai directory.
### Emoji Psychosis / Hashtag Psychosis
Oobabooga had an issue where for some reason they added an additional space to the end of the prompt. This causes the bot to want to spam ever lengthening repeating twitter hashtags and long long strings of emojis incessantly.
The cause is thought to be because double-spaces in the LLMs are statistically usually written just before emojis, so the LLM will calculate any double space as likely being followed by an emoji.
The fix is to make sure there are no double spaces or any spaces at all at the end of your prompt.
### Dalai tends to ramble even after your bot has already sent the message.
The reason for this is that there is no proper working stop command built into dalai. There is one they tried to make, but it crashes the dalai server every 2nd or 3rd time you run it so in my view it's not working.
I built my own stop command into the source code myself. Not only does it work every time without crashing, it's also much faster and stops the rambling instantly, compared to their weak stop command that lets it ramble for like 5+ whole seconds after you told it to stop.
It's just 5 easy steps to get it working on your system too!
1. download the dalai source code from that cocktailpeanut github linked above
2. unzip it to a folder somewhere ***ON C DRIVE ON C DRIVE ON C DRIVE IT DOES NOT WORK ON ANY OTHER DRIVE LETTER*** (I suggest putting it next to the c:\users\username\dalai folder. mine is C:\Users\Dean\dalaiDS)
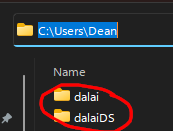
3. replace the index.js file with my special index.js file here: https://pastebin.com/A3bpWhTG
4. navigate a command prompt to this custom source dalai folder we just unzipped with the custom index.js file in it (by typing "cd" and then the custom folder. like this: ``cd c:\downloads\dalaiCustomSource``
5. run the ``npx dalai serve`` command from command prompt within this folder
NOTE: it will do this purple IndexTree thingie every time you start the server with my custom code:
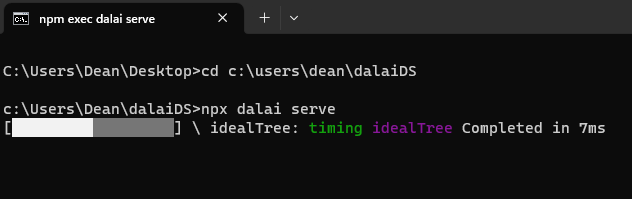
I don't know why but it just does. It takes like 20-40 seconds at worst. Small price to pay for a working stop command that actually stops the bot ramblin without crashing the server.
That's it! After it starts up, you are ready to run the bot and query some LLMs!