https://github.com/Hellisotherpeople/CX_DB8
a contextual, biasable, word-or-sentence-or-paragraph extractive summarizer powered by the latest in text embeddings (Bert, Universal Sentence Encoder, Flair)
https://github.com/Hellisotherpeople/CX_DB8
contextual-summarization cuda debate-evidence embeddings extractive-summarization flair python semantic-search semantic-summarization summarization summarizer token-level-summarization universal-sentence-encoder
Last synced: about 1 year ago
JSON representation
a contextual, biasable, word-or-sentence-or-paragraph extractive summarizer powered by the latest in text embeddings (Bert, Universal Sentence Encoder, Flair)
- Host: GitHub
- URL: https://github.com/Hellisotherpeople/CX_DB8
- Owner: Hellisotherpeople
- License: gpl-3.0
- Created: 2019-02-19T23:05:17.000Z (over 7 years ago)
- Default Branch: master
- Last Pushed: 2022-12-27T15:36:19.000Z (over 3 years ago)
- Last Synced: 2024-05-21T00:49:29.273Z (about 2 years ago)
- Topics: contextual-summarization, cuda, debate-evidence, embeddings, extractive-summarization, flair, python, semantic-search, semantic-summarization, summarization, summarizer, token-level-summarization, universal-sentence-encoder
- Language: Python
- Homepage: https://huggingface.co/spaces/Hellisotherpeople/Unsupervised_Extractive_Summarization
- Size: 6.21 MB
- Stars: 222
- Watchers: 11
- Forks: 26
- Open Issues: 9
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# CX_DB8
UPDATE: A webapp version of this which implements most of the functionality in CX_DB8 is available here: https://huggingface.co/spaces/Hellisotherpeople/Unsupervised_Extractive_Summarization
100 Stars - 2/1/2019
Thank you for all the support!
BTW: Someone has a notebook with CX_DB8 working for those who don't want to go through the installation or deal with version mismatches due to me no longer updating this repo. It's available [here](https://notebooks.azure.com/TheDubNY/projects/NLP1/html/Flair%20and%20summarization.ipynb)
  
A contextual, queryable, token (or sentence or paragraph) extracting summarizer designed from the ground up by a former debater for debaters
# Table of Contents
* [Features](#Features)
* [Install Instructions](#install-instructions)
* [Usage Instructions](#usage-instructions)
* [Examples](#Examples)
* [What is this?](#what-is-this)
* [Future Plans](#what-are-your-plans)
## Features
* Worlds most flexible unsupervised extractive summarizer / semantic search engine
* Queryable text-rank like Summarization for words, sentences, or paragraphs. (Char level and ngram level on the way)
* Supports any combination of modern word embedding architectures
* Outputs underlined and highlighted summary in terminal, docx, and HTML
* Graphically visualize summaries with either first 3 vector components of model or a dimensionality reduction algorithim reducing original embedding to 3D.
Colors of each point reflect cosine similarity to query (red dot)
(UMAP)
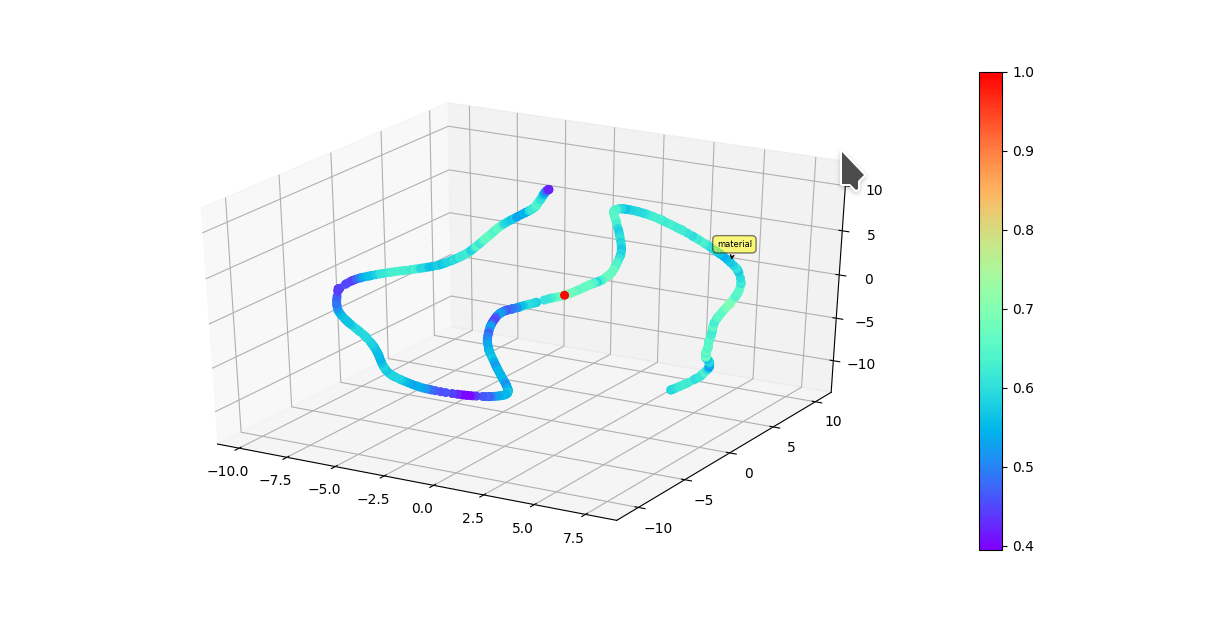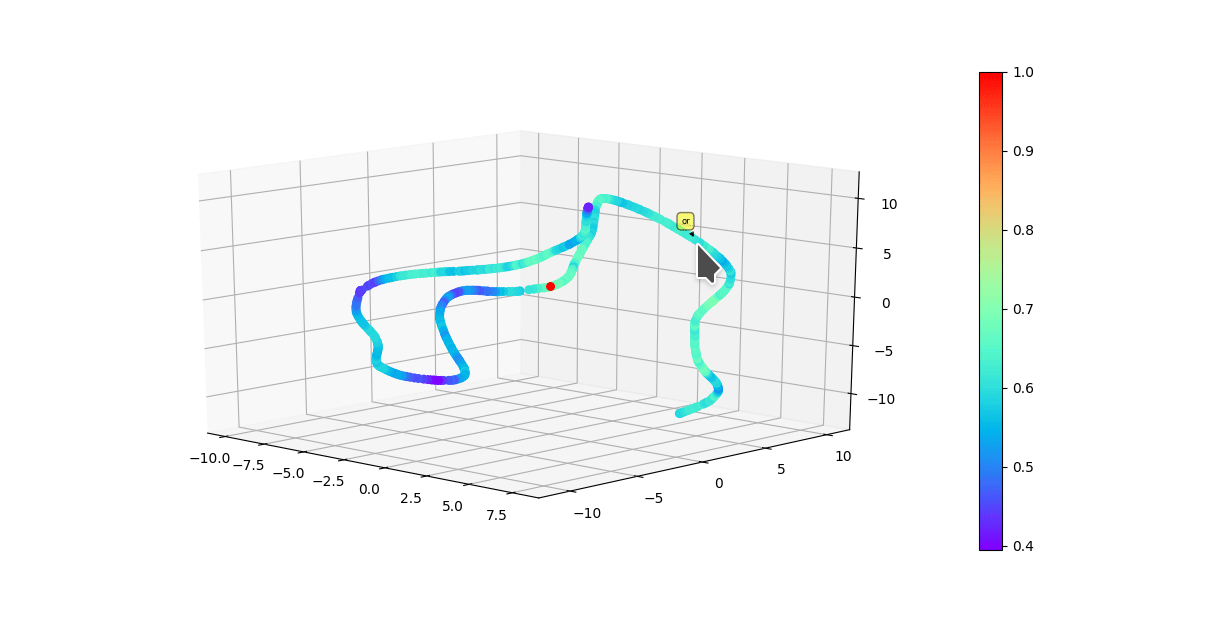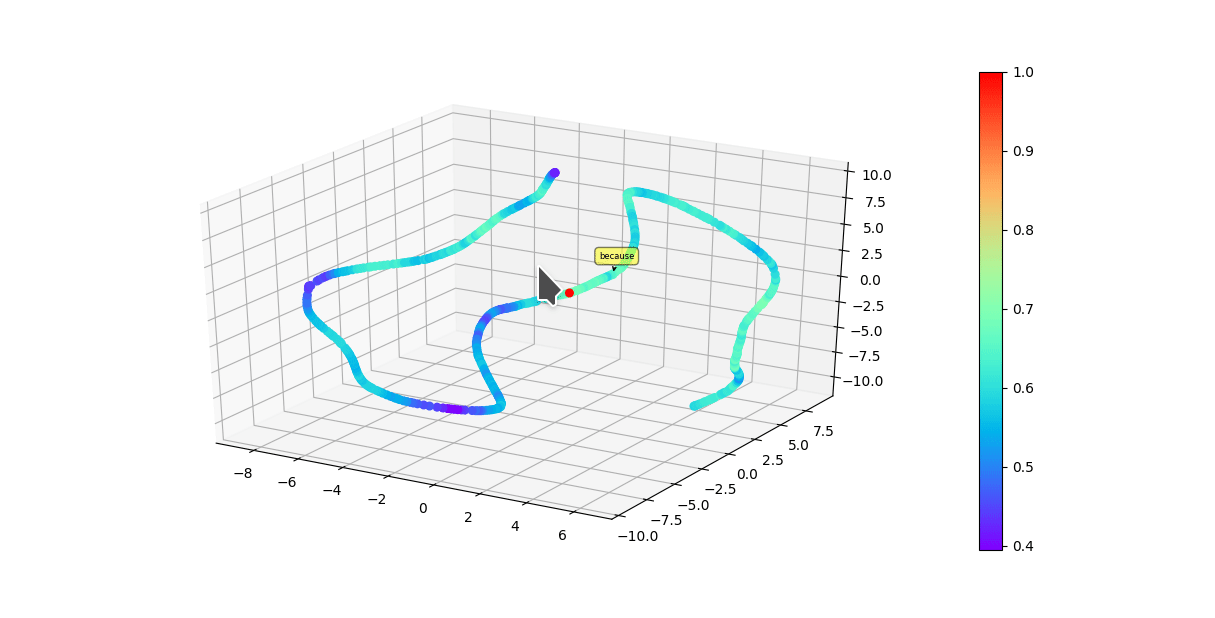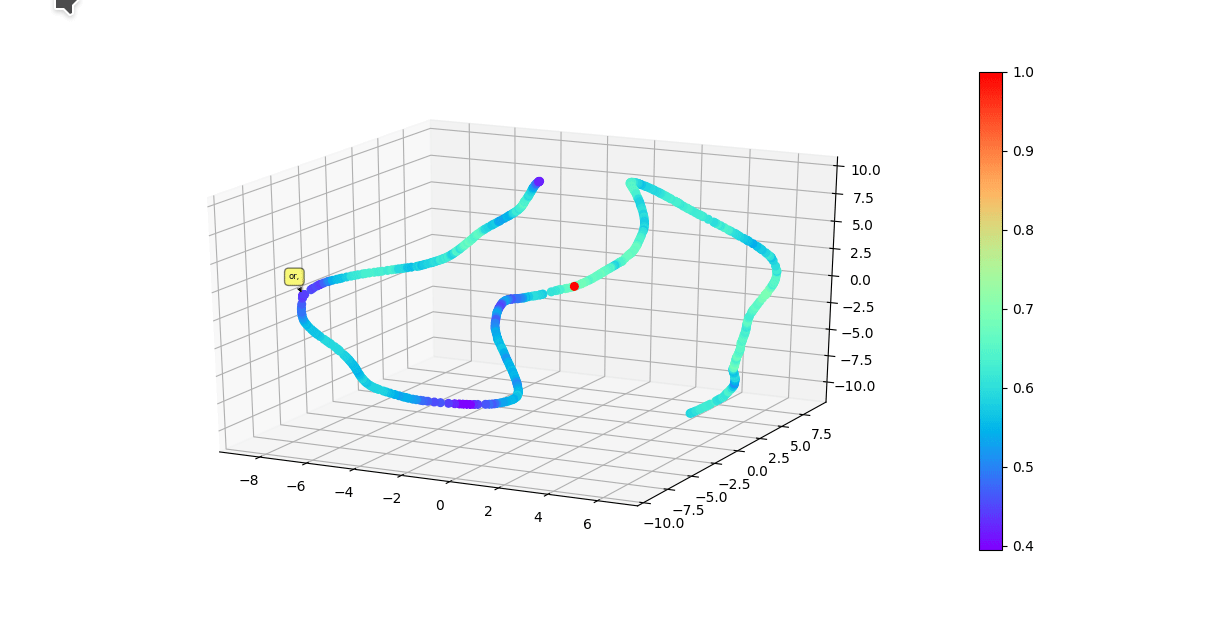
(Raw vector components)
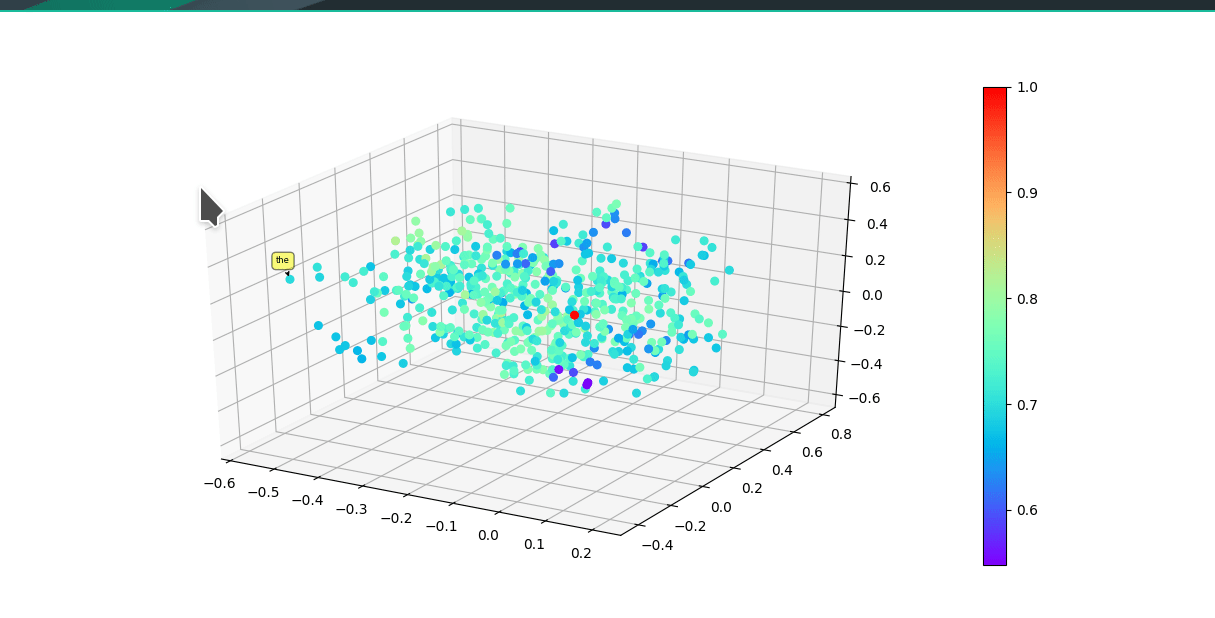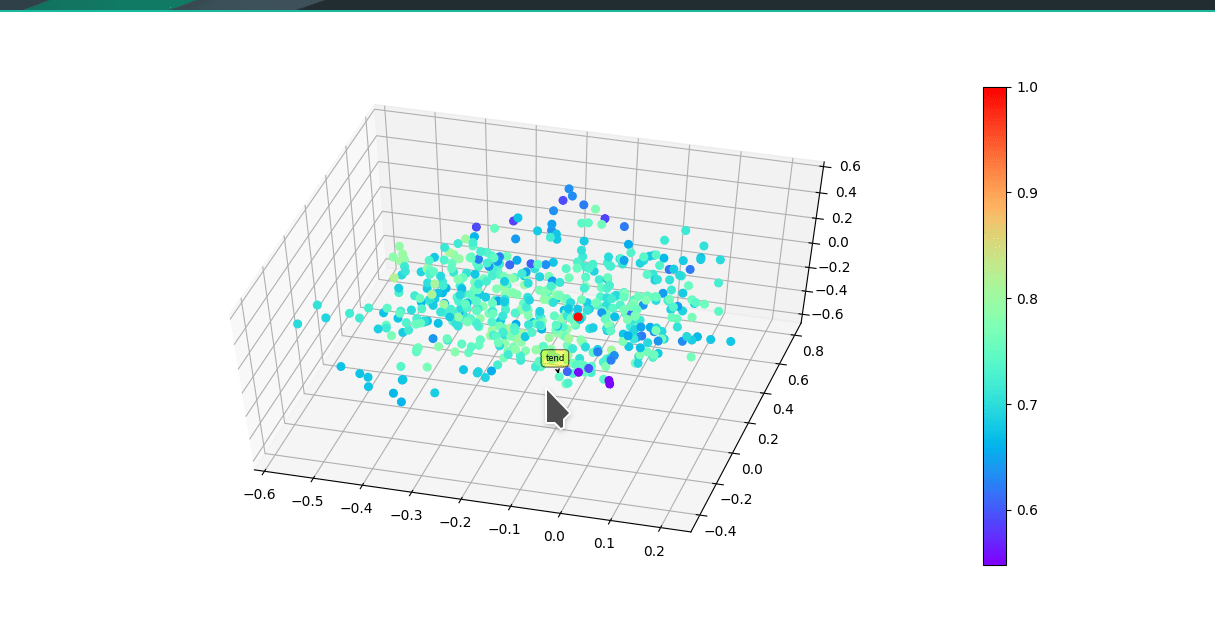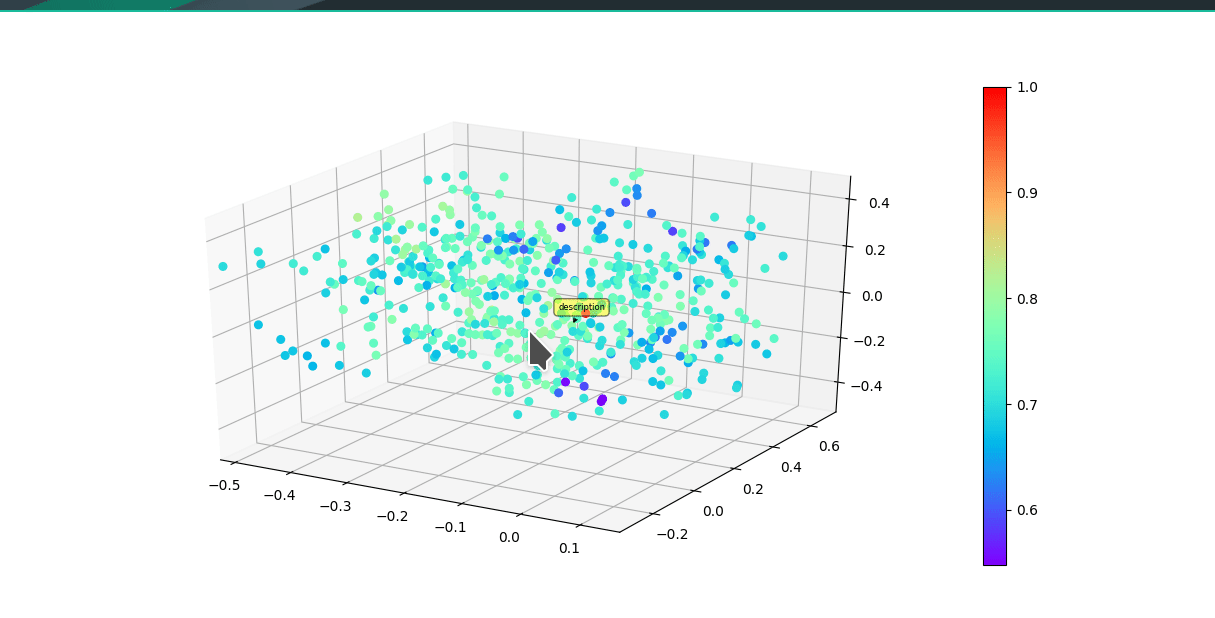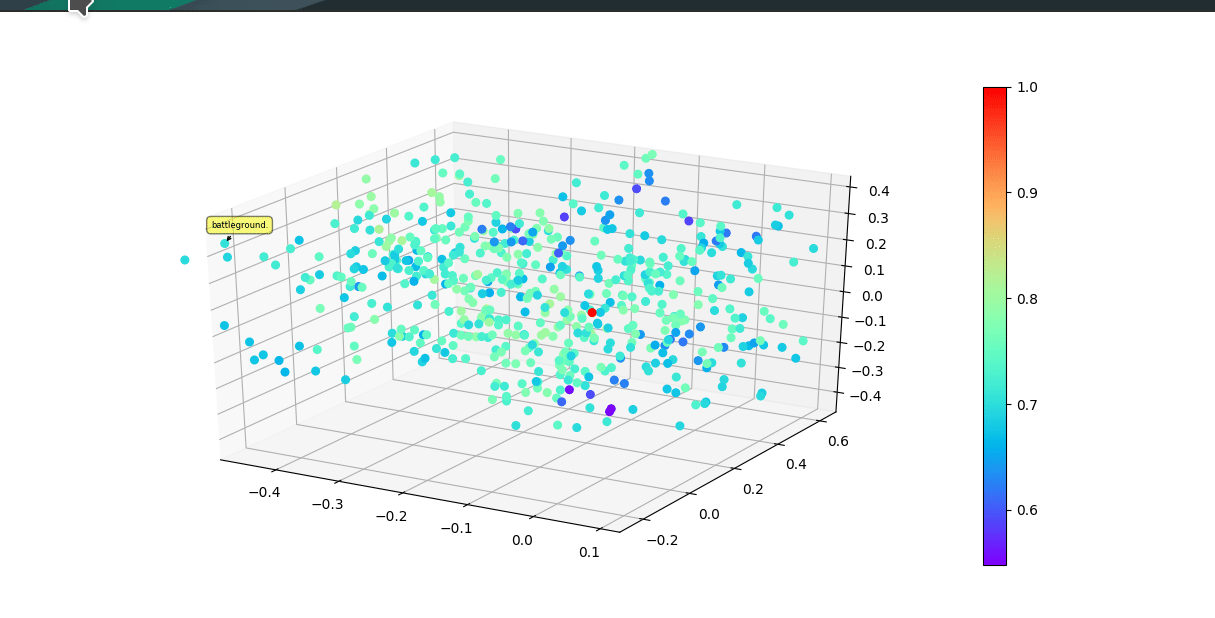
## Install Instructions
1. Confirm that you have Python 3.6+ (Should come preinstalled in a modern Linux install, may need to install on Windows). Open a terminal and Type "python" or "python3" (if python2 comes up), and take note of which version of Python 3 you have.
2. Confirm that you have "pip" (The python package manager). usually a simple "pip" or "pip3" will confirm if you have it or not. If this is not present, it can be installed via apt-get (for ubuntu users)
3. Install [PyTorch](https://pytorch.org/). The install instructions are quite easy - you'll want to install the "pip" package, correponding to your Python version. Advanced users who want to take advantage of their GPU and who have installed CUDA and CUDNN can select their corresponding CUDA version - but most users will want to select "None". Finally, PyTorch will generate a one line command. A user with Python 3.7 and not using cuda would run this command:
```
pip3 install https://download.pytorch.org/whl/cpu/torch-1.0.1.post2-cp37-cp37m-linux_x86_64.whl
pip3 install torchvision
```
4. move to your favorite empty directory, and clone CX_DB8 into that directory
```
git clone https://github.com/Hellisotherpeople/CX_DB8.git
cd CX_DB8
pip3 install -r requirments.txt
```
5. It's installed! You should be ready to cx_db8 this from the command line with a
```
python3 -i cx_db8_flair.py
```
## Usage Instructions
Sorry, but right now I don't have a good configuration setting abstraction - so you need to edit the source code to change settings. Don't worry, it's not hard
First, open up cx_db8_flair.py in your favorite text editor
```
vim cx_db8_flair.py
```
Change line 31 to "True" if you'd like grammatically correct, sentence level, summarization
Change line 32 to "True" if you'd like to see "Dynamic" highlights of your embeddings (brightness changes based on "importance"), False is like the bottom examples picture.
Change line 33 to "True" to enable experimental vizualization features (not recommended)
Edit lines 36-45 as you see fit to choose the embeddings. Comment out the embeddings you don't want (comment with the # sign) and uncomment the embeddings that you do want to use. Stuff closer to the top should be faster to run but worse at summarization (in general). You can mix and match any combination of embeddings (even your own finetuned embeddings). Personally, I've had a lot of success with "Law2Vec", a word2vec instance trained on a high quality legal corpus. Turns out lawyers are amazing at Summarizing debate evidence!
If you are using word level summarization, the integer which controlls the word window size is on line 303. I will soon update this to be a user configurable value.
For a list of supported embeddings, look for the tables [here](https://github.com/zalandoresearch/flair/blob/master/resources/docs/TUTORIAL_3_WORD_EMBEDDING.md) and [here](https://github.com/zalandoresearch/flair/blob/master/resources/docs/TUTORIAL_4_ELMO_BERT_FLAIR_EMBEDDING.md) from Flair.
UPDATE (Aug 7 2019), Flair just updated to support a bunch of new ultra modern embeddings. I *highly* recommend "XLnet" as its training mechanism (involving permutating the input) makes it especially useful for CX_DB8's word level summarization capabilities.
After you've selected the embeddings combination that you want. Flair will go and download the embeddings. Depending on the selected combination, these can take 4GB+ of diskspace, and will take up about that much RAM during execution.
Upon first running cx_db8_flair.py, CX_DB8 will prompt you with a screen asking you to continue. Press "y" or it will end execution, and save any summaries found to "test_sum.docx".
If you'd like to run CX_DB8 on a file on disk, you can pass a "card_file_path" to it like so
```
python3 cx_Db8_flair.py --card_file_path card_file_path.txt
```
If a file is not passed, CX_DB8 will then prompt you to add card text into CX_DB8 when Ctrl-D (Ctrl-Z + Enter for Windows) is pressed.
Then it will ask for a card tag, or allow the user to give a "generic" summary by entering -1.
It will ask you what percentile that you want underlined and highlighted. this is user dependent based on the size of the summary.
It will then prompty for a card author and date, and then the citation. This is only relavent for the creation of the word document. After all of this are entered, the summary is generated and the prompt will ask you to either continue execution with a "y" or to end exeuction.
Depending on the paramaters chosen, summarization may take a long time (more accurate) or be nearly instant.
Please submit issues for help with installation or running cx_db8 here with the issue tracker.
## Examples
**Settings used: FastText, underline top 70%, highlight top 65%, brighter = more important. All highlights are more important than only underlined**

**Card tag given: "Humanity is an abstraction".**

**It supports sentence level summarization!**

**And now, it also generates word docs!!**

## UPDATE 3/30/2019
I finally got fed up with trying to experiment with supervised summarization systems. Thanks to the magical folks at Google for creating the unsupervised ["Universal Sentence Encoder"](https://tfhub.dev/google/universal-sentence-encoder/2) which is more rightly called the "Universal Text Encoder" given how smoothly it works on Words, Sentences, or even whole Documents.
Also, high school debators are really quite bad at properly summarizing debate documents. Garbage in - Garbage out when it came to Supervised Learning methods.
So, I enlist the help of the wikipedia pre-trained Universal Sentence Encoder to create the (to my knowledge) **worlds first contextual token-level extractive summarizer.**
It works by first computing the "meaning" of the card tag, which can be anything. Then, it goes through every word in the actual card. Now, here, I could just compute the meaning of the individual word like "The" = 0.11 and "Person" = 0.12, but that doesn't include the context of the other words around it.
So, instead I take N words before and after the string, and use those to compute the meaning of the N gram generated for each word. The first word only includes N words after the first word, and the last word only includes N words before the first word. This allows the CX_DB8 system to properly compute the meaning of each word in the text **in the context of the N words before and after it**. I then compute a similarity score between each word with context and the card tag, and decide to include it in the summarized text if the similarity score is over a user defined threshhold. If the user gives a 1, then the summarizer only includes the exact same string, if the user gives a 0 it includes everything. I've experimented and found a score of about 0.25 - 0.4 to be very effective
I am strapped for time but will provide a good setup and install script and instructions on how to install and use this. If you know how to code, you should be able to easily get this working on your own system. **it doesn't even require a GPU, since the Universal Sentence Encoder model is CPU friendly** (but you might need Mac or Linux - have not tested Windows support yet and that's a big deal since no one runs word on a Linux box)
## What is this?
So - I'm really passionate about someone using the [various](https://github.com/google-research/bert) [different](https://blog.openai.com/better-language-models/) [new](https://github.com/zalandoresearch/flair) [cool](http://jalammar.github.io/illustrated-transformer/) [innovations](https://github.com/abisee/pointer-generator) that currently exist in NLP to solve a surprisngly well defined problems that (should) have been solved by now: Token-Level Extractive Summarization.
## Why token level extractive summarization?
In American competative cross-examination debate (also known as Policy Debate) - a unique form of evidence summarization is utilized - Summarization by highlighting - which this "card" will illustrate:

In this example, everything after the citation is the verbatim supreme court dissenting opinion. Competative debators summarize this document by simply underlining the important parts of the document. They read outloud the highlighed portions of the document.
There are a multitude of NLP tasks that we could apply to a dataset of thousands of pieces of debate evidence. I am most interested in the task of creating an automatic evidence underlining tool.
## So.... where is that tool?
CX_DB8 is above, but this repo also contains some misc code for analyzing debate corpuses
I'm publishing the dataset parsing and creation tools now to prove that I am (to my knowledge) the first one to write a parsing script capable of converting competative debate evidence into CoNNEL 2003 / Seq2Seq friendly data types. In theory, any Seq2Seq or PoS tagging model that accepts one of those formats can utilize this dataset. I will write a quick tutorial on how to gather these dataset files yourself:
*Step 1: Download all open evidence files from 2013-2017 ( https://openev.debatecoaches.org/ ) and unzip them into a directory
*Step 2: Convert all evidence from docx files to html5 files using pandoc with this command:
```
for f in *.docx; do pandoc "$f" -s -o "${f%.docx}.html5"; done
```
*Step 3: run one of my .py files with python3 to have it parse all the html5 files and it will dump out a file titled "card_data.txt" in the output format specified by the .py file
I will document how to change the file locations at a future time.
## What are your plans?
So, it looks like the prefered framework for doing state of the art NLP work [Flair](https://github.com/zalandoresearch/flair/issues/563#issuecomment-470010988) is finally being updated to allow it to train with large datasets. This is going to allow me to create a sentence compression (highlighter) model as soon as the patch allowing large datasets makes it into Flair. I will be training this model using the latest in sentence and word pre-trained embeddings (like google BERT) to give the sentence compression model far more semantic understanding.
After the sentence compression model is developed (DONE), I have 2 other models I want to create for the good of the debate community.
1. A document classifier. (also possible using Flair). I will soon write some parsing code to extract the class of a debate card. For instance, an answer to the Capitalism Kritik by saying that there would be tranisition wars would be classified as "A2 Capitalism - Transition Wars". Given the way that debate documents are hierachially structured using verbatims "hats and pockets" features - it should be possible to automatically extract a reasonable class for each document. With some cleaning, I hope to get a document classifier that can classify an arbitrary piece of evidence into 1 of N (I assume N is around 200) buckets.
2. A card tag generator - basically just a abstractive summarizer model. I'd explore Pointer-Generator networks for this, as they are mature and allow for abstractive summaries which utilize lots of words from the source text.
Combing the 3 models, a document highlighter, a document classifier, and a card tag generator with a system to automate taking in new cards (RSS feed or something involving Kafka / REST Apis) - a fully end to end researching system can be created - which will automate away all tasks of debate.