Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/HobbitLong/CMC
[arXiv 2019] "Contrastive Multiview Coding", also contains implementations for MoCo and InstDis
https://github.com/HobbitLong/CMC
Last synced: 1 day ago
JSON representation
[arXiv 2019] "Contrastive Multiview Coding", also contains implementations for MoCo and InstDis
- Host: GitHub
- URL: https://github.com/HobbitLong/CMC
- Owner: HobbitLong
- License: bsd-2-clause
- Created: 2019-06-13T10:32:11.000Z (over 5 years ago)
- Default Branch: master
- Last Pushed: 2020-11-10T07:33:17.000Z (about 4 years ago)
- Last Synced: 2024-10-29T22:32:23.654Z (15 days ago)
- Language: Python
- Homepage:
- Size: 74.2 KB
- Stars: 1,299
- Watchers: 28
- Forks: 179
- Open Issues: 25
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
Official implementation:
- CMC: Contrastive Multiview Coding ([Paper](http://arxiv.org/abs/1906.05849))
Unofficial implementation:
- MoCo: Momentum Contrast for Unsupervised Visual Representation Learning ([Paper](https://arxiv.org/abs/1911.05722))
- InsDis: Unsupervised Feature Learning via Non-Parametric Instance-level Discrimination ([Paper](https://arxiv.org/abs/1805.01978))
## Citation
If you find this repo useful for your research, please consider citing the paper
```
@article{tian2019contrastive,
title={Contrastive Multiview Coding},
author={Tian, Yonglong and Krishnan, Dilip and Isola, Phillip},
journal={arXiv preprint arXiv:1906.05849},
year={2019}
}
```
## Contrastive Multiview Coding
This repo covers the implementation for CMC (as well as Momentum Contrast and Instance Discrimination), which learns representations from multiview data in a self-supervised way (by multiview, we mean multiple sensory, multiple modal data, or literally multiple viewpoint data. It's flexible to define what is a "view"):
"Contrastive Multiview Coding" [Paper](http://arxiv.org/abs/1906.05849), [Project Page](http://hobbitlong.github.io/CMC/).
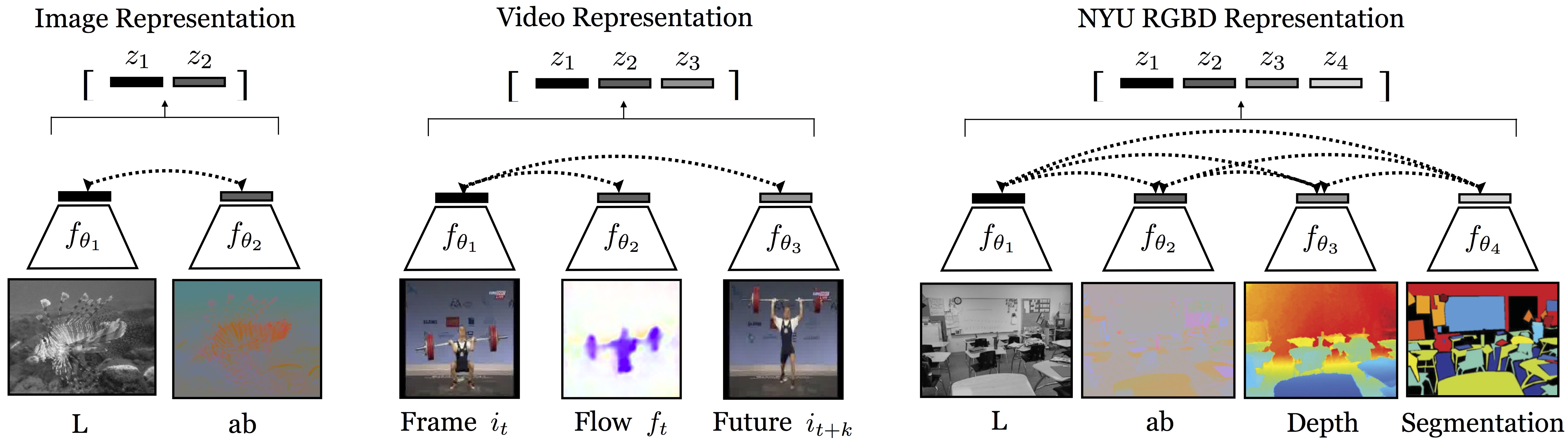
## Highlights
**(1) Representation quality as a function of number of contrasted views.**
We found that, the more views we train with, the better the representation (of each single view).
**(2) Contrastive objective v.s. Predictive objective**
We compare the contrastive objective to cross-view prediction, finding an advantage to the contrastive approach.
**(3) Unsupervised v.s. Supervised**
Several ResNets trained with our **unsupervised** CMC objective surpasses **supervisedly** trained AlexNet on ImageNet classification ( e.g., 68.4% v.s. 59.3%). For this first time on ImageNet classification, unsupervised methods are surpassing the classic supervised-AlexNet proposed in 2012 (CPC++ and AMDIM also achieve this milestone concurrently).
## Updates
Aug 20, 2019 - ResNets on ImageNet have been added.
Nov 26, 2019 - New results updated. Implementation of **MoCo** and **InsDis** added.
Jan 18, 2020 - Weights of **InsDis** and **MoCo** added.
May 22, 2020 - ImageNet-100 list uploaded, see [`imagenet100.txt`](imagenet100.txt).
## Installation
This repo was tested with Ubuntu 16.04.5 LTS, Python 3.5, PyTorch 0.4.0, and CUDA 9.0. But it should be runnable with recent PyTorch versions >=0.4.0
**Note:** It seems to us that training with Pytorch version >= 1.0 yields slightly worse results. If you find the similar discrepancy and figure out the problem, please report this since we are trying to fix it as well.
## Training AlexNet/ResNets with CMC on ImageNet
**Note:** For AlexNet, we split across the channel dimension and use each half to encode L and ab. For ResNets, we use a standard ResNet model to encode each view.
NCE flags:
- `--nce_k`: number of negatives to contrast for each positive. Default: 4096
- `--nce_m`: the momentum for dynamically updating the memory. Default: 0.5
- `--nce_t`: temperature that modulates the distribution. Default: 0.07 for ImageNet, 0.1 for STL-10
Path flags:
- `--data_folder`: specify the ImageNet data folder.
- `--model_path`: specify the path to save model.
- `--tb_path`: specify where to save tensorboard monitoring events.
Model flag:
- `--model`: specify which model to use, including *alexnet*, *resnets18*, *resnets50*, and *resnets101*
An example of command line for training CMC (Default: `AlexNet` on Single GPU)
```
CUDA_VISIBLE_DEVICES=0 python train_CMC.py --batch_size 256 --num_workers 36 \
--data_folder /path/to/data
--model_path /path/to/save
--tb_path /path/to/tensorboard
```
Training CMC with ResNets requires at least 4 GPUs, the command of using `resnet50v1` looks like
```
CUDA_VISIBLE_DEVICES=0,1,2,3 python train_CMC.py --model resnet50v1 --batch_size 128 --num_workers 24
--data_folder path/to/data \
--model_path path/to/save \
--tb_path path/to/tensorboard \
```
To support mixed precision training, simply append the flag `--amp`, which, however is likely to harm the downstream classification. I measure it on ImageNet100 subset and the gap is about 0.5-1%.
By default, the training scripts will use L and ab as two views for contrasting. You can switch to `YCbCr` by specifying `--view YCbCr`, which yields better results (about 0.5-1%). If you want to use other color spaces as different views, follow the line [here](https://github.com/HobbitLong/CMC/blob/master/train_CMC.py#L146) and other color transfer functions are already available in `dataset.py`.
## Training Linear Classifier
Path flags:
- `--data_folder`: specify the ImageNet data folder. Should be the same as above.
- `--save_path`: specify the path to save the linear classifier.
- `--tb_path`: specify where to save tensorboard events monitoring linear classifier training.
Model flag `--model` is similar as above and should be specified.
Specify the checkpoint that you want to evaluate with `--model_path` flag, this path should directly point to the `.pth` file.
This repo provides 3 ways to train the linear classifier: *single GPU*, *data parallel*, and *distributed data parallel*.
An example of command line for evaluating, say `./models/alexnet.pth`, should look like:
```
CUDA_VISIBLE_DEVICES=0 python LinearProbing.py --dataset imagenet \
--data_folder /path/to/data \
--save_path /path/to/save \
--tb_path /path/to/tensorboard \
--model_path ./models/alexnet.pth \
--model alexnet --learning_rate 0.1 --layer 5
```
**Note:** When training linear classifiers on top of ResNets, it's important to use large learning rate, e.g., 30~50. Specifically, change `--learning_rate 0.1 --layer 5` to `--learning_rate 30 --layer 6` for `resnet50v1` and `resnet50v2`, to `--learning_rate 50 --layer 6` for `resnet50v3`.
## Pretrained Models
Pretrained weights can be found in [Dropbox](https://www.dropbox.com/sh/5k4t77mt4011gyr/AABkBvKm2bGNNut0m6bLMK84a?dl=0).
Note:
- CMC weights are trained with `NCE` loss, `Lab` color space, `4096` negatives and `amp` option. Switching to `softmax-ce` loss, `YCbCr`, `65536` negatives, and turning off `amp` option, are likely to improve the results.
- `CMC_resnet50v2.pth` and `CMC_resnet50v3.pth` are trained with FastAutoAugment, which improves the downstream accuracy by 0.8~1%. I will update weights without FastAutoAugment once they are available.
InsDis and MoCo are trained using the same hyperparameters as in MoCo (`epochs=200, lr=0.03, lr_decay_epochs=120,160, weight_decay=1e-4`), but with only 4 GPUs.
| |Arch | #Params(M) | Loss | #Negative | Accuracy(%) | Delta(%) |
|----------|:----:|:---:|:---:|:---:|:---:|:---:|
| InsDis | ResNet50 | 24 | NCE | 4096 | 56.5 | - |
| InsDis | ResNet50 | 24 | Softmax-CE | 4096 | 57.1 | +0.6 |
| InsDis | ResNet50 | 24 | Softmax-CE | 16384 | 58.5 | +1.4 |
| MoCo | ResNet50 | 24 | Softmax-CE | 16384 | 59.4 | +0.9|
## Momentum Contrast and Instance Discrimination
I have implemented and tested MoCo and InsDis on a ImageNet100 subset (but the code allows one to train on full ImageNet simply by setting the flag `--dataset imagenet`):
The pre-training stage:
- For InsDis:
```
CUDA_VISIBLE_DEVICES=0,1,2,3 python train_moco_ins.py \
--batch_size 128 --num_workers 24 --nce_k 16384 --softmax
```
- For MoCo:
```
CUDA_VISIBLE_DEVICES=0,1,2,3 python train_moco_ins.py \
--batch_size 128 --num_workers 24 --nce_k 16384 --softmax --moco
```
The linear evaluation stage:
- For both InsDis and MoCo (lr=10 is better than 30 on this subset, for full imagenet please switch to 30):
```
CUDA_VISIBLE_DEVICES=0 python eval_moco_ins.py --model resnet50 \
--model_path /path/to/model --num_workers 24 --learning_rate 10
```
The comparison of `CMC` (using YCbCr), `MoCo` and `InsDIS` on my ImageNet100 subset, is tabulated as below:
| |Arch | #Params(M) | Loss | #Negative | Accuracy |
|----------|:----:|:---:|:---:|:---:|:---:|
| InsDis | ResNet50 | 24 | NCE | 16384 | -- |
| InsDis | ResNet50 | 24 | Softmax-CE | 16384 | 69.1 |
| MoCo | ResNet50 | 24 | NCE | 16384 | -- |
| MoCo | ResNet50 | 24 | Softmax-CE | 16384 | 73.4 |
| CMC | 2xResNet50half | 12 | NCE | 4096 | -- |
| CMC | 2xResNet50half | 12 | Softmax-CE | 4096 | 75.8 |
For any questions, please contact Yonglong Tian ([email protected]).
## Acknowledgements
Part of this code is inspired by Zhirong Wu's unsupervised learning algorithm [lemniscate](https://github.com/zhirongw/lemniscate.pytorch).