https://github.com/IliaZenkov/sklearn-audio-classification
An in-depth analysis of audio classification on the RAVDESS dataset. Feature engineering, hyperparameter optimization, model evaluation, and cross-validation with a variety of ML techniques and MLP
https://github.com/IliaZenkov/sklearn-audio-classification
audio audio-data classification deep-learning-tutorial deep-neural-networks dnns emotion emotion-detection emotion-recognition feature-engineering machine-learning machine-learning-tutorials mlp-model model-evaluation ravdess-dataset scikit-learn sklearn
Last synced: over 1 year ago
JSON representation
An in-depth analysis of audio classification on the RAVDESS dataset. Feature engineering, hyperparameter optimization, model evaluation, and cross-validation with a variety of ML techniques and MLP
- Host: GitHub
- URL: https://github.com/IliaZenkov/sklearn-audio-classification
- Owner: IliaZenkov
- License: mit
- Created: 2020-10-01T03:53:47.000Z (almost 6 years ago)
- Default Branch: master
- Last Pushed: 2020-11-05T21:33:16.000Z (over 5 years ago)
- Last Synced: 2024-10-28T16:45:32.603Z (over 1 year ago)
- Topics: audio, audio-data, classification, deep-learning-tutorial, deep-neural-networks, dnns, emotion, emotion-detection, emotion-recognition, feature-engineering, machine-learning, machine-learning-tutorials, mlp-model, model-evaluation, ravdess-dataset, scikit-learn, sklearn
- Language: Jupyter Notebook
- Homepage:
- Size: 4.77 MB
- Stars: 72
- Watchers: 2
- Forks: 18
- Open Issues: 1
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- awesome-sources - Introduction to Audio Classification with Deep Neural Networks - of-the-art. (Audio ##)
README
# Introduction to Audio Classification with Deep Neural Networks
## [See Notebook for Code Walk-Through](https://nbviewer.jupyter.org/github/IliaZenkov/sklearn-audio-classification/blob/master/sklearn_audio_classification.ipynb)
# Table of Contents
- [Intro: Speech Emotion Recognition on the RAVDESS dataset](https://nbviewer.jupyter.org/github/IliaZenkov/sklearn-audio-classification/blob/master/sklearn_audio_classification.ipynb#Intro:-Speech-Emotion-Recognition-on-the-RAVDESS-dataset)
- [Machine Learning Process Overview](https://nbviewer.jupyter.org/github/IliaZenkov/sklearn-audio-classification/blob/master/sklearn_audio_classification.ipynb#Machine-Learning-Process-Overview)
- [Feature Engineering](https://nbviewer.jupyter.org/github/IliaZenkov/sklearn-audio-classification/blob/master/sklearn_audio_classification.ipynb#Feature-Engineering)
- [Short-Time Fourier Transform](https://nbviewer.jupyter.org/github/IliaZenkov/sklearn-audio-classification/blob/master/sklearn_audio_classification.ipynb#Short-Time-Fourier-Transform)
- [Mel-Frequency Cepstral Coefficients](https://nbviewer.jupyter.org/github/IliaZenkov/sklearn-audio-classification/blob/master/sklearn_audio_classification.ipynb#Mel-Frequency-Cepstral-Coefficients)
- [Mel Spectrograms and Mel-Frequency Cepstrums](https://nbviewer.jupyter.org/github/IliaZenkov/sklearn-audio-classification/blob/master/sklearn_audio_classification.ipynb#Mel-Spectrograms-and-Mel-Frequency-Cepstrums)
- [The Chromagram](https://nbviewer.jupyter.org/github/IliaZenkov/sklearn-audio-classification/blob/master/sklearn_audio_classification.ipynb#The-Chromagram)
- [Feature Extraction](https://nbviewer.jupyter.org/github/IliaZenkov/sklearn-audio-classification/blob/master/sklearn_audio_classification.ipynb#Feature-Extraction)
- [Load the Dataset and Compute Features](https://nbviewer.jupyter.org/github/IliaZenkov/sklearn-audio-classification/blob/master/sklearn_audio_classification.ipynb#Load-the-Dataset-and-Compute-Features)
- [Feature Scaling](https://nbviewer.jupyter.org/github/IliaZenkov/sklearn-audio-classification/blob/master/sklearn_audio_classification.ipynb#Feature-Scaling)
- [Classical Machine Learning Models](https://nbviewer.jupyter.org/github/IliaZenkov/sklearn-audio-classification/blob/master/sklearn_audio_classification.ipynb#Classical-Machine-Learning-Models)
- [Training: The 80/20 Split and Validation](https://nbviewer.jupyter.org/github/IliaZenkov/sklearn-audio-classification/blob/master/sklearn_audio_classification.ipynb#Training:-The-80/20-Split-and-Validation)
- [Comparing Models](https://nbviewer.jupyter.org/github/IliaZenkov/sklearn-audio-classification/blob/master/sklearn_audio_classification.ipynb#Comparing-Models)
- [The Support Vector Machine Classifier](https://nbviewer.jupyter.org/github/IliaZenkov/sklearn-audio-classification/blob/master/sklearn_audio_classification.ipynb#The-Support-Vector-Machine-Classifier)
- [k Nearest Neighbours](https://nbviewer.jupyter.org/github/IliaZenkov/sklearn-audio-classification/blob/master/sklearn_audio_classification.ipynb#k-Nearest-Neighbours)
- [Random Forests](https://nbviewer.jupyter.org/github/IliaZenkov/sklearn-audio-classification/blob/master/sklearn_audio_classification.ipynb#Random-Forests)
- [OOB Score](https://nbviewer.jupyter.org/github/IliaZenkov/sklearn-audio-classification/blob/master/sklearn_audio_classification.ipynb#OOB-Score)
- [The MLP Model for Classification](https://nbviewer.jupyter.org/github/IliaZenkov/sklearn-audio-classification/blob/master/sklearn_audio_classification.ipynb#The-MLP-Model-for-Classification)
- [Choice of Hyperparameters](https://nbviewer.jupyter.org/github/IliaZenkov/sklearn-audio-classification/blob/master/sklearn_audio_classification.ipynb#Choice-of-Hyperparameters)
- [Network Architecture](https://nbviewer.jupyter.org/github/IliaZenkov/sklearn-audio-classification/blob/master/sklearn_audio_classification.ipynb#Network-Architecture)
- [Hyperparameter Optimization and Grid Search](https://nbviewer.jupyter.org/github/IliaZenkov/sklearn-audio-classification/blob/master/sklearn_audio_classification.ipynb#Hyperparameter-Optimization-and-Grid-Search)
- [Training and Evaluating the MLP Model](https://nbviewer.jupyter.org/github/IliaZenkov/sklearn-audio-classification/blob/master/sklearn_audio_classification.ipynb#Training-and-Evaluating-the-MLP-Model)
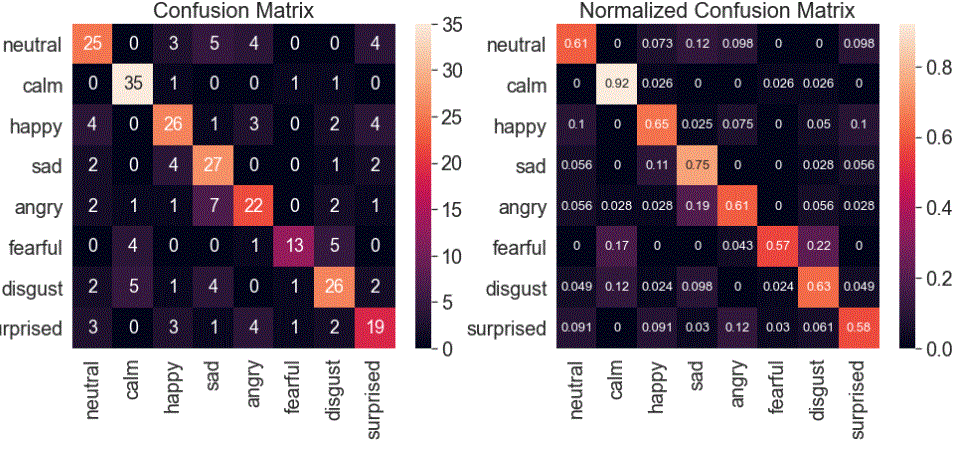
- [The Confusion Matrix](https://nbviewer.jupyter.org/github/IliaZenkov/sklearn-audio-classification/blob/master/sklearn_audio_classification.ipynb#The-Confusion-Matrix)
- [Precision, Recall, F-Score](https://nbviewer.jupyter.org/github/IliaZenkov/sklearn-audio-classification/blob/master/sklearn_audio_classification.ipynb#Precision,-Recall,-F-Score)
- [K-Fold Cross-Validation](https://nbviewer.jupyter.org/github/IliaZenkov/sklearn-audio-classification/blob/master/sklearn_audio_classification.ipynb#K-Fold-Cross-Validation)
- [The Validation Curve: Further Tuning of Hyperparameters](https://nbviewer.jupyter.org/github/IliaZenkov/sklearn-audio-classification/blob/master/sklearn_audio_classification.ipynb#The-Validation-Curve:-Further-Tuning-of-Hyperparameters)
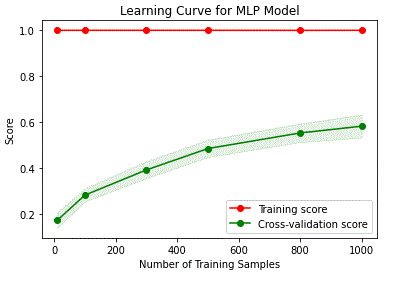
- [The Learning Curve: Determining Optimal Training Set Size](https://nbviewer.jupyter.org/github/IliaZenkov/sklearn-audio-classification/blob/master/sklearn_audio_classification.ipynb#The-Learning-Curve:-Determining-Optimal-Training-Set-Size)
- [Conclusion & Higher Complexity DNNs](https://nbviewer.jupyter.org/github/IliaZenkov/sklearn-audio-classification/blob/master/sklearn_audio_classification.ipynb#Conclusion)
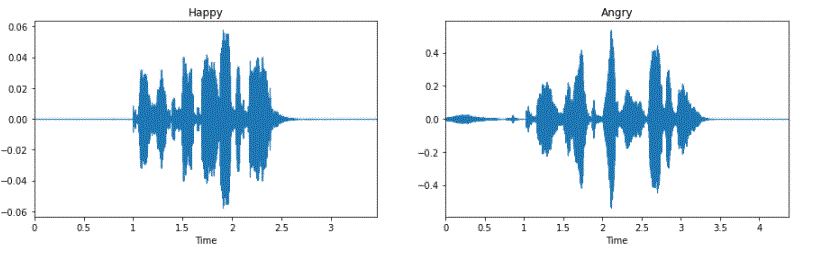
|Power Spectrogram | Chromagram|
|---------------------------|------------------|
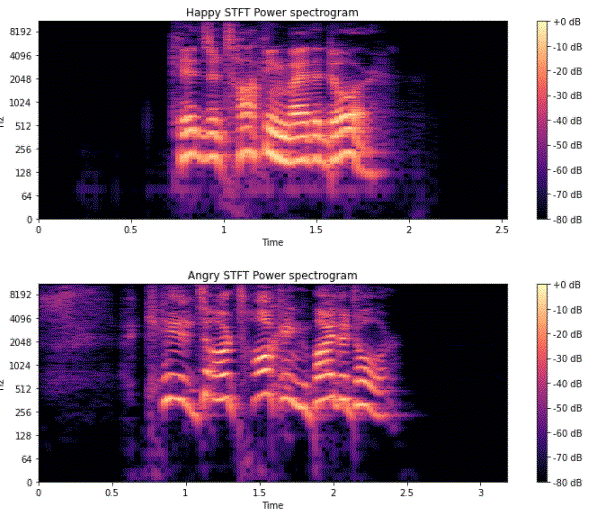 |
| 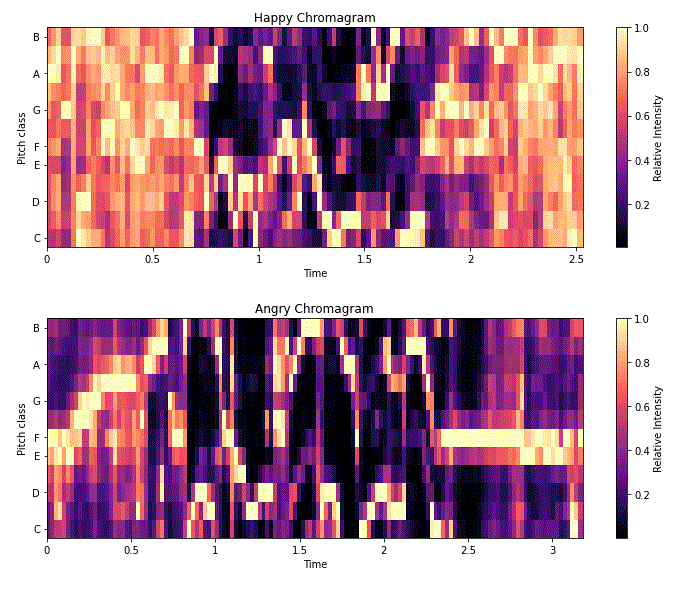 |
|
|Mel Spectrogram | MFC Coefficients|
|--------------------------|------------------|
|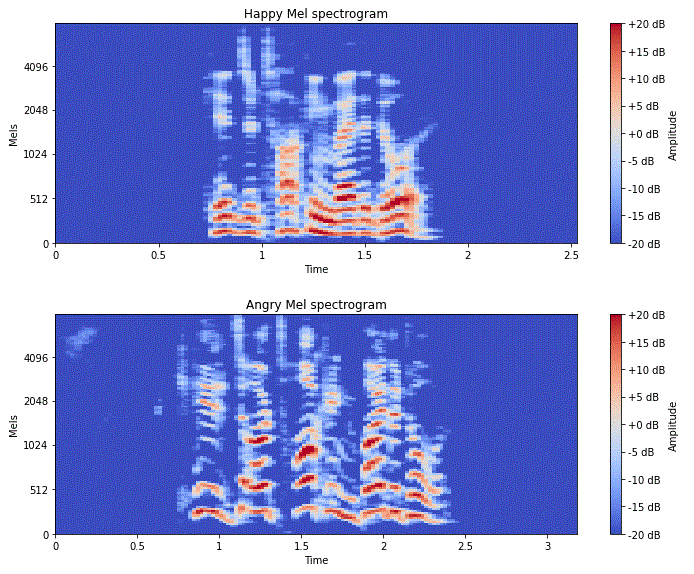 |
| 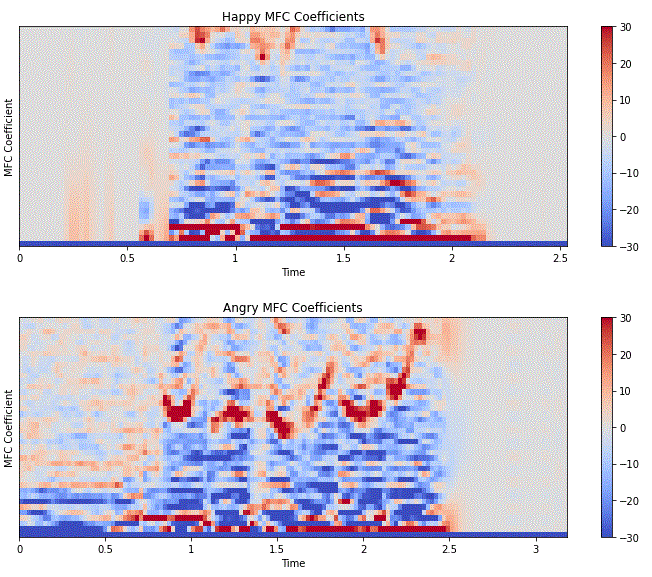 |
|
# Abstract
## Purpose
This notebook serves as an introduction to working with audio data for classification problems; it is meant as a learning resource rather than a demonstration of the state-of-the-art. The techniques mentioned in this notebook apply not only to classification problems, but to regression problems and problems dealing with other types of input data as well. I focus particularly on feature engineering techniques for audio data and provide an in-depth look at the logic, concepts, and properties of the Multilayer Perceptron (MLP) model, an ancestor and the origin of deep neural networks (DNNs) today. I also provide an introduction to a few key machine learning models and the logic in choosing their hyperparameters. These objectives are framed by the task of recognizing emotion from snippets of speech audio from the [RAVDESS dataset](https://smartlaboratory.org/ravdess/).
## Summary
Data cleansing and feature engineering comprise the most crucial aspect of preparing machine and deep learning models alike and is often the difference between success and failure. We can drastically improve the performance of a model with proper attention paid to feature engineering. This stands for input data which is already useable for predictions; even such data can be transformed in myriad ways to improve predictive performance. For features to be useful in classification they must encompass sufficient variance between different classes. We can further improve the performance of our models by understanding the influence of and precisely tuning their hyperparameters, for which there are algorithmic aids such as Grid Search.
Network architecture is a critical factor in determining the computational complexity of DNNs; often, however, simpler models with just one hidden layer perform better than more complicated models. The importance of proper model evaluation cannot be overstressed: training data should be used strictly for training a model, validation data strictly for tuning a model, and test data strictly to evaluate a model once it is tuned - a model should never be tuned to perform better on test data. To this end, K-Fold Cross Validation is a staple tool. Finally, the Random Forest ensemble model makes a robust benchmark model suitable to less-than-clean data with unkown distribution, especially when strapped for time and wishing to evaluate the useability of features extracted from a dataset.
## Conclusions
Classic machine learning models such as Support Vector Machines (SVM), k Nearest Neighbours (kNN), and Random Forests have distinct advantages to deep neural networks in many tasks but do not match the performance of even the simplest deep neural network in the task of audio classification. The Multilayer Perceptron (MLP) model is the simplest form of DNN suited to classification tasks, provides decent off-the-shelf performance, and can be precisely tuned to be accurate and relatively quick to train.
The MLP provides appreciable accuracy on the RAVDESS dataset, but suffers from the relatively small number of training samples afforded by this dataset. Long Short Term Memory Recurrent Neural Networks (LSTM RNNs) and Convolutional Neural Networks (CNNs) are excellent DNN candidates for audio data classification: LSTM RNNs because of their excellent ability to interpret sequential data such as the audio waveform represented as a time series, and CNNs because features engineered on audio data such as spectrograms have marked resemblance to images, in which CNNs excel at recognition and discrimination between distinct patterns.
## Cite
If you find this work useful in your own research, please cite as follows:
```
@misc{Zenkov-sklearn-SER-basics,
author = {Zenkov, Ilia},
title = {sklearn-audio-classification},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/IliaZenkov/sklearn-audio-classification}},
}
```
## Licence
[](https://github.com/IliaZenkov/sklearn-audio-classification/blob/master/LICENSE)