https://github.com/InternLM/xtuner
An efficient, flexible and full-featured toolkit for fine-tuning LLM (InternLM2, Llama3, Phi3, Qwen, Mistral, ...)
https://github.com/InternLM/xtuner
agent baichuan chatbot chatglm2 chatglm3 conversational-ai internlm large-language-models llama2 llama3 llava llm llm-training mixtral msagent peft phi3 qwen supervised-finetuning
Last synced: over 1 year ago
JSON representation
An efficient, flexible and full-featured toolkit for fine-tuning LLM (InternLM2, Llama3, Phi3, Qwen, Mistral, ...)
- Host: GitHub
- URL: https://github.com/InternLM/xtuner
- Owner: InternLM
- License: apache-2.0
- Created: 2023-07-11T03:18:13.000Z (about 3 years ago)
- Default Branch: main
- Last Pushed: 2025-03-17T19:51:01.000Z (over 1 year ago)
- Last Synced: 2025-03-17T22:11:26.212Z (over 1 year ago)
- Topics: agent, baichuan, chatbot, chatglm2, chatglm3, conversational-ai, internlm, large-language-models, llama2, llama3, llava, llm, llm-training, mixtral, msagent, peft, phi3, qwen, supervised-finetuning
- Language: Python
- Homepage: https://xtuner.readthedocs.io/zh-cn/latest/
- Size: 2.28 MB
- Stars: 4,387
- Watchers: 36
- Forks: 331
- Open Issues: 246
-
Metadata Files:
- Readme: README.md
- Contributing: .github/CONTRIBUTING.md
- License: LICENSE
Awesome Lists containing this project
- StarryDivineSky - InternLM/xtuner
- alan_awesome_llm - Xtuner - featured toolkit for fine-tuning large models. (微调 Fine-Tuning)
- awesome-LLM-resources - Xtuner - featured toolkit for fine-tuning large models. (微调 Fine-Tuning)
- AiTreasureBox - InternLM/xtuner - 11-03_4964_0](https://img.shields.io/github/stars/InternLM/xtuner.svg)|An efficient, flexible and full-featured toolkit for fine-tuning large models (InternLM, Llama, Baichuan, Qwen, ChatGLM)| (Repos)
- Awesome-Multimodal-Modeling - Code
- awesome-opensource-ai - XTuner - A next-generation training engine built for ultra-large MoE models with efficient QLoRA and full-parameter fine-tuning. Apache 2.0 licensed.  (7. Training & Fine-tuning Ecosystem)
- awesome-LLMs-finetuning - xtuner - tuning LLM (InternLM, Llama, Baichuan, QWen, ChatGLM2). (540 stars) (4. Fine-Tuning / Frameworks)
- awesome-ai-agents - InternLM/xtuner - XTuner is a comprehensive and efficient toolkit for fine-tuning large language and vision-language models, supporting a wide range of models and training algorithms with scalability and flexibility. (Autonomous Research & Content Generation / Programming Languages)
- awesome-production-llm - xtuner - featured toolkit for fine-tuning LLM (InternLM2, Llama3, Phi3, Qwen, Mistral, ...) (LLM Training / Finetuning)
- awesome-llms-fine-tuning - xtuner - tuning LLM (InternLM, Llama, Baichuan, QWen, ChatGLM2). (540 stars) (GitHub projects)
- awesome-open-source-ai-tools - InternLM/xtuner - An efficient, flexible and full-featured toolkit for fine-tuning LLM (InternLM2, Llama3, Phi3, Qwen, Mistral, ...) (Other AI Tools)
README

[](https://github.com/InternLM/xtuner/stargazers)
[](https://github.com/InternLM/xtuner/blob/main/LICENSE)
[](https://pypi.org/project/xtuner/)
[](https://pypi.org/project/xtuner/)
[](https://github.com/InternLM/xtuner/issues)
[](https://github.com/InternLM/xtuner/issues)
👋 join us on [](https://cdn.vansin.top/internlm/xtuner.jpg)
[](https://twitter.com/intern_lm)
[](https://discord.gg/xa29JuW87d)
🔍 Explore our models on
[](https://huggingface.co/xtuner)
[](https://www.modelscope.cn/organization/xtuner)
[](https://openxlab.org.cn/usercenter/xtuner)
[](https://www.wisemodel.cn/organization/xtuner)
English | [简体中文](README_zh-CN.md)
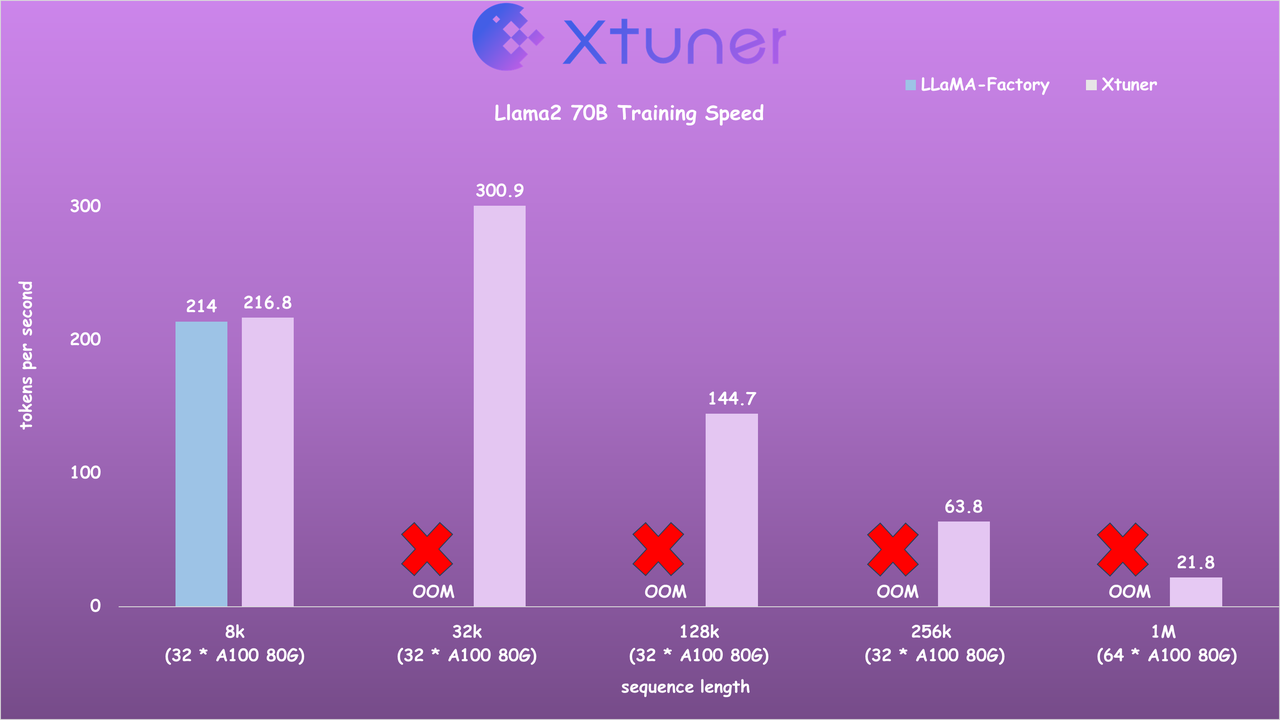
## 🚀 Speed Benchmark
- Llama2 7B Training Speed

- Llama2 70B Training Speed
## 🎉 News
- **\[2025/02\]** Support [OREAL](https://github.com/InternLM/OREAL), a new RL method for math reasoning!
- **\[2025/01\]** Support [InternLM3 8B Instruct](https://huggingface.co/internlm/internlm3-8b-instruct)!
- **\[2024/07\]** Support [MiniCPM](xtuner/configs/minicpm/) models!
- **\[2024/07\]** Support [DPO](https://github.com/InternLM/xtuner/tree/main/xtuner/configs/dpo), [ORPO](https://github.com/InternLM/xtuner/tree/main/xtuner/configs/orpo) and [Reward Model](https://github.com/InternLM/xtuner/tree/main/xtuner/configs/reward_model) training with packed data and sequence parallel! See [documents](https://xtuner.readthedocs.io/en/latest/dpo/overview.html) for more details.
- **\[2024/07\]** Support [InternLM 2.5](xtuner/configs/internlm/internlm2_5_chat_7b/) models!
- **\[2024/06\]** Support [DeepSeek V2](xtuner/configs/deepseek/deepseek_v2_chat/) models! **2x faster!**
- **\[2024/04\]** [LLaVA-Phi-3-mini](https://huggingface.co/xtuner/llava-phi-3-mini-hf) is released! Click [here](xtuner/configs/llava/phi3_mini_4k_instruct_clip_vit_large_p14_336) for details!
- **\[2024/04\]** [LLaVA-Llama-3-8B](https://huggingface.co/xtuner/llava-llama-3-8b) and [LLaVA-Llama-3-8B-v1.1](https://huggingface.co/xtuner/llava-llama-3-8b-v1_1) are released! Click [here](xtuner/configs/llava/llama3_8b_instruct_clip_vit_large_p14_336) for details!
- **\[2024/04\]** Support [Llama 3](xtuner/configs/llama) models!
- **\[2024/04\]** Support Sequence Parallel for enabling highly efficient and scalable LLM training with extremely long sequence lengths! \[[Usage](https://github.com/InternLM/xtuner/blob/docs/docs/zh_cn/acceleration/train_extreme_long_sequence.rst)\] \[[Speed Benchmark](https://github.com/InternLM/xtuner/blob/docs/docs/zh_cn/acceleration/benchmark.rst)\]
- **\[2024/02\]** Support [Gemma](xtuner/configs/gemma) models!
- **\[2024/02\]** Support [Qwen1.5](xtuner/configs/qwen/qwen1_5) models!
- **\[2024/01\]** Support [InternLM2](xtuner/configs/internlm) models! The latest VLM [LLaVA-Internlm2-7B](https://huggingface.co/xtuner/llava-internlm2-7b) / [20B](https://huggingface.co/xtuner/llava-internlm2-20b) models are released, with impressive performance!
- **\[2024/01\]** Support [DeepSeek-MoE](https://huggingface.co/deepseek-ai/deepseek-moe-16b-chat) models! 20GB GPU memory is enough for QLoRA fine-tuning, and 4x80GB for full-parameter fine-tuning. Click [here](xtuner/configs/deepseek/) for details!
- **\[2023/12\]** 🔥 Support multi-modal VLM pretraining and fine-tuning with [LLaVA-v1.5](https://github.com/haotian-liu/LLaVA) architecture! Click [here](xtuner/configs/llava/README.md) for details!
- **\[2023/12\]** 🔥 Support [Mixtral 8x7B](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) models! Click [here](xtuner/configs/mixtral/README.md) for details!
- **\[2023/11\]** Support [ChatGLM3-6B](xtuner/configs/chatglm) model!
- **\[2023/10\]** Support [MSAgent-Bench](https://modelscope.cn/datasets/damo/MSAgent-Bench) dataset, and the fine-tuned LLMs can be applied by [Lagent](https://github.com/InternLM/lagent)!
- **\[2023/10\]** Optimize the data processing to accommodate `system` context. More information can be found on [Docs](docs/en/user_guides/dataset_format.md)!
- **\[2023/09\]** Support [InternLM-20B](xtuner/configs/internlm) models!
- **\[2023/09\]** Support [Baichuan2](xtuner/configs/baichuan) models!
- **\[2023/08\]** XTuner is released, with multiple fine-tuned adapters on [Hugging Face](https://huggingface.co/xtuner).
## 📖 Introduction
XTuner is an efficient, flexible and full-featured toolkit for fine-tuning large models.
**Efficient**
- Support LLM, VLM pre-training / fine-tuning on almost all GPUs. XTuner is capable of fine-tuning 7B LLM on a single 8GB GPU, as well as multi-node fine-tuning of models exceeding 70B.
- Automatically dispatch high-performance operators such as FlashAttention and Triton kernels to increase training throughput.
- Compatible with [DeepSpeed](https://github.com/microsoft/DeepSpeed) 🚀, easily utilizing a variety of ZeRO optimization techniques.
**Flexible**
- Support various LLMs ([InternLM](https://huggingface.co/internlm), [Mixtral-8x7B](https://huggingface.co/mistralai), [Llama 2](https://huggingface.co/meta-llama), [ChatGLM](https://huggingface.co/THUDM), [Qwen](https://huggingface.co/Qwen), [Baichuan](https://huggingface.co/baichuan-inc), ...).
- Support VLM ([LLaVA](https://github.com/haotian-liu/LLaVA)). The performance of [LLaVA-InternLM2-20B](https://huggingface.co/xtuner/llava-internlm2-20b) is outstanding.
- Well-designed data pipeline, accommodating datasets in any format, including but not limited to open-source and custom formats.
- Support various training algorithms ([QLoRA](http://arxiv.org/abs/2305.14314), [LoRA](http://arxiv.org/abs/2106.09685), full-parameter fune-tune), allowing users to choose the most suitable solution for their requirements.
**Full-featured**
- Support continuous pre-training, instruction fine-tuning, and agent fine-tuning.
- Support chatting with large models with pre-defined templates.
- The output models can seamlessly integrate with deployment and server toolkit ([LMDeploy](https://github.com/InternLM/lmdeploy)), and large-scale evaluation toolkit ([OpenCompass](https://github.com/open-compass/opencompass), [VLMEvalKit](https://github.com/open-compass/VLMEvalKit)).
## 🔥 Supports
Models
SFT Datasets
Data Pipelines
Algorithms
- InternLM2 / 2.5
- Llama 2 / 3
- Phi-3
- ChatGLM2
- ChatGLM3
- Qwen
- Baichuan2
- Mixtral
- DeepSeek V2
- Gemma
- MiniCPM
- ...
- MSAgent-Bench
-
MOSS-003-SFT 🔧 -
Alpaca en / zh - WizardLM
- oasst1
- Open-Platypus
- Code Alpaca
-
Colorist 🎨 - Arxiv GenTitle
- Chinese Law
- OpenOrca
- Medical Dialogue
- ...
## 🛠️ Quick Start
### Installation
- It is recommended to build a Python-3.10 virtual environment using conda
```bash
conda create --name xtuner-env python=3.10 -y
conda activate xtuner-env
```
- Install XTuner via pip
```shell
pip install -U xtuner
```
or with DeepSpeed integration
```shell
pip install -U 'xtuner[deepspeed]'
```
- Install XTuner from source
```shell
git clone https://github.com/InternLM/xtuner.git
cd xtuner
pip install -e '.[all]'
```
### Fine-tune
XTuner supports the efficient fine-tune (*e.g.*, QLoRA) for LLMs. Dataset prepare guides can be found on [dataset_prepare.md](./docs/en/user_guides/dataset_prepare.md).
- **Step 0**, prepare the config. XTuner provides many ready-to-use configs and we can view all configs by
```shell
xtuner list-cfg
```
Or, if the provided configs cannot meet the requirements, please copy the provided config to the specified directory and make specific modifications by
```shell
xtuner copy-cfg ${CONFIG_NAME} ${SAVE_PATH}
vi ${SAVE_PATH}/${CONFIG_NAME}_copy.py
```
- **Step 1**, start fine-tuning.
```shell
xtuner train ${CONFIG_NAME_OR_PATH}
```
For example, we can start the QLoRA fine-tuning of InternLM2.5-Chat-7B with oasst1 dataset by
```shell
# On a single GPU
xtuner train internlm2_5_chat_7b_qlora_oasst1_e3 --deepspeed deepspeed_zero2
# On multiple GPUs
(DIST) NPROC_PER_NODE=${GPU_NUM} xtuner train internlm2_5_chat_7b_qlora_oasst1_e3 --deepspeed deepspeed_zero2
(SLURM) srun ${SRUN_ARGS} xtuner train internlm2_5_chat_7b_qlora_oasst1_e3 --launcher slurm --deepspeed deepspeed_zero2
```
- `--deepspeed` means using [DeepSpeed](https://github.com/microsoft/DeepSpeed) 🚀 to optimize the training. XTuner comes with several integrated strategies including ZeRO-1, ZeRO-2, and ZeRO-3. If you wish to disable this feature, simply remove this argument.
- For more examples, please see [finetune.md](./docs/en/user_guides/finetune.md).
- **Step 2**, convert the saved PTH model (if using DeepSpeed, it will be a directory) to Hugging Face model, by
```shell
xtuner convert pth_to_hf ${CONFIG_NAME_OR_PATH} ${PTH} ${SAVE_PATH}
```
### Chat
XTuner provides tools to chat with pretrained / fine-tuned LLMs.
```shell
xtuner chat ${NAME_OR_PATH_TO_LLM} --adapter {NAME_OR_PATH_TO_ADAPTER} [optional arguments]
```
For example, we can start the chat with InternLM2.5-Chat-7B :
```shell
xtuner chat internlm/internlm2_5-chat-7b --prompt-template internlm2_chat
```
For more examples, please see [chat.md](./docs/en/user_guides/chat.md).
### Deployment
- **Step 0**, merge the Hugging Face adapter to pretrained LLM, by
```shell
xtuner convert merge \
${NAME_OR_PATH_TO_LLM} \
${NAME_OR_PATH_TO_ADAPTER} \
${SAVE_PATH} \
--max-shard-size 2GB
```
- **Step 1**, deploy fine-tuned LLM with any other framework, such as [LMDeploy](https://github.com/InternLM/lmdeploy) 🚀.
```shell
pip install lmdeploy
python -m lmdeploy.pytorch.chat ${NAME_OR_PATH_TO_LLM} \
--max_new_tokens 256 \
--temperture 0.8 \
--top_p 0.95 \
--seed 0
```
🔥 Seeking efficient inference with less GPU memory? Try 4-bit quantization from [LMDeploy](https://github.com/InternLM/lmdeploy)! For more details, see [here](https://github.com/InternLM/lmdeploy/tree/main#quantization).
### Evaluation
- We recommend using [OpenCompass](https://github.com/InternLM/opencompass), a comprehensive and systematic LLM evaluation library, which currently supports 50+ datasets with about 300,000 questions.
## 🤝 Contributing
We appreciate all contributions to XTuner. Please refer to [CONTRIBUTING.md](.github/CONTRIBUTING.md) for the contributing guideline.
## 🎖️ Acknowledgement
- [Llama 2](https://github.com/facebookresearch/llama)
- [DeepSpeed](https://github.com/microsoft/DeepSpeed)
- [QLoRA](https://github.com/artidoro/qlora)
- [LMDeploy](https://github.com/InternLM/lmdeploy)
- [LLaVA](https://github.com/haotian-liu/LLaVA)
## 🖊️ Citation
```bibtex
@misc{2023xtuner,
title={XTuner: A Toolkit for Efficiently Fine-tuning LLM},
author={XTuner Contributors},
howpublished = {\url{https://github.com/InternLM/xtuner}},
year={2023}
}
```
## License
This project is released under the [Apache License 2.0](LICENSE). Please also adhere to the Licenses of models and datasets being used.