Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/IpsumLorem16/S3-key-lister
List all keys in any public AWS s3 bucket, option to check if each object is public or private
https://github.com/IpsumLorem16/S3-key-lister
Last synced: 3 months ago
JSON representation
List all keys in any public AWS s3 bucket, option to check if each object is public or private
- Host: GitHub
- URL: https://github.com/IpsumLorem16/S3-key-lister
- Owner: IpsumLorem16
- Created: 2019-02-20T14:18:47.000Z (over 5 years ago)
- Default Branch: master
- Last Pushed: 2019-03-05T18:48:14.000Z (over 5 years ago)
- Last Synced: 2024-05-27T12:01:48.690Z (6 months ago)
- Language: Python
- Size: 809 KB
- Stars: 7
- Watchers: 1
- Forks: 2
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# S3-key-lister
List all keys in any public Amazon s3 bucket, option to check if each object is public or private. Saves result as a .csv file
- Requires [Boto3](https://github.com/boto/boto3) `$ pip install boto3`
- Uses python 2.7
- No need for access keys, authentication or anything, runs 'anonymously'
- Saves key name, file size in bytes, date last modified, and 'public'|'private'|'unknown' in .csv [example](/examples/ryft.csv)
- Prints progress to command line while running, number of keys, num of public keys, and run time
## Usage:
```
python2 s3getkeys.py -t [--key=] [-r] [-v] [--acl] [-o=]
python2 s3getkeys.py -t [--key] [--estimate]
python2 s3getkeys.py -t [-h|--help]
Options:
-t, --bucket bucket to fetch keys from
--key key to start from
-r recursivly fetch all keys
-v verbose, print keys
--acl check if each key is public can take long time in large buckets
-o, --output name of output file, do not include .csv[default:bucket]
--estimate estimate how long to run [-r][--acl]
-h,--help show this help info
```
### Examples:
#### Fetch all keys
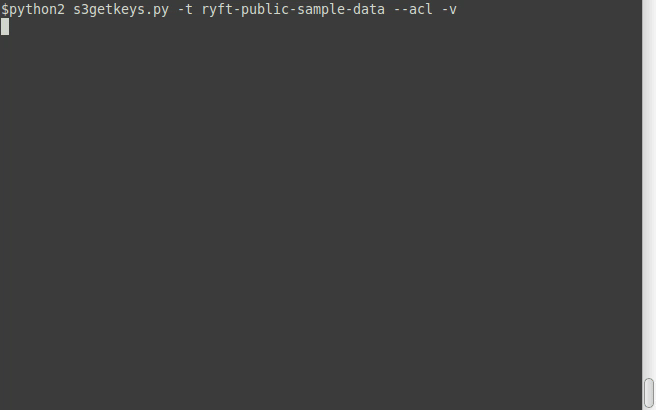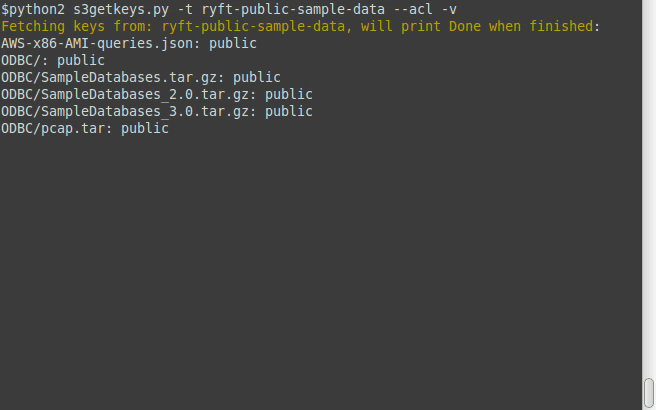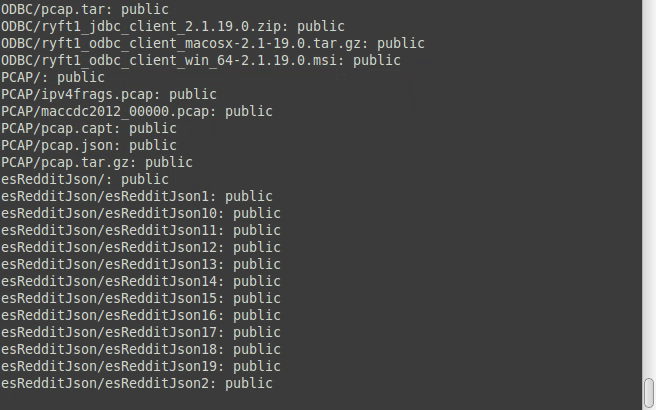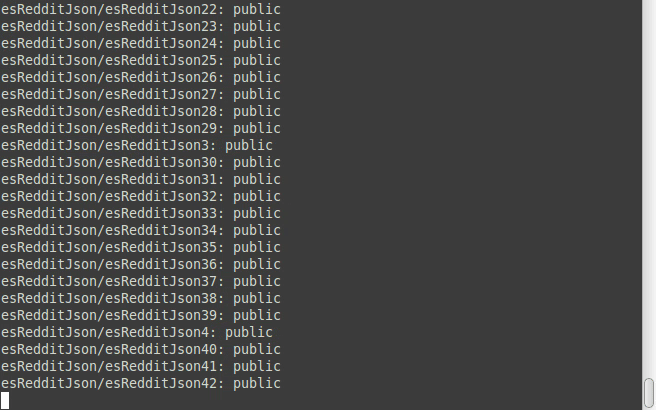
Fetch *all* keys from the public bucket; https://s3.amazonaws.com/ryft-public-sample-data , check which keys are public, and save it to a file called '[ryft.csv](/examples/ryft.csv)' :
```
$ python2 s3getkeys.py -t ryft-public-sample-data --acl -r -o ryft
```
You can ctrl+c to stop the script at any time if you need to, and your .csv file should have everything saved up to that point.
#### Get estimated query time
For larger buckets, it can take a while to run, get an estimated time on how long it might take with `-r` `--acl` options enabled :
```
$ python2 s3getkeys.py -t ryft-public-sample-data --estimate
```
Prints time in seconds, as well as number of keys, and average time for 20 head_object requests (what we use to determine if a key is public or private). If you know how many objects are in a bucket you can just wait for the average time, ctrl+c to stop, and then multiply this by the number of objects for the same result.
This is a very rough estimate, the actual the total time would depend on a lot of factors. use as a guide only.
#### Start from a particular key
You can start from any point in the bucket using the `--key` option:
```
$ python2 s3getkeys.py -t ryft-public-sample-data --key esRedditJson/esRedditJson9 --acl -r -o ryft
```
or
```
$ python2 s3getkeys.py -t ryft-public-sample-data --key esRedditJson/esRedditJson9 --estimate
```
This is especially useful if you previously used ctrl+c and want to continue from the last key found. Be careful, If you use the same filename it *will* overwrite *not* append it.
## Notes:
- Working, but still a work in progress.
- Made on linux for linux, might have bugs when running on windows, and printed text in the terminal..formatting will probably be a little screwed up.
- Large buckets with hundreds of thousands of keys can take a long time to go over with `--acl`, since it will query every individual object in the bucket to get the info. This is something that will be improved on v2. Use `--estimate` option for a rough estimate
### TODO:
- [ ] add `--prefix` and `--delimiter` options
- [ ] add warning, `file already exists. overwrite? y/n`
- [ ] add `--continue` | `--append` option to start up where we left off
- [ ] add option to not include header in saved csv file
- [ ] add `--include` | `--exclude` option to only fetch keys that include/exclude this text
- [ ] add `--ext` | `--exclude_ext` to only include/exclude these file extensions
- [ ] integrate gcp if possible