https://github.com/LAION-AI/CLAP
Contrastive Language-Audio Pretraining
https://github.com/LAION-AI/CLAP
Last synced: about 1 year ago
JSON representation
Contrastive Language-Audio Pretraining
- Host: GitHub
- URL: https://github.com/LAION-AI/CLAP
- Owner: LAION-AI
- License: cc0-1.0
- Created: 2022-03-06T20:12:49.000Z (over 4 years ago)
- Default Branch: main
- Last Pushed: 2024-07-09T02:20:16.000Z (about 2 years ago)
- Last Synced: 2024-11-19T11:08:54.594Z (over 1 year ago)
- Language: Python
- Homepage: https://arxiv.org/abs/2211.06687
- Size: 9.13 MB
- Stars: 1,422
- Watchers: 29
- Forks: 137
- Open Issues: 55
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- awesome-python-audio - CLAP (LAION) - Audio Pretraining for zero-shot audio classification (Audio Embeddings & Representations)
README
# CLAP




### This repository provides representations of audios and texts via Contrastive Language-Audio Pretraining (CLAP)
With CLAP, you can extract a latent representation of any given audio and text for your own model, or for different downstream tasks.
All codes are comming officially with the following paper, accepted by IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2023:
- [Large-Scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation](https://arxiv.org/abs/2211.06687)
**New Updates:**
1. We release new CLAP pretrained checkpoints pretrained on music and speech data collecstions from [our dataset collection repo](https://github.com/LAION-AI/audio-dataset).
2. CLAP model is incorporated and supported by [HuggingFace Transformers](https://huggingface.co/docs/transformers/v4.27.2/en/model_doc/clap). Many thanks to [Younes Belkada](https://huggingface.co/ybelkada) and [Arthur Zucker](https://fr.linkedin.com/in/arthur-zucker-8a0445144) for contributing to the HuggingFace support.
## About this project
This project is a project in [LAION](https://laion.ai/) that aims at learning better audio understanding and getting more audio data.
This is an opensource project. We adopt the codebase of [open_clip](https://github.com/mlfoundations/open_clip) for this project.
many thanks to @cfoster0 for allowing us to use his repo name.
## Architecture
Contrastive Language-Audio Pretraining, known as CLAP. Referring to the CLIP (Contrastive Language-Image Pretraining) architecture, the CLAP architecture is as follows.
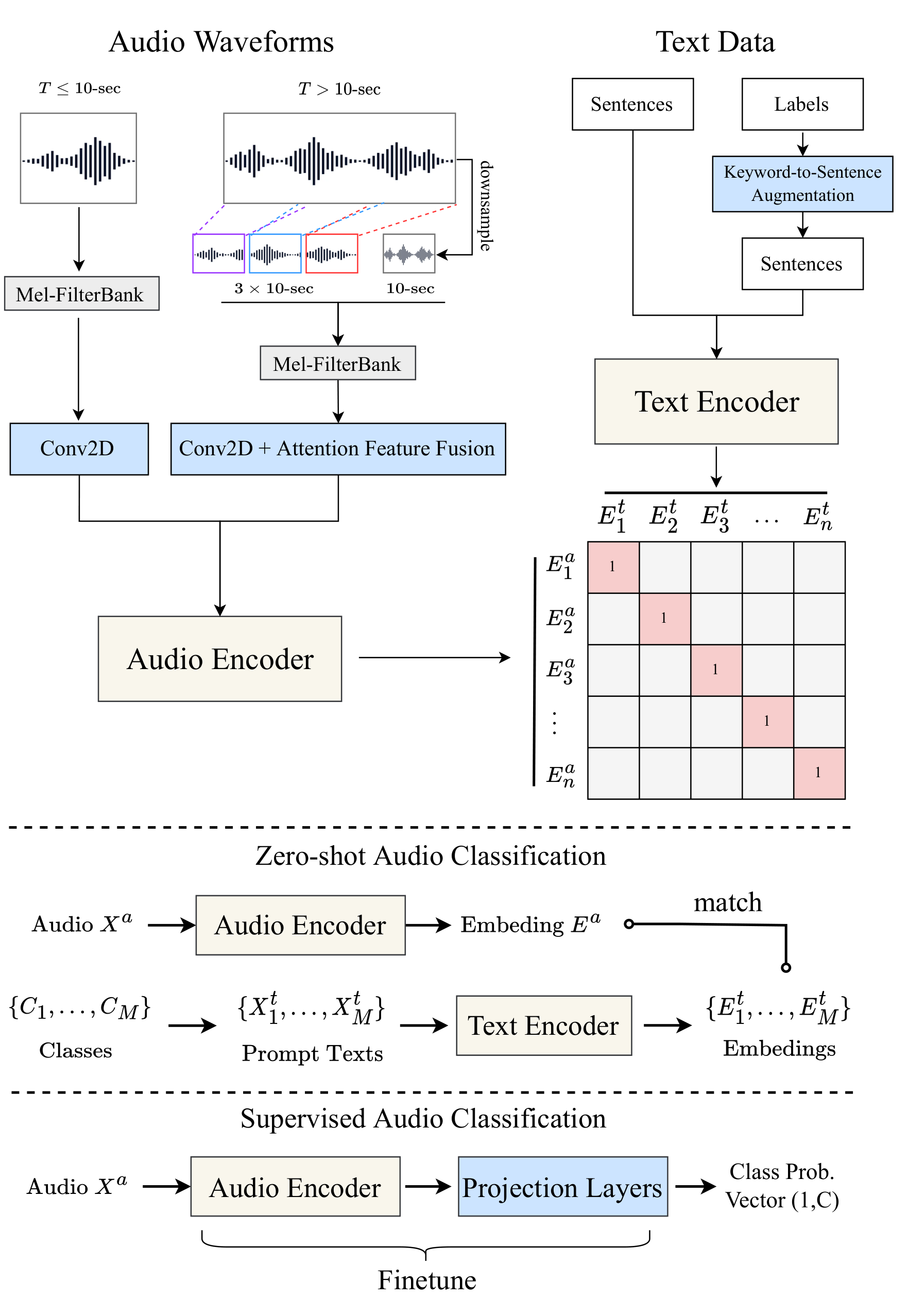
## Quick Start
We provide the PyPI library for our CLAP model:
```bash
pip install laion-clap
```
Then you can follow the below usage or refer to [unit_test.py](https://github.com/LAION-AI/CLAP/blob/laion_clap_pip/src/laion_clap/unit_test.py).
For the documentation of the API, please refer to [hook.py](https://github.com/LAION-AI/CLAP/blob/main/src/laion_clap/hook.py).
```python
import numpy as np
import librosa
import torch
import laion_clap
# quantization
def int16_to_float32(x):
return (x / 32767.0).astype('float32')
def float32_to_int16(x):
x = np.clip(x, a_min=-1., a_max=1.)
return (x * 32767.).astype('int16')
model = laion_clap.CLAP_Module(enable_fusion=False)
model.load_ckpt() # download the default pretrained checkpoint.
# Directly get audio embeddings from audio files
audio_file = [
'/home/data/test_clap_short.wav',
'/home/data/test_clap_long.wav'
]
audio_embed = model.get_audio_embedding_from_filelist(x = audio_file, use_tensor=False)
print(audio_embed[:,-20:])
print(audio_embed.shape)
# Get audio embeddings from audio data
audio_data, _ = librosa.load('/home/data/test_clap_short.wav', sr=48000) # sample rate should be 48000
audio_data = audio_data.reshape(1, -1) # Make it (1,T) or (N,T)
audio_embed = model.get_audio_embedding_from_data(x = audio_data, use_tensor=False)
print(audio_embed[:,-20:])
print(audio_embed.shape)
# Directly get audio embeddings from audio files, but return torch tensor
audio_file = [
'/home/data/test_clap_short.wav',
'/home/data/test_clap_long.wav'
]
audio_embed = model.get_audio_embedding_from_filelist(x = audio_file, use_tensor=True)
print(audio_embed[:,-20:])
print(audio_embed.shape)
# Get audio embeddings from audio data
audio_data, _ = librosa.load('/home/data/test_clap_short.wav', sr=48000) # sample rate should be 48000
audio_data = audio_data.reshape(1, -1) # Make it (1,T) or (N,T)
audio_data = torch.from_numpy(int16_to_float32(float32_to_int16(audio_data))).float() # quantize before send it in to the model
audio_embed = model.get_audio_embedding_from_data(x = audio_data, use_tensor=True)
print(audio_embed[:,-20:])
print(audio_embed.shape)
# Get text embedings from texts:
text_data = ["I love the contrastive learning", "I love the pretrain model"]
text_embed = model.get_text_embedding(text_data)
print(text_embed)
print(text_embed.shape)
# Get text embedings from texts, but return torch tensor:
text_data = ["I love the contrastive learning", "I love the pretrain model"]
text_embed = model.get_text_embedding(text_data, use_tensor=True)
print(text_embed)
print(text_embed.shape)
```
## Pretrained Models
The pretrained checkpoints can be found in [here](https://huggingface.co/lukewys/laion_clap/tree/main).
Please refer to the previous section for how to load and run the checkpoints.
For the PyPI library, [630k-audioset-best.pt](https://huggingface.co/lukewys/laion_clap/blob/main/630k-audioset-best.pt) and [630k-audioset-fusion-best.pt](https://huggingface.co/lukewys/laion_clap/blob/main/630k-audioset-fusion-best.pt) are our default models (non-fusion and fusion)
We further provide below pretrained models according to your usages:
* For general audio less than 10-sec: [630k-audioset-best.pt](https://huggingface.co/lukewys/laion_clap/blob/main/630k-audioset-best.pt) or [630k-best.pt](https://huggingface.co/lukewys/laion_clap/blob/main/630k-best.pt)
* For general audio with variable-length: [630k-audioset-fusion-best.pt](https://huggingface.co/lukewys/laion_clap/blob/main/630k-audioset-fusion-best.pt) or [630k-fusion-best.pt](https://huggingface.co/lukewys/laion_clap/blob/main/630k-fusion-best.pt)
* For music: [music_audioset_epoch_15_esc_90.14.pt](https://huggingface.co/lukewys/laion_clap/blob/main/music_audioset_epoch_15_esc_90.14.pt)
* For music and speech: [music_speech_epoch_15_esc_89.25.pt](https://huggingface.co/lukewys/laion_clap/blob/main/music_speech_epoch_15_esc_89.25.pt)
* For speech, music and general audio: [music_speech_audioset_epoch_15_esc_89.98.pt](https://huggingface.co/lukewys/laion_clap/blob/main/music_speech_audioset_epoch_15_esc_89.98.pt)
The checkpoints list here for each model setting is the one with the highest average mAP score in training.
The average mAP score is calculated by averaging 4 scores: A-->T mAP@10 on AudioCaps, and T-->A mAP@10 on AudioCaps, A-->T mAP@10 on Clotho, and T-->A mAP@10 on Clotho.
To use above pretrained models, you need to load the ckpt by yourself, as:
Update 2023.4.7: we have released 3 larger CLAP models trained on music, speech dataset in addition to LAION-Audio-630k. Here are descriptions of the model and their performance:
- `music_speech_audioset_epoch_15_esc_89.98.pt`: trained on music + speech + Audioset + LAION-Audio-630k. The zeroshot ESC50 performance is 89.98%, the GTZAN performance is 51%.
- `music_audioset_epoch_15_esc_90.14.pt`: trained on music + Audioset + LAION-Audio-630k. The zeroshot ESC50 performance is 90.14%, the GTZAN performance is 71%.
- `music_speech_epoch_15_esc_89.25.pt`: trained on music + speech + LAION-Audio-630k. The zeroshot ESC50 performance is 89.25%, the GTZAN performance is 69%.
The model uses a larger audio encoder. To load the model using the pip API:
```python
import laion_clap
model = laion_clap.CLAP_Module(enable_fusion=False, amodel= 'HTSAT-base')
model.load_ckpt('checkpoint_path/checkpoint_name.pt')
```
Please note that this is a temporary release for people who are working on larger-scale down-stream task.
We will release a more comprehensive version of the model with detailed experiments in the future.
Please take your own risk when using this model.
* All the new checkpoints did not trained with fusion. The training dataset size for `music_speech_audioset_epoch_15_esc_89.98.pt` is around 4M samples. The zeroshot GTZAN score is evaluated using the prompt `This audio is a song.`
## Environment Installation
If you want to check and reuse our model into your project instead of directly using the pip library, you need to install the same environment as we use, please run the following command:
```bash
conda create env -n clap python=3.10
conda activate clap
git clone https://github.com/LAION-AI/CLAP.git
cd CLAP
# you can also install pytorch by following the official instruction (https://pytorch.org/get-started/locally/)
pip install torch==1.11.0+cu113 torchvision==0.12.0+cu113 torchaudio==0.11.0+cu113 -f https://download.pytorch.org/whl/torch_stable.html
pip install -r requirements.txt
```
## Dataset format
We use training data in webdataset format. For details of our dataset please see https://github.com/LAION-AI/audio-dataset.
Due to copyright reasons, we cannot release the dataset we train this model on. However, we released [LAION-audio-630K](https://github.com/LAION-AI/audio-dataset/tree/main/laion-audio-630k), the data source we used to compose the dataset with link to each audio and their caption. Please refer to [LAION-audio-630K](https://github.com/LAION-AI/audio-dataset/tree/main/laion-audio-630k) for more details. You could download the dataset, preprocess it on your own and train it locally. To train on the local dataset, please change the `--remotedata` in training scripts (see [experiment_scripts](./experiment_scripts) folder) with `--datasetpath `.
You can find an example of our dataset format in [here](https://drive.google.com/drive/folders/1scyH43eQAcrBz-5fAw44C6RNBhC3ejvX?usp=sharing).
It contains the full ESC50 dataset, split according to the first 5-fold split.
## Training, Fine-tuning and Evaluation
Please find the script of training, fine-tuning and evaluation (zero-shot and retrieval) in the [experiment_scripts](./experiment_scripts) folder.
The scripts included there are the one we used to train our model on a SLURM cluster.
You need to change the script to fit your own environment.
For example, in a single machine multi-GPU setting, you might want to use `torchrun` instead of `srun` to run the script.
To train on a single GPU machine, use `CUDA_VISIBLE_DEVICES=0 python -m ...` instead of `srun`.
We use [Weights and Biases](https://wandb.ai/site) for experiment logging. You need to configure the weights and biases in your environment.
To train on local dataset, please change the `--remotedata` in training scripts (see [experiment_scripts](./experiment_scripts) folder) with `--datasetpath `.
## Core Code
Please refer to [main.py](https://github.com/LAION-AI/CLAP/blob/laion_clap_pip/src/laion_clap/training/main.py), [train.py](https://github.com/LAION-AI/CLAP/blob/laion_clap_pip/src/laion_clap/training/train.py), [data.py](https://github.com/LAION-AI/CLAP/blob/laion_clap_pip/src/laion_clap/training/data.py),and [model.py](https://github.com/LAION-AI/CLAP/blob/laion_clap_pip/src/laion_clap/clap_module/model.py) to quicly get familiar with our model.
## Reproducibility
An example of the preprocessed Clotho dataset in webdataset format can be download [here](https://drive.google.com/drive/folders/1mU9mBOe11jTFCrQRJQsUa4S-3TlNuYoI?usp=sharing) (by downloading, you will be agreeing the license described in the [Clotho dataset](https://zenodo.org/record/3490684#.Y9ALPeyZP1w)). The audio encoder pretrained with 48kHz AudioSet can be found [here](https://drive.google.com/drive/folders/1SMQyzJvc6DwJNuhQ_WI8tlCFL5HG2vk6?usp=sharing), where `HTSAT-fullset-imagenet-map=0.467.ckpt` is the checkpoint used to initalize our HTSAT audio encoder. You should get similar result by loading from the audio encoder checkpoint and training on same dataset.
The script to train the model on Clotho dataset is included [here](experiment_scripts/train-only-clotho.sh). You need to replace the `datasetpath` and `pretrained-audio` to pointing to your own directory. You could check the [report](https://stability.wandb.io/clap/clap/reports/CLAP-trained-on-Clotho-dataset--VmlldzoyNzY?accessToken=c0erq9hhp7h880jclihd9j9if679s6bylwto33vo14yo5jg40ppe38qeoafoonpz) of the training script on a single A100 GPU for reference.
Because most of the dataset has copyright restriction, unfortunatly we cannot directly share other preprocessed datasets. The caption generated by keyword-to-caption model for Audioset can be found [here](https://github.com/LAION-AI/audio-dataset/tree/main/laion-audio-630k#keyword-to-caption-augmentation)
## Zeroshot Classification with ESC50 official split
Here is an example code to run the zeroshot classification on **first** ESC50 official split with the pip API:
```python
import laion_clap
import glob
import json
import torch
import numpy as np
device = torch.device('cuda:0')
# download https://drive.google.com/drive/folders/1scyH43eQAcrBz-5fAw44C6RNBhC3ejvX?usp=sharing and extract ./ESC50_1/test/0.tar to ./ESC50_1/test/
esc50_test_dir = './ESC50_1/test/*/'
class_index_dict_path = './class_labels/ESC50_class_labels_indices_space.json'
# Load the model
model = laion_clap.CLAP_Module(enable_fusion=False, device=device)
model.load_ckpt()
# Get the class index dict
class_index_dict = {v: k for v, k in json.load(open(class_index_dict_path)).items()}
# Get all the data
audio_files = sorted(glob.glob(esc50_test_dir + '**/*.flac', recursive=True))
json_files = sorted(glob.glob(esc50_test_dir + '**/*.json', recursive=True))
ground_truth_idx = [class_index_dict[json.load(open(jf))['tag'][0]] for jf in json_files]
with torch.no_grad():
ground_truth = torch.tensor(ground_truth_idx).view(-1, 1)
# Get text features
all_texts = ["This is a sound of " + t for t in class_index_dict.keys()]
text_embed = model.get_text_embedding(all_texts)
audio_embed = model.get_audio_embedding_from_filelist(x=audio_files)
ranking = torch.argsort(torch.tensor(audio_embed) @ torch.tensor(text_embed).t(), descending=True)
preds = torch.where(ranking == ground_truth)[1]
preds = preds.cpu().numpy()
metrics = {}
metrics[f"mean_rank"] = preds.mean() + 1
metrics[f"median_rank"] = np.floor(np.median(preds)) + 1
for k in [1, 5, 10]:
metrics[f"R@{k}"] = np.mean(preds < k)
# map@10
metrics[f"mAP@10"] = np.mean(np.where(preds < 10, 1 / (preds + 1), 0.0))
print(
f"Zeroshot Classification Results: "
+ "\t".join([f"{k}: {round(v, 4):.4f}" for k, v in metrics.items()])
)
```
For ESC50 dataset, you could either download our processed ESC50 in webdataset format
from [here](https://drive.google.com/drive/folders/1scyH43eQAcrBz-5fAw44C6RNBhC3ejvX?usp=sharing), and extract the
`./test/0.tar` to `./test/`. Or you could download the original ESC50 dataset and
preprocess the label to the format of `class_labels/ESC50_class_labels_indices_space.json` by yourself (replace `_` with space).
The result should be the same as the following:
For `model = laion_clap.CLAP_Module(enable_fusion=True, device=device)`: `mean_rank: 1.2425 median_rank: 1.0000 R@1: 0.9050 R@5: 0.9900 R@10: 0.9925 mAP@10: 0.9407`
For `model = laion_clap.CLAP_Module(enable_fusion=False, device=device)`: `mean_rank: 1.1450 median_rank: 1.0000 R@1: 0.9275 R@5: 0.9975 R@10: 1.0000 mAP@10: 0.9556`
Note that the results is slightly higher than the reported results in the paper, because we use the train + test data of ESC50 and removing the data overlap in other training datasets (mainly freesound).
## Citation
If you find this project and the LAION-Audio-630K dataset useful, please cite our paper:
```
@inproceedings{laionclap2023,
title = {Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation},
author = {Wu*, Yusong and Chen*, Ke and Zhang*, Tianyu and Hui*, Yuchen and Berg-Kirkpatrick, Taylor and Dubnov, Shlomo},
booktitle={IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP},
year = {2023}
}
@inproceedings{htsatke2022,
author = {Ke Chen and Xingjian Du and Bilei Zhu and Zejun Ma and Taylor Berg-Kirkpatrick and Shlomo Dubnov},
title = {HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound Classification and Detection},
booktitle={IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP},
year = {2022}
}
```
## Acknowledgements
This project is working in progress, thus the codebase and model might not be perfect or bug-free.
We will very much appreciate any kind of contribution or and issue raised.
If you find a bug or have any suggestion, please feel free to open an issue or contact us.
If you would actively contribute to this project, please join the discord of LAION.