https://github.com/LanguageMachines/PICCL
A set of workflows for corpus building through OCR, post-correction and normalisation
https://github.com/LanguageMachines/PICCL
computational-linguistics corpus-linguistics corpus-tools folia nlp ocr workflow
Last synced: over 1 year ago
JSON representation
A set of workflows for corpus building through OCR, post-correction and normalisation
- Host: GitHub
- URL: https://github.com/LanguageMachines/PICCL
- Owner: LanguageMachines
- License: other
- Created: 2017-03-25T12:01:28.000Z (over 9 years ago)
- Default Branch: master
- Last Pushed: 2022-09-07T12:28:13.000Z (almost 4 years ago)
- Last Synced: 2025-03-20T09:06:34.320Z (over 1 year ago)
- Topics: computational-linguistics, corpus-linguistics, corpus-tools, folia, nlp, ocr, workflow
- Language: Python
- Homepage:
- Size: 4.26 MB
- Stars: 48
- Watchers: 7
- Forks: 7
- Open Issues: 3
-
Metadata Files:
- Readme: README.md
- License: LICENSE.md
Awesome Lists containing this project
README
[](http://applejack.science.ru.nl/languagemachines/)
[](https://travis-ci.org/LanguageMachines/PICCL)
[](https://GitHub.com/LanguageMachines/PICCL/releases/)
[](https://www.repostatus.org/#unsupported)
# PICCL: Philosophical Integrator of Computational and Corpus Libraries
PICCL offers a workflow for corpus building and builds on a variety of tools.
The primary component of PICCL is TICCL; a Text-induced Corpus Clean-up system, which
performs spelling correction and OCR post-correction (normalisation of spelling
variants etc).
PICCL and TICCL constitute original research by Martin Reynaert (Tilburg University & Radboud University Nijmegen), and
is currently developed in the scope of the [CLARIAH](https://www.clariah.nl) project.
This repository hosts the relevant workflows that constitute PICCL, powered by
[Nextflow](https://www.nextflow.io). These will be shipped as part of our
[LaMachine](https://proycon.github.io/LaMachine) software distribution. The
combination of these enable the PICCL workflow to be portable and scalable; it
can be executed accross multiple computing nodes on a high performance cluster
such as SGE, LSF, SLURM, PBS, HTCondor, Kubernetes and Amazon AWS.
Parallellisation is handled automatically. Consult the [Nextflow
documentation](https://www.nextflow.io/docs/latest/index.html) for details
regarding this.
All the modules that make up TICCL are part of the [TicclTools](https://github.com/LanguageMachines/ticcltools)
collection, and are not part of the current repository. Certain other required components are in the
[FoLiA-Utils](https://github.com/LanguageMachines/foliautils) collection. There is no need to install either of these or
other dependencies manually.
PICCL makes extensive use of the [FoLiA](https://proycon.github.io/folia) format, a rich XML-based format for linguistic
annotation.
**Important Note**: This is beta software still in development; for the old and deprecated version consult [this repository](https://github.com/martinreynaert/TICCL).
## Installation
PICCL is shipped as a part of [LaMachine](https://proycon.github.io/LaMachine), although you need to explicitly select it for installation using ``lamachine-add piccl && lamachine-update`` (from inside a LaMachine installation). Once inside LaMachine, the command line interface can be invoked by directly specifying one of the workflows:
$ ocr.nf
Or
$ ticcl.nf
If you using a LaMachine installation, you can skip the rest of this section. If not, you can install [Nextflow](https://www.nextflow.io) and [Docker](https://docker.io) manually and then run the
following to obtain the latest development release of PICCL:
$ nextflow pull LanguageMachines/PICCL
In this case you need to ensure to always run it with the ``-with-docker proycon/lamachine:piccl`` parameter, this lets
nextflow manage your LaMachine docker container (this is not tested as much as running from inside the container
directly):
$ nextflow run LanguageMachines/PICCL -with-docker proycon/lamachine:piccl
We have prepared PICCL for work in many languages, mainly on the basis of available open source lexicons due to [Aspell](http://aspell.net), these data files serve as the input for TICCL and have to be downloaded once as follows;
$ nextflow run LanguageMachines/PICCL/download-data.nf -with-docker proycon/lamachine:piccl
This will generate a ``data/`` directory in your current directory, and will be referenced in the usage examples in the
next section. In a LaMachine environment, this directory is already available in ``$LM_PREFIX/opt/PICCL/data``.
In addition, you can also download example corpora (>300MB), which will be placed in a ``corpora/`` directory:
$ nextflow run LanguageMachines/PICCL/download-examples.nf -with-docker proycon/lamachine:piccl
## Architecture
PICCL consists of two workflows, one for optical character recognition using [tesseract](https://github.com/tesseract-ocr/tesseract), and a TICCL workflow for
OCR-post-correction and normalisation. Third, PICCL provides a webservice that ties together both these workflows and
also integrates two other workflows from [aNtiLoPe](https://github.com/proycon/antilope): a workflow for tokenisation (using [ucto](https://languagemachines.github.io/ucto)) and Dutch Linguistic Enrichment (using [frog](https://languagemachines.github.io/frog)).
The architecture of the PICCL webservice, and its two integral workflows, is visualised schematically as follows:
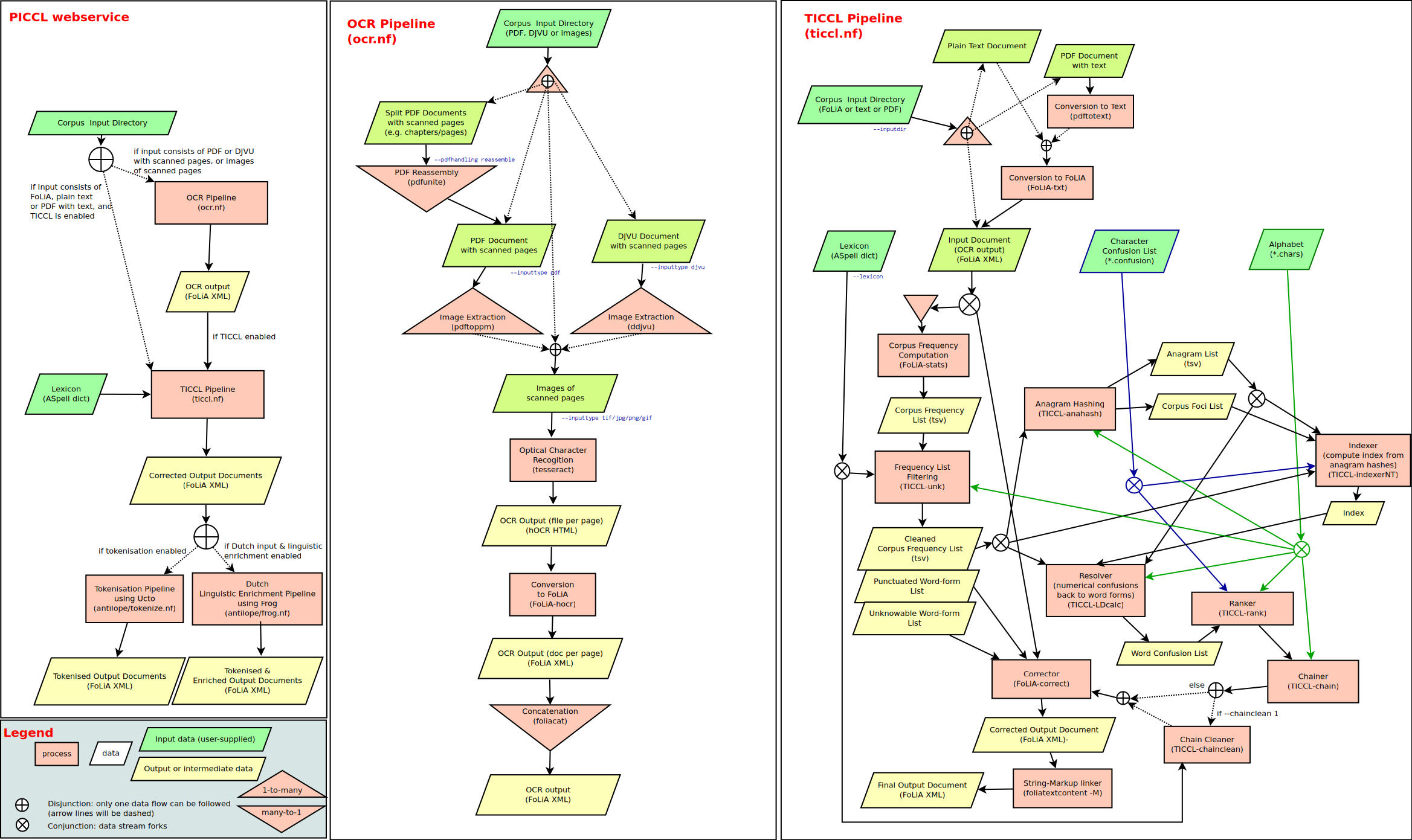
## Usage
### Command line interface
PICCL encompasses two workflows (and in webservice form it also integrates two more from
[aNtiLoPe](https://github.com/proycon/antilope))
* ``ocr.nf`` - A pipeline for Optical Character Recognition using [Tesseract](https://github.com/tesseract-ocr/tesseract); takes PDF documents or images of scanned pages and produces [FoLiA](https://proycon.github.io/folia) documents.
* ``ticcl.nf`` - The Text-induced Corpus Clean-up system: performs OCR-postcorrection, takes as input the result from
``ocr.nf``, or standalone text or PDF (text; no OCR), and produces further enriched [FoLiA](https://proycon.github.io/folia) documents.
If you are inside LaMachine, you can invoke these directly. If you let Nextflow manage LaMachine through docker, then
you have to invoke them like ``nextflow run LanguageMachines/PICCL/ocr.nf -with-docker proycon/lamachine:piccl``. This applies to all examples in this section.
Running with the ``--help`` parameter or absence of any parameters will output usage
information.
$ ocr.nf --help
--------------------------
OCR Pipeline
--------------------------
Usage:
ocr.nf [PARAMETERS]
Mandatory parameters:
--inputdir DIRECTORY Input directory
--language LANGUAGE Language (iso-639-3)
Optional parameters:
--inputtype STR Specify input type, the following are supported:
pdf (extension *.pdf) - Scanned PDF documents (image content) [default]
tif ($document-$sequencenumber.tif) - Images per page (adhere to the naming convention!)
jpg ($document-$sequencenumber.jpg) - Images per page
png ($document-$sequencenumber.png) - Images per page
gif ($document-$sequencenumber.gif) - Images per page
djvu (extension *.djvu)"
(The hyphen delimiter may optionally be changed using --seqdelimiter)
--outputdir DIRECTORY Output directory (FoLiA documents)
--virtualenv PATH Path to Python Virtual Environment to load (usually path to LaMachine)
--pdfhandling reassemble Reassemble/merge all PDFs with the same base name and a number suffix; this can
for instance reassemble a book that has its chapters in different PDFs.
Input PDFs must adhere to a \$document-\$sequencenumber.pdf convention.
(The hyphen delimiter may optionally be changed using --seqdelimiter)
--seqdelimiter Sequence delimiter in input files (defaults to: _)
--seqstart What input field is the sequence number (may be a negative number to count from the end), default: -2
$ ticcl.nf --help
--------------------------
TICCL Pipeline
--------------------------
Usage:
ticcl.nf [OPTIONS]
Mandatory parameters:
--inputdir DIRECTORY Input directory (FoLiA documents with an OCR text layer)
--lexicon FILE Path to lexicon file (*.dict)
--alphabet FILE Path to alphabet file (*.chars)
--charconfus FILE Path to character confusion list (*.confusion)
Optional parameters:
--outputdir DIRECTORY Output directory (FoLiA documents)
--language LANGUAGE Language
--extension STR Extension of FoLiA documents in input directory (default: folia.xml)
--inputclass CLASS FoLiA text class to use for input, defaults to 'current' for FoLiA input; must be set to 'OCR' for FoLiA documents produced by ocr.nf
--inputtype STR Input type can be either 'folia' (default), 'text', or 'pdf' (i.e. pdf with text; no OCR)
--virtualenv PATH Path to Virtual Environment to load (usually path to LaMachine)
--artifrq INT Default value for missing frequencies in the validated lexicon (default: 10000000)
--distance INT Levenshtein/edit distance (default: 2)
--clip INT Limit the number of variants per word (default: 10)
--corpusfreqlist FILE Corpus frequency list (skips the first step that would compute one for you)
--low INT skip entries from the anagram file shorter than 'low' characters. (default=5)
--high INT skip entries from the anagram file longer than 'high' characters. (default=35)
--chainclean BOOLINT enable chain clean or not (1 = on, 0 = off, default)
An example of invoking an OCR workflow for English is provided below, it assumes the sample data are installed in the ``corpora/``
directory. It OCRs the ``OllevierGeets.pdf`` file, which contains scanned image data, therefore we choose the
``pdfimages`` input type.
$ ocr.nf --inputdir corpora/PDF/ENG/ --inputtype pdfimages --language eng
Alternative input types are images per page, in which case ``inputtype`` is set to either ``tif``, ``jpg``, ``gif`` or ``png``. These input files should be placed in the designated input directory and follow the naming convention
``$documentname-$sequencenumber.$extension``, for example ``harrypotter-032.png``. An example invocation on dutch
scanned pages in the example collection would be:
$ ocr.nf --inputdir corpora/TIFF/NLD/ --inputtype tif --language nld
In case of the first example the result will be a file ``OllevierGeets.folia.xml`` in the ``ocr_output/`` directory. This in turn can serve as
input for the TICCL workflow, which will attempt to correct OCR errors. Take care that that the ``--inputclass OCR``
parameter is mandatory if you want to use the FoLiA output of ``ocr.nf`` as input for TICCL:
$ ticcl.nf --inputdir ocr_output/ --inputclass OCR --lexicon $LM_PREFIX/opt/PICCL/data/int/eng/eng.aspell.dict --alphabet $LM_PREFIX/opt/PICCL/data/int/eng/eng.aspell.dict.lc.chars --charconfus $LM_PREFIX/opt/PICCL/data/int/eng/eng.aspell.dict.c0.d2.confusion
Note that here we pass a language-specific lexicon file, alphabet file, and character confusion file from the data files obtained by
``download-data.nf``. Result will be a file ``OllevierGeets.folia.ticcl.xml`` in the ``ticcl_output/`` directory,
containing enriched corrections. The second example, on the dutch corpus data, can be run as follows:
$ ticcl.nf --inputdir ocr_output/ --inputclass OCR --lexicon $LM_PREFIX/opt/PICCL/data/int/nld/nld.aspell.dict --alphabet $LM_PREFIX/opt/PICCL/data/int/nld/nld.aspell.dict.lc.chars --charconfus $LM_PREFIX/opt/PICCL/data/int/nld/nld.aspell.dict.c20.d2.confusion
## Webapplication / RESTful webservice
### Installation
PICCL is also available as a webapplication and RESTful webservice, powered by [CLAM](https://proycon.github.io/clam).
If you are in LaMachine with PICCL, the webservice is already installed, but you may need to run
``lamachine-start-webserver`` if it is not already running.
For production environments, you will want to adapt the CLAM configuration. To this end,
copy ``$LM_PREFIX/etc/piccl.config.yml`` to ``$LM_PREFIX/etc/piccl.$HOST.yml``, where ``$HOST`` corresponds with your
hostname and edit the file with your host specific settings. Always enable authentication if your server is world-accessible (consult the CLAM
documentation to read how).
## Technical Details & Contributing
Please see CONTRIBUTE.md for technical details and information on how to contribute.