https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow
Simple Reinforcement learning tutorials, 莫烦Python 中文AI教学
https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow
a3c actor-critic asynchronous-advantage-actor-critic ddpg deep-deterministic-policy-gradient deep-q-network double-dqn dqn dueling-dqn machine-learning policy-gradient ppo prioritized-replay proximal-policy-optimization q-learning reinforcement-learning sarsa sarsa-lambda tensorflow-tutorials tutorial
Last synced: over 1 year ago
JSON representation
Simple Reinforcement learning tutorials, 莫烦Python 中文AI教学
- Host: GitHub
- URL: https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow
- Owner: MorvanZhou
- License: mit
- Created: 2017-05-06T03:01:31.000Z (about 9 years ago)
- Default Branch: master
- Last Pushed: 2024-03-31T05:40:51.000Z (over 2 years ago)
- Last Synced: 2025-03-26T01:07:02.545Z (over 1 year ago)
- Topics: a3c, actor-critic, asynchronous-advantage-actor-critic, ddpg, deep-deterministic-policy-gradient, deep-q-network, double-dqn, dqn, dueling-dqn, machine-learning, policy-gradient, ppo, prioritized-replay, proximal-policy-optimization, q-learning, reinforcement-learning, sarsa, sarsa-lambda, tensorflow-tutorials, tutorial
- Language: Python
- Homepage: https://mofanpy.com/tutorials/machine-learning/reinforcement-learning/
- Size: 428 KB
- Stars: 9,125
- Watchers: 290
- Forks: 5,036
- Open Issues: 69
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
- awesome-deep-rl - MorvanZhou/Reinforcement Learning Methods and Tutorials
- awesome-machine-learning-resources - **[Tutorial - learning-with-tensorflow?style=social) (Table of Contents)
- awesome-list - Reinforcement-learning-with-tensorflow - Simple Reinforcement learning tutorials. (Machine Learning Tutorials / Data Management)
README

# Reinforcement Learning Methods and Tutorials
In these tutorials for reinforcement learning, it covers from the basic RL algorithms to advanced algorithms developed recent years.
**If you speak Chinese, visit [莫烦 Python](https://mofanpy.com) or my [Youtube channel](https://www.youtube.com/channel/UCdyjiB5H8Pu7aDTNVXTTpcg) for more.**
**As many requests about making these tutorials available in English, please find them in this playlist:** ([https://www.youtube.com/playlist?list=PLXO45tsB95cIplu-fLMpUEEZTwrDNh6Ba](https://www.youtube.com/playlist?list=PLXO45tsB95cIplu-fLMpUEEZTwrDNh6Ba))
# Table of Contents
* Tutorials
* [Simple entry example](contents/1_command_line_reinforcement_learning)
* [Q-learning](contents/2_Q_Learning_maze)
* [Sarsa](contents/3_Sarsa_maze)
* [Sarsa(lambda)](contents/4_Sarsa_lambda_maze)
* [Deep Q Network (DQN)](contents/5_Deep_Q_Network)
* [Using OpenAI Gym](contents/6_OpenAI_gym)
* [Double DQN](contents/5.1_Double_DQN)
* [DQN with Prioitized Experience Replay](contents/5.2_Prioritized_Replay_DQN)
* [Dueling DQN](contents/5.3_Dueling_DQN)
* [Policy Gradients](contents/7_Policy_gradient_softmax)
* [Actor-Critic](contents/8_Actor_Critic_Advantage)
* [Deep Deterministic Policy Gradient (DDPG)](contents/9_Deep_Deterministic_Policy_Gradient_DDPG)
* [A3C](contents/10_A3C)
* [Dyna-Q](contents/11_Dyna_Q)
* [Proximal Policy Optimization (PPO)](contents/12_Proximal_Policy_Optimization)
* [Curiosity Model](/contents/Curiosity_Model), [Random Network Distillation (RND)](/contents/Curiosity_Model/Random_Network_Distillation.py)
* [Some of my experiments](experiments)
* [2D Car](experiments/2D_car)
* [Robot arm](experiments/Robot_arm)
* [BipedalWalker](experiments/Solve_BipedalWalker)
* [LunarLander](experiments/Solve_LunarLander)
# Some RL Networks
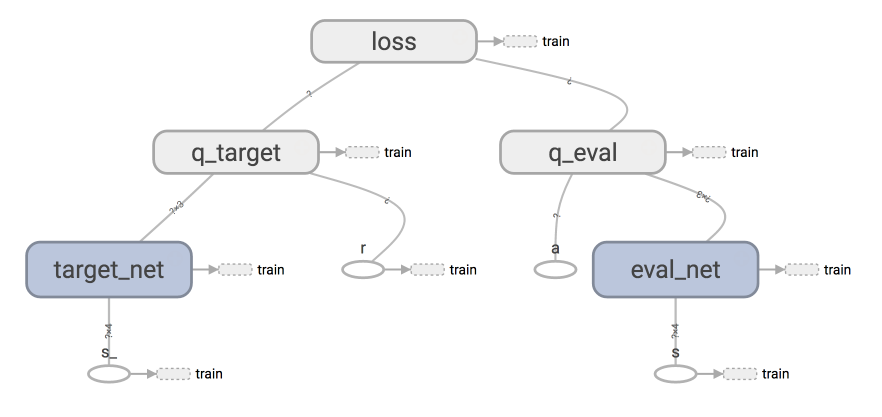
### [Deep Q Network](contents/5_Deep_Q_Network)
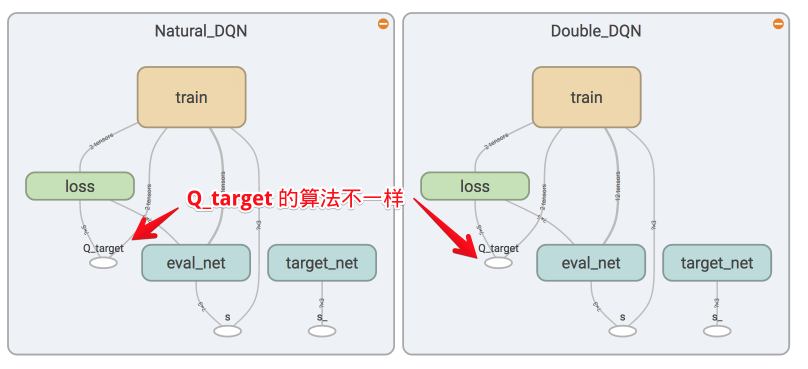
### [Double DQN](contents/5.1_Double_DQN)
### [Dueling DQN](contents/5.3_Dueling_DQN)

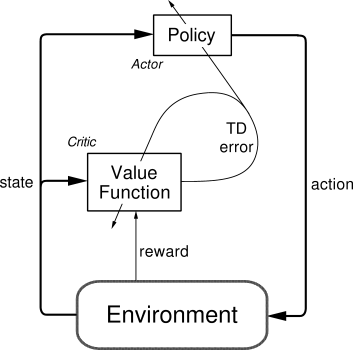
### [Actor Critic](contents/8_Actor_Critic_Advantage)
### [Deep Deterministic Policy Gradient](contents/9_Deep_Deterministic_Policy_Gradient_DDPG)

### [A3C](contents/10_A3C)

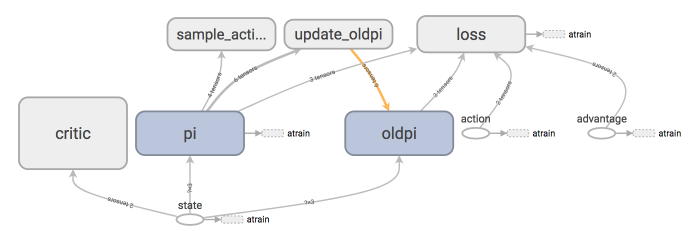
### [Proximal Policy Optimization (PPO)](contents/12_Proximal_Policy_Optimization)
### [Curiosity Model](/contents/Curiosity_Model)

# Donation
*If this does help you, please consider donating to support me for better tutorials. Any contribution is greatly appreciated!*

