https://github.com/NVlabs/FasterViT
[ICLR 2024] Official PyTorch implementation of FasterViT: Fast Vision Transformers with Hierarchical Attention
https://github.com/NVlabs/FasterViT
ade20k backbone coco deep-learning foundation-models image-classification image-net object-detection pre-trained-model self-attention semantic-segmentation vision-transformer visual-recognition
Last synced: over 1 year ago
JSON representation
[ICLR 2024] Official PyTorch implementation of FasterViT: Fast Vision Transformers with Hierarchical Attention
- Host: GitHub
- URL: https://github.com/NVlabs/FasterViT
- Owner: NVlabs
- License: other
- Created: 2023-05-19T22:19:34.000Z (about 3 years ago)
- Default Branch: main
- Last Pushed: 2024-06-02T19:30:17.000Z (about 2 years ago)
- Last Synced: 2024-09-16T14:19:17.416Z (almost 2 years ago)
- Topics: ade20k, backbone, coco, deep-learning, foundation-models, image-classification, image-net, object-detection, pre-trained-model, self-attention, semantic-segmentation, vision-transformer, visual-recognition
- Language: Python
- Homepage: https://arxiv.org/abs/2306.06189
- Size: 1.28 MB
- Stars: 763
- Watchers: 18
- Forks: 62
- Open Issues: 4
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# FasterViT: Fast Vision Transformers with Hierarchical Attention
Official PyTorch implementation of [**FasterViT: Fast Vision Transformers with Hierarchical Attention**](https://arxiv.org/abs/2306.06189).
[](https://github.com/NVlabs/FasterViT/stargazers)
[Ali Hatamizadeh](https://research.nvidia.com/person/ali-hatamizadeh),
[Greg Heinrich](https://developer.nvidia.com/blog/author/gheinrich/),
[Hongxu (Danny) Yin](https://hongxu-yin.github.io/),
[Andrew Tao](https://developer.nvidia.com/blog/author/atao/),
[Jose M. Alvarez](https://alvarezlopezjosem.github.io/),
[Jan Kautz](https://jankautz.com/),
[Pavlo Molchanov](https://www.pmolchanov.com/).
For business inquiries, please visit our website and submit the form: [NVIDIA Research Licensing](https://www.nvidia.com/en-us/research/inquiries/)
---
FasterViT achieves a new SOTA Pareto-front in
terms of Top-1 accuracy and throughput without extra training data !
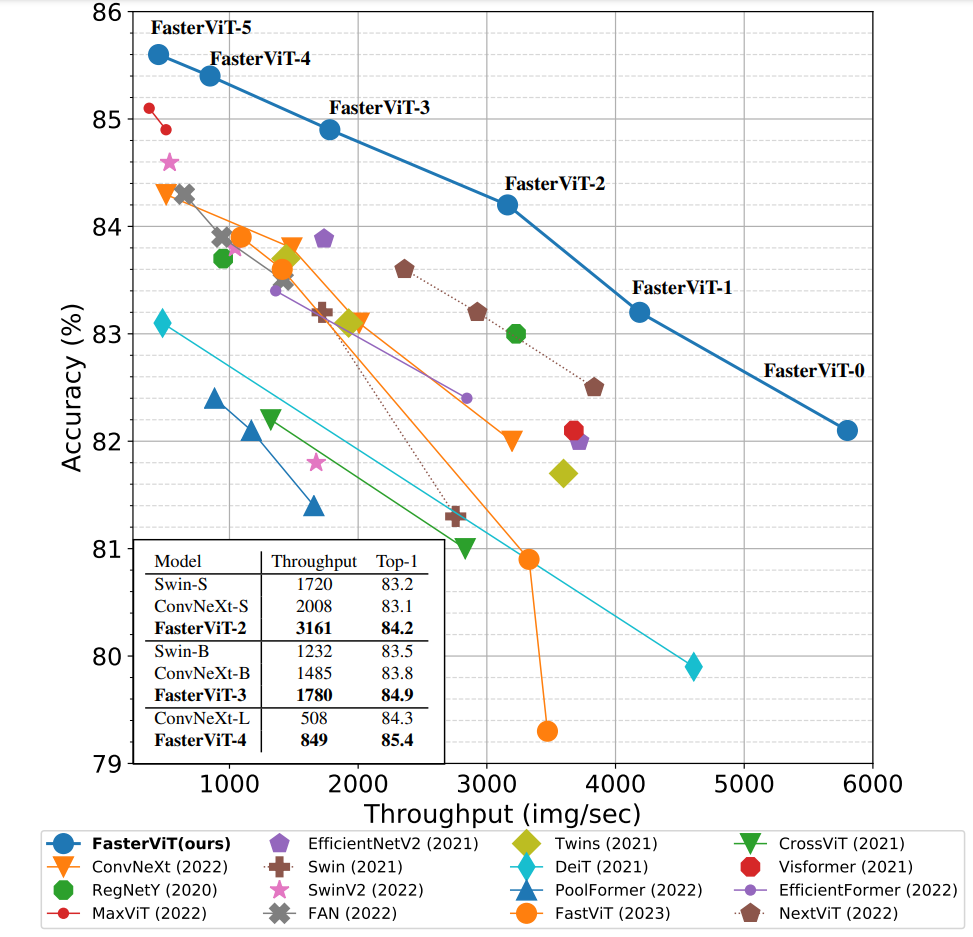
We introduce a new self-attention mechanism, denoted as Hierarchical
Attention (HAT), that captures both short and long-range information by learning
cross-window carrier tokens.

Note: Please use the [**latest NVIDIA TensorRT release**](https://docs.nvidia.com/deeplearning/tensorrt/container-release-notes/index.html) to enjoy the benefits of optimized FasterViT ops.
## 💥 News 💥
- **[04.02.2024]** 🔥 Updated [manuscript](https://arxiv.org/abs/2306.06189) now available on arXiv !
- **[01.24.2024]** 🔥🔥🔥 **Object Tracking with MOTRv2 + FasterViT** is now open-sourced ([link](./downstream/object_tracking/motrv2/README.md)) !
- **[01.17.2024]** 🔥🔥🔥 FasterViT paper has been accepted to [ICLR 2024](https://openreview.net/group?id=ICLR.cc/2024/Conference#tab-your-consoles) !
- **[10.14.2023]** 🔥🔥 We have added the FasterViT [object detection repository](./downstream/object_detection/dino/README.md) with [DINO](https://arxiv.org/abs/2203.03605) !
- **[08.24.2023]** 🔥 FasterViT Keras models with pre-trained weights published in [keras_cv_attention_models](https://github.com/leondgarse/keras_cv_attention_models/tree/main/keras_cv_attention_models/fastervit) !
- **[08.20.2023]** 🔥🔥 We have added ImageNet-21K SOTA pre-trained models for various resolutions !
- **[07.20.2023]** We have created official NVIDIA FasterViT [HuggingFace](https://huggingface.co/nvidia/FasterViT) page.
- **[07.06.2023]** FasterViT checkpoints are now also accecible in HuggingFace!
- **[07.04.2023]** ImageNet pretrained FasterViT models can now be imported with **1 line of code**. Please install the latest FasterViT pip package to use this functionality (also supports Any-resolution FasterViT models).
- **[06.30.2023]** We have further improved the [TensorRT](https://developer.nvidia.com/tensorrt-getting-started) throughput of FasterViT models by 10-15% on average across different models. Please use the [**latest NVIDIA TensorRT release**](https://docs.nvidia.com/deeplearning/tensorrt/container-release-notes/index.html) to use these throughput performance gains.
- **[06.29.2023]** Any-resolution FasterViT model can now be intitialized from pre-trained ImageNet resolution (224 x 244) models.
- **[06.18.2023]** We have released the FasterViT [pip package](https://pypi.org/project/fastervit/) !
- **[06.17.2023]** [Any-resolution FasterViT](./fastervit/models/faster_vit_any_res.py) model is now available ! the model can be used for variety of applications such as detection and segmentation or high-resolution fine-tuning with arbitrary input image resolutions.
- **[06.09.2023]** 🔥🔥 We have released source code and ImageNet-1K FasterViT-models !
## Quick Start
### Object Detection
Please see FasterViT [object detection repository](./object_detection/README.md) with [DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection](https://arxiv.org/abs/2203.03605) for more details.
### Classification
We can import pre-trained FasterViT models with **1 line of code**. Firstly, FasterViT can be simply installed:
```bash
pip install fastervit
```
Note: Please upgrate the package to ```fastervit>=0.9.8``` if you have already installed the package to use the pretrained weights.
A pretrained FasterViT model with default hyper-parameters can be created as in:
```python
>>> from fastervit import create_model
# Define fastervit-0 model with 224 x 224 resolution
>>> model = create_model('faster_vit_0_224',
pretrained=True,
model_path="/tmp/faster_vit_0.pth.tar")
```
`model_path` is used to set the directory to download the model.
We can also simply test the model by passing a dummy input image. The output is the logits:
```python
>>> import torch
>>> image = torch.rand(1, 3, 224, 224)
>>> output = model(image) # torch.Size([1, 1000])
```
We can also use the any-resolution FasterViT model to accommodate arbitrary image resolutions. In the following, we define an any-resolution FasterViT-0
model with input resolution of 576 x 960, window sizes of 12 and 6 in 3rd and 4th stages, carrier token size of 2 and embedding dimension of
64:
```python
>>> from fastervit import create_model
# Define any-resolution FasterViT-0 model with 576 x 960 resolution
>>> model = create_model('faster_vit_0_any_res',
resolution=[576, 960],
window_size=[7, 7, 12, 6],
ct_size=2,
dim=64,
pretrained=True)
```
Note that the above model is intiliazed from the original ImageNet pre-trained FasterViT with original resolution of 224 x 224. As a result, missing keys and mis-matches could be expected since we are addign new layers (e.g. addition of new carrier tokens, etc.)
We can test the model by passing a dummy input image. The output is the logits:
```python
>>> import torch
>>> image = torch.rand(1, 3, 576, 960)
>>> output = model(image) # torch.Size([1, 1000])
```
## Catalog
- [x] ImageNet-1K training code
- [x] ImageNet-1K pre-trained models
- [x] Any-resolution FasterViT
- [x] FasterViT pip-package release
- [x] Add capablity to initialize any-resolution FasterViT from ImageNet-pretrained weights.
- [x] ImageNet-21K pre-trained models
- [x] Detection code + models
---
## Results + Pretrained Models
### ImageNet-1K
**FasterViT ImageNet-1K Pretrained Models**
Name
Acc@1(%)
Acc@5(%)
Throughput(Img/Sec)
Resolution
#Params(M)
FLOPs(G)
Download
FasterViT-0
82.1
95.9
5802
224x224
31.4
3.3
model
FasterViT-1
83.2
96.5
4188
224x224
53.4
5.3
model
FasterViT-2
84.2
96.8
3161
224x224
75.9
8.7
model
FasterViT-3
84.9
97.2
1780
224x224
159.5
18.2
model
FasterViT-4
85.4
97.3
849
224x224
424.6
36.6
model
FasterViT-5
85.6
97.4
449
224x224
975.5
113.0
model
FasterViT-6
85.8
97.4
352
224x224
1360.0
142.0
model
### ImageNet-21K
**FasterViT ImageNet-21K Pretrained Models (ImageNet-1K Fine-tuned)**
Name
Acc@1(%)
Acc@5(%)
Resolution
#Params(M)
FLOPs(G)
Download
FasterViT-4-21K-224
86.6
97.8
224x224
271.9
40.8
model
FasterViT-4-21K-384
87.6
98.3
384x384
271.9
120.1
model
FasterViT-4-21K-512
87.8
98.4
512x512
271.9
213.5
model
FasterViT-4-21K-768
87.9
98.5
768x768
271.9
480.4
model
Raw pre-trained ImageNet-21K model weights for FasterViT-4 is also available for download in this [link](https://drive.google.com/file/d/1T3jDrzlTmTcZVS1Dh01Fl3J2LXZHWKdL/view?usp=sharing).
### Robustness (ImageNet-A - ImageNet-R - ImageNet-V2)
All models use `crop_pct=0.875`. Results are obtained by running inference on ImageNet-1K pretrained models without finetuning.
Name
A-Acc@1(%)
A-Acc@5(%)
R-Acc@1(%)
R-Acc@5(%)
V2-Acc@1(%)
V2-Acc@5(%)
FasterViT-0
23.9
57.6
45.9
60.4
70.9
90.0
FasterViT-1
31.2
63.3
47.5
61.9
72.6
91.0
FasterViT-2
38.2
68.9
49.6
63.4
73.7
91.6
FasterViT-3
44.2
73.0
51.9
65.6
75.0
92.2
FasterViT-4
49.0
75.4
56.0
69.6
75.7
92.7
FasterViT-5
52.7
77.6
56.9
70.0
76.0
93.0
FasterViT-6
53.7
78.4
57.1
70.1
76.1
93.0
A, R and V2 denote ImageNet-A, ImageNet-R and ImageNet-V2 respectively.
## Installation
We provide a [docker file](./Dockerfile). In addition, assuming that a recent [PyTorch](https://pytorch.org/get-started/locally/) package is installed, the dependencies can be installed by running:
```bash
pip install -r requirements.txt
```
## Training
Please see [TRAINING.md](TRAINING.md) for detailed training instructions of all models.
## Evaluation
The FasterViT models can be evaluated on ImageNet-1K validation set using the following:
```
python validate.py \
--model
--checkpoint
--data_dir
--batch-size