https://github.com/NVlabs/GCVit
[ICML 2023] Official PyTorch implementation of Global Context Vision Transformers
https://github.com/NVlabs/GCVit
ade20k backbone coco deep-learning imagenet imagenet-classification object-detection pre-train pre-trained-model self-attention semantic-segmentation vision-transformer visual-recognition
Last synced: about 1 year ago
JSON representation
[ICML 2023] Official PyTorch implementation of Global Context Vision Transformers
- Host: GitHub
- URL: https://github.com/NVlabs/GCVit
- Owner: NVlabs
- License: other
- Created: 2022-06-18T00:44:21.000Z (about 4 years ago)
- Default Branch: main
- Last Pushed: 2023-12-22T13:04:04.000Z (over 2 years ago)
- Last Synced: 2024-11-15T06:32:43.074Z (over 1 year ago)
- Topics: ade20k, backbone, coco, deep-learning, imagenet, imagenet-classification, object-detection, pre-train, pre-trained-model, self-attention, semantic-segmentation, vision-transformer, visual-recognition
- Language: Python
- Homepage: https://arxiv.org/abs/2206.09959
- Size: 858 KB
- Stars: 425
- Watchers: 10
- Forks: 49
- Open Issues: 1
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# Global Context Vision Transformer (GC ViT)
This repository presents the official PyTorch implementation of **Global Context Vision Transformers** (ICML2023) \
\
[Global Context Vision
Transformers](https://arxiv.org/pdf/2206.09959.pdf) \
[Ali Hatamizadeh](https://research.nvidia.com/person/ali-hatamizadeh),
[Hongxu (Danny) Yin](https://scholar.princeton.edu/hongxu),
[Greg Heinrich](https://developer.nvidia.com/blog/author/gheinrich/),
[Jan Kautz](https://jankautz.com/),
and [Pavlo Molchanov](https://www.pmolchanov.com/).
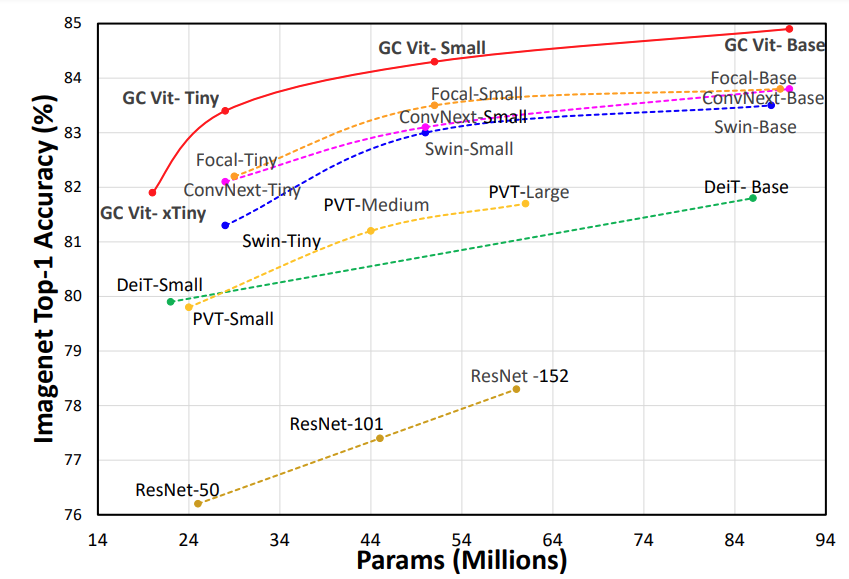
GC ViT achieves state-of-the-art results across image classification, object detection and semantic segmentation tasks. On ImageNet-1K dataset for classification, GC ViT variants with `51M`, `90M` and `201M` parameters achieve `84.3`, `85.9` and `85.7` Top-1 accuracy, respectively, surpassing comparably-sized prior art such as CNN-based ConvNeXt and ViT-based Swin Transformer.
The architecture of GC ViT is demonstrated in the following:

## 💥 News 💥
- **[10.14.2023]** 🔥 We have released the [object detection code](https://github.com/NVlabs/GCVit/tree/main/detection
) !
- **[07.27.2023]** We will present GC ViT in the (1:30-3:30 HDT) ICML23 session in exhibit hall#1, poster #516.
- **[07.22.2023]** 🔥🔥 We have released pretrained 21K GC ViT-L checkpoint for 512 x 512 resolution !
- **[07.22.2023]** Pretrained checkpoints are now available in official [NVIDIA GCViT HuggingFace](https://huggingface.co/nvidia/GCViT) page !
- **[07.21.2023]** 🔥 We have released the object detection/instance segmentation [code](./detection/README.md) !
- **[05.21.2023]** 🔥 We have released ImageNet-21K fine-tuned GC ViT model weights for 224x224 and 384x384.
- **[05.21.2023]** 🔥🔥 We have released new ImageNet-1K GC ViT model weights with **better performance** !
- **[04.24.2023]** 🔥🔥🔥 GC ViT has been accepted to **ICML 2023** !
## Introduction
**GC ViT** leverages global context self-attention modules, joint with local self-attention, to effectively yet efficiently model both long and short-range spatial interactions, without the need for expensive
operations such as computing attention masks or shifting local windows.

## ImageNet Benchmarks
**ImageNet-1K Pretrained Models**
Model Variant
Acc@1
#Params(M)
FLOPs(G)
Download
GC ViT-XXT
79.9
12
2.1
model
GC ViT-XT
82.0
20
2.6
model
GC ViT-T
83.5
28
4.7
model
GC ViT-T2
83.7
34
5.5
model
GC ViT-S
84.3
51
8.5
model
GC ViT-S2
84.8
68
10.7
model
GC ViT-B
85.0
90
14.8
model
GC ViT-L
85.7
201
32.6
model
**ImageNet-21K Pretrained Models**
Model Variant
Resolution
Acc@1
#Params(M)
FLOPs(G)
Download
GC ViT-L
224 x 224
86.6
201
32.6
model
GC ViT-L
384 x 384
87.4
201
120.4
model
GC ViT-L
512 x 512
87.6
201
245.0
model
## Installation
The dependencies can be installed by running:
```bash
pip install -r requirements.txt
```
## Data Preparation
Please download the ImageNet dataset from its official website. The training and validation images need to have
sub-folders for each class with the following structure:
```bash
imagenet
├── train
│ ├── class1
│ │ ├── img1.jpeg
│ │ ├── img2.jpeg
│ │ └── ...
│ ├── class2
│ │ ├── img3.jpeg
│ │ └── ...
│ └── ...
└── val
├── class1
│ ├── img4.jpeg
│ ├── img5.jpeg
│ └── ...
├── class2
│ ├── img6.jpeg
│ └── ...
└── ...
```
## Commands
### Training on ImageNet-1K From Scratch (Multi-GPU)
The `GC ViT` model can be trained on ImageNet-1K dataset by running:
```bash
python -m torch.distributed.launch --nproc_per_node --master_port 11223 train.py \
--config --data_dir --batch-size --amp --tag --model-ema
```
To resume training from a pre-trained checkpoint:
```bash
python -m torch.distributed.launch --nproc_per_node --master_port 11223 train.py \
--resume --config --amp --data_dir --batch-size --tag --model-ema
```
### Evaluation
To evaluate a pre-trained checkpoint using ImageNet-1K validation set on a single GPU:
```bash
python validate.py --model --checkpoint --data_dir --batch-size
```
## Citation
Please consider citing GC ViT paper if it is useful for your work:
```
@inproceedings{hatamizadeh2023global,
title={Global context vision transformers},
author={Hatamizadeh, Ali and Yin, Hongxu and Heinrich, Greg and Kautz, Jan and Molchanov, Pavlo},
booktitle={International Conference on Machine Learning},
pages={12633--12646},
year={2023},
organization={PMLR}
}
```
## Third-party Implementations and Resources
In this section, we list third-party contributions by other users. If you would like to have your work included here, please
raise an issue in this repository.
| Name | Link | Contributor | Framework
|:---:|:---:|:---:|:---------:|
|timm|[Link](https://github.com/rwightman/pytorch-image-models)| @rwightman | PyTorch
|tfgcvit|[Link](https://github.com/shkarupa-alex/tfgcvit)| @shkarupa-alex | Tensorflow 2.0 (Keras)
|gcvit-tf|[Link](https://github.com/awsaf49/gcvit-tf)| @awsaf49 | Tensorflow 2.0 (Keras)
|GCViT-TensorFlow|[Link](https://github.com/EMalagoli92/GCViT-TensorFlow)| @EMalagoli92 | Tensorflow 2.0 (Keras)
|keras_cv_attention_models|[Link](https://github.com/leondgarse/keras_cv_attention_models/tree/main/keras_cv_attention_models/gcvit)| @leondgarse | Keras
|flaim|[Link](https://github.com/BobMcDear/flaim)| @BobMcDear | JAX/Flax
## Additional Resources
We list additional GC ViT resources such as notebooks, demos, paper explanations in this section. If you have created similar items and would like to be included, please raise an issue in this repository.
| Name | Link | Contributor | Note
|:---:|:---:|:---:|:---------:|
|Paper Explanation|[Link](https://www.kaggle.com/code/awsaf49/guie-global-context-vit-gcvit)| @awsaf49 | Annotated GC ViT
|Colab Notebook|[Link](https://colab.research.google.com/github/awsaf49/gcvit-tf/blob/main/notebooks/GCViT_Flower_Classification.ipynb)| @awsaf49 | Flower classification
|Kaggle Notebook|[Link](https://www.kaggle.com/code/awsaf49/flower-classification-gcvit-global-context-vit/notebook)| @awsaf49 | Flower classification
|Live Demo|[Link](https://huggingface.co/spaces/awsaf49/gcvit-tf)| @awsaf49 | Hugging Face demo
## Licenses
Copyright © 2023, NVIDIA Corporation. All rights reserved.
This work is made available under the Nvidia Source Code License-NC. Click [here](LICENSE) to view a copy of this license.
The pre-trained models are shared under [CC-BY-NC-SA-4.0](https://creativecommons.org/licenses/by-nc-sa/4.0/). If you remix, transform, or build upon the material, you must distribute your contributions under the same license as the original.
For license information regarding the timm, please refer to its [repository](https://github.com/rwightman/pytorch-image-models).
For license information regarding the ImageNet dataset, please refer to the ImageNet [official website](https://www.image-net.org/).
## Acknowledgement
- This repository is built upon the [timm](https://github.com/rwightman/pytorch-image-models) library.
- We would like to sincerely thank the community especially Github users @rwightman, @shkarupa-alex, @awsaf49, @leondgarse, who have provided insightful feedback, which has helped us to further improve GC ViT and achieve even better benchmarks.