https://github.com/OpenLMLab/LOMO
LOMO: LOw-Memory Optimization
https://github.com/OpenLMLab/LOMO
Last synced: about 1 year ago
JSON representation
LOMO: LOw-Memory Optimization
- Host: GitHub
- URL: https://github.com/OpenLMLab/LOMO
- Owner: OpenLMLab
- License: mit
- Created: 2023-06-16T08:17:45.000Z (almost 3 years ago)
- Default Branch: main
- Last Pushed: 2024-07-02T14:57:27.000Z (almost 2 years ago)
- Last Synced: 2025-03-31T03:18:31.052Z (about 1 year ago)
- Language: Python
- Size: 1.72 MB
- Stars: 982
- Watchers: 12
- Forks: 70
- Open Issues: 29
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- StarryDivineSky - OpenLMLab/LOMO - Memory **O**ptimization,它将梯度计算和参数更新融合在一步中,以减少内存使用。 我们的方法使得在单张 RTX 3090 上可以进行 7B 模型的全参数微调,或者在单个 8×RTX 3090 的机器上可以进行 65B 模型的全参数微调(RTX 3090 的内存为 24GB)。 (A01_文本生成_文本对话 / 大语言对话模型及数据)
README
[**English**](./README.md) | [**中文**](./README_ZH.md)
This is the implementation for [Full Parameter Fine-Tuning for Large Language Models with Limited Resources](https://arxiv.org/pdf/2306.09782.pdf)
and [AdaLomo: Low-memory Optimization with Adaptive Learning Rate](https://arxiv.org/pdf/2310.10195.pdf).
# News
- LOMO and AdaLomo were integrated in [`transformers`](https://huggingface.co/docs/transformers/main/en/trainer#lomo-optimizer) and [`accelerate`](https://huggingface.co/docs/accelerate/main/en/package_reference/accelerator#accelerate.Accelerator.lomo_backward).
- PyPI package `lomo-optim` was released.
- LOMO and AdaLomo were integrated in [`CoLLiE`](https://github.com/OpenMOSS/collie) library, which supports Collaborative Training of Large Language Models in an Efficient Way.
# Usage
You can install `lomo-optim` from PyPI using pip.
```bash
pip install lomo-optim
```
Then, import `Lomo` or `AdaLomo`.
```python
from lomo_optim import Lomo
from lomo_optim import AdaLomo
```
The usage of `Lomo` and `AdaLomo` is similar but not the same as PyTorch's optimizers
([example](https://github.com/OpenMOSS/CoLLiE/blob/726ec80d263c1e1c56344dfde5b3c24897daa94d/collie/controller/trainer.py#L469)).
We recommend to use `AdaLomo` without `gradnorm` to get better performance and higher throughput.
# LOMO: LOw-Memory Optimization
In this work, we propose a new optimizer, **LO**w-Memory **O**ptimization (**LOMO**), which fuses the gradient computation and the parameter update in one step to reduce memory usage.
Our approach enables the full parameter fine-tuning of a 7B model on a single RTX 3090, or
a 65B model on a single machine with 8×RTX 3090, each with 24GB memory.
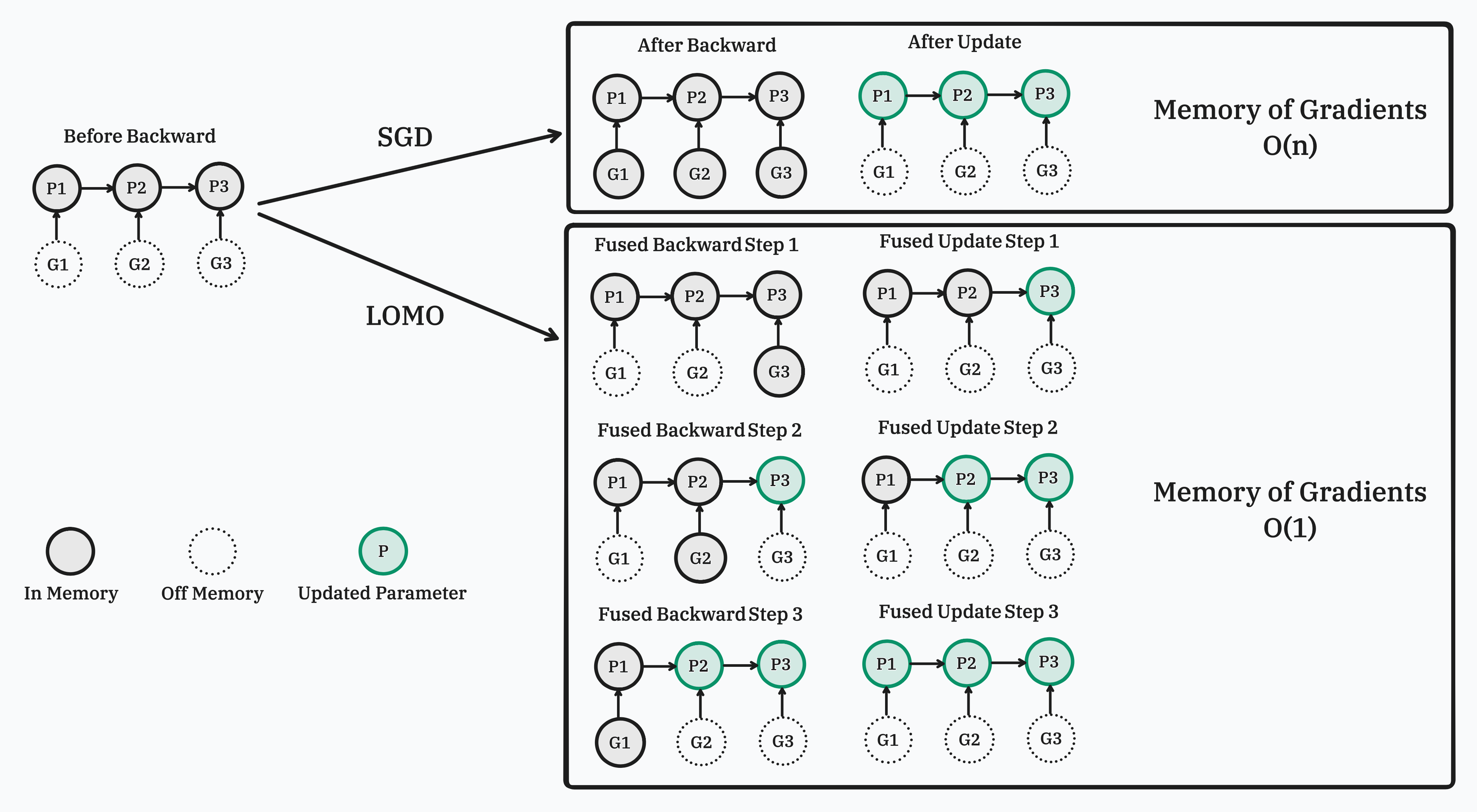
## Implementation
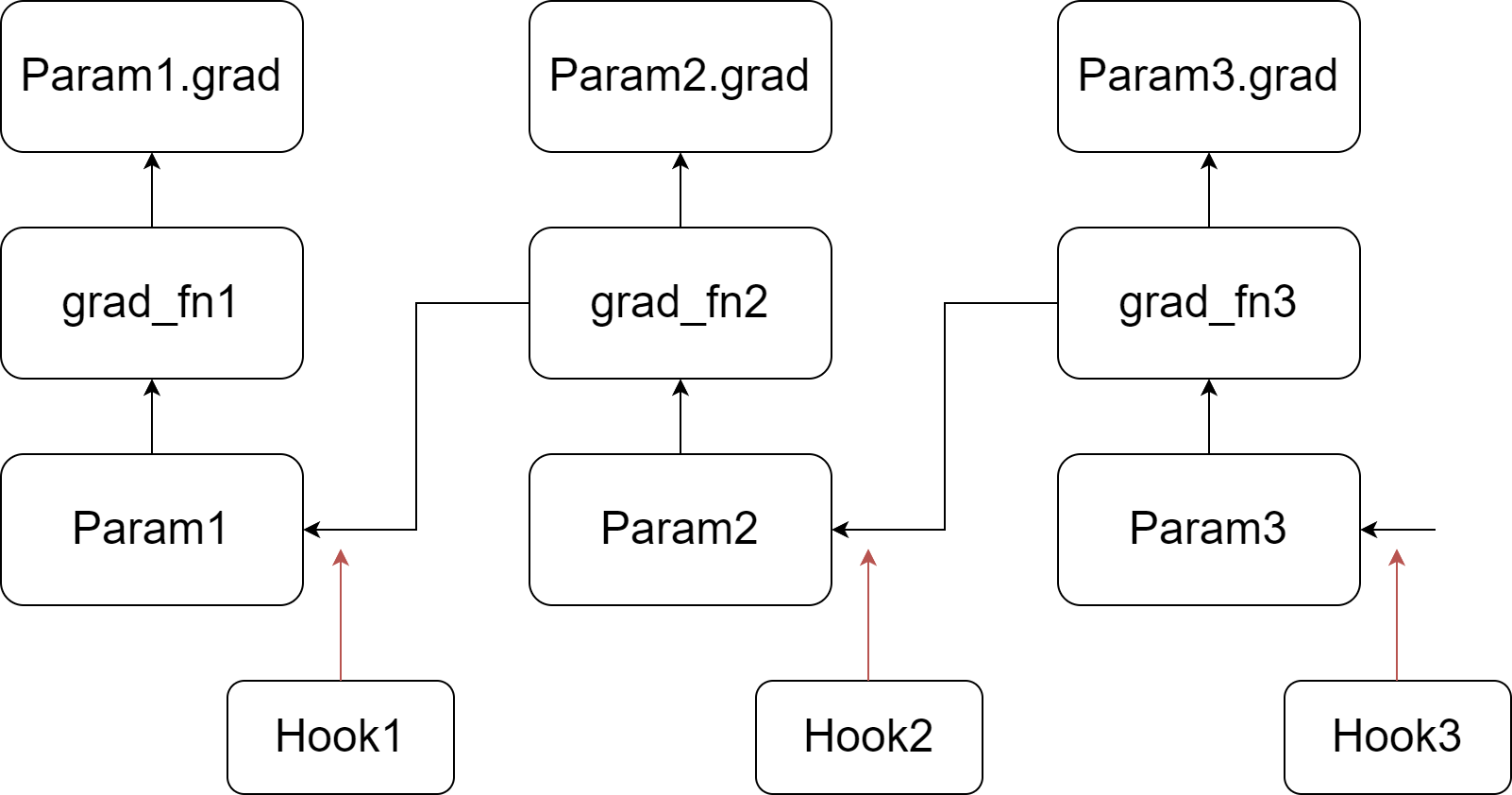
Our implementation relies on injecting hook functions into PyTorch's backward pass. As depicted in the figure, we register a customized hook function for each parameter. When the gradient of a parameter is computed (prior to writing it to the .grad attribute), its corresponding hook function is invoked. For more information about hook functions and the backward pass of the autograd graph, please refer to [PyTorch's documentation](https://pytorch.org/docs/stable/notes/autograd.html#backward-hooks-execution). In summary, during the backward pass, we go through a tensor and its grad_fn, write the gradient into the .grad attribute, and then pass to the next tensor.
Our customized hook function scans all the parameters, updating a parameter if its .grad attribute is not empty, and then clears and frees the .grad attribute. Since the hook function for a parameter is called before its .grad attribute is set, the .grad attribute of the last parameter in the autograd graph is not ready when the last hook function is invoked. Therefore, we perform an additional scan to update the last parameter.
The code for LOMO is in [lomo](lomo) folder.
# AdaLomo: Low-memory Optimization with Adaptive Learning Rate
In this work, we examined the distinctions between the LOMO and Adam optimization techniques and introduce AdaLomo, which provides an adaptive learning rate for each parameter and utilizes grouped update normalization while maintaining memory efficiency.
AdaLomo achieves results comparable to AdamW in both instruction-tuning and further pre-training with less memory footprint.

The code for AdaLomo is in [adalomo](adalomo) folder.
## Citation
```text
@article{lv2023full,
title={Full Parameter Fine-tuning for Large Language Models with Limited Resources},
author={Lv, Kai and Yang, Yuqing and Liu, Tengxiao and Gao, Qinghui and Guo, Qipeng and Qiu, Xipeng},
journal={arXiv preprint arXiv:2306.09782},
year={2023}
}
@article{lv2023adalomo,
title={AdaLomo: Low-memory Optimization with Adaptive Learning Rate},
author={Lv, Kai and Yan, Hang and Guo, Qipeng and Lv, Haijun and Qiu, Xipeng},
journal={arXiv preprint arXiv:2310.10195},
year={2023}
}
```