https://github.com/P-p-H-d/mlib
Library of generic and type safe containers in pure C language (C99 or C11) for a wide collection of container (comparable to the C++ STL).
https://github.com/P-p-H-d/mlib
algorithms array bitset c collections data-structures generic hashmap json list lock-free memory-pool priority-queue queue set stack string tree tuples variant
Last synced: over 1 year ago
JSON representation
Library of generic and type safe containers in pure C language (C99 or C11) for a wide collection of container (comparable to the C++ STL).
- Host: GitHub
- URL: https://github.com/P-p-H-d/mlib
- Owner: P-p-H-d
- License: bsd-2-clause
- Created: 2017-02-18T17:35:25.000Z (over 9 years ago)
- Default Branch: master
- Last Pushed: 2024-08-19T20:03:25.000Z (almost 2 years ago)
- Last Synced: 2024-08-20T23:54:07.888Z (almost 2 years ago)
- Topics: algorithms, array, bitset, c, collections, data-structures, generic, hashmap, json, list, lock-free, memory-pool, priority-queue, queue, set, stack, string, tree, tuples, variant
- Language: C
- Homepage:
- Size: 9.68 MB
- Stars: 861
- Watchers: 28
- Forks: 77
- Open Issues: 3
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- awesome-lists - type safe containers in pure C
- awesome-c - M\*LIB - Library for generic, but typesafe C containers. Implemented as header-only. [BSD-2-Clause](https://spdx.org/licenses/BSD-2-Clause.html) (Data Structures)
- awesome-c-zh - M*LIB - 用于通用但类型安全的C容器的库。实施为仅标题。[](https://spdx.org/licenses/BSD-2-Clause.html) (数据结构)
- awesome-c - M\*LIB - Library for generic, but typesafe C containers. Implemented as header-only. [BSD-2-Clause](https://spdx.org/licenses/BSD-2-Clause.html) (Data Structures)
- AwesomeCppGameDev - mlib
README
M\*LIB: Generic type-safe Container Library for C language
==========================================================
1. [Overview](#overview)
2. [Components](#components)
3. [Build & Installation](#build--installation)
4. [How to use](#how-to-use)
5. [Performance](#performance)
6. [OPLIST](#oplist)
7. [Memory Allocation](#memory-allocation)
8. [Emplace construction](#Emplace-construction)
9. [Errors & compilers](#errors--compilers)
10. [External Reference](#external-reference)
11. [API Documentation](#api-documentation)
1. [Generic methods](#generic-methods)
2. [List](#m-list)
3. [Array](#m-array)
4. [Deque](#m-deque)
5. [Dictionary](#m-dict)
6. [Tuple](#m-tuple)
7. [Variant](#m-variant)
8. [Red/Black Tree](#m-rbtree)
9. [B+ Tree](#m-bptree)
10. [Generic Tree](#m-tree)
11. [Priority queue](#m-prioqueue)
12. [Fixed buffer queue](#m-buffer)
13. [Atomic Shared Register](#m-snapshot)
14. [Shared pointers](#m-shared-ptr)
15. [Intrusive Shared Pointers](#m-i-shared)
16. [Intrusive list](#m-i-list)
17. [Concurrent adapter](#m-concurrent)
18. [Bitset](#m-bitset)
19. [String](#m-string)
20. [Core preprocessing](#m-core)
21. [Thread](#m-thread)
22. [Worker threads](#m-worker)
23. [Atomic](#m-atomic)
24. [Generic algorithms](#m-algo)
25. [Function objects](#m-funcobj)
26. [Exception handling](#m-try)
27. [Memory pool](#m-mempool)
28. [JSON Serialization](#m-serial-json)
29. [Binary Serialization](#m-serial-bin)
30. [Generic interface](#m-generic)
31. [Byte String](#m-bstring)
12. [Global User Customization](#global-user-customization)
13. [License](#license)
## Overview
M\*LIB (M star lib) is a C library enabling to define and to use **generic and
type safe container** in C, aka handling generic
[containers](https://en.wikipedia.org/wiki/Container_%28abstract_data_type%29) in pure C language.
The encapsulated objects can have their own constructor, destructor, operators
or can be basic C type like the C type 'int': both are fully supported.
This makes it possible to construct fully
recursive container objects (`container-of[...]-container-of-type-T`)
while keeping compile time type checking.
This is an equivalent of the [C++](https://en.wikipedia.org/wiki/C%2B%2B)
[Standard Library](https://en.wikipedia.org/wiki/C%2B%2B_Standard_Library),
providing vector, deque, forward_list, set, map, multiset, multimap,
unordered_set, unordered_map, stack, queue, shared_ptr, string, variant, option
to standard ISO C99 / C11.
There is not a strict mapping as both the STL and M\*LIB have their exclusive containers:
See [here](https://github.com/P-p-H-d/mlib/wiki/STL-to-M*LIB-mapping) for details.
M\*LIB provides also additional concurrent containers to design properly
multi-threaded programs: shared register, communication queue, ...
M\*LIB is portable to any systems that support [ISO C99](https://en.wikipedia.org/wiki/C99).
Some optional features need at least [ISO C11](https://en.wikipedia.org/wiki/C11_(C_standard_revision)).
M\*LIB is **only** composed of a set of headers.
There is no C file, and as such, the installation is quite simple:
you just have to put the header in the search path of your compiler,
and it will work.
There is no dependency (except some other headers of M\*LIB and the LIBC).
One of M\*LIB design key is to ensure safety. This is done by multiple means:
* in debug mode, defensive programming is extensively used:
the contracts of the function are checked, ensuring
that the data are not corrupted. For example, strict
[Buffer overflow](https://en.wikipedia.org/wiki/Buffer_overflow) are checked in this mode
through [bound checking](https://en.wikipedia.org/wiki/Bounds_checking)
or the intrinsic properties of a Red-Black tree (for example) are verified.
Buffer overflow checks can still be kept in release mode if needed.
* as few cast as possible are used within the library (casts are the evil of safety).
Still the library can be used with the greatest level of warnings by a C compiler without
any aliasing warning.
* the genericity is not done directly by macro (which usually prevent type safety), but indirectly by making them
define inline functions with the proper prototypes: this enables
the user calls to have proper error and warning checks.
* extensive testing: the library is tested on the main targets using Continuous Integration with a coverage of the test suite of more than 99%.
The test suite itself is run through the multiple sanitizers defined by GCC/CLANG (Address, undefined, leak, thread).
The test suite also includes a comparison of equivalent behaviors of M\*LIB with the C++ STL using random testing or fuzzer testing.
* static analysis: multiple static analyzer (like scan-build or GCC fanalyzer or CodeQL) are run on the generated code, and the results analyzed.
Other key designs are:
* do not rewrite the C library and just wrap around it (for example don't rewrite sort but stable sort),
* do not make users pay the cost of what they don't need.
Due to the unfortunate [weak](https://en.wikipedia.org/wiki/Strong_and_weak_typing#Pointers) nature of the C language for pointers,
[type safe](https://en.wikipedia.org/wiki/Type_safety) means that at least a warning
is generated by the compiler in case of wrong type passed as
container arguments to the functions.
M\*LIB is still quite-efficient:
there is no overhead in using this library rather than using
direct C low-level access as the compiler is able to **fully** optimize
the library usage
and the library is carefully designed.
In [fact](https://github.com/P-p-H-d/mlib/wiki/performance), M\*LIB
is one of the fastest generic C/C++ library you can find.
M\*LIB uses internally the `malloc`, `realloc` and `free` functions to handle
the memory pool. This behavior can be overridden at different level.
Its default policy is to abort the program if there is a memory error.
However, this behavior can also be customized globally.
M\*LIB supports also the exception error model by providing its own implementation of the try / catch mechanism.
This mechanism is compatible with [RAII programming](https://en.wikipedia.org/wiki/Resource_acquisition_is_initialization):
when an exception is thrown, the destructors of the constructed objects are called (See [m-try](#m-try) for more details).
M\*LIB may use a lot of assertions in its implementation to ensure safety:
it is highly recommended to properly define `NDEBUG` for released programs.
M\*LIB provides automatically several [serialization](https://en.wikipedia.org/wiki/Serialization) methods for each containers.
You can read or write your full and complex data structure into [JSON](https://en.wikipedia.org/wiki/JSON) format in a few lines.
M\*LIB is distributed under BSD-2 simplified license.
It is strongly advised not to read the source to know how to use the library
as the code is quite complex and uses a lot of tricks
but rather read the examples.
In this documentation,
* _shall_ will be used to indicate a user constraint that is
mandatory to follow under penalty of undefined behavior.
* _should_ will be used to indicate a recommendation to the user.
All pointers expected by the functions of the library shall expect non-null argument except if indicated.
## Components
The following headers define containers that don't require the user structure to be modified:
* [m-array.h](#m-array): header for creating dynamic array of generic type,
* [m-list.h](#m-list): header for creating singly-linked list of generic type,
* [m-deque.h](#m-deque): header for creating dynamic double-ended queue of generic type,
* [m-dict.h](#m-dict): header for creating unordered associative array (through hashmap) or unordered set of generic type,
* [m-rbtree.h](#m-rbtree): header for creating ordered set (through Red/Black binary sorted tree) of generic type,
* [m-bptree.h](#m-bptree): header for creating ordered map/set/multimap/multiset (through sorted B+TREE) of generic type,
* [m-tree.h](#m-tree): header for creating arbitrary tree of generic type,
* [m-tuple.h](#m-tuple): header for creating arbitrary tuple of generic types,
* [m-variant.h](#m-variant): header for creating arbitrary variant of generic type,
* [m-prioqueue.h](#m-prioqueue): header for creating dynamic priority queue of generic type.
The available containers of M\*LIB for thread synchronization are in the following headers:
* [m-buffer.h](#m-buffer): header for creating fixed-size queue (or stack) of generic type (multiple producer / multiple consumer),
* [m-snapshot](#m-snapshot): header for creating 'atomic buffer' (through triple buffer) for sharing synchronously big data (thread safe),
* [m-shared-ptr.h](#m-shared-ptr): header for creating shared pointer of generic type,
* m-c-mempool.h: WIP header for creating fast concurrent memory allocation.
The following containers are intrusive (You need to modify your structure to add fields needed by the container) and are defined in:
* [m-i-list.h](#m-i-list): header for creating doubly-linked intrusive list of generic type,
Other headers offering other functionality are:
* [m-string.h](#m-string): header for creating dynamic string of characters (UTF-8 support),
* [m-bstring.h](#m-bstring): header for creating dynamic string of BYTE,
* [m-bitset.h](#m-bitset): header for creating dynamic bitset (or "packed array of bool"),
* [m-algo.h](#m-algo): header for providing various generic algorithms to the previous containers,
* [m-funcobj.h](#m-funcobj): header for creating function object (used by algorithm generation),
* [m-try.h](#m-try): header for handling errors by throwing exceptions,
* [m-mempool.h](#m-mempool): header for creating specialized & fast memory allocator,
* [m-worker.h](#m-worker): header for providing an easy pool of workers on separated threads to handle work orders (used for parallel tasks),
* [m-serial-json.h](#m-serial-json): header for importing / exporting the containers in [JSON format](https://en.wikipedia.org/wiki/JSON),
* [m-serial-bin.h](#m-serial-bin): header for importing / exporting the containers in an adhoc fast binary format,
* [m-generic.h](#m-generic): header for using a common interface for all registered types,
* [m-genint.h](m-genint.h): internal header for generating unique integers in a concurrent context,
* [m-core.h](#m-core): header for meta-programming with the C preprocessor (used by all other headers).
Finally, headers for compatibility with non C11 compilers:
* [m-atomic.h](#m-atomic): header for ensuring compatibility between C's `stdatomic.h` and C++'s atomic header (provide also its own implementation if nothing is available),
* [m-thread.h](#m-thread): header for providing a very thin layer across multiple implementation of mutex/threads (C11/PTHREAD/WIN32).
The following headers are obsolete:
* [m-shared.h](#m-shared): header for creating shared pointer of generic type,
* [m-concurrent.h](#m-concurrent): header for transforming a container into a concurrent container (thread safe),
* [m-i-shared.h](#m-i-shared): header for creating intrusive shared pointer of generic type (Thread Safe).
Each containers define their iterators (if it is meaningful).
All containers try to expose the same common interface:
if the method name is the same, then it does the same thing
and is used in the same way.
In some rare case, the method is adapted to the container needs.
Each header can be used separately from others: dependency between headers have been kept to the minimum.

## Build & Installation
M\*LIB is **only** composed of a set of headers, as such there is no build for the library.
The library doesn't depend on any other library than the LIBC.
To run the test suite, run:
```bash
make check
```
You can also override the compiler CC or its flags CFLAGS if needed:
```bash
make check CC="gcc" CFLAGS="-O3"
```
To generate the documentation, run:
```bash
make doc
```
To install the headers, run:
```bash
make install PREFIX=/my/directory/where/to/install [DESTDIR=...]
```
Other targets exist. Mainly for development purpose.
## How to use
To use these data structures, you first include the desired header,
instantiate the definition of the structure and its associated methods
by using a macro `_DEF` for the needed container.
Then you use the defined types and functions. Let's see a first simple example
that creates a list of unsigned int:
```C
#include
#include "m-list.h"
LIST_DEF(list_uint, unsigned int) /* Define struct list_uint_t and its methods */
int main(void) {
list_uint_t list ; /* list_uint_t has been define above */
list_uint_init(list); /* All type needs to be initialized */
list_uint_push_back(list, 42); /* Push 42 in the list */
list_uint_push_back(list, 17); /* Push 17 in the list */
list_uint_it_t it; /* Define an iterator to scan each one */
for(list_uint_it(it, list) /* Start iterator on first element */
; !list_uint_end_p(it) /* Until the end is not reached */
; list_uint_next(it)) { /* Set the iterator to the next element*/
printf("%d\n", /* Get a reference to the underlying */
*list_uint_cref(it)); /* data and print it */
}
list_uint_clear(list); /* Clear all the list (destroying the object list)*/
}
```
> [!NOTE] Do not forget to add `-std=c99` (or c11) to your compile command to request a C99 compatible build
>
This looks like a typical C program except the line with `LIST_DEF`
that doesn't have any semi-colon at the end. And in fact, except
this line, everything is typical C program and even macro free!
The only macro is in fact `LIST_DEF`: this macro expands to the
good type for the list of the defined type and to all the necessary
functions needed to handle such type. It is heavily context dependent
and can generate different code depending on it.
You can use it as many times as needed to defined as many lists as you want.
The first argument of the macro is the name to use, e.g. the prefix that
is added to all generated functions and types.
The second argument of the macro is the type to embed within the container.
It can be any C type.
The third argument of the macro is optional and is the oplist to use.
See below for more information.
You could replace `LIST_DEF` by `ARRAY_DEF` to change
the kind of container (an array instead of a linked list)
without changing the code below: the generated interface
of a list or of an array is very similar.
Yet the performance remains the same as hand-written code
for both the list variant and the array variant.
This is equivalent to this C++ program using the STL:
```C
#include
#include
typedef std::list list_uint_t;
typedef std::list::iterator list_uint_it_t;
int main(void) {
list_uint_t list ; /* list_uint_t has been define above */
list.push_back(42); /* Push 42 in the list */
list.push_back(17); /* Push 17 in the list */
for(list_uint_it_t it = list.begin() /* Iterator is first element*/
; it != list.end() /* Until the end is not reached */
; ++it) { /* Set the iterator to the next element*/
std::cout << *it << '\n'; /* Print the underlying data */
}
}
```
As you can see, this is rather equivalent with the following remarks:
* M\*LIB requires an explicit definition of the instance of the list,
* M\*LIB code is more verbose in the method name,
* M\*LIB needs explicit construction and destruction (as plain old C requests),
* M\*LIB doesn't return a value to the underlying data but a pointer to this value:
- this was done for performance (it avoids copying all the data within the stack)
- and for generality reasons (some structure may not allow copying data).
Note: M\*LIB defines its own container as an array of a structure of size 1.
This has the following advantages:
* you effectively reserve the data whenever you declare a variable,
* you pass automatically the variable per reference for a function call,
* you can not copy the variable by an affectation (you have to use the API instead).
M\*LIB offers also the possibility to condense further your code, so that it is more high level:
by using the `M_EACH` & `M_LET` macros (if you are not afraid of using syntactic macros):
```C
#include
#include "m-list.h"
LIST_DEF(list_uint, unsigned int) /* Define struct list_uint_t and its methods */
int main(void) {
M_LET(list, LIST_OPLIST(uint)) { /* Define & init list as list_uint_t */
list_uint_push_back(list, 42); /* Push 42 in the list */
list_uint_push_back(list, 17); /* Push 17 in the list */
for M_EACH(item, list, LIST_OPLIST(uint)) {
printf("%d\n", *item); /* Print the item */
}
} /* Clear of list will be done now */
}
```
Here is another example with a complete type (with proper initialization & clear function) by using the [GMP](https://gmplib.org/) library:
```C
#include
#include
#include "m-array.h"
ARRAY_DEF(array_mpz, mpz_t, (INIT(mpz_init), INIT_SET(mpz_init_set), SET(mpz_set), CLEAR(mpz_clear)) )
int main(void) {
array_mpz_t array ; /* array_mpz_t has been define above */
array_mpz_init(array); /* All type needs to be initialized */
mpz_t z; /* Define a mpz_t type */
mpz_init(z); /* Initialize the z variable */
mpz_set_ui (z, 42);
array_mpz_push_back(array, z); /* Push 42 in the array */
mpz_set_ui (z, 17);
array_mpz_push_back(array, z); /* Push 17 in the array */
array_it_mpz_t it; /* Define an iterator to scan each one */
for(array_mpz_it(it, array) /* Start iterator on first element */
; !array_mpz_end_p(it) /* Until the end is not reached */
; array_mpz_next(it)) { /* Set the iterator to the next element*/
gmp_printf("%Zd\n", /* Get a reference to the underlying */
*array_mpz_cref(it)); /* data and print it */
}
mpz_clear(z); /* Clear the z variable */
array_mpz_clear(array); /* Clear all the array */
}
```
As the `mpz_t` type needs proper initialization, copy and destroy functions
we need to tell to the container how to handle such a type.
This is done by giving it the oplist associated to the type.
An oplist is an associative array where an operator is associated to its associated method.
This associative array only exists in the preprocessing step of the compilation,
resulting in no runtime cost and strict aliasing check.
In the example, we tell to the container to use
the `mpz_init` function for the `INIT` operator of the type (aka constructor),
the `mpz_clear` function for the `CLEAR` operator of the type (aka destructor),
the `mpz_set` function for the `SET` operator of the type (aka copy),
the `mpz_init_set` function for the `INIT_SET` operator of the type (aka copy constructor).
See [OPLIST](#oplist) chapter for more detailed information.
We can also write the same example shorter:
```C
#include
#include
#include "m-array.h"
// Register the oplist of a mpz_t.
#define M_OPL_mpz_t() (INIT(mpz_init), INIT_SET(mpz_init_set), \
SET(mpz_set), CLEAR(mpz_clear))
// Define an instance of an array of mpz_t (both type and function)
ARRAY_DEF(array_mpz, mpz_t)
// Register the oplist of the created instance of array of mpz_t
#define M_OPL_array_mpz_t() ARRAY_OPLIST(array_mpz, M_OPL_mpz_t())
int main(void) {
// Let's define `array` as an 'array_mpz_t' & initialize it.
M_LET(array, array_mpz_t)
// Let's define 'z1' and 'z2' to be 'mpz_t' & initialize it
M_LET (z1, z2, mpz_t) {
mpz_set_ui (z1, 42);
array_mpz_push_back(array, z1); /* Push 42 in the array */
mpz_set_ui (z2, 17);
array_mpz_push_back(array, z2); /* Push 17 in the array */
// Let's iterate over all items of the container
for M_EACH(item, array, array_mpz_t) {
gmp_printf("%Zd\n", *item);
}
} // All variables are cleared with the proper method beyond this point.
return 0;
}
```
Or even shorter when you're comfortable enough with the library:
```C
#include
#include
#include "m-array.h"
// Register the oplist of a mpz_t. It is a classic oplist.
#define M_OPL_mpz_t() M_OPEXTEND(M_CLASSIC_OPLIST(mpz), \
INIT_WITH(mpz_init_set_ui), EMPLACE_TYPE(unsigned int))
// Define an instance of an array of mpz_t (both type and function)
ARRAY_DEF(array_mpz, mpz_t)
// Register the oplist of the created instance of array of mpz_t
#define M_OPL_array_mpz_t() ARRAY_OPLIST(array_mpz, M_OPL_mpz_t())
int main(void) {
// Let's define `array` as an 'array_mpz_t' with mpz_t(17) and mpz_t(42)
M_LET((array,(17),(42)), array_mpz_t) {
// Let's iterate over all items of the container
for M_EACH(item, array, array_mpz_t) {
gmp_printf("%Zd\n", *item);
}
} // All variables are cleared with the proper method beyond this point.
return 0;
}
```
There are two ways a container can known which oplist is to be used for the type:
* either the oplist is passed explicitly for each definition of container and for the `M_LET` and `M_EACH` macros,
* or the oplist is registered globally by defining a new macro starting with the prefix `M_OPL_` and finishing with the name of type (don't forget the parenthesis and the suffix _t if needed). The macros performing the definition of container and the `M_LET` and `M_EACH` will test if such macro is defined. If it is defined, it will be used. Otherwise, default methods are used.
Here we can see that we register the `mpz_t` type into the container with
the minimum information of its interface needed, and another one to initialize a `mpz_t` from an unsigned integer.
We can also see in this example so the container ARRAY provides also
a macro to define the oplist of the array itself. This is true for
all containers and this enables to define proper recursive container like in this example which reads from a text file a definition of sections:
```C
#include
#include "m-array.h"
#include "m-tuple.h"
#include "m-dict.h"
#include "m-string.h"
TUPLE_DEF2(symbol, (offset, long), (value, long))
#define M_OPL_symbol_t() TUPLE_OPLIST(symbol, M_BASIC_OPLIST, M_BASIC_OPLIST)
ARRAY_DEF(array_symbol, symbol_t)
#define M_OPL_array_symbol_t() ARRAY_OPLIST(array_symbol, M_OPL_symbol_t())
DICT_DEF2(sections, string_t, array_symbol_t)
#define M_OPL_sections_t() DICT_OPLIST(sections, STRING_OPLIST, M_OPL_array_symbol_t())
int main(int argc, const char *argv[])
{
if (argc < 2) abort();
FILE *f = fopen(argv[1], "rt");
if (!f) abort();
M_LET(sc, sections_t) {
sections_in_str(sc, f);
array_symbol_t *a = sections_get(sc, STRING_CTE(".text"));
if (a == NULL) {
printf("There is no .text section.");
} else {
printf("Section .text is :");
array_symbol_out_str(stdout, *a);
printf("\n");
}
}
return 0;
}
```
This example reads the data from a file
and outputs the .text section if it finds it on the terminal.
Other examples are available in the example folder.
Internal fields of the structure are subject to change even for small revision
of the library.
The final goal of the library is to be able to write code like this in pure C while keeping type safety and compile time name resolution:
```C
M_LET(list, list_uint_t) {
push(list, 42);
push(list, 17);
for each (item, list) {
M_PRINT(*item, "\n");
}
}
```
See the [example](https://github.com/P-p-H-d/mlib/blob/master/example/ex11-generic01.c)
and [M-GENERIC](#M-GENERIC) header for details.
## Performance
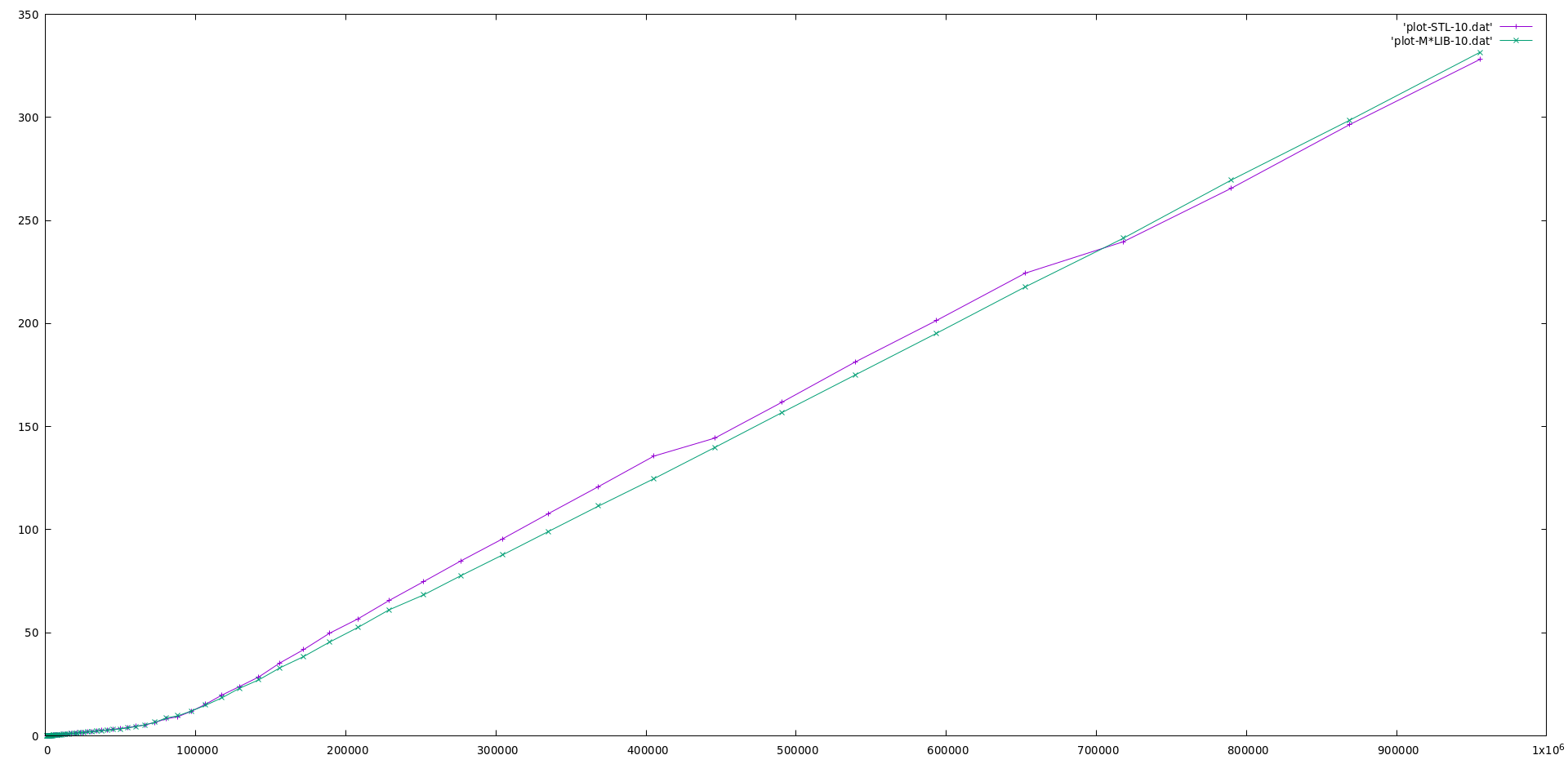
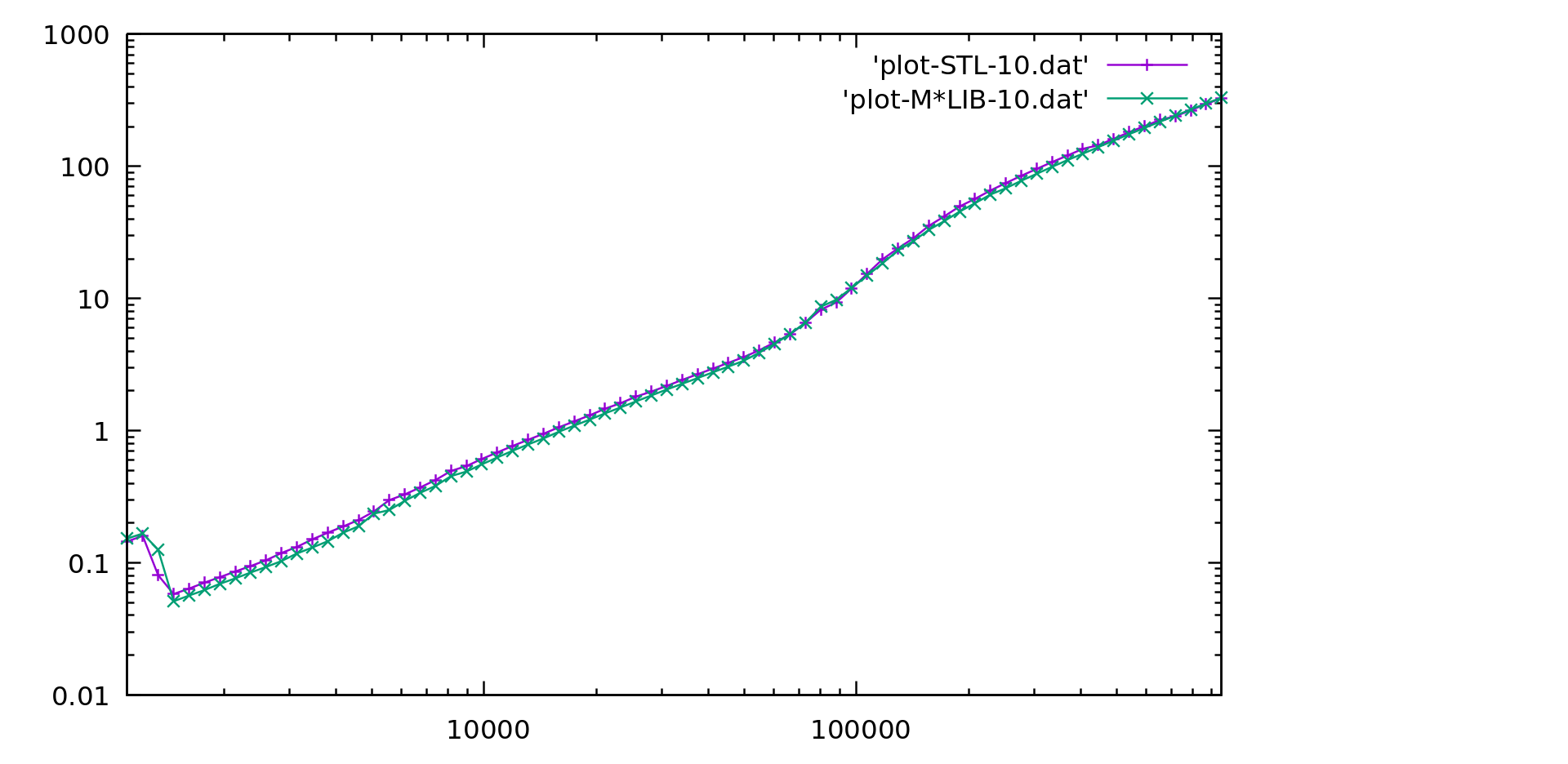
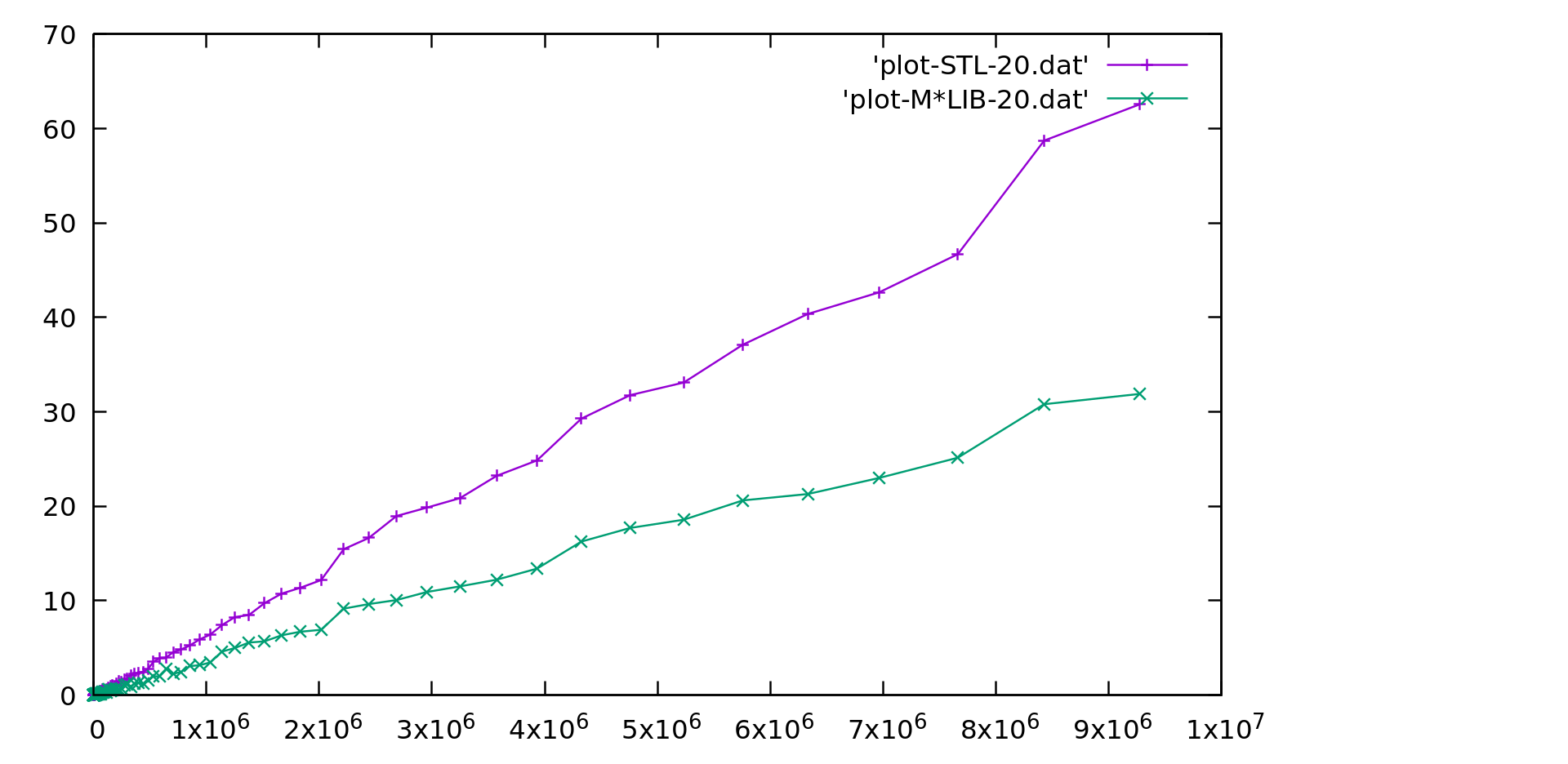
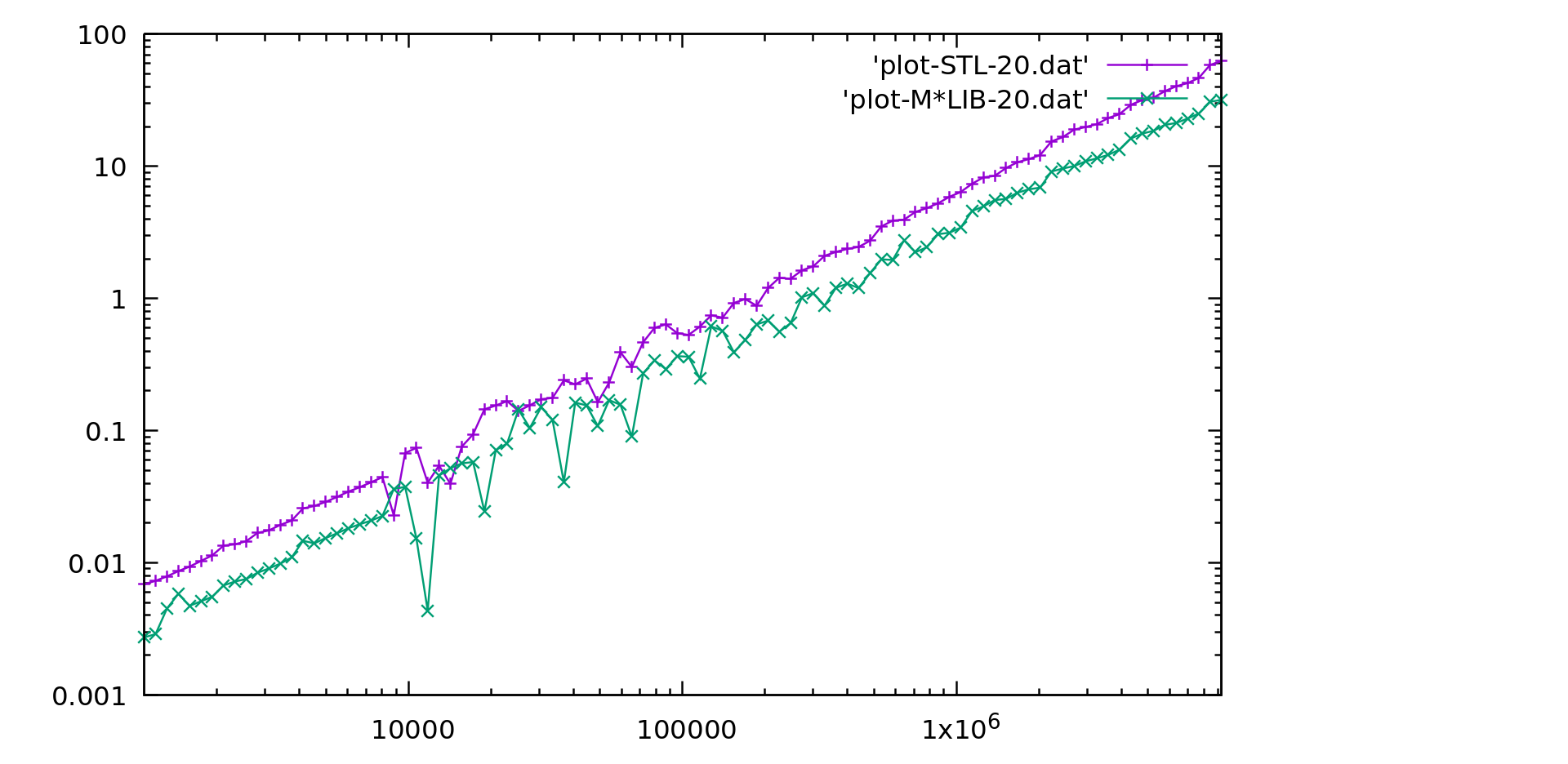
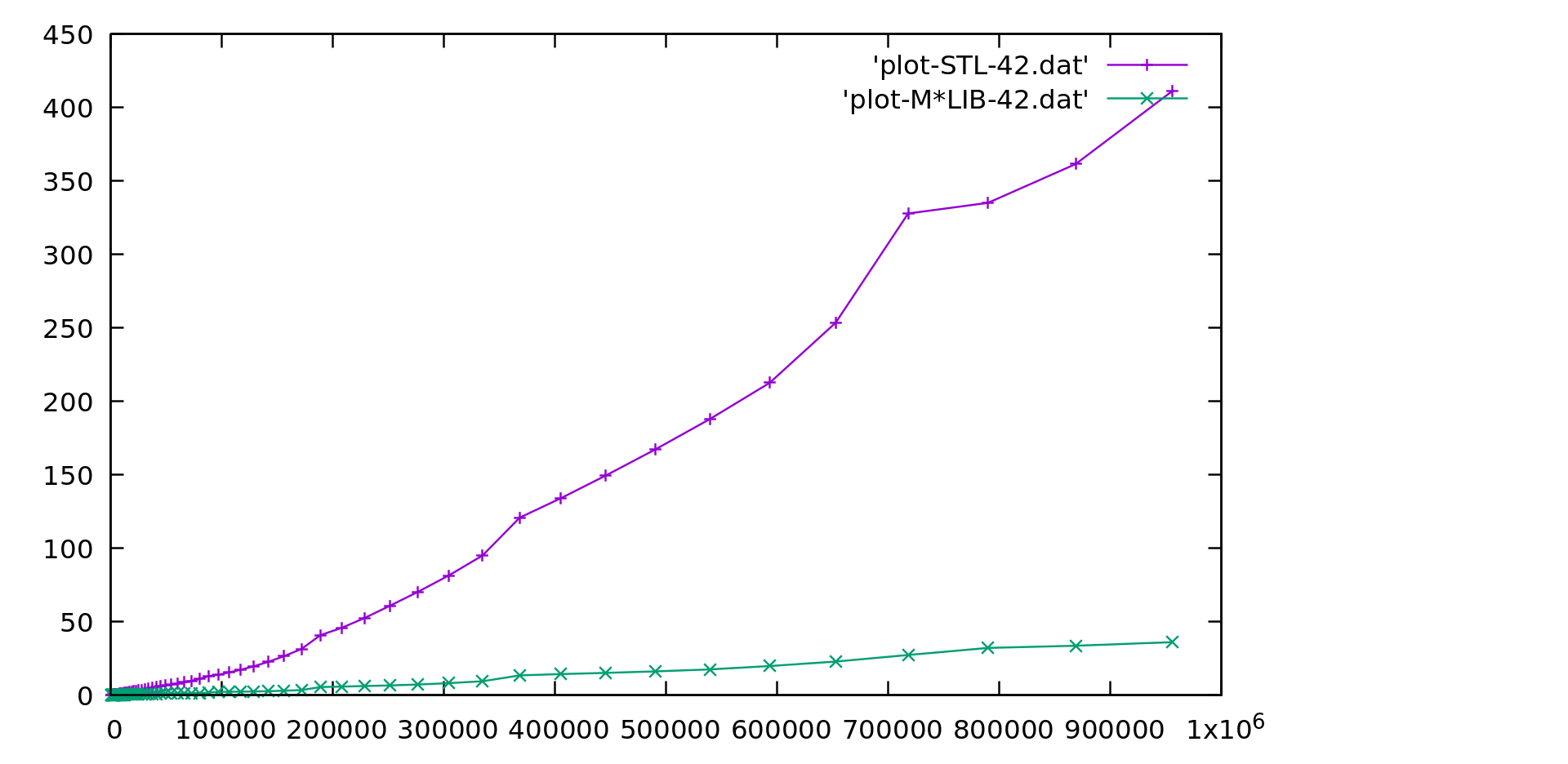
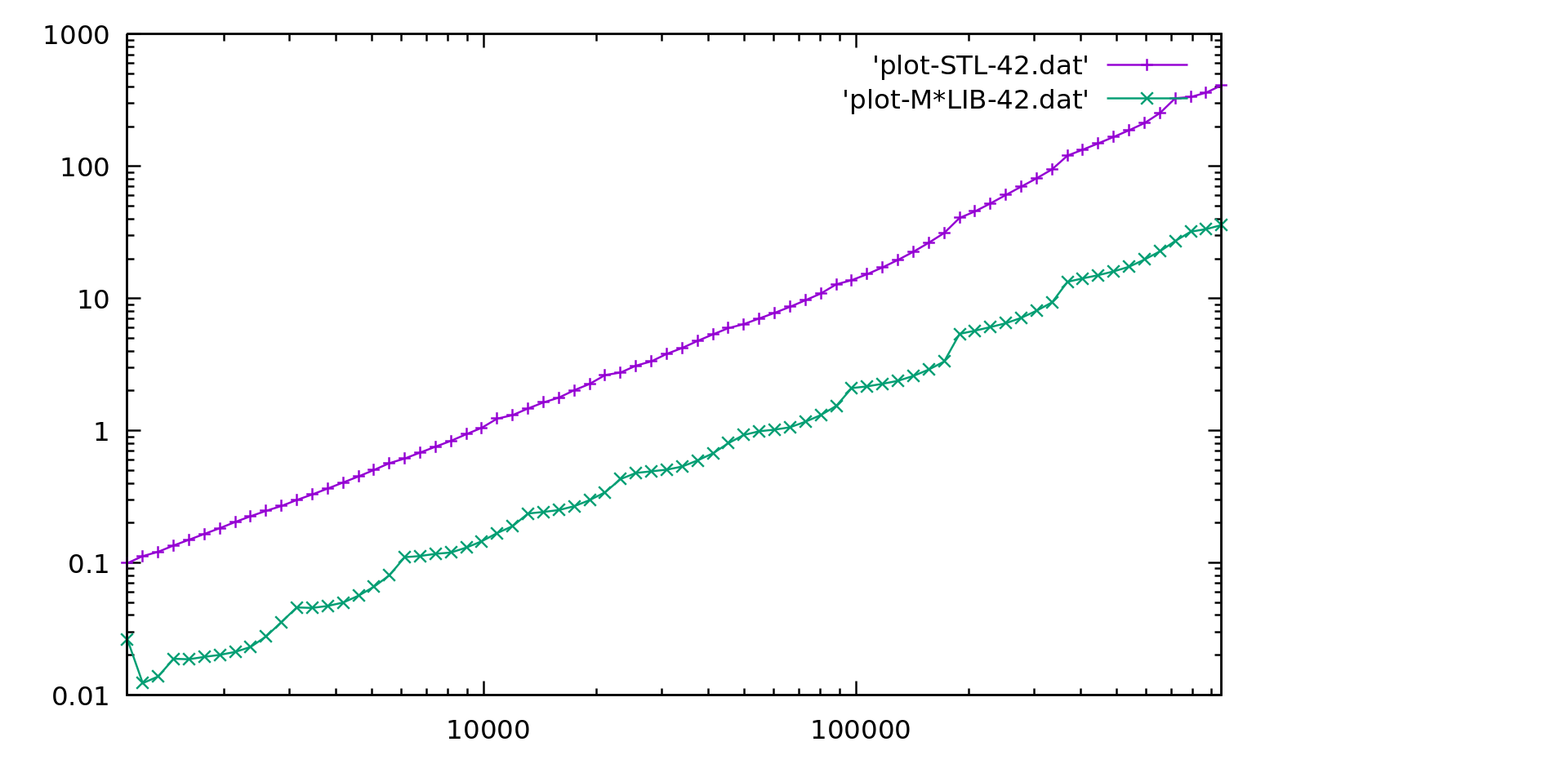
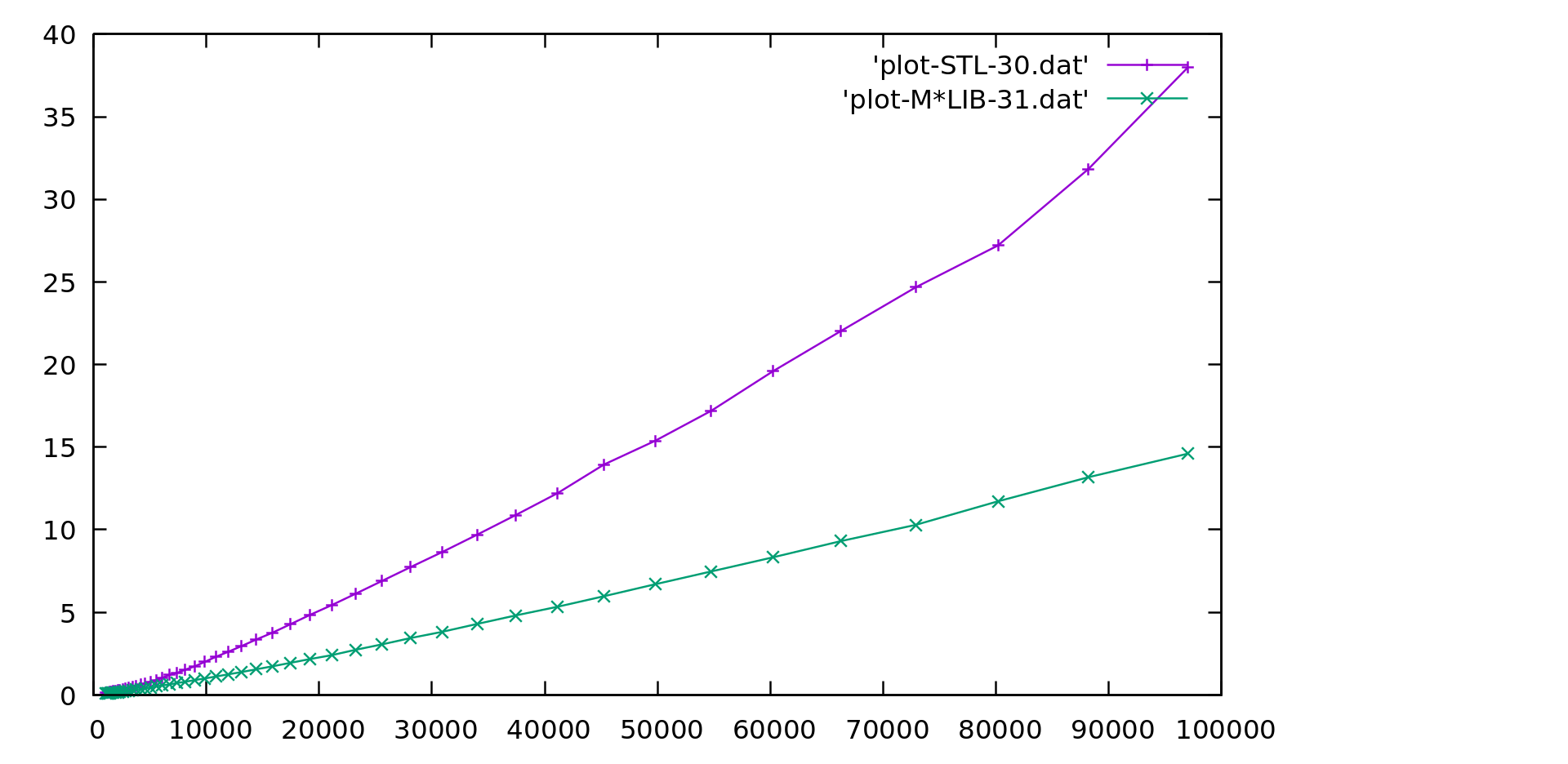
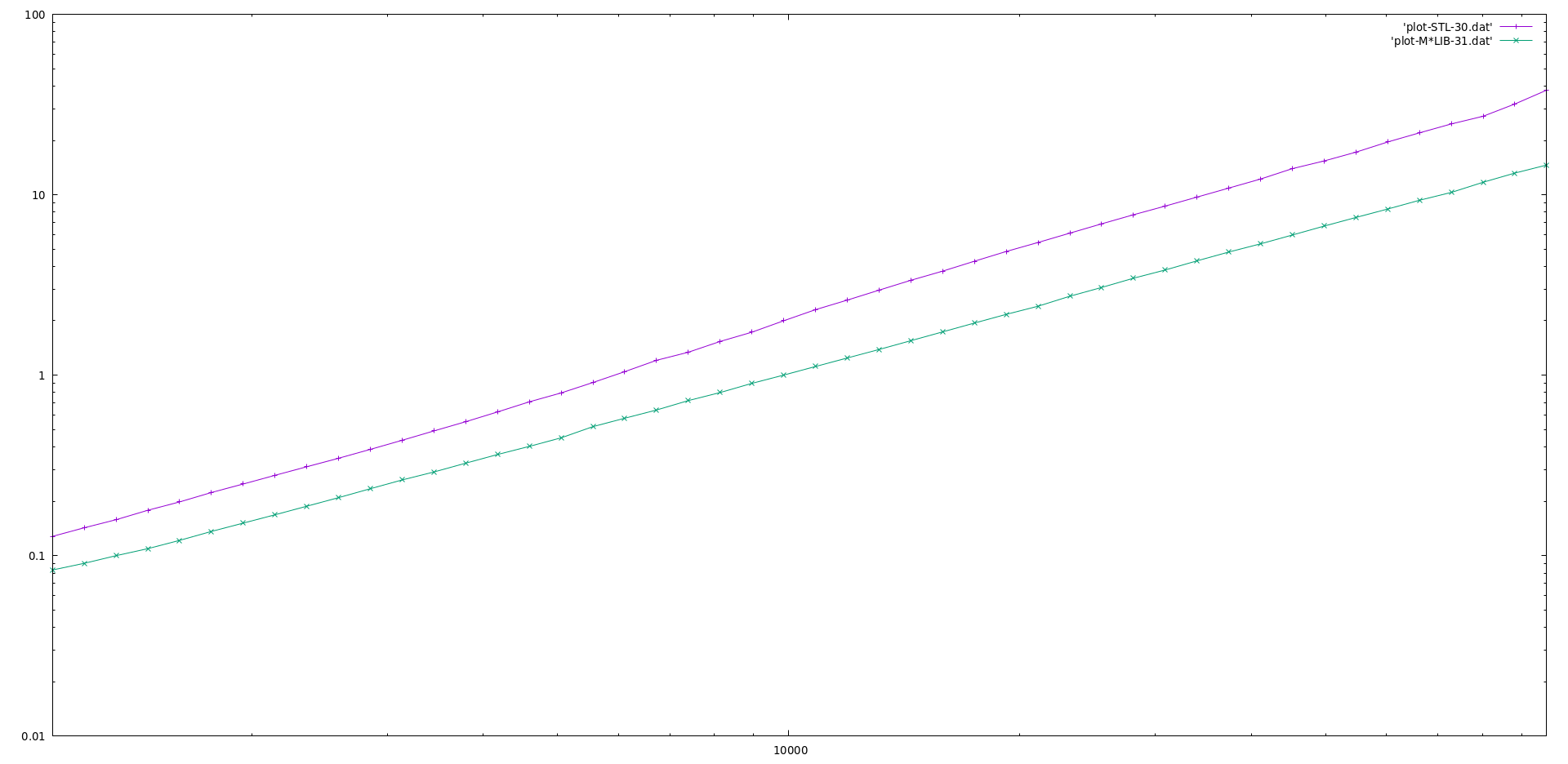
M\*LIB performance is compared to the one of GNU C++ STL (v10.2) in the following graphs.
Each graph is presented first in linear scale and then in logarithmic scale to better realize the differences.
M\*LIB is on par with the STL or even faster.
All used bench codes are available in this [repository](https://github.com/P-p-H-d/c-stl-comparison)
The results for several different libraries are also available [in a separate page](https://github.com/P-p-H-d/mlib/wiki/performance).
#### Singly List
#### Array
#### Unordered Map
#### Ordered Set
## OPLIST
### Definition
An `OPLIST` is a fundamental notion of M\*LIB that hasn't be seen in any other library.
In order to know how to operate on a type, M\*LIB needs additional information
as the compiler doesn't know how to handle properly any type (contrary to C++).
This is done by giving an operator list (or oplist in short) to any macro that
needs to handle the type. As such, an oplist has only meaning within a macro.
Fundamentally, this is the exposed interface of a type:
that is to say the association of the operators defined by the library to the
effective methods provided by the type, including their call interface.
This association is done only with the C preprocessor.
Therefore, an oplist is an associative array of operators to methods
in the following format:
```C
(OPERATOR1(method1), OPERATOR2(method2), ...)
```
It starts with a parenthesis and ends with a parenthesis.
Each association is separated by a comma.
Each association is composed of a predefined operator (as defined below)
a method (in parentheses), and an optional API interface (see below).
In the given example,
the function `method1` is used to handle `OPERATOR1`.
The function `method2` is used to handle `OPERATOR2`, etc.
In case the same operator appears multiple times in the list,
the first apparition of the operator has priority,
and its associated method will be used.
This enables overloading of operators in oplist in case you want to inherit oplists.
The associated method in the oplist is a preprocessor expression
that shall not contain a comma as first level.
An oplist has no real form from the C language point of view. It is just an abstraction
that disappears after the macro expansion step of the preprocessing.
If an oplist remains unprocessed after the C preprocessing, a compiler error will be generated.
### Usage
When you define an instance of a new container for a given type, you give the type `OPLIST`
alongside the type for building the container.
Some functions of the container may not be available in function of the provided interface of the `OPLIST`
(for optional operators).
Of if some mandatory operators are missing, a compiler error is generated.
The generated container will also provide its own oplist, which will depends on all
the oplists used to generate it. This oplist can also be used to generate new containers.
You can therefore use the oplist of the container to chain this new interface
with another container, creating container-of-container.
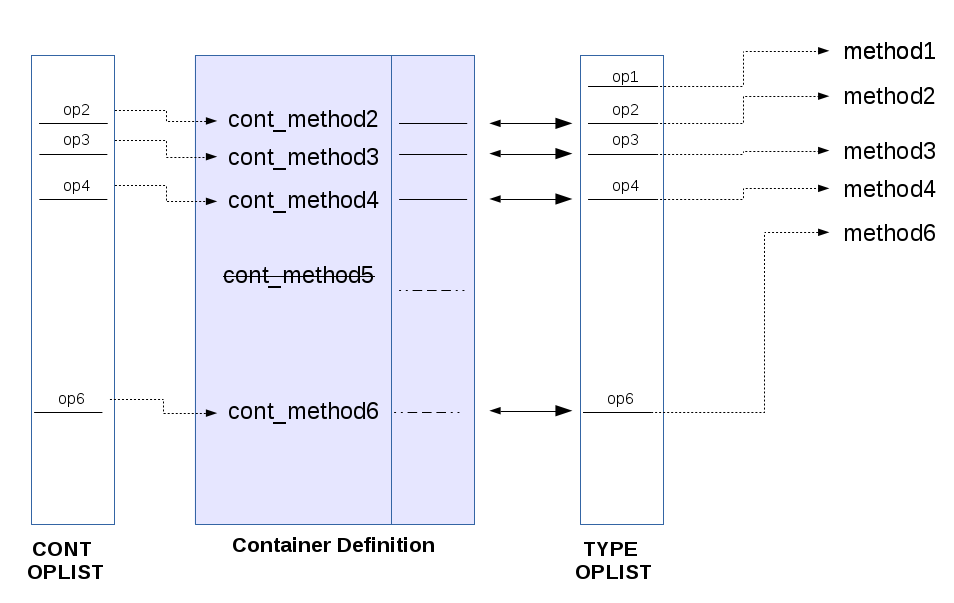
### Operators
> [!NOTE]
> An operator shall fail only on **abnormal error** and if it is marked as potentially raising asynchronous errors. In this case it shall throw exceptions only if exceptions are configured. Otherwise, the program shall be terminated.
>
> In this case, the objects remain initialized and valid but in an unspecified state.
> In case of in constructors, the object is not constructed and the destructor of the object has not to be called.
> [!NOTE]
> If an operator is not marked as raising asynchronous errors, it shall not fail or throw any exceptions in any cases.
Not all operators are needed for an oplist to handle a container.
If some operator is missing, the associated default method of the operator is used if it exists.
The following classic operators are usually expected for an object:
* `INIT(obj)`: initialize the object `obj` into a valid state (constructor). It may raise asynchronous error.
* `INIT_SET(obj, org)`: initialize the object `obj` into the same state as the object `org` (copy constructor). It may raise asynchronous error.
* `SET(obj, org)`: set the initialized object `obj` into the same state as the initialized object org (copy operator). It may raise asynchronous error.
* `CLEAR(obj)`: destroy the initialized object `obj`, releasing any attached memory (destructor).
Other documented operators are:
* `NAME()` --> `prefix`: Return the base name `prefix` used to construct the container.
* `FIELD()` --> `field name`: Return the name of the field used when constructing the container.
* `TYPE()` --> `type`: Return the base type associated to this oplist.
* `SUBTYPE()` --> `type`: Return the type of the element stored in the container (used to iterate over the container).
* `GENTYPE()` --> `type`: Return the type representing TYPE suitable for a _Generic statement.
* `OPLIST()` --> `oplist`: Return the oplist of the type of the elements stored in the container.
* `KEY_TYPE()` --> `key_t`: Return the key type for associative containers.
* `VALUE_TYPE()` --> `value_t`: Return the value type for associative containers.
* `KEY_OPLIST()` --> `oplist`: Return the oplist of the key type for associative containers.
* `VALUE_OPLIST()` --> `oplist`: Return the oplist of the value type for associative containers.
* `NEW(type)` --> `type pointer`: allocate a new object (with suitable alignment and size) and return a pointer to it. The returned object is **not initialized** (a constructor operator shall be called afterward). The default method is `M_MEMORY_ALLOC` (that allocates from the heap). It returns NULL in case of failure.
* `DEL(&obj)`: free the allocated uninitialized object `obj`. The destructor of the pointed object shall be called before freeing the memory by calling this method. The object shall have been allocated by the associated NEW method. The default method is `M_MEMORY_DEL` (that frees to the heap). `obj` shall not be NULL and shall be of the proper type.
* `REALLOC(type, type pointer, number)` --> `type pointer`: reallocate the given array referenced by type pointer (either a NULL pointer or a pointer returned by the associated `REALLOC` method itself) to an array of the number of objects of this type and return a pointer to this new array. Previously objects pointed by the pointer are kept up to the minimum of the new size and old one but may have moved from their original positions (if the array is reallocated otherwhere). New objects are not initialized (a constructor operator shall be called afterward). Freed objects are not cleared (A destructor operator shall be called before). The default is `M_MEMORY_REALLOC` (that allocates from the heap). It returns NULL in case of failure in which case the original array is not modified.
* `FREE(&obj)`: free the allocated uninitialized array object `obj`. The destructor of the pointed objects shall be called before freeing the memory by calling this method. The objects shall have been allocated by the associated REALLOC method. The default is `M_MEMORY_FREE` (that frees to the heap).
* `INC_ALLOC(size_t s)` --> `size_t`: Define the growing policy of an array (or equivalent structure). It returns a new allocation size based on the old allocation size (`s`). Default policy is to get the maximum between `2*s` and 16.
> [!NOTE]
> It doesn't check for overflow: if the returned value is lower
> than the old one, the user shall raise an overflow error (memory error).
* `INIT_MOVE(objd, objc)`: Initialize `objd` to the same state than `objc` by stealing as many resources as possible from `objc`, and then clear `objc` (constructor of `objd` + destructor of `objc`). It is semantically equivalent to calling `INIT_SET(objd,objc)` then `CLEAR(objc)` but is usually way faster. Contrary to the C++ choice of using "conservative move" semantic (you still need to call the destructor of a moved object in C++) M\*LIB implements a "destructive move" semantic (this enables better optimization). By default, all objects are assumed to be **trivially movable** (i.e. using memcpy to move an object is safe). Most C objects (even complex structure) are trivially movable and it is a very nice property to have (enabling better optimization). A notable exception are intrusive objects. If an object is not trivially movable, it shall provide an `INIT_MOVE` method or disable the `INIT_MOVE` method entirely
> [!NOTE]
> Some containers may assume that the objects are always trivially movable (like array).
> Moved objects shall use the same memory allocator.
* `MOVE(objd, objc)`: Set `objd` to the same state than `objc` by stealing as resources as possible from `objc` and then clear `objc` (destructor of `objc`). It is equivalent to calling `SET(objd,objc)` then `CLEAR(objc)` or `CLEAR(objd)` and then `INIT_MOVE(objd, objc)`. See `INIT_MOVE` for details and constraints. TBC if this operator is really needed as calling `CLEAR` then `INIT_MOVE` is what do all known implementation, and is efficient.
* `INIT_WITH(obj, ...)`: Initialize the object `obj` with the given variable set of arguments (constructor). The arguments are variable and can be of different types. It is up to the method of the object to decide how to initialize the object based on this initialization array. This operator is used by the `M_LET` macro to initialize objects with their given values and this operator defines what the `M_LET` macro supports. It may raise asynchronous error.
> [!NOTE]
>In C11, you can use `API_1(M_INIT_WITH_THROUGH_EMPLACE_TYPE)` as method to automatically use the different emplace functions defined in `EMPLACE_TYPE` through a _Generic switch case. The `EMPLACE_TYPE` shall use the LIST format. See [emplace chapter](#Emplace-construction).
>
* `SWAP(objd, objc)`: Swap the states of the object `objc` and the object `objd`.
> [!NOTE]
> The swapped objects shall use the same allocator.
* `RESET(obj)`: Reset the object to its initialized state (Emptying the object if it is a container object).
* `EMPTY_P(obj)` --> `bool`: Test if the container object is empty (true) or not.
* `FULL_P(obj)` --> `bool`: Test if the container object is full (true) or not. Default if not defined is to be not full.
* `GET_SIZE (container)` --> `size_t`: Return the number of elements in the container object.
* `HASH (obj)` --> `size_t`: return a hash of the object (not a secure hash but one that is usable for a hash table). Default is performing a hash of the memory representation of the object. This default implementation is invalid if the object holds pointer to other objects or has spare fields.
* `EQUAL(obj1, obj2)` --> `bool`: Compare the two objects for equality. Return true if both objects are equal, false otherwise. Default is using the C comparison operator. 'obj1' may be an OOR object (Out of Representation) for the Open Addressing dictionary (see `OOR_*` operators): in such cases, it shall return false.
* `CMP(obj1, obj2)` --> `int`: Provide a complete order the objects. return a negative integer if `obj1 < obj2`, 0 if `obj1 = obj2`, a positive integer otherwise. Default is C comparison operator.
> [!NOTE]
> The equivalence between `EQUAL(a, b)` and `CMP(a, b) == 0` is not required, but is usually welcome.
* `ADD(obj1, obj2, obj3)`: Set obj1 to the sum of obj2 and obj3. Default is `+` C operator. It may raise asynchronous error.
* `SUB(obj1, obj2, obj3)`: Set obj1 to the difference of obj2 and obj3. Default is `-` C operator. It may raise asynchronous error.
* `MUL(obj1, obj2, obj3)`: Set obj1 to the product of obj2 and obj3. Default is `*` C operator. It may raise asynchronous error.
* `DIV(obj1, obj2, obj3)`: Set obj1 to the division of obj2 and obj3. Default is `/` C operator. It may raise asynchronous error.
* `GET_KEY (container, key)` --> `&value`: Return a pointer to the value object within the container associated to the key `key` if an object is associated to this key. Otherwise it may return NULL or terminate the program with a logic error (depending on the container). The pointer to the value object remains valid until any modification of the container.
* `SET_KEY (container, key, value)`: Associate the key object `key` to the value object `value` in the given container. It may raise asynchronous error.
* `SAFE_GET_KEY (container, key)` --> `&value`: return a pointer to the value object within the container associated to the key `key` if it exists, or create a new entry in the container and associate it to the key `key` with the default initialization before returning its pointer. The pointer to the object remains valid until any modification of the container. The returned pointer is therefore never NULL. It may raise asynchronous error.
* `ERASE_KEY (container, key)` --> `bool`: Erase the object associated to the key `key` within the container. Return true if successful, false if the key is not found (nothing is done).
* `PUSH(container, obj)`: Push `obj` (of type `SUBTYPE()`) into the container `container`. How and where it is pushed is container dependent. It may raise asynchronous error.
* `POP(&obj, container)`: Pop an object from the container `container` and set it in the initialized object `*obj` (of type `SUBTYPE()`) if the pointer `obj` is not NULL. Which object is popped is container dependent. It may raise asynchronous error.
* `PUSH_MOVE(container, &obj)`: Push and move the object `*obj` (of type `SUBTYPE()`) into the container `container` (`*obj` destructor). How it is pushed is container dependent. `*obj` is cleared afterward and shall not be used anymore. See `INIT_MOVE` for more details and constraints. It may raise asynchronous error.
* `POP_MOVE(&obj, container)`: Pop an object from the container `container` and **init & move** it in the uninitialized object `*obj` (aka constructor). Which object is popped is container dependent. `*obj` shall be uninitialized. See `INIT_MOVE` for more details and constraints.
> [!NOTE]
> When using a `POP` operator (or any derived operator) on a container, this container shall have at least one object.
The iterator operators are:
* `IT_TYPE()` --> `type`: Return the type of the iterator object of this container.
* `IT_FIRST(it_obj, obj)`: Set the iterator it_obj to the first sub-element of the container `obj`. What is the first element is container dependent (it may be front or back, or something else). However, iterating from FIRST to LAST (included) or END (excluded) through `IT_NEXT` ensures going through all elements of the container. If there is no sub-element in the container, it references an end of the container.
* `IT_LAST(it_obj, obj)`: Set the iterator it_obj to the last sub-element of the container `obj`. What is the last element is container dependent (it may be front or back, or something else). However, iterating from LAST to FIRST (included) or END (excluded) through `IT_PREVIOUS` ensures going through all elements of the container. If there is no sub-element in the container, it references an end of the container.
* `IT_END(it_obj, obj)`: Set the iterator it_obj to an end of the container `obj`. Once an iterator has reached an end, it can't use PREVIOUS or NEXT operators. If an iterator has reached an END, it means that there is no object referenced by the iterator (kind of NULL pointer). There can be multiple representation of the end of a container, but all of then share the same properties.
* `IT_SET(it_obj, it_obj2)`: Set the iterator it_obj to reference the same sub-element as it_obj2.
* `IT_END_P(it_obj)` --> `bool`: Return true if the iterator it_obj references an end of the container, false otherwise.
* `IT_LAST_P(it_obj)` --> `bool`: Return true if the iterator it_obj references the last element of the container (just before reaching an end) or has reached an end of the container, false otherwise.
* `IT_EQUAL_P(it_obj, it_obj2)` --> `bool`: Return true if both iterators reference the same element, false otherwise.
* `IT_NEXT(it_obj)`: Move the iterator to the next sub-element or an end of the container if there is no more sub-element. The direction of `IT_NEXT` is container dependent. it_obj shall not be an end of the container.
* `IT_PREVIOUS(it_obj)`: Move the iterator to the previous sub-element or an end of the container if there is no more sub-element. The direction of PREVIOUS is container dependent, but it is the reverse of the `IT_NEXT` operator. it_obj shall not be an end of the container.
* `IT_CREF(it_obj)` --> `&subobj`: Return a constant pointer to the object referenced by the iterator (of type `const SUBTYPE()`). This pointer remains valid until any modifying operation on the container, or until another reference is taken from this container through an iterator (some containers may reduce theses constraints, for example a list). The iterator shall not be an end of the container.
* `IT_REF(it_obj)` --> `&subobj`: Same as `IT_CREF`, but return a modifiable pointer to the object referenced by the iterator.
* `IT_INSERT(obj, it_obj, subobj)`: Insert `subobj` after 'it_obj' in the container `obj` and update it_obj to point to the inserted object (as per `IT_NEXT` semantics). All other iterators of the same container become invalidated. If 'it_obj' is an end of the container, it inserts the object as the first one.
* `IT_REMOVE(obj, it_obj)`: Remove it_obj from the container `obj` (clearing the associated object) and update it_obj to point to the next object (as per `IT_NEXT` semantics). As it modifies the container, all other iterators of the same container become invalidated. it_obj shall not be an end of the container.
* `SPLICE_BACK(objd, objs, it_obj)`: Move the object of the container `objs` referenced by the iterator 'it_obj' to the container `objd`. Where it is moved is container dependent (it is recommended however to be like the `PUSH` method). Afterward 'it_obj' references the next item in 'containerSrc' (as per `IT_NEXT` semantics). 'it_obj' shall not be an end of the container. Both objects shall use the same allocator. It may raise asynchronous error.
* `SPLICE_AT(objd, id_objd, objs, it_objs)`: Move the object referenced by the iterator `it_objs` from the container `objs` just after the object referenced by the iterator `it_objd` in the container `objd`. If `it_objd` references an end of the container, it is inserted as the first item of the container (See operator `IT_INSERT`). Afterward `it_objs` references the next item in the container `objs`, and `it_objd` references the moved item in the container `objd`. `it_objs` shall not be an end of the container. Both objects shall use the same allocator. It may raise asynchronous error.
> [!NOTE]
> An iterator doesn't have a constructor nor destructor methods.
> Therefore, it cannot not allocate any memory.
> [!NOTE]
> A reference to an object through the pointer get from the iterator
> is only valid until another reference is taken from the same
> container (potentially through another iterator),
> or the iterator is modified
> or the container itself is modified.
> This reference is therefore extremely local and should not be stored anywhere else.
> Some containers may lessen this constraint (for example list or RB-Tree).
> [!NOTE]
> If the container is *modified*, all iterators
> of this container become invalid and shall not be used anymore
> except if the modifying operator provided itself an updated iterator.
> Some containers may lessen this constraint.
The I/O operators are:
* `OUT_STR(FILE* f, obj)`: Output `obj` as a custom formatted string into the `FILE*` stream `f`. Format is container dependent, but is human readable.
* `IN_STR(obj, FILE* f)` --> `bool`: Set `obj` to the value associated to the formatted string representation of the object in the `FILE*` stream `f`. Return true in case of success (in that case the stream `f` has been advanced to the end of the parsing of the object), false otherwise (in that case, the stream `f` is in an undetermined position but is likely where the parsing fails). It ensures that an object which is output in a FILE through `OUT_STR`, and an object which is read from this FILE through `IN_STR` are considered as equal. It may raise asynchronous error.
* `GET_STR(string_t str, obj, bool append)`: Set `str` to a formatted string representation of the object `obj`. Append to the string if `append` is true, set it otherwise. This operator requires the module [m-string](#m-string). It may raise asynchronous error.
* `PARSE_STR(obj, const char *str, const char **endp)` --> `bool`: Set `obj` to the value associated to the formatted string representation of the object in the char stream `str`. Return true in case of success (in that case if endp is not NULL, it points to the end of the parsing of the object), false otherwise (in that case, if endp is not NULL, it points to an undetermined position but likely to be where the parsing fails). It ensures that an object which is written in a string through GET_STR, and an object which is read from this string through `PARSE_STR` are considered as equal. It may raise asynchronous error.
* `OUT_SERIAL(m_serial_write_t *serial, obj)` --> `m_serial_return_code_t`: Output `obj` into the configurable serialization stream `serial` (See [m-serial-json.h](#m-serial-json) for details and example) as per the serial object semantics. Return `M_SERIAL_OK_DONE` in case of success, or `M_SERIAL_FAIL` otherwise. It may raise asynchronous error.
* `IN_SERIAL(obj, m_serial_read_t *serial)` --> `m_serial_return_code_t`: Set `obj` to its representation from the configurable serialization stream `serial` (See [m-serial-json.h](#m-serial-json) for details and example) as per the serial object semantics. `M_SERIAL_OK_DONE` in case of success (in that case the stream `serial` has been advanced up to the complete parsing of the object), or `M_SERIAL_FAIL` otherwise (in that case, the stream `serial` is in an undetermined position but usually around the next characters after the first failure). It may raise asynchronous error.
The final operators are:
* `OOR_SET(obj, int_value)`: Some containers want to store some information within the uninitialized objects (for example Open Addressing Hash Table). This method stores the integer value 'int_value' into an uninitialized object `obj`. It shall be able to differentiate between uninitialized object and initialized object (How is type dependent). The way to store this information is fully object dependent. In general, you use out-of-range value for detecting such values. The object remains uninitialized but sets to of out-of-range value (OOR). int_value can be 0 or 1.
* `OOR_EQUAL(obj, int_value)`: This method compares the object `obj` (initialized or uninitialized) to the out-of-range value (OOR) representation associated to 'int_value' and returns true if both objects are equal, false otherwise. See `OOR_SET`.
* `REVERSE(obj)`: Reverse the order of the items in the container `obj`. It may raise asynchronous error.
* `SEPARATOR()` --> `character`: Return the character used to separate items for I/O methods (default is ',') (for internal use only).
* `EXT_ALGO(name, container oplist, object oplist)`: Define additional algorithms functions specialized for the containers (for internal use only).
* `PROPERTIES()` --> `( properties)`: Return internal properties of a container in a recursive oplist format. Use M_GET_PROPERTY to get the property.
* `EMPLACE_TYPE( ... )`: Specify the types usable for "emplacing" the object (initializing the object in-place, constructor). See chapter [Emplace construction](#Emplace-construction). THe referenced initializing functions may raise asynchronous error.
> [!NOTE]
> The operator names listed above shall not be defined as macro.
More operators are expected.
### Properties
Properties can be stored in a sub-oplist format in the `PROPERTIES` operator.
The following properties are defined:
* `LET_AS_INIT_WITH(1)` — Defined if the macro `M_LET` shall always initialize the object with `INIT_WITH` regardless of the given input. The value of the property is 1 (enabled) or 0 (disabled/default).
* `NOCLEAR(1)` — Defined if the object `CLEAR` operator can be omitted (like for basic types or POD data). The value of the property is 1 (enabled) or 0 (disabled/default).
> [!NOTE]
> The properties names listed above shall not be defined as macro.
More properties are expected.
### Example:
Let's take the interface of the MPZ library:
```C
void mpz_init(mpz_t z); // Constructor of the object z
void mpz_init_set(mpz_t z, const mpz_t s); // Copy Constructor of the object z
void mpz_set(mpz_t z, const mpz_t s); // Copy operator of the object z
void mpz_clear(mpz_t z); // Destructor of the object z
```
A basic oplist will be:
```C
(INIT(mpz_init),SET(mpz_set),INIT_SET(mpz_init_set),CLEAR(mpz_clear),TYPE(mpz_t))
```
Much more complete oplist can be built for this type however, enabling much more powerful generation:
See in the [example](https://github.com/P-p-H-d/mlib/blob/master/example/ex11-multi02.c)
### Global namespace
Oplist can be registered globally by defining, for the type `type`, a macro named
`M_OPL_ ## type ()` that expands to the oplist of the type.
Only type without any space in their name can be registered. A typedef of the type
can be used instead, but this typedef shall be used everywhere.
Example:
```C
#define M_OPL_mpz_t() (INIT(mpz_init),SET(mpz_set), \
INIT_SET(mpz_init_set),CLEAR(mpz_clear),TYPE(mpz_t))
```
This can simplify a lot `OPLIST` usage and it is recommended.
Then each times a macro expects an oplist, you can give instead its type.
This make the code much easier to read and understand.
There is one exception however: the macros that are used to build oplist
(like `ARRAY_OPLIST`) don't perform this simplification and the oplist of
the basic type shall be given instead
(This is due to limitation in the C preprocessing).
### API Interface Adaptation
Within an `OPLIST`, you can also specify the needed low-level transformation to perform for calling your method.
This is called API Interface Adaptation: it enables to transform the API requirements of the selected operator
(which is very basic in general) to the API provided by the given method.
Assuming that the method to call is called 'method' and the first argument of the operator is 'output',
which interface is `OPERATOR(output, ...)`
then the following predefined adaptation are available:
| API | Method | Description |
|:------------|:----------------------------------|:----------------------------------------------------------------------------------------|
| **API_0** | `method(output, ...)` | No adaptation |
| **API_1** | `method(oplist, output, ...)` | No adaptation but gives the oplist to the method |
| **API_2** | `method(&output, ...)` | Pass by address the first argument (like with `M_IPTR`) |
| **API_3** | `method(oplist, &output, ...)` | Pass by address the first argument (like with `M_IPTR`) and give the oplist of the type |
| **API_4** | `output = method(...)` | Pass by return value the first argument |
| **API_5** | `output = method(oplist, ...)` | Pass by return value the first argument and give the oplist of the type |
| **API_6** | `method(&output, &...)` | Pass by address the two first arguments |
| **API_7** | `method(oplist, &output, &...)` | Pass by address the two first argument and give the oplist of the type |
The API Adaptation to use shall be embedded in the `OPLIST` definition.
For example:
```C
(INIT(API_0(mpz_init)), SET(API_0(mpz_set)), INIT_SET(API_0(mpz_init_set)), CLEAR(API_0(mpz_clear)))
```
The default adaptation is API_0 (i.e. no adaptation between operator interface and method interface).
If an adaptation gives an oplist to the method, the method shall be implemented as macro.
Let's take the interface of a pseudo library:
```C
typedef struct { ... } obj_t;
obj_t *obj_init(void); // Constructor of the object z
obj_t *obj_init_str(const char *str); // Constructor of the object z
obj_t *obj_clone(const obj_t *s); // Copy Constructor of the object z
void obj_clear(obj_t *z); // Destructor of the object z
```
The library returns a pointer to the object, so we need API_4 for these methods.
There is no method for the `SET` operator available. However, we can use the macro `M_SET_THROUGH_INIT_SET`
to emulate a SET semantics by using a combination of `CLEAR` + `INIT_SET`. This enables to support
the type for array containers in particular. Or we can avoid this definition if we don't need it.
A basic oplist will be:
```C
(INIT(API_4(obj_init)),SET(API_1(M_SET_THROUGH_INIT_SET)),INIT_SET(API_4(obj_clone)),CLEAR(obj_clear),TYPE(obj_t *))
```
### Generic API Interface Adaptation
You can also describe the exact transformation to perform for calling the method:
this is called Generic API Interface Adaptation (or GAIA).
With this, you can add constant values to parameter of the method,
reorder the parameters as you wish, pass then by pointers, or even change the return value.
The API adaptation is also described in the operator mapping with the method name by using the API keyword.
Usage in oplist:
```C
, OPERATOR( API( method, returncode, args...) ) ,
```
Within the `API` keyword,
* method is the pure method name (as like any other oplist)
* `returncode` is the transformation to perform of the return code.
* args are the list of the arguments of the function. It can be:
`returncode` can be
* `NONE` — no transformation,
* `VOID` — cast to void,
* `NEG` — inverse the result,
* `EQ(val)`/`NEQ(val)`/`LT(val`)/`GT(val)`/`LE(val)`/`GE(val)` — compare the return code to the given value
* `ARG[1-9]` — set the associated argument number of the operator to the return code
An argument can be:
* a constant,
* a variable name — probably global,
* `ID( constant or variable)` — if the constant or variable is not a valid token,
* `ARG[1-9]` — the associated argument number of the operator,
* `ARGPTR[1-9]` — the pointer of the associated argument number of the operator,
* `OPLIST` — the oplist
Therefore, it supports at most 9 arguments.
Example:
```C
, EQUAL( API(mpz_cmp, EQ(0), ARG1, ARG2) ) ,
```
This will transform a return value of 0 by the mpz_cmp method into a boolean for the `EQUAL` operator.
Another Example:
```C
, OUT_STR( API(mpz_out_str, VOID, ARG1, 10, ARG2) ) ,
```
This will serialize the mpz_t value in base 10 using the mpz_out_str method, and discarding the return value.
### Disable an operator
An operator `OP` can be defined, omitted or disabled:
* `( OP(f) )`: the function f is the method of the operator OP
* `( OP(API_N(f)) )`: the function f is the method of the operator OP with the API transformation number N,
* `( )`: the operator OP is omitted, and the default global operation for OP is used (if it exists).
* `( OP(0) )`: the operator OP is disabled, and it can never be used.
This can be useful to disable an operator in an inherited oplist.
### Which `OPLIST` to use?
My type is:
* a C Boolean: `M_BOOL_OPLIST` (`M_BASIC_OPLIST` also works partially),
* a C integer or a C float: `M_BASIC_OPLIST` (it can also be omitted),
* a C enumerate: `M_ENUM_OPLIST`,
* a pointer to something (the container do nothing on the pointed object): `M_PTR_OPLIST`,
* a plain structure that can be init/copy/compare with memset/memcpy/memcmp: `M_POD_OPLIST`,
* a plain structure that is passed by reference using [1] and can be init,copy,compare with `memset`, `memcpy`, `memcmp`: `M_A1_OPLIST`,
* a type that offers `name_init`, `name_init_set`, `name_set`, `name_clear` methods: `M_CLASSIC_OPLIST`,
* a const string (`const char *`) that is neither freed nor moved: `M_CSTR_OPLIST`,
* a M\*LIB string_t: `STRING_OPLIST`,
* a M\*LIB container: the `OPLIST` of the used container,
* other things: you need to provide a custom `OPLIST` to your type.
> [!NOTE]
> The precise exported methods of the OPLIST depend on the version
> of the used C language. Typically, in C11 mode, the `M_BASIC_OPLIST`
> exports all needed methods to handle generic input/output of int/floats
> (using `_Generic` keyword) whereas it is not possible in C99 mode.
This explains why JSON import/export is only available in C11 mode
(See below chapter).
Basic usage of oplist is available in the [example](https://github.com/P-p-H-d/mlib/blob/master/example/ex-array00.c)
### Oplist inheritance
Oplist can inherit from another one.
This is useful when you want to customize some specific operators while keeping other ones by default.
For example, internally `M_BOOL_OPLIST` inherits from `M_BASIC_OPLIST`.
A typical example is if you want to provide the `OOR_SET` and `OOR_EQUAL` operators to a type
so that it can be used in an `OA` dict.
To do it, you use the `M_OPEXTEND` macro. It takes as first argument the oplist you want to inherit with,
and then you provide the additional associations between operators to methods you want to add
or override in the inherited oplist. For example:
```C
int my_int_oor_set(char c) { return INT_MIN + c; }
bool my_int_oor_equal(int i1, int i2) { return i1 == i2; }
#define MY_INT_OPLIST \
M_OPEXTEND(M_BASIC_OPLIST, OOR_SET(API_4(my_int_oor_set)), \
OOR_EQUAL(my_int_oor_equal))
```
You can even inherit from another oplist to disable some operators in your new oplist.
For example:
```C
#define MY_INT_OPLIST \
M_OPEXTEND(M_BASIC_OPLIST, HASH(0), CMP(0), EQUAL(0))
```
`MY_INT_OPLIST` is a new oplist that handles integers but has disabled the operators `HASH`, `CMP` and `EQUAL`.
The main interest is to disable the generation of optional methods of a container (since they are only
expanded if the oplist provides some methods).
Usage of inheritance and oplist is available
in the [int example](https://github.com/P-p-H-d/mlib/blob/master/example/ex-dict05.c)
and the [cstr example](https://github.com/P-p-H-d/mlib/blob/master/example/ex-dict06.c)
### Advanced example
Let's take a look at the interface of the `FILE*` interface:
```C
FILE *fopen(const char *filename, const char *mode);
fclose(FILE *f);
```
There is no `INIT` operator (an argument is mandatory), no `INIT_SET` operator.
It is only possible to open a file from a filename.
`FILE*` contains some space, so an alias is needed.
There is an optional mode argument, which is a constant string, and isn't a valid preprocessing token.
An oplist can therefore be:
```C
typedef FILE *m_file_t;
#define M_OPL_m_file_t() (INIT_WITH(API(fopen, ARG1, ARG2, ID("wt"))), \
SET(0),INIT_SET(0),CLEAR(fclose),TYPE(m_file_t))
```
Since there is no `INIT_SET` operator available, pretty much no container can work.
However, you'll be able to use a writing text `FILE*` using a `M_LET`:
```C
M_LET( (f, ("tmp.txt")), m_file_t) {
fprintf(f, "This is a tmp file.");
}
```
This is pretty useless, except if you enable exceptions...
In which case, this enables you to close the file even if an exception is thrown.
## Memory Allocation
### Customization
Memory Allocation functions can be globally set by overriding the following macros before using the definition `_DEF` macros:
* `M_MEMORY_ALLOC (type)` --> `ptr`: return a pointer to a new object of type `type`.
* `M_MEMORY_DEL (ptr)`: free the single object pointed by `ptr`.
* `M_MEMORY_REALLOC (type, ptr, number)` --> `ptr`: return a pointer to an array of 'number' objects of type `type`, reusing the old array pointed by `ptr`. `ptr` can be NULL, in which case the array will be created.
* `M_MEMORY_FREE (ptr)`: free the array of objects pointed by `ptr`.
`ALLOC` and `DEL` operators are supposed to allocate fixed size single element object (no array).
These objects are not expected to grow.
`REALLOC` and `FREE` operators deal with allocated memory for growing objects.
Do not mix pointers between both: a pointer allocated by `ALLOC` (resp. `REALLOC`) is supposed
to be only freed by `DEL` (resp. `FREE`). There are separated 'free' operators to enable
specialization in the allocator (a good allocator can take this hint into account).
`M_MEMORY_ALLOC` and `M_MEMORY_REALLOC` are supposed to return NULL in case of memory allocation failure.
The defaults are `malloc`, `free`, `realloc` and `free`.
You can also override the methods `NEW`, `DEL`, `REALLOC` and `DEL` in the oplist given to a container
so that only the container will use these memory allocation functions instead of the global ones.
### Out-of-memory error
When a memory exhaustion is reached, the global macro `M_MEMORY_FULL` is called
and the function returns immediately after.
The object remains in a valid (if previously valid) and unchanged state in this case.
By default, the macro prints an error message and aborts the program:
handling non-trivial memory errors can be hard,
testing them is even harder but still mandatory to avoid security holes.
So the default behavior is rather conservative.
It can however be overloaded to handle other policy for error handling like:
* throwing an error (which is automatically done by including header [m-try](#m-try) ),
* set a global error and handle it when the function returns [planned, not possible yet],
* other policy.
This function takes the size in bytes of the memory that has been tried to be allocated.
If needed, this macro shall be defined ***prior*** to instantiate the structure.
> [!NOTE]
> A good design should handle a process entire failure (using for examples multiple
> processes for doing the job) so that even if a process stops, it should be recovered.
> See [here](http://joeduffyblog.com/2016/02/07/the-error-model/) for more
> information about why abandonment is good software practice.
In M\*LIB, we classify the kind of errors according to this classification:
* *logical error*: the expectations of the function are not met (null pointer passed as argument, negative argument, invalid object state, ...). In which case, the sanction is abnormal halt of the program, if it is detected, regardless of the configuration of M\*LIB. Normally, debug build will detect such errors.
* *abnormal error*: errors that are unlikely to be expected during the execution of the program (like no more memory). In which case, the sanction is either abnormal halt of the program or throwing an exception.
* *normal error*: errors that can be expected in the execution of the program (all I/O errors like file not found or invalid file format, parsing of invalid user input, no solution found, etc). In which case, the error is reported by the return code of the function or by polling for error (See `ferror`) in the data structure.
## Emplace construction
For M\*LIB, 'emplace' means pushing a new object in the container,
while not giving it a copy of the new object, but the parameters needed
to construct this object.
This is a shortcut to the pattern of creating the object with the arguments,
pushing it in the container, and deleting the created object
(even if using `PUSH_MOVE` could simplify the design).
The containers defining an emplace like method generate the emplace functions
based on the provided `EMPLACE_TYPE` of the oplist. If `EMPLACE_TYPE` doesn't exist or is disabled, no emplace function is generated. Otherwise `EMPLACE_TYPE` identifies
which types can be used to construct the object and which methods to use to construct then:
* `EMPLACE_TYPE( typeA )`, means that the object can be constructed from `typeA` using the method of the `INIT_WITH` operator. An emplace function without suffix will be generated.
* `EMPLACE_TYPE( (typeA, typeB, ...) )`, means that the object can be constructed from the lists of types `typeA`, `typeB`, `...` using the method of the `INIT_WITH` operator. An emplace function without suffix will be generated.
* `EMPLACE_TYPE( LIST( (suffix, function, typeA, typeB, ...)`, (`suffix`, `function`, `typeA`, `typeB`, `...`) means that the object can be constructed from all the provided lists of types `typeA`, `typeB`, `...` using the provided method `function`. The `function` is the method to call to construct the object from the list of types. It supports API transformation if needed. As many emplace function will be generated as there are constructor function. Each generated function will be generated by suffixing it with the provided `suffix` (if suffix is empty, no suffix will be added).
For example, for an `ARRAY` definition named vec, if there is such a definition of `EMPLACE_TYPE(const char *)`, it will generate a function `vec_emplace_back(const char *)`. This function will take a `const char*` parameter, construct the object from it (for example a string_t) then push the result back on the array.
Another example, for an `ARRAY` definition named vec, if there is such a definition of `EMPLACE_TYPE( LIST( (_ui, mpz_init_set_ui, unsigned int), (_si, mpz_init_set_si, int) ) )`, it will generate two functions `vec_emplace_back_ui(unsigned int)` and `vec_emplace_back_si(int)`. These functions will take the (unsigned) int parameter, construct the object from it then push the result back on the array.
If the container is an associative array, the name will be constructed as follows:
```C
name_emplace[_key_keysuffix][_val_valsuffix]
```
where `keysuffix` (resp. `valsuffix`) is the emplace suffix of the key (resp. `value`) oplist.
If you take once again the example of the `FILE*`, a more complete oplist can be:
```C
typedef FILE *m_file_t;
#define M_OPL_m_file_t() (INIT_WITH(API_1(M_INIT_WITH_THROUGH_EMPLACE_TYPE)), \
SET(0),INIT_SET(0),CLEAR(fclose),TYPE(m_file_t), \
EMPLACE_TYPE(LIST((_str, API(fopen, ARG1, ARG2, ID("wb")), char *))))
```
The `INIT_WITH` operator will use the provided init methods in the `EMPLACE_TYPE`.
`EMPLACE_TYPE` defines a `_str` suffix method with a GAIA for `fopen`, and accepts a `char*` as argument.
The GAIA specifies that the output (ARG1) is set as return value,
ARG2 is given as the first argument, and a third constant argument is used.
## ERRORS & COMPILERS
M\*LIB implements internally some controls to reduce the list of errors/warnings generated by a compiler
when it detects some violation in the use of oplist by use of static assertion.
It can also transform some type warnings into proper errors.
In C99 mode, it will produce illegal code with the name of the error as attribute.
In C11 mode, it will use static assert and produce a detailed error message.
The list of errors it can generate:
* `M_LIB_NOT_AN_OPLIST`: something has been given (directly or indirectly) and it doesn't reduce as a proper oplist. You need to give an oplist for this definition.
* `M_LIB_ERROR(ARGUMENT_OF_*_OPLIST_IS_NOT_AN_OPLIST, name, oplist)`: sub error of the previous error one, identifying the root cause. The error is in the oplist construction of the given macro. You need to give an oplist for this oplist construction.
* `M_LIB_MISSING_METHOD`: a required operator doesn't define any method in the given oplist. You need to complete the oplist with the missing method.
* `M_LIB_TYPE_MISMATCH`: the given oplist and the type do not match each other. You need to give the right oplist for this type.
* `M_LIB_NOT_A_BASIC_TYPE`: The oplist `M_BASIC_OPLIST` (directly or indirectly) has been used with the given type, but the given type is not a basic C type (int/float). You need to give the right oplist for this type.
You should focus mainly on the first reported error/warning
even if the link between what the compiler report and what the error is
is not immediate. The error is always in one of the **oplist definition**.
Examples of typical errors:
* lack of inclusion of an header,
* overriding locally operator names by macros (like `NEW`, `DEL`, `INIT`, `OPLIST`, `...`),
* lack of `( )` or double level of `( )` around the oplist,
* an unknown variable (example using `BASIC_OPLIST` instead of `M_BASIC_OPLIST`),
* the name given to the oplist is not the same as the one used to define the methods,
* use of a type instead of an oplist in the `OPLIST` definition,
* a missing sub oplist in the `OPLIST` definition.
A good way to avoid these errors is to register the oplist globally as soon
as you define the container.
In case of difficulties, debugging can be done by generating the preprocessed file
(by usually calling the compiler with the `-E` option instead of `-c`)
and check what's wrong in the preprocessed file:
```shell
cc -std=c99 -E test-file.c |grep -v '^#' > test-file.i
perl -i -e 's/;/;\n/g' test-file.i
cc -std=c99 -c -Wall test-file.i
```
If there is a warning reported by the compiler in the generated code,
then there is definitely an **error** you should fix (except if it reports
shadowed variables), in particular cast evolving pointers.
You should also turn off the macro expansion of the errors reported by
your compiler. There are often completely useless and misleading:
* For GCC, uses `-ftrack-macro-expansion=0`
* For CLANG, uses `-fmacro-backtrace-limit=1`
Due to the unfortunate [weak](https://en.wikipedia.org/wiki/Strong_and_weak_typing#Pointers) nature of the C language for pointers,
you should turn incompatible pointer type warning into an error in your compiler.
For GCC / CLANG, uses `-Werror=incompatible-pointer-types`
For MS Visual C++ compiler , you need the following options:
```shell
/Zc:__cplusplus /Zc:preprocessor /D__STDC_WANT_LIB_EXT1__ /EHsc
```
## External Reference
Many other implementation of generic container libraries in C exist.
For example, a non exhaustive list is:
* [BKTHOMPS/CONTAINERS](https://github.com/bkthomps/Containers)
* [BSD tree.h](http://fxr.watson.org/fxr/source/sys/tree.h)
* [CC](https://github.com/JacksonAllan/CC)
* [CDSA](https://github.com/MichaelJWelsh/cdsa)
* [CELLO](http://libcello.org/)
* [C-Macro-Collections](https://github.com/LeoVen/C-Macro-Collections)
* [COLLECTIONS-C](https://github.com/srdja/Collections-C)
* [CONCURRENCY KIT](https://github.com/concurrencykit/ck)
* CTL [by glouw](https://github.com/glouw/ctl) or [by rurban](https://github.com/rurban/ctl)
* [GDB internal library](https://sourceware.org/git/gitweb.cgi?p=binutils-gdb.git;a=blob;f=gdb/common/vec.h;h=41e41b5b22c9f5ec14711aac35ce4ae6bceab1e7;hb=HEAD)
* [GLIB](https://wiki.gnome.org/Projects/GLib)
* [KLIB](https://github.com/attractivechaos/klib)
* [LIBCHASTE](https://github.com/mgrosvenor/libchaste)
* [LIBCOLLECTION](https://bitbucket.org/manvscode/libcollections)
* [LIBDICT](https://github.com/fmela/libdict)
* [LIBDYNAMIC](https://github.com/fredrikwidlund/libdynamic)
* [LIBLFDS](https://www.liblfds.org/)
* [LIBSRT: Safe Real-Time library for the C programming language](https://github.com/faragon/libsrt)
* [NEDTRIES](https://github.com/ned14/nedtries)
* [POTTERY](https://github.com/ludocode/pottery)
* [QLIBC](http://wolkykim.github.io/qlibc/)
* [SC](https://github.com/tezc/sc)
* [SGLIB](http://sglib.sourceforge.net/)
* [Smart pointer for GNUC](https://github.com/Snaipe/libcsptr)
* [STB stretchy_buffer](https://github.com/nothings/stb)
* [STC - Smart Template Container for C](https://github.com/tylov/STC)
* [TommyDS](https://github.com/amadvance/tommyds)
* [UTHASH](http://troydhanson.github.io/uthash/index.html)
Each can be classified into one of the following concept:
* Each object is handled through a pointer to void (with potential registered callbacks to handle the contained objects for the specialized methods). From a user point of view, this makes the code harder to use (as you don't have any help from the compiler) and type unsafe with a lot of cast (so no formal proof of the code is possible). This also generally generate slower code (even if using link time optimization, this penalty can be reduced). Properly used, it can yet be the most space efficient for the code, but can consume a lot more for the data due to the obligation of using pointers. This is however the easiest to design & code.
* Macros are used to access structures in a generic way (using known fields of a structure — typically size, number, etc.). From a user point of view, this can create subtitle bug in the use of the library (as everything is done through macro expansion in the user defined code) or hard to understand warnings. This can generates fully efficient code. From a library developer point of view, this can be quite limiting in what you can offer.
* Macros detect the type of the argument passed as parameter using _Generics, and calls the associated methods of the switch. The difficulty is how to add pure user types in this generic switch.
* A known structure is put in an intrusive way in the type of all the objects you wan to handle. From a user point of view, he needs to modify its structure and has to perform all the allocation & deallocation code itself (which is good or bad depending on the context). This can generate efficient code (both in speed and size). From a library developer point of view, this is easy to design & code. You need internally a cast to go from a pointer to the known structure to the pointed object (a reverse of offsetof) that is generally type unsafe (except if mixed with the macro generating concept). This is quite limitation in what you can do: you can't move your objects so any container that has to move some objects is out-of-question (which means that you cannot use the most efficient container).
* Header files are included multiple times with different contexts (some different values given to defined macros) in order to generate different code for each type. From a user point of view, this creates a new step before using the container: an instantiating stage that has to be done once per type and per compilation unit (The user is responsible to create only one instance of the container, which can be troublesome if the library doesn't handle proper prefix for its naming convention). The debug of the library is generally easy and can generate fully specialized & efficient code. Incorrectly used, this can generate a lot of code bloat. Properly used, this can even create smaller code than the void pointer variant. The interface used to configure the library can be quite tiresome in case of a lot of specialized methods to configure: it doesn't enable to chain the configuration from a container to another one easily. It also cannot have heavy customization of the code.
* Macros are used to generate context-dependent C code enabling to generate code for different type. This is pretty much like the headers solution but with added flexibility. From a user point of view, this creates a new step before using the container: an instantiating stage that has to be done once per type and per compilation unit (The user is responsible to create only one instance of the container, which can be troublesome if the library doesn't handle proper prefix for its naming convention). This can generate fully specialized & efficient code. Incorrectly used, this can generate a lot of code bloat. Properly used, this can even create smaller code than the void pointer variant. From a library developer point of view, the library is harder to design and to debug: everything being expanded in one line, you can't step in the library (there is however a solution to overcome this limitation by adding another stage to the compilation process). You can however see the generated code by looking at the preprocessed file. You can perform heavy context-dependent customization of the code (transforming the macro preprocessing step into its own language). Properly done, you can also chain the methods from a container to another one easily, enabling expansion of the library. Errors within the macro expansion are generally hard to decipher, but errors in code using containers are easy to read and natural.
M\*LIB category is mainly the last one.
Some macros are also defined to access structure in a generic way, but they are optional.
There are also intrusive containers.
M\*LIB main added value compared to other libraries is its oplist feature
enabling it to chain the containers and/or use complex types in containers:
list of array of dictionary of C++ objects are perfectly supported by M\*LIB.
For the macro-preprocessing part, other libraries and reference also exist. For example:
* [Boost preprocessor](http://www.boost.org/doc/libs/1_63_0/libs/preprocessor/doc/index.html)
* [C99 Lambda](https://github.com/Leushenko/C99-Lambda)
* [C Preprocessor Tricks, Tips and Idioms](https://github.com/pfultz2/Cloak/wiki/C-Preprocessor-tricks,-tips,-and-idioms)
* [CPP MAGIC](http://jhnet.co.uk/articles/cpp_magic)
* [MAP MACRO](https://github.com/swansontec/map-macro)
* [metalang99](https://github.com/Hirrolot/metalang99)
* [OrderPP](https://github.com/rofl0r/order-pp)
* [P99](http://p99.gforge.inria.fr/p99-html/)
* [Zlang](https://github.com/pfultz2/ZLang)
You can also consult [awesome-c-preprocessor](https://github.com/Hirrolot/awesome-c-preprocessor) for a more comprehensive list of libraries.
For the string part, there is the following libraries for example:
* [POTTERY STRING](https://github.com/ludocode/pottery/tree/develop/util/pottery/string)
* [SDS](https://github.com/antirez/sds)
* [STC - C99 Standard Container library](https://github.com/tylov/C99Containers)
* [STR -yet another string library for C language](https://github.com/maxim2266/str)
* [The Better String Library](http://bstring.sourceforge.net/) with a page that lists a lot of other string libraries.
* [VSTR](http://www.and.org/vstr/) with a [page](http://www.and.org/vstr/comparison) that lists a lot of other string libraries.
_________________
## API Documentation
The M\*LIB reference card is available [here](http://htmlpreview.github.io/?https://github.com/P-p-H-d/mlib/blob/master/doc/Container.html).
### Generic methods
The generated containers tries to generate and provide a consistent interface:
their methods would behave the same for all generated containers.
This chapter will explain the generic interface.
In case of difference, it will be explained in the specific container.
In the following description:
* `name` is the prefix used for the container generation,
* `name_t` refers to the type of the container,
* `name_it_t` refers to the iterator type of the container,
* `type_t` refers to the type of the object stored in the container,
* `key_type_t` refers to the type of the key object used to associate an element to,
* `value_type_t` refers to the type of the value object used to associate an element to.
* `name_itref_t` refers to a pair of key and value for associative arrays.
An object shall be initialized (aka constructor) before being used by other methods.
It shall be cleared (aka destructor) after being used and before program termination.
An iterator has not destructor but shall be set before being used.
A container takes as input the
* `name` — it is a mandatory argument that is the prefix used to generate all functions and types,
* `type` — it is a mandatory argument that the basic element of the container,
* `oplist` — it is an optional argument that defines the methods associated to the type. The provided oplist (if provided) shall be the one that is associated to the type, otherwise it won't generate compilable code. If there is no oplist parameter provided, a globally registered oplist associated to the type is used if possible, or the basic oplist for basic C types is used. This oplist will be used to handle internally the objects of the container.
The `type` given to any templating macro can be either
an integer, a float, a boolean, an enum, a named structure, a named union, a pointer to such types,
or a typedef alias of any C type:
in fact, the only constraint is that the preprocessing concatenation between `type` and `variable` into
'type variable' shall be a valid C expression.
Therefore the `type` cannot be a C array or a function pointer
and you shall use a typedef as an intermediary named type for such types.
The output parameters are listed fist, then the input/output parameters and finally the input parameters.
This generic interface is specified as follow:
##### `void name_init(name_t container)`
Initialize the container `container` (aka constructor) to an empty container.
Also called the default constructor of the container.
##### `void name_init_set(name_t container, const name_t ref)`
Initialize the container `container` (aka constructor) and set it to a copy of `ref`.
This method is only created if the `INIT_SET` & `SET` methods are provided.
Also called the copy constructor of the container.
##### `void name_set(name_t container, const name_t ref)`
Set the container `container` to the copy of `ref`.
This method is only created if the `INIT_SET` and `SET` methods are provided.
##### `void name_init_move(name_t container, name_t ref)`
Initialize the container `container` (aka constructor)
by stealing as many resources from `ref` as possible.
After-wise `ref` is cleared and can no longer be used (aka destructor).
##### `void name_move(name_t container, name_t ref)`
Set the container `container` (aka constructor)
by stealing as many resources from `ref` as possible.
After-wise `ref` is cleared and can no longer be used (aka destructor).
##### `void name_clear(name_t container)`
Clear the container `container` (aka destructor),
calling the `CLEAR` method of all the objects of the container and freeing memory.
The object can't be used anymore, except to be reinitialized with a constructor.
##### `void name_reset(name_t container)`
Reset the container clearing and freeing all objects stored in it.
The container becomes empty but remains initialized.
##### `type_t *name_back(const name_t container)`
Return a pointer to the data stored in the back of the container.
This pointer should not be stored in a global variable.
##### `type_t *name_front(const name_t container)`
Return a pointer to the data stored in the front of the container.
This pointer should not be stored in a global variable.
##### `void name_push(name_t container, const type_t value)`
##### `void name_push_back(name_t container, const type_t value)`
##### `void name_push_front(name_t container, const type_t value)`
Push a new element in the container `container` as a copy of the object `value`.
This method is created only if the `INIT_SET` operator is provided.
The `_back` suffixed method will push it in the back of the container.
The `_front` suffixed method will push it in the front of the container.
##### `type_t *name_push_raw(name_t container)`
##### `type_t *name_push_back_raw(name_t container)`
##### `type_t *name_push_front_raw(name_t container)`
Push a new element in the container `container`
without initializing it and returns a pointer to the **non-initialized** data.
The first thing to do after calling this function shall be to initialize the data
using the proper constructor of the object of type `type_t`.
This enables using more specialized constructor than the generic copy one.
The user should use other `_push` function if possible rather than this one
as it is low level and error prone.
This pointer should not be stored in a global variable.
The `_back` suffixed method will push it in the back of the container.
The `_front` suffixed method will push it in the front of the container.
##### `type_t *name_push_new(name_t container)`
##### `type_t *name_push_back_new(name_t container)`
##### `type_t *name_push_front_new(name_t container)`
Push a new element in the container `container`
and initialize it with the default constructor associated to the type `type_t`.
Return a pointer to the initialized object.
This pointer should not be stored in a global variable.
This method is only created if the `INIT` method is provided.
The `_back` suffixed method will push it in the back of the container.
The `_front` suffixed method will push it in the front of the container.
##### `void name_push_move(name_t container, type_t *value)`
##### `void name_push_back_move(name_t container, type_t *value)`
##### `void name_push_front_move(name_t container, type_t *value)`
Push a new element in the container `container`
as a move from the object `*value`:
it will therefore steal as much resources from `*value` as possible.
Afterward `*value` is cleared and cannot longer be used (aka. destructor).
The `_back` suffixed method will push it in the back of the container.
The `_front` suffixed method will push it in the front of the container.
##### `void name_emplace[suffix](name_t container, args...)`
##### `void name_emplace_back[suffix](name_t container, args...)`
##### `void name_emplace_front[suffix](name_t container, args...)`
Push a new element in the container `container`
by initializing it with the provided arguments.
The provided arguments shall therefore match one of the constructor provided
by the `EMPLACE_TYPE` operator.
There is one generated method per suffix defined in the `EMPLACE_TYPE` operator,
and the `suffix` in the generated method name corresponds to the suffix defined
in the `EMPLACE_TYPE` operator (it can be empty).
This method is created only if the `EMPLACE_TYPE` operator is provided.
See [emplace](#Emplace-construction) chapter for more details.
The `_back` suffixed method will push it in the back of the container.
The `_front` suffixed method will push it in the front of the container.
##### `void name_pop(type_t *data, name_t container)`
##### `void name_pop_back(type_t *data, name_t container)`
##### `void name_pop_front(type_t *data, name_t container)`
Pop a element from the container `container`;
and set `*data` to this value if data is not the NULL pointer,
otherwise it only pops the data.
This method is created if the `SET` or `INIT_MOVE` operator is provided.
The `_back` suffixed method will pop it from the back of the container.
The `_front` suffixed method will pop it from the front of the container.
##### `void name_pop_move(type_t *data, name_t container)`
##### `void name_pop_move_back(type_t *data, name_t container)`
##### `void name_pop_move_front(type_t *data, name_t container)`
Pop a element from the container `container`
and initialize and set `*data` to this value (aka. constructor)
by stealing as much resources from the container as possible.
data shall not be a NULL pointer.
The `_back` suffixed method will pop it from the back of the container.
The `_front` suffixed method will pop it from the front of the container.
##### `bool name_empty_p(const name_t container)`
Return true if the container is empty, false otherwise.
##### `void name_swap(name_t container1, name_t container2)`
Swap the container `container1` and `container2`.
##### `void name_set_at(name_t container, size_t key, type_t value)`
##### `void name_set_at(name_t container, key_type_t key, value_type_t value)` [for associative array]
Set the element associated to `key` of the container `container` to `value`.
If the container is sequence-like (like array), the key is an integer.
The selected element is the `key`-th element of the container,
The index `key` shall be within the size of the container.
This method is created if the `INIT_SET` operator is provided.
If the container is associative-array like,
the selected element is the `value` object associated to the `key` object in the container.
It is created if it doesn't exist, overwritten otherwise.
##### `void name_emplace_key[keysuffix](name_t container, keyargs..., value_type_t value)` [for associative array]
##### `void name_emplace_val[valsuffix](name_t container, key_type_t key, valargs...)` [for associative array]
##### `void name_emplace_key[keysuffix]_val[valsuffix](name_t container, keyargs..., valargs...)` [for associative array]
Set the element associated to `key` of the container `container` to `value`.
`key` (resp. value) is constructed from the provided args `keyargs` (resp. `valargs`) if not provided.
`keyargs` (resp. `valargs`) shall therefore match one of the constructor provided
by the `EMPLACE_TYPE` operator of the key (resp. the value).
There is:
* one generated method per suffix defined in the `EMPLACE_TYPE` operator of the key,
* one generated method per suffix defined in the `EMPLACE_TYPE` operator of the value,
* one generated method per pair of suffix defined in the `EMPLACE_TYPE` operators of the key and value,
The `suffix` in the generated method name corresponds to the suffix defined in
in the `EMPLACE_TYPE` operator (it can be empty).
This method is created only if one `EMPLACE_TYPE` operator is provided.
See [emplace](#Emplace-construction) chapter for more details.
##### `type_t *name_get(const name_t container, size_t key)` [for sequence-like]
##### `const type_t *name_cget(const name_t container, size_t key)` [for sequence-like]
##### `type_t *name_get(const name_t container, const type_t key)` [for set-like]
##### `const type_t *name_cget(const name_t container, const type_t key)` [for set-like]
##### `value_type_t *name_get(const name_t container, const key_type_t key)` [for associative array]
##### `const value_type_t *name_cget(const name_t container, const key_type_t key)` [for associative array]
Return a modifiable (resp. constant) pointer to
the element associated to `key` in the container.
If the container is sequence-like, the key is an integer.
The selected element is the `key`-th element of the container,
the front being at the index 0, the last at the index (`size-1`).
The index `key` shall be within the size of the container.
Therefore, it will never return NULL in this case.
If the container is associative array like,
the selected element is the `value` object associated to the `key` object in the container.
If the key is not found, it returns NULL.
If the container is set-like,
the selected element is the `value` object which is equal to the `key` object in the container.
If the key is not found, it returns NULL.
This pointer remains valid until the container is modified by another method.
This pointer should not be stored in a global variable.
##### `type_t *name_get_emplace[suffix](const name_t container, args...)` [for set-like]
##### `value_type_t * name_get_emplace[suffix](name_t container, args...)` [for associative array]
Return a modifiable (resp. constant) pointer to
the element associated to the key constructed from `args` in the container.
The selected element is the `value` object associated to the `key` object in the container
for an associative array, or the element itself for a set.
If the key is not found, it returns NULL.
This pointer remains valid until the container is modified by another method.
This pointer should not be stored in a global variable.
##### `type_t *name_safe_get(name_t container, size_t key)` [for sequence]
##### `type_t *name_safe_get(name_t container, const type_t key)` [for set]
##### `value_type_t *name_safe_get(name_t container, const key_type_t key)` [for associative array]
Return a modifiable pointer to
the element associated to `key` in the container,
creating a new element if it doesn't exist (ensuring therefore a safe `get` operation).
If the container is sequence-like, key_type_t is an alias for size_t and key an integer,
the selected element is the `key`-th element of the container.
If the element doesn't exist, the container size will be increased
if needed (creating new elements with the `INIT` operator),
which might increase the container to much in some cases.
The returned pointer cannot be NULL.
This method is only created if the `INIT` method is provided.
This pointer remains valid until the array is modified by another method.
This pointer should not be stored in a global variable.
##### `bool name_erase(name_t container, const size_t key)`
##### `bool name_erase(name_t container, const type_t key)` [for set]
##### `bool name_erase(name_t container, const key_type_t key)` [for associative array]
Remove the element referenced by the key `key` in the container `container`.
Do nothing if `key` is no present in the container.
Return true if the key was present and erased, false otherwise.
##### `size_t name_size(const name_t container)`
Return the number elements of the container (its size).
Return 0 if there is no element.
##### `size_t name_capacity(const name_t container)`
Return the capacity of the container, i.e. the maximum number of elements
supported by the container before a reserve operation is needed to accommodate
new elements.
##### `void name_resize(name_t container, size_t size)`
Resize the container `container` to the size `size`,
increasing or decreasing the size of the container
by initializing new elements or clearing existing ones.
This method is only created if the INIT method is provided.
##### `void name_reserve(name_t container, size_t capacity)`
Extend or reduce the capacity of the `container` to a rounded value based on `capacity`.
If the given capacity is below the current size of the container,
the capacity is set to a rounded value based on the size of the container.
Therefore a capacity of 0 is used to perform a shrink-to-fit operation on the container,
i.e. reducing the container usage to the minimum possible allocation.
##### `void name_it(name_it_t it, const name_t container)`
Set the iterator `it` to the first element of the container `container`.
There is no destructor associated to this initialization.
##### `void name_it_set(name_it_t it, const name_it_t ref)`
Set the iterator `it` to the iterator `ref`.
There is no destructor associated to this initialization.
##### `void name_it_end(name_it_t it, const name_t container)`
Set the iterator `it` to a non valid element of the container.
There is no destructor associated to this initialization.
##### `bool name_end_p(const name_it_t it)`
Return true if the iterator doesn't reference a valid element anymore.
##### `bool name_last_p(const name_it_t it)`
Return true if the iterator references the last element of the container
or if the iterator doesn't reference a valid element anymore.
##### `bool name_it_equal_p(const name_it_t it1, const name_it_t it2)`
Return true if the iterator `it1` references the same element than the iterator `it2`.
##### `void name_next(name_it_t it)`
Move the iterator to the next element of the container.
##### `void name_previous(name_it_t it)`
Move the iterator `it` to the previous element of the container.
##### `type_t *name_ref(name_it_t it)`
##### `const type_t *name_cref(const name_it_t it)`
##### `name_itref_t *name_ref(name_it_t it)` [for associative array]
##### `const name_itref_t *name_cref(name_it_t it)` [for associative array]
Return a modifiable (resp. constant) pointer to the element pointed by the iterator.
For associative-array like container, this element is the pair composed of
the key (`key` field) and the associated value (`value` field);
otherwise this element is simply the basic type of the container (`type_t`).
This pointer should not be stored in a global variable.
This pointer remains valid until the container is modified by another method.
##### `void name_insert(name_t container, const name_it_t it, const type_t x)`
Insert the object `x` after the position referenced by the iterator `it` in the container `container`
or if the iterator `it` doesn't reference anymore to a valid element of the container,
it is added as the first element of the container.
`it` shall be an iterator of the container `container`.
##### `void name_remove(name_t container, name_it_t it)`
Remove the element referenced by the iterator `it` from the container `container`.
`it` shall be an iterator of the container `container`.
Afterwards, `it` references the next element of the container if it exists,
or not a valid element otherwise.
##### `bool name_equal_p(const name_t container1, const name_t container2)`
Return true if both containers `container1` and `container2` are considered equal.
This method is only created if the `EQUAL` method is provided.
##### `size_t name_hash(const name_t container)`
Return a fast hash value of the container `container`,
suitable to be used by a dictionary.
This method is only created if the `HASH` method is provided.
##### `void name_get_str(string_t str, const name_t container, bool append)`
Set `str` to the formatted string representation of the container `container` if `append` is false
or append `str` with this representation if `append` is true.
This method is only created if the `GET_STR` method is provided.
##### `bool name_parse_str(name_t container, const char str[], const char **endp)`
Parse the formatted string `str`,
that is assumed to be a string representation of a container,
and set `container` to this representation.
It returns true if success, false otherwise.
If `endp` is not NULL, it sets `*endp` to the pointer of the first character not
decoded by the function (or where the parsing fails).
This method is only created if the `PARSE_STR` & `INIT` methods are provided.
It is ensured that the container gets from parsing a formatted string representation
gets from `name_get_str` and the original container are equal.
##### `void name_out_str(FILE *file, const name_t container)`
Generate a formatted string representation of the container `container`
and outputs it into the file `FILE*`.
The file `FILE*` shall be opened in write text mode and without error.
This method is only created if the `OUT_STR` methods is provided.
##### `bool name_in_str(name_t container, FILE *file)`
Read from the file `FILE*` a formatted string representation of a container
and set `container` to this representation.
It returns true if success, false otherwise.
This method is only created if the `IN_STR` & `INIT` methods are provided.
It is ensured that the container gets from parsing a formatted string representation
gets from name_out_str and the original container are equal.
##### `m_serial_return_code_t name_out_serial(m_serial_write_t serial, const name_t container)`
Output the container `container` into the serializing object `serial`.
How and where it is output depends on the serializing object.
It returns `M_SERIAL_OK_DONE` in case of success,
or `M_SERIAL_FAILURE` in case of failure.
In case of failure, the serializing object is in an unspecified but valid state.
This method is only created if the `OUT_SERIAL` methods is provided.
##### `m_serial_return_code_t name_in_serial(name_t container, m_serial_read_t serial)`
Read from the serializing object `serial` a representation of a container
and set `container` to this representation.
It returns `M_SERIAL_OK_