https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI
Easily train a good VC model with voice data <= 10 mins!
https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI
audio-analysis change conversational-ai conversion converter retrieval-model retrieve-data rvc so-vits-svc sovits vc vits voice voice-conversion voice-converter voiceconversion
Last synced: about 1 year ago
JSON representation
Easily train a good VC model with voice data <= 10 mins!
- Host: GitHub
- URL: https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI
- Owner: RVC-Project
- License: mit
- Created: 2023-03-27T09:59:10.000Z (about 3 years ago)
- Default Branch: main
- Last Pushed: 2024-11-24T15:09:44.000Z (over 1 year ago)
- Last Synced: 2025-03-30T00:02:18.206Z (about 1 year ago)
- Topics: audio-analysis, change, conversational-ai, conversion, converter, retrieval-model, retrieve-data, rvc, so-vits-svc, sovits, vc, vits, voice, voice-conversion, voice-converter, voiceconversion
- Language: Python
- Homepage:
- Size: 13.9 MB
- Stars: 28,260
- Watchers: 191
- Forks: 3,996
- Open Issues: 541
-
Metadata Files:
- Readme: README.md
- Contributing: CONTRIBUTING.md
- License: LICENSE
Awesome Lists containing this project
- ai-catalog - RVC GUI
- StarryDivineSky - RVC-Project/Retrieval-based-Voice-Conversion-WebUI
- awesome-tts-stt - RVC - based voice conversion with GUI | MIT | (Voice Cloning & Conversion / Voice Conversion (STS))
- AiTreasureBox - RVC-Project/Retrieval-based-Voice-Conversion-WebUI - 11-03_32728_0](https://img.shields.io/github/stars/RVC-Project/Retrieval-based-Voice-Conversion-WebUI.svg)|Voice data <= 10 mins can also be used to train a good VC model!| (Repos)
- awesome-ai-papers - [Retrieval-based-Voice-Conversion-WebUI - ChatTTS](https://github.com/panyanyany/Awesome-ChatTTS)\]\[[VoiceHub](https://github.com/kadirnar/VoiceHub)\] (Multimodal / 1. Audio)
- awesome-local-ai - RVC WebUI
README
Retrieval-based-Voice-Conversion-WebUI
一个基于VITS的简单易用的变声框架
[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)

[](https://colab.research.google.com/github/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/Retrieval_based_Voice_Conversion_WebUI.ipynb)
[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/LICENSE)
[](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)
[](https://discord.gg/HcsmBBGyVk)
[**更新日志**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_CN.md) | [**常见问题解答**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98%E8%A7%A3%E7%AD%94) | [**AutoDL·5毛钱训练AI歌手**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B) | [**对照实验记录**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%AF%B9%E7%85%A7%E5%AE%9E%E9%AA%8C%C2%B7%E5%AE%9E%E9%AA%8C%E8%AE%B0%E5%BD%95)) | [**在线演示**](https://modelscope.cn/studios/FlowerCry/RVCv2demo)
[**English**](./docs/en/README.en.md) | [**中文简体**](./README.md) | [**日本語**](./docs/jp/README.ja.md) | [**한국어**](./docs/kr/README.ko.md) ([**韓國語**](./docs/kr/README.ko.han.md)) | [**Français**](./docs/fr/README.fr.md) | [**Türkçe**](./docs/tr/README.tr.md) | [**Português**](./docs/pt/README.pt.md)
> 底模使用接近50小时的开源高质量VCTK训练集训练,无版权方面的顾虑,请大家放心使用
> 请期待RVCv3的底模,参数更大,数据更大,效果更好,基本持平的推理速度,需要训练数据量更少。
训练推理界面
实时变声界面
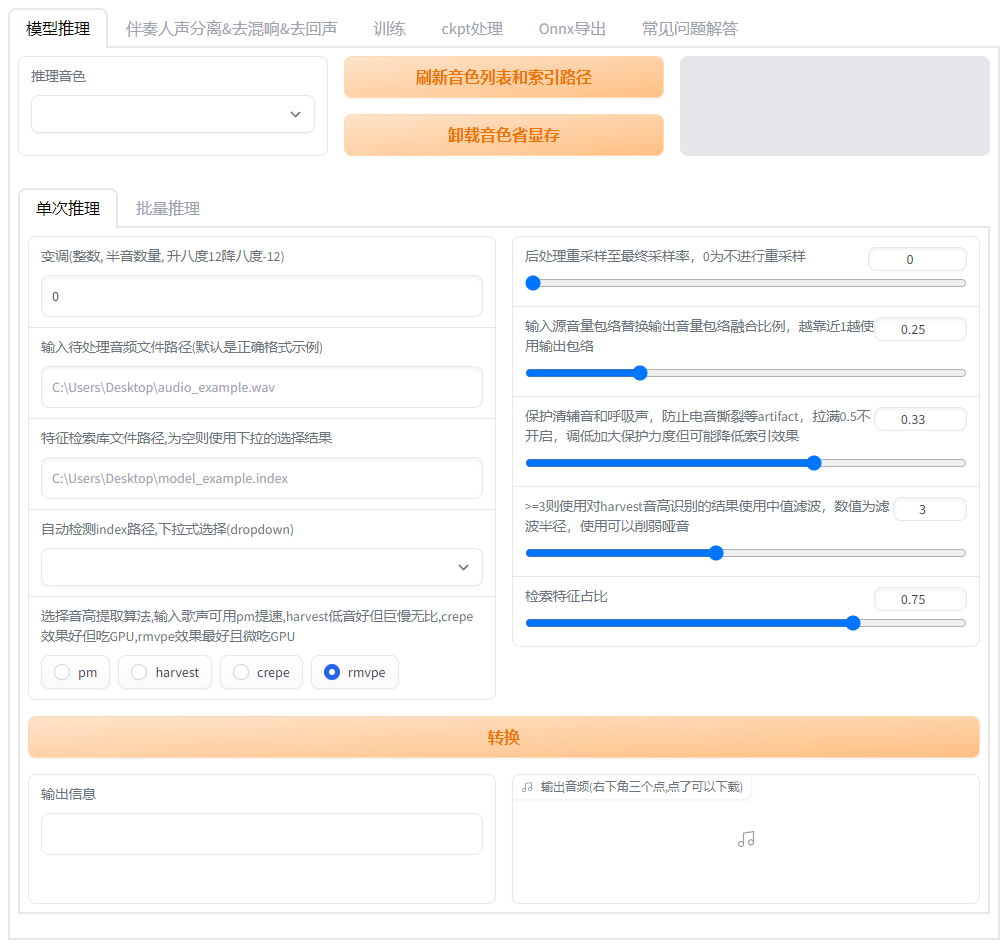

go-web.bat
go-realtime-gui.bat
可以自由选择想要执行的操作。
我们已经实现端到端170ms延迟。如使用ASIO输入输出设备,已能实现端到端90ms延迟,但非常依赖硬件驱动支持。
## 简介
本仓库具有以下特点
+ 使用top1检索替换输入源特征为训练集特征来杜绝音色泄漏
+ 即便在相对较差的显卡上也能快速训练
+ 使用少量数据进行训练也能得到较好结果(推荐至少收集10分钟低底噪语音数据)
+ 可以通过模型融合来改变音色(借助ckpt处理选项卡中的ckpt-merge)
+ 简单易用的网页界面
+ 可调用UVR5模型来快速分离人声和伴奏
+ 使用最先进的[人声音高提取算法InterSpeech2023-RMVPE](#参考项目)根绝哑音问题。效果最好(显著地)但比crepe_full更快、资源占用更小
+ A卡I卡加速支持
点此查看我们的[演示视频](https://www.bilibili.com/video/BV1pm4y1z7Gm/) !
## 环境配置
以下指令需在 Python 版本大于3.8的环境中执行。
### Windows/Linux/MacOS等平台通用方法
下列方法任选其一。
#### 1. 通过 pip 安装依赖
1. 安装Pytorch及其核心依赖,若已安装则跳过。参考自: https://pytorch.org/get-started/locally/
```bash
pip install torch torchvision torchaudio
```
2. 如果是 win 系统 + Nvidia Ampere 架构(RTX30xx),根据 #21 的经验,需要指定 pytorch 对应的 cuda 版本
```bash
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
```
3. 根据自己的显卡安装对应依赖
- N卡
```bash
pip install -r requirements.txt
```
- A卡/I卡
```bash
pip install -r requirements-dml.txt
```
- A卡ROCM(Linux)
```bash
pip install -r requirements-amd.txt
```
- I卡IPEX(Linux)
```bash
pip install -r requirements-ipex.txt
```
#### 2. 通过 poetry 来安装依赖
安装 Poetry 依赖管理工具,若已安装则跳过。参考自: https://python-poetry.org/docs/#installation
```bash
curl -sSL https://install.python-poetry.org | python3 -
```
通过 Poetry 安装依赖时,python 建议使用 3.7-3.10 版本,其余版本在安装 llvmlite==0.39.0 时会出现冲突
```bash
poetry init -n
poetry env use "path to your python.exe"
poetry run pip install -r requirments.txt
```
### MacOS
可以通过 `run.sh` 来安装依赖
```bash
sh ./run.sh
```
## 其他预模型准备
RVC需要其他一些预模型来推理和训练。
你可以从我们的[Hugging Face space](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)下载到这些模型。
### 1. 下载 assets
以下是一份清单,包括了所有RVC所需的预模型和其他文件的名称。你可以在`tools`文件夹找到下载它们的脚本。
- ./assets/hubert/hubert_base.pt
- ./assets/pretrained
- ./assets/uvr5_weights
想使用v2版本模型的话,需要额外下载
- ./assets/pretrained_v2
### 2. 安装 ffmpeg
若ffmpeg和ffprobe已安装则跳过。
#### Ubuntu/Debian 用户
```bash
sudo apt install ffmpeg
```
#### MacOS 用户
```bash
brew install ffmpeg
```
#### Windows 用户
下载后放置在根目录。
- 下载[ffmpeg.exe](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffmpeg.exe)
- 下载[ffprobe.exe](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffprobe.exe)
### 3. 下载 rmvpe 人声音高提取算法所需文件
如果你想使用最新的RMVPE人声音高提取算法,则你需要下载音高提取模型参数并放置于RVC根目录。
- 下载[rmvpe.pt](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt)
#### 下载 rmvpe 的 dml 环境(可选, A卡/I卡用户)
- 下载[rmvpe.onnx](https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.onnx)
### 4. AMD显卡Rocm(可选, 仅Linux)
如果你想基于AMD的Rocm技术在Linux系统上运行RVC,请先在[这里](https://rocm.docs.amd.com/en/latest/deploy/linux/os-native/install.html)安装所需的驱动。
若你使用的是Arch Linux,可以使用pacman来安装所需驱动:
````
pacman -S rocm-hip-sdk rocm-opencl-sdk
````
对于某些型号的显卡,你可能需要额外配置如下的环境变量(如:RX6700XT):
````
export ROCM_PATH=/opt/rocm
export HSA_OVERRIDE_GFX_VERSION=10.3.0
````
同时确保你的当前用户处于`render`与`video`用户组内:
````
sudo usermod -aG render $USERNAME
sudo usermod -aG video $USERNAME
````
## 开始使用
### 直接启动
使用以下指令来启动 WebUI
```bash
python infer-web.py
```
若先前使用 Poetry 安装依赖,则可以通过以下方式启动WebUI
```bash
poetry run python infer-web.py
```
### 使用整合包
下载并解压`RVC-beta.7z`
#### Windows 用户
双击`go-web.bat`
#### MacOS 用户
```bash
sh ./run.sh
```
### 对于需要使用IPEX技术的I卡用户(仅Linux)
```bash
source /opt/intel/oneapi/setvars.sh
```
## 参考项目
+ [ContentVec](https://github.com/auspicious3000/contentvec/)
+ [VITS](https://github.com/jaywalnut310/vits)
+ [HIFIGAN](https://github.com/jik876/hifi-gan)
+ [Gradio](https://github.com/gradio-app/gradio)
+ [FFmpeg](https://github.com/FFmpeg/FFmpeg)
+ [Ultimate Vocal Remover](https://github.com/Anjok07/ultimatevocalremovergui)
+ [audio-slicer](https://github.com/openvpi/audio-slicer)
+ [Vocal pitch extraction:RMVPE](https://github.com/Dream-High/RMVPE)
+ The pretrained model is trained and tested by [yxlllc](https://github.com/yxlllc/RMVPE) and [RVC-Boss](https://github.com/RVC-Boss).
## 感谢所有贡献者作出的努力
