https://github.com/Shotray/DataWarehouse
https://github.com/Shotray/DataWarehouse
Last synced: 9 months ago
JSON representation
- Host: GitHub
- URL: https://github.com/Shotray/DataWarehouse
- Owner: Shotray
- Created: 2021-11-23T11:26:00.000Z (about 4 years ago)
- Default Branch: main
- Last Pushed: 2022-10-22T12:14:38.000Z (about 3 years ago)
- Last Synced: 2024-11-10T06:34:32.163Z (about 1 year ago)
- Language: Python
- Size: 17.2 MB
- Stars: 0
- Watchers: 1
- Forks: 2
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
- awesome-tjsse-project - Shotray/DataWarehouse
README
# DataWarehouse
# 1 数据爬取
本项目最初使用的数据集为Amazon电影和TV评论数据中的Movies and TV 5-core (3,410,019 reviews),该数据共有314万条评论数据。
本过程中,我们针对评论进行数据预处理和数据爬取。
## 1.1 数据预处理
在正式进行爬取过程之前,我们需要先明确要爬取的内容是什么。通过分析Amazon电影网页,我们发现不同电影数据拥有一个独特的asin信息,并且该电影数据对应的网址如下:
www.amazon.com/-/zh/dp/ + asin编号
因此,我们只需要从评论数据集中提取出不同电影的asin信息即可。为了完成这一需求,通过读取评论数据集,并取json文件中asin信息,并存入一个集合中。最终将该集合输出到.csv文件中,即可完成该需求:
```python
asinSet=set()
with open(fileName, 'r', encoding='utf-8') as f:
while True:
line = f.readline()
if not line:
break
s = json.loads(line)
asinSet.add(s['asin'])
```
本操作中获取了 条电影asin信息。 ## TODO
## 1.2 数据爬取
在提取完电影的asin信息后,我们便可以开始对每一个asin进行数据爬取。常见的数据爬取有两种策略:
1. 爬虫框架爬取(如requests或scrapy)
2. 模拟人的行为进行爬取(selenium库)
在此,考虑到Amazon的反爬机制相对比较完善,我们选择了策略2进行数据爬取。
在采用selenium库进行数据爬取的过程中,我们主要解决了访问网页和输入验证码两种行为。
### 1.2.1 访问网页
在使用selenium的时候,我们需要模拟人来输入网址,访问该网页。
该过程比较简单,只需要从前面获取的.csv文件中读取asin信息,接着使用Chrome Driver对该网址进行访问即可。为了减少对于信息提取遗漏的情况,我们采取了先获取页面全部元素,将其保存为txt,以便后续离线处理的方案。
此外,为了防止较快的爬取速度让Amazon封禁本ip地址,我们每爬取一个网站,会随机休息一段时间。
本部分代码如下所示:
```python
def getNextPage(self):
self.wait = WebDriverWait(self.driver, 0.8, 0.5)
# 访问该网站
self.driver.get(self.nextUrl)
time.sleep(random.random())
# 标记为已提取
self.asinSet.iloc[self.index, 1] = True
self.total = self.driver.page_source
try:
title = self.driver.find_element_by_xpath(
'//span[@id="productTitle"]')
print(title.text.replace('\n', ''))
with open(self.saveFileUrl+self.nextUrl[-10:]+'.txt', 'w', encoding='utf-8') as fp:
fp.write(self.total)
except:
# 处理验证码
self.handleCaptcha()
```
### 1.2.2 验证码处理
如下所示,是在Amazon进行爬虫时会遇到问题。当一段时间内操作过于频繁,会被要求输入验证码,以证明是本人。
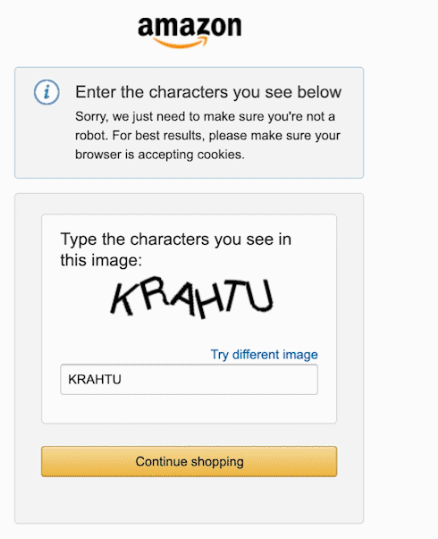
为了解决该问题,通常有两种方法:
1. 尝试更换ip地址和伪装头等;
2. 尝试输入验证码, 完成校验。
考虑到我们在爬虫过程中使用的就是selenium,能够很好的做出人的行为,因此在此我们选择了策略2。
通过分析页面结构我们发现,验证码图片位于一个img标签下,图片地址在src中,因此我们需要先将图片提取出来:
```python
src = soup.find(class_="a-row a-text- center").findChild(name="img").attrs["src"]
```
在将图片提取出来之后,下一个要解决的问题就是如何将图片中的字符识别出来。
针对于这一问题,我们在github上发现了Amazon Captcha库(https://github.com/a-maliarov/amazoncaptcha )。它可以接受图片,通过预先训练好的模型,将图片转化为结果字符串。
因此,我们将前面得到的图片url放入该训练模型中,即可获得结果字符串。在获得结果之后,将其回填到输入框中,并点击确定键,即完成了验证码识别。
```python
def handleCaptcha(self):
try:
self.total = self.driver.page_source
soup = BeautifulSoup(self.total, features="lxml")
src = soup.find(
class_="a-row a-text-center").findChild(name="img").attrs["src"]
captcha = AmazonCaptcha.fromlink(src)
solution = captcha.solve(keep_logs=True)
print(solution)
#
input_element = self.driver.find_element_by_id("captchacharacters")
input_element.send_keys(solution)
button = self.driver.find_element_by_xpath("//button")
button.click()
print("已解决验证码√")
#再次访问刚刚的网址
self.asinSet.iloc[self.index, 1] = False
except:
return
```
### 1.2.3 404网页
在爬虫的过程中,还会遇到部分电影已经变为404网页的情况。
在这种情况下,标记后继续爬取下一个asin即可。
### 1.2.4 爬虫汇总
完成上述的代码之后,便可以让程序挂机进行爬虫过程。通过分析,该爬虫过程的主要瓶颈在于网络约束。通过改为多线程爬取,并没有提高爬取速度。因此,我们尝试更换了更好的网络环境进行信息爬取。
同时,为了减少不必要的资源损耗,在爬虫过程中我们设置默认不显示图片:
```python
options = ChromeOptions()
prefs = {
'profile.default_content_setting_values': {
'images': 2,
}
}
options.add_experimental_option('prefs', prefs)
```
在爬取完成之后,我们共获得了上万条数据。
# 2 数据预处理
## 2.1 数据提取与解析
针对爬虫爬取的数据进行分析,所有的数据均为结构雷同的Html文件,因此仅需对每个文件使用Xpath, BS4等文本解析库进行逐个解析。
针对数据的存储要求,我们根据网页的结构对相应字段进行逐一提取。如网页中的电影名称,由于不同网页的HTML结构相同,因此我们仅需使用:
```python
movie_title = html_selector.xpath('normalize-space(//span[@id="productTitle"]/text())')
```
解析页面种id为"productTitle"的span元素内的值即可获取。而对于页面不同位置的同类信息,如演员和导演信息,解析脚本会综合这两个地方的信息以防止数据丢失。对于电影的风格信息,由于页面详细信息未包含电影风格,因此我们考虑解析HTML文件中的id = "wayfindingbreadcrumbs_featur_div"的div块中获得电影类别或风格信息。
由于同一电影具有多重版本,为保留这一版本信息,解析脚本对同一电影页面下各格式各版本的Asin均进行逐一解析,以数组形式存贮在每一个电影的字段中,为接下来的冲突合并做好准备。
为筛选掉TV数据,我们对电影Label为“TV”的数据进行去除,最终得到了解析后的电影数据表,以便进行接下来的数据清洗和冲突合并。
## 2.2 数据清洗与冲突合并
在经过从网页标签中提取数据与对数据进行冲突识别过程,目前已经获得基本的电影数据与冲突关系。但是由于爬取的Amazon网页的电影数据并不规整,电影信息中参杂了很多商品信息与无用符号信息,使用不规整的电影数据会使后续处理过程结果并不准确,因此在解决数据冲突之前,需要对电影数据信息进行简单的数据清洗。
### 2.2.1 数据清洗
数据清洗的主要过程为清洗空值、清洗多余符号串以及清洗附属于电影的商品信息。
通过标签提取出来的电影信息包含很多空值,由于不同电影属性的空值字符表达并不相同,因此需要对所有符合空值语义的符号串进行字符替换,统一表达空值的情况方便后续信息的比较与整合。代码如下所示:
```python
def removeSymbolValue(data):
naList = [',',' ','-','_','.','*',"None","N/a","N/A","na","[]","__","~","none","nan","|"]
for column in ('movie_title','director','actor','main_actor','movie_category'):
data.loc[data[column].isin(naList),column] = ""
for column in ('director','actor','main_actor'):
data.loc[data[column].str.lower().str.contains('various'),column] = ""
```
对于电影评分、电影评价数量的缺失值,为了方便后续的运算,将评分的缺失值设定为“-1”,将评论的缺失值设定为“0”。
另一方面,由于电影属性字符串中包含很多空格、换行符、中文引号等信息,这种情况对相同电影名称、演员等信息的比较会造成影响,因此对这类字符进行替换,代码如下:
```python
def removeNewLine(data, attribute):
data[attribute] = data[attribute].apply(lambda x: x.strip())
data[attribute] = data[attribute].apply(lambda x: x.replace("\n",""))
data[attribute] = data[attribute].apply(lambda x: x.replace("'\n",""))
```
由于数据来源于Amazon商品网页,在使用电影数据的过程中,电影名称等信息附带了繁杂的商品属性信息,不利于我们获得纯粹的电影信息。因此我们简单的对电影属性进行了处理,去除了包含在括号内的电影版本、商品属性等信息,一定程度上提高了电影数据信息的纯度与集中度,利用正则表达式处理代码如下:
```python
def removeBrackets(data, attribute):
#去除掉一个字符串的括号及括号内的内容
data[attribute] = data[attribute].apply(lambda x: re.sub('\(.*?\)','',x))
#去除掉一个字符串的[]括号
data[attribute] = data[attribute].apply(lambda x: re.sub('\[.*?\]','',x))
#去除字符串以(结尾的内容
data[attribute] = data[attribute].apply(lambda x: re.sub('(\(.*?)$','',x))
#去除字符串以)结尾的内容
data[attribute] = data[attribute].apply(lambda x: re.sub('(\).*?)$','',x))
```
最后一部分是内容是对演员与主演信息的处理。因演员与主演信息之间存在相关性,所以如果数据中存在两者之间有一为空的情况下,可以采用另一个数据列进行代替,完成对缺失数据的补足,提高数据的使用效果,代码块如下:
```python
for index,row in data.iterrows():
if row['actor'] == "" and row['main_actor'] != "":
data.loc[index,'actor']=data.loc[index,'main_actor']
elif row['actor'] != "" and row['main_actor'] == "":
data.loc[index,'main_actor']=data.loc[index,'actor']
```
### 2.2.2 解决冲突与数据合并
在数据清洗完成后,可以根据上述对电影版本之间的关系处理目前数据中存在的冲突。解决冲突的目标在于对信息的汇总,即电影不同属性字段选取规则的建立。根据不同电影属性的特点,可以自定义对属性的选取规则来解决现存的数据冲突。
选取的规则如下:
- 对于存在冲突的电影标题信息,选取目前存在数据池中长度较短的字符串作为整体的电影标题。
- 对于存在冲突的电影导演信息,选取目前存在数据池中长度较短的字符串作为整体的电影导演信息。
- 对于存在冲突的电影演员信息与主演信息,选取目前存在数据池中长度较长的字符串作为整体的电影演员主演信息。
- 对于存在冲突的电影发布时间信息,选取目前存在数据池中发布时间最早的信息作为整体的电影发布时间信息。
- 对于存在冲突的电影分数与评论数信息,综合整体冲突版本的评论总条数作为整体的评论数量,并根据评论数量进行加权计算电影分数作为整体的电影得分。
- 对于不存在冲突的属性或电影信息中并非关注的主要属性,均选取父节点电影版本信息(即首次爬取的电影信息)作为整体的电影信息。
选取的示例代码如下:
```python
def getMovieTitle(sonList, data):
minLengthTitle = ""
minLength = 1000
for index,asin in enumerate(sonList):
cursor = data[data['asin'] == asin]
cursor = cursor.loc[:,'movie_title']
cursor_movie_title = cursor.iloc[0]
if cursor_movie_title == "":
continue
if len(cursor_movie_title) < minLength:
minLength = len(cursor_movie_title)
minLengthTitle = cursor_movie_title
return minLengthTitle
```
最后,根据上述得到的电影之间的版本关系,为解决冲突后的电影数据填充版本数量的字段,表示目前的电影数据融合的电影记录数量,方便后续存储与使用。
### 2.2.3 数据抽取
为了支持下游不同特性的数据库对电影数据的需求,需要对已经解决冲突后的电影数据进行属性的抽取与存储。主要的目的在于对电影导演、演员、主演以及类别信息的提取。由于这些电影属性在合并后的汇总数据中并不是原子性的,而是一个电影对应了一个属性的符号串,为了获得清洗的属性数据,需要对属性列进行拆分与重组,得到更规则的电影属性信息。
在输入需要处理的标签列表后,即可得到抽取后的属性结果。实现数据抽取与重新组装的代码如下所示:
```python
def splitAndDropDulplication(self, tagList):
self.consolidation.loc[:,tagList].fillna("",inplace = True)
result_with_tag = {}
for tag in tagList:
# 定义一个结果列表、切片合并数据源获得对应Series
result = []
data_with_tag = self.consolidation.loc[:,tag]
for index,item in enumerate(data_with_tag):
if not pd.isnull(item):
#对每一个字符串进行切片操作
item = str(item)
dataList = re.split(r'[;,&/|]', item)
#去除前后空格
for it in range(len(dataList)):
dataList[it] = dataList[it].strip()
#重新拼接为合法字符串
pureDataString = ",".join(str(i) for i in dataList)
#填充操作
self.consolidation.loc[index,tag] = pureDataString
result.extend(dataList)
#去重
result = list(set(result))
#去除非法删除字符
for dropItem in self.dropList:
if dropItem in result:
result.remove(dropItem)
#将结果填充至字典
result_with_tag[tag] = result
return result_with_tag
```
# 3 存储模型
## 3.1 关系型数据库
#### 3.1.1 关系型数据库逻辑模型
本项目要求存储有关电影基本信息,演员信息,评分信息,时间信息等多个维度的信息,对数据库涉及的操作仅为大量高并发查询,因此关系型数据库的设计要点为以冗余的存储来提高查询的效率。针对以上业务要求,关系型数据库使用**星型模式**(Star Schema)进行关系型数据库的结构组织。其逻辑模型如下图所示:
.png)
我们使用电影事实表存储电影主要数据,包括两类信息,一类是数值信息,另外一类为维度信息。其中数值信息仅包括如电影名称、电影版本数、电影评论数、电影ASIN等仅与电影本身属性有关的信息,维度属性不直接存储数据,而是存储维度表的外键值。
除事实表外,维度表存储各个维度的属性值。本星型模式具有包括时间维度、演员维度、导演维度、电影类别维度、电影评价维度、电影评分维度、电影评分维度七张维度表,每个维度表都将与具有维度值的事实表中列相关联,存储有关该维度的附加信息。
在关系型数据库的逻辑模型中,我们暂不考虑查询性能优化,仅考虑了具备哪些维度和需要存储哪些信息。
#### 3.1.2 关系型数据库物理模型
根据以上物理模型,在进行存储和查询的综合考量后,使用如下物理模型进行最终数据存储:

在实际存储中,若仍然以存储外键的方式在事实表中存储演员信息和导演信息,则在movie表中会出现大量冗余行,因为一个电影存在多个演员和导演,因此这里颠倒了存储方式,在演员表和维度表中将电影id作为主键,这一冗余信息仅存在于列数相对较少的维度表中,同时根据演员、导演查询电影的效率也会大大提高。同样的设计方法用在了电影分数表中。除此之外还新增了一个Time_movie冗余表,仅存储每个电影的时间信息,为满足实际查询过程中根据时间范围查询电影的需求,最大化查询速度。
## 3.2 分布式数据库
本项目采用了Hadoop这一分布式文件系统进行分布式数据库的存储,并使用Hive进行操作,我们建立了一个NameNode以及两个DataNode,实现了数据的分布式存储。分布式数据库的优越之处在于其能通过可用的计算机集群分配数据,完成存储和计算任务,同时可以在各个节点之间进行动态的移动数据,保证各个节点的动态平衡,多个副本存储也使其具有高容错性。根据存储和查询需求,我们建立存储模型如下图所示。

因为Hadoop中可以插入复杂数据结构,所以我们在movie表中可以建立Array类型的列来对导演、主演以及演员进行存储。因为Hive的join操作非常耗时,为尽快查找到人和人之间关系,我们建立了三张表进行存储。人与人之间关系本来可以使用一张表进行存储,但为了加快查找速度,我们将其拆分为三个表,由于每次操作都会扫描全表,所以表行数的减少会使查询速度更快。
## 3.3 图数据库
我们采用了neo4j作为图数据库存储,其中共有124872个结点和234513条关系边。
其存储模型如下所示:
电影、种类和人作为单独的结点,而电影所属种类、导演情况、主演情况和出演情况作为图里的边。
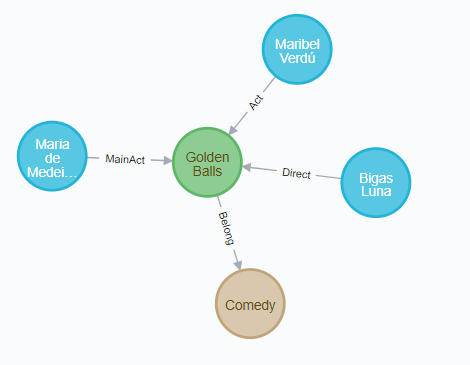
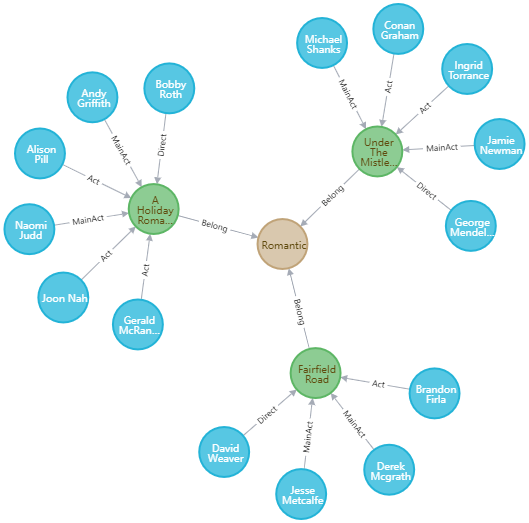
# 4 存储优化
## 4.1 Mysql
#### 4.1.1 单表字段存储优化
本优化针对每个字段的存储类型优化,减少数据表中单行记录的存储大小,提高单表扫描的速度。具体优化的规则如下:
1. 用 TINYINT 作为整数类型而非 INT,VARCHAR 的长度只分配真正需要的空间
2. 适当删去不会查询到的字段,减少宽表列数,提高扫描速度
3. 除外键之外避免使用NULL字段,因为NULL字段的存在可能会影响Mysql使用索引查询,显著降低查询扫描速度。
#### 4.1.2 建立索引
在进行查询的书写时,针对查询条件进行有针对性地添加索引,从而提高查询速度。对于索引的创建,我们采用以下原则:
1. 维度高的列尽量创建索引
2. 对于sql查询语句中where, on ,group by, order by 中出现的列使用索引,即对经常查询的条件相应的字段创建索引。
3. 对较小的数据列使用索引,这一会使索引文件更小,同时内存中也可以装载更多的索引键。
4. 由于本数据库不涉及增删改,因此索引的创建无需考虑多增加带来的对DML操作的影响
5. 对于多重条件的查询,可以考虑创建组合索引
如以下索引的建立显著提高了查询速度:
##### 4.1.2.1 单条件多表联合查询
考虑以下查询:**查询给定评分范围内的电影信息**
针对以上查询,需要联立movie表和movie_score表,通过inner join查询。对于查询优化的分析,我们可以在查询语句前加入EXPLAIN关键字进行查询结果的分析。在不进行索引建立时,查询评分在4.9到5.0的电影,查询语句及结果如下:
```sql
EXPLAIN SELECT
movie_score.movie_id,
movie.movie_name,
movie.movie_edition_num,
movie.movie_score,
movie.movie_asin,
movie.movie_edition,
movie.comment_num,
movie.time_str
FROM
movie_score
INNER JOIN
movie
ON
movie_score.movie_id = movie.movie_id
WHERE
movie_score.movie_score >= 4.9 AND
movie_score.movie_score <= 5.0
```

根据上述的结果我们发现在进行movie_score表的查询时,由于未设置索引,查询的type为“All”这表示扫描了全表才确定了最终结果。而进行join操作时,由于建表时外键建立了索引,因此type为“eq_ref”,效率较高。由此发现该查询的优化瓶颈为针对movie_score查询字段的索引优化。我们添加查询字段“movie_score”为索引。建立索引后的查询分析结果如下:

可见在建立索引后,对movie_score表进行的扫描减少了50倍左右,查询type变为了“range”,符合“保证查询至少达到range级别”的要求。
上述索引创建前后查询的速度对比图如下:
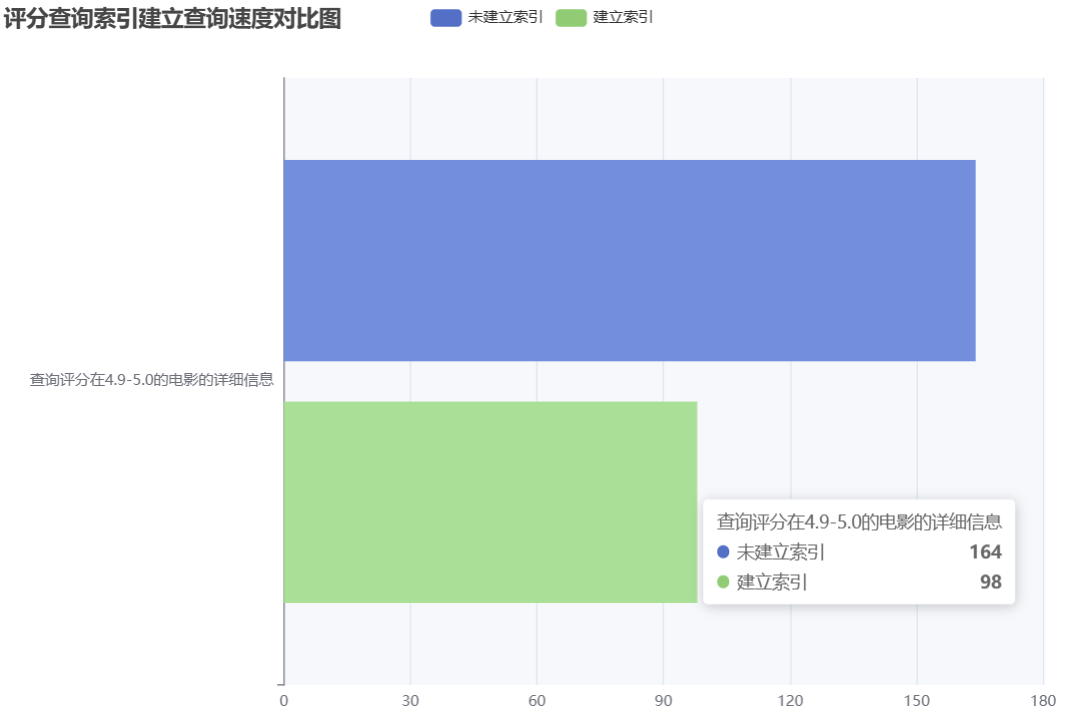
##### 4.1.2.2 多条件多表联合查询
考虑如下查询:**按照时间范围、类别、评分、好评率查询符合条件的电影信息**
查询的sql语句如下:
```sql
EXPLAIN
SELECT
movie.movie_name,
movie.movie_score,
movie.movie_asin,
movie.movie_edition,
movie.comment_num,
movie.time_str
FROM
category
INNER JOIN
movie
ON
category.movie_id = movie.movie_id
INNER JOIN
movie_score
ON
movie.movie_id = movie_score.movie_id
INNER JOIN
time
ON
movie.time_id = time.time_id
WHERE
category.category_name = 'Comedy' AND
movie_score.movie_score >= 3.5 AND
movie_score.positive_comment_rating >= 0.2 AND
time.`year` >= 2000 AND
time.season = 2 AND
time.weekday >= 3
```
针对该查询,我们可以针对要查询的且维度较高的字段建立索引。其中,对于time表,由于查询的字段较为繁多,我们可以考虑建立 **组合索引**。
在分别对time建立聚合索引,对category表的category_name字段建立索引,movie_score的movie_score字段和positive_comment_rating字段建立索引后,使用EXPLAIN进行分析后的结果如下:

建立索引前和建立索引后的查询结果比较如下图所示:

##### 4.1.2 增加冗余字段和冗余表
由于本数据库查询使用Spring boot 后端JPA查询,因此实际查询速度还考虑其本身的特性。我们针对特定的查询条件和特定的后端实现技术增加了特定的冗余字段和冗余表。
首先是根据时间范围查询电影。由于Spring boot 查询本身直接嵌入Sql语句进行查询十分不便,本项目的实际查询思路是先根据条件筛选出Movie_id列表,然后根据id查询出每个电影的各个信息。在最后的汇总时,由于movie表本身无时间信息,因此在获取时间信息还需再次join time表,极大降低了总体查询效率,因此考虑在movie表中加入冗余字段Time_str,减少最后再次join表的时间开销。
同时,在根据时间范围查询时,若查询某一时间范围内的电影,需要同时join time表和movie 表,为尽量避免表的连接,创建了Time_movie冗余表,仅含movie_id和time_str两个字段,可以避免join直接在表内筛选出结果。
经过实践证明,适当增加冗余字段和冗余表的方法显著提高了Spring boot JPA查询的实际速度。
## 4.2 Hive
### 4.2.1 更改Hive的Fetch抓取配置
Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算。例如SELECT * FROM movie;这句查询语句,不需要进行MapReduce的计算,Hive可以直接读取movie存储目录下的文件,然后将查询结果输出至控制台。
`hive-default.xml.template`文件中`hive.fetch.task.conversion`默认为`more`,而之前版本的hive默认值为`minimal`,当其属性修改为more之后,在全局查找、字段查找、limit查找都不使用MapReduce来加快查询速度。
将抓取配置设置为`more`以及设置为`minimal`的对比图如下所示:

### 4.2.2 开启Hive本地模式
大多数的Hadoop Job是需要Hadoop提供的完整的可扩展性来处理大数据集的。不过,有时Hive的输入数据量是非常小的。在这种情况下,为查询触发执行任务消耗的时间可能会比实际job的执行时间要多的多。对于大多数这种情况,Hive可以通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间可以明显被缩短。
用于测试的`movie`表数据总数为56417条,属于较小的数据集,所以我们可以开启本地模式进行单机处理,我们可以将`hive.exec.mode.local.auto`的值设置为`true`来实现此优化。
优化实现语句如下所示:
```
set hive.exec.mode.local.auto = true
```
优化前和优化后对比如下图所示:

### 4.2.3 压缩
##### 4.2.3.1 开启Map输出阶段压缩
开启map输出阶段压缩可以减少job中map和Reduce task间数据传输量。具体配置如下:
```
1)开启hive中间传输数据压缩功能
hive>set hive.exec.compress.intermediate=true;
2)开启mapreduce中map输出压缩功能
hive>set mapreduce.map.output.compress=true;
3)设置mapreduce中map输出数据的压缩方式
hive>set mapreduce.map.output.compress.codec= org.apache.hadoop.io.compress.SnappyCodec;
4)执行查询语句
hive>select count(asin) from movie;
```
压缩后和压缩前的时间对比如下图所示:

##### 4.2.3.2 开启Reduce输出阶段压缩
当Hive将输出写入到表中时,输出内容同样可以进行压缩。属性`hive.exec.compress.output`控制着这个功能。用户可能需要保持默认设置文件中的默认值`false`,这样默认的输出就是非压缩的纯文本文件了。用户可以通过在查询语句或执行脚本中设置这个值为`true`,来开启输出结果压缩功能。
```
1)开启hive最终输出数据压缩功能
hive >set hive.exec.compress.output=true;
2)开启mapreduce最终输出数据压缩
hive >set mapreduce.output.fileoutputformat.compress=true;
3)设置mapreduce最终数据输出压缩方式
hive > set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec;
4)设置mapreduce最终数据输出压缩为块压缩
hive > set mapreduce.output.fileoutputformat.compress.type=BLOCK;
```
压缩后和压缩前的时间对比如下图所示:

由于Reduce阶段的优化主要体现在Hive将输出写入表中时,所以查询语句在这里被优化的并不明显。
##### 4.2.3.3 开启Map和Reduce输出阶段压缩
将Map和Reduce阶段均压缩,其压缩后和压缩前的时间对比如下图所示:

## 4.3 Neo4j
### 4.3.1 Native Graph Processing
原生图(Native Graph)数据库指的是以图的方式存储、处理、查询和展现数据,它在关系遍历和路径搜索类查询应用中有着良好的性能。
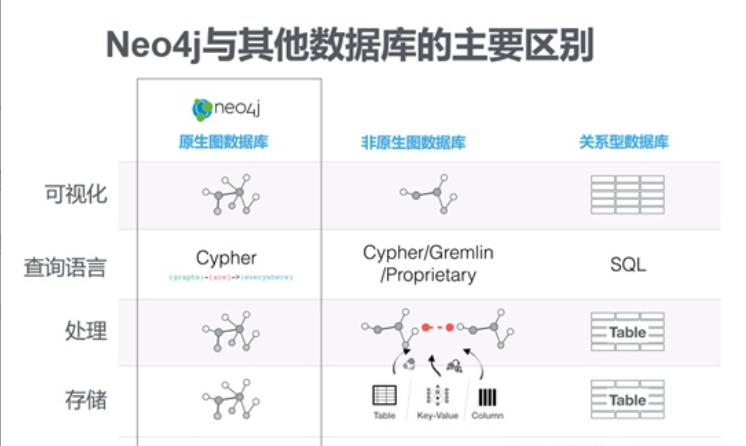
Neo4j中数据对象/实体被保存为节点,它们之间的关系则以链接地址的形式也保存在物理存储中。因此,在遍历关系时,原生的Neo4j图数据库中只要找到起始节点、读取节点的邻接边就可以访问该节点的邻居;而无需像关系数据库那样需要执行昂贵的连接JOIN操作,系统开销大大减少、执行效率极大提升。
在本项目中,每一个电影都可能属于一个或多个类别。针对于类别,我们有两种存储策略:第一种是将Movie、Category分别作为一个结点,而将Movie和Category的从属关系作为边;第二种则是将Category信息作为Movie结点的一个属性。
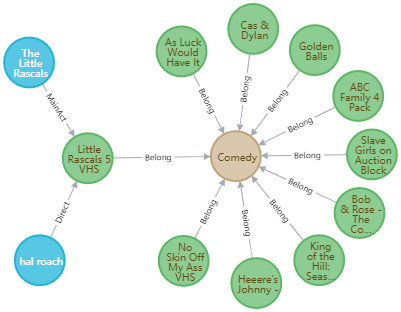

根据前面的理论,我们可以预测查询某一种类的全部电影的时间复杂度分别为:
- 方案一:O(logN)+n*O(1),其中N为电影类别数量,n为该类别电影数
- 方案二:O(logM),其中M为电影总数
由于N<
由此证明,将电影类别作为单独的结点存储是一种更好的方案。
### 4.3.2 建立查询索引
对于任意一种数据库,对经查被查询到的属性建立索引是一种很好的策略。
考虑到我们最终的查询涉及到查找某一年上映的电影,因此我们为year属性建立索引:
```cypher
create index on :Movie(year)
```
建立索引前后查询效率如下所示:
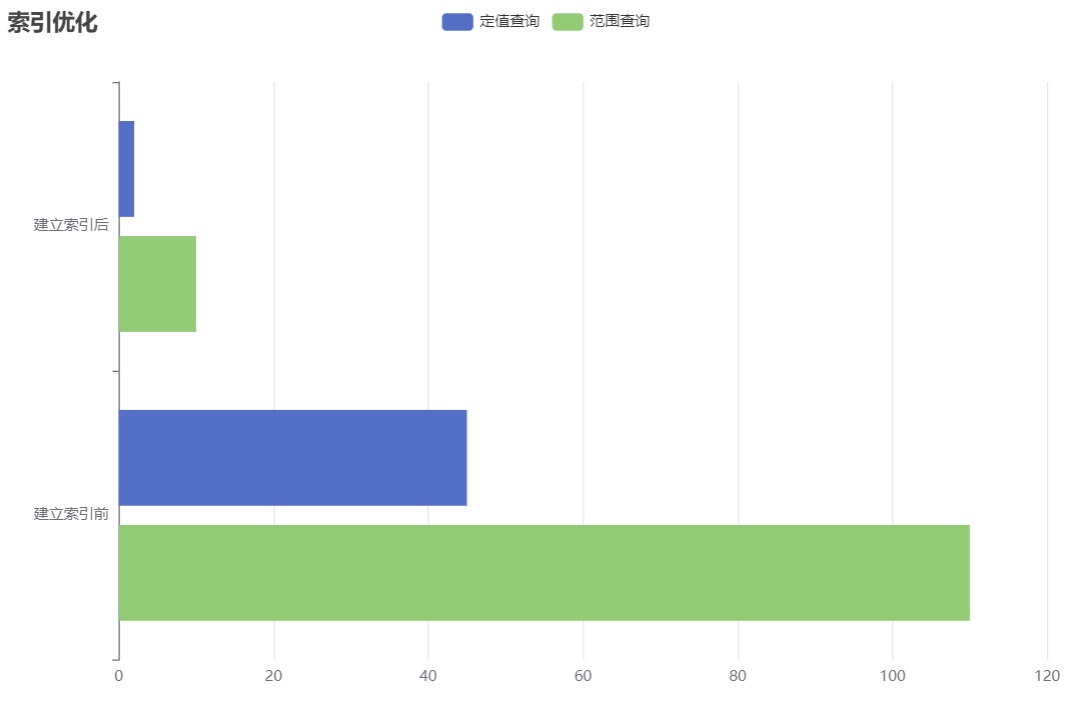
因此,为需要经常被查询的属性建立索引是一种很好的策略。
# 5 总结
通过我们在本次项目中对于数据的存储,我们有以下收获。
## 5.1 适宜查询
关系型数据库常常将同一业务范围内或同一方面的实体或事物组合成一张表,十分适合作单一条件的筛选查询,使用索引后的单表扫描效率十分高效。如根据某一类别的所有电影,某一时间段内的所有电影等。同时,适当使用索引也会加快多条件多表查询的速度。因此多条件的结果筛选同样适合关系型数据库,如针对不同条件的复合查询等。
分布式数据库适合于分布式的数据管理,在拥有多节点的情况下可以确保系统的可靠性。同时,由于可以依靠多个分布结点的算力,所以其在大数据量时的计算会更加快捷,比如不同条件的符合查询。当数据量越大时,分布式数据库锁体现的优势越大。
图数据库由于天然的就能够反映结点和结点之间的关系,因此非常适合于做关系之间的查询,例如:合作次数最多的演员、电影所属类别等。
## 5.2 数据质量
经过从评论集中获取电影编号信息到爬取、处理、清洗、抽取、存储等整个流程,对数据质量进行改善,但从整体上评估Amazon电影数据质量,仍有改进空间。
- 完整性
Amazon电影数据总体记录数量较多,但是其中部分电影数据缺失属性较为严重。并且由于大部分属性数据之间相对于独立,因此并不能通过已有相关数据进行推导、总结得到。但是,为了使得数据更具有完整性,我们通过对未冲突数据的电影演员与主演之间的关联关系而进行信息互补,另一方面通过对存在冲突的电影数据进行汇总,也一定程度上完成了对缺失值的填充。
- 规范性
由于Amazon电影数据是以商品销售为目的,因此提取出的属性字段的规范性并不好,尤其体现在电影数据的电影标题、电影演员与导演等字符属性中。该属性字段中含有较多的商品版本信息,并未以规范的形式区分电影名称与版本信息,因此属性值杂糅并不规范。我们试图通过提取一般规律来提高数据质量,如去除电影名称中括号内的内容与括号后的内容来提高电影名称的质量。另一方面,演员、导演等信息是通过字符串拼接得到的整体信息,由于字符串中混杂着换行符、前后空格,该种情况不利于对建立电影与人员的关系与搜索,因此对字符串进行切分与重组达到规范字符串的目的。
由此,该项目中数据质量很大程度受到不同属性列字段的完整性与规范性的影响。由于数据缺失值较多且数据相对独立,导致记录缺失必要信息。另一方面,由于字段没有统一的规范拼接,导致数据并不利于后续的存储与建立关系连接,也进一步导致数据质量无法满足唯一性与关联性。对于同一部电影没有严谨的关联关系以及唯一的形式表达,导致数据重复信息较多且无法对同一部电影进行信息整合与冲突解决。
目前,该项目通过上述对字段进行规范处理、对冲突数据建立规则整合信息、对关联缺失信息进行相互补足的方式一定程度上保证了数据质量,仍有待改进的方式为通过爬取国家电影数据库或者电影评价网站的信息来清洗Amazon电影数据,通过对字段的唯一化来建立数据冲突,整合数据并解决该冲突,从而提高数据质量,利于后续查询存储与维护。
## 5.3 数据血缘
数据血缘关系可以被利用于数据流向的查询、结果的溯源与错误值的定位。对于项目中的Amazon电影数据可以进行简单的数据血缘推导,结合上述建立的冲突解决规则可完成对结果的溯源查询,具体使用场景如下所示:
1. 数据流向查询
数据血缘正向的使用场景为从初始的评论数据集到最后我们合并冲突的数据集整体的数据信息变化过程与数量,本项目中通过建立桑基图的方式表现数据的流动过程,如下所示:
[](https://imgtu.com/i/TAkC40)
2. 不同阶段的数据信息查询
为了保存数据血缘关系,我们对处理过程中的中间过程数据进行了存储,因此可以在项目中点击相应的数据节点查看该类数据的信息,如下图所示:
[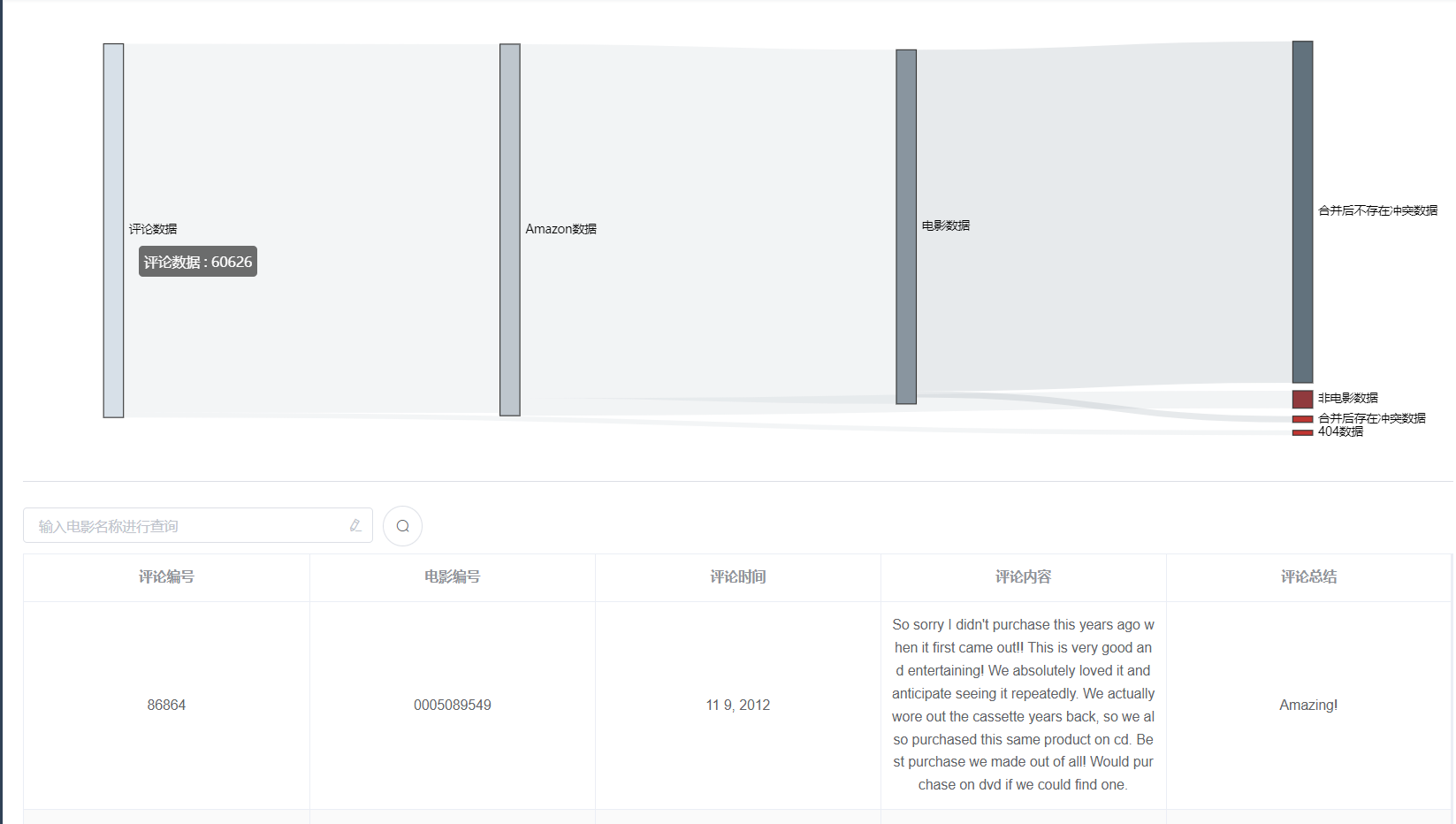](https://imgtu.com/i/TAk6bj)
3. 溯源查询
数据血缘最契合于对数据流向的逆过程探索,即对数据进行溯源查询。该项目可以对多版本电影数据进行溯源查询,查询得到合并前的电影数据信息,以及该电影来源于的评论数量,最后可以通过点击不同版本的电影跳转回原网页实现最终的溯源,示意图如下所示:
[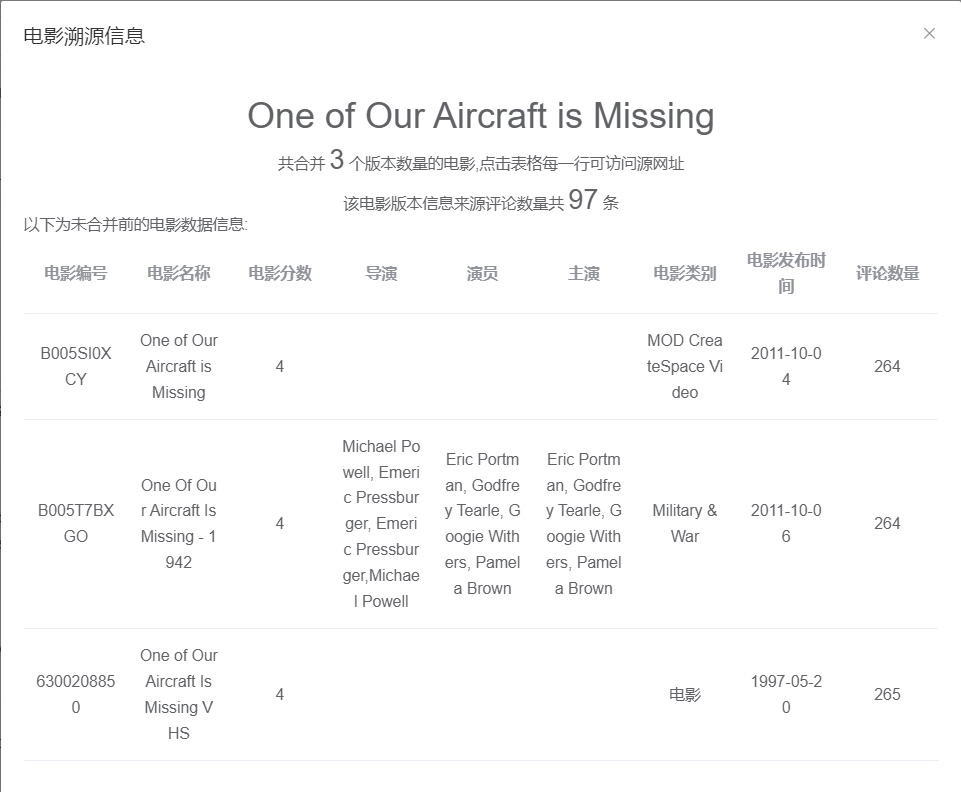](https://imgtu.com/i/TAExDe)
综上所述,数据血缘是数据从起源到结束的演变过程,可以通过对演变过程中某一阶段进行向上的探索与搜查。在本项目中,由于部分电影缺少字段的现象严重,数据合并的过程相对而言并没有很复杂的逻辑。考虑到合并后电影信息的数据来源主要为清洗后的电影信息与起源的评论数据信息,因此通过筛选完成对合并版本的电影数据与总评论数量的结果展示,结合合并前清洗后的电影数据与设定的筛选规则可以直观了解到解决冲突的过程,并且可以通过跳转回原网站查询实际结果。
## 5.2 测试用例及对比
### 5.2.1 单条件查询
##### 5.2.1.1 测试代码
1. 关系型数据库
```sql
SELECT
movie.*
FROM
movie
WHERE
movie.movie_name = "Sex is Comedy"
```
2. 分布式数据库
```sql
select * from movie where movie_title = "Sex is Comedy";
```
3. 图数据库
```cypher
match (m:Movie) where m.movie_title = "Sex is Comedy" return m;
```
##### 5.2.1.2 速度对比

### 5.2.2 多条件查询
##### 5.2.2.1 测试代码
1. 关系型数据库
```sql
SELECT
movie.*
FROM
movie
INNER JOIN
category
ON
movie.movie_id = category.movie_id
INNER JOIN
actor_movie
ON
movie.movie_id = actor_movie.movie_id
INNER JOIN
time_movie
ON
movie.movie_id = time_movie.movie_id
WHERE
movie.movie_name = "Sex is Comedy" AND
category.category_name = "Cooking" AND
(actor_movie.actor_name = "A Half Men" AND
actor_movie.is_main_actor = 1) OR
(actor_movie.actor_name = "Cade Sutton" AND
actor_movie.is_main_actor = 0) AND
movie.movie_score > 1 AND
movie.movie_score < 5 AND
time_movie.time_str>"2021-12-06 00:00:00" AND
time_movie.time_str<"2021-12-23 00:00:00"
```
2. 分布式数据库
```sql
select * from movie
where movie_title = "Sex Is Comedy"
and style = "Cooking"
and array_contains(directors,"Aaron Augenblick")
and array_contains(main_actors,"A Half Men")
and array_contains(actors,"Cade Sutton")
and score > 1
and score < 5
and release_date < 2021-12-23
and release_date > 2021-12-06
```
3. 图数据库
```cypher
match (m:Movie) ,
(m)-[:Belong]->(:Category{name:"Cooking"}) ,(m)<-[:Direct]-(:Person{name:"Aaron Augenblick"}) ,(m)<-[:MainAct]-(:Person{name:"A Half Men"}) ,(m)<-[:Act]-(:Person{name:"Cade Sutton"})
where m.title="Sex Is Comedy"
and m.score >=1
and m.score <= 5
and m.year*10000+m.month*100+m.day >= 20211206
and m.year*10000+m.month*100+m.day <= 20211223
return m
```
##### 5.2.2.2 速度对比
