https://github.com/Sunny-117/js-toochain-book
掘金专栏 前端工具链 代码仓库 掘金专栏地址:https://juejin.cn/column/7287224080172302336
https://github.com/Sunny-117/js-toochain-book
Last synced: 7 months ago
JSON representation
掘金专栏 前端工具链 代码仓库 掘金专栏地址:https://juejin.cn/column/7287224080172302336
- Host: GitHub
- URL: https://github.com/Sunny-117/js-toochain-book
- Owner: Sunny-117
- Created: 2023-10-08T09:20:59.000Z (about 2 years ago)
- Default Branch: main
- Last Pushed: 2023-10-08T10:04:06.000Z (about 2 years ago)
- Last Synced: 2025-03-25T19:40:53.794Z (7 months ago)
- Language: JavaScript
- Size: 1.33 MB
- Stars: 5
- Watchers: 2
- Forks: 1
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# js-toochain-book
掘金专栏 前端工具链 代码仓库 掘金专栏地址:https://juejin.cn/column/7287224080172302336
专栏所有代码地址:https://github.com/Sunny-117/js-toochain-book
# 概述
首先我们这边来确定几个概念:
- 前端工具
- 构建工具
- 脚手架
## 前端工具
一说到前端工具,那么这个工具的数量是非常非常多的,每一个工具实际上都是在致力于做一件事情。
本门课程我们主要聚焦于介绍和 JS 相关的工具,下面罗列了一些常见的工具:
1. *Prettier*:*Prettier* 是一个代码格式化工具,用于自动格式化 *JavaScript、TypeScript、CSS、HTML* 等文件。*Prettier* 可以确保团队遵循一致的代码风格,从而提高代码的可读性和维护性。
2. *ESLint*:*ESLint* 是一个静态代码分析工具,用于检查 *JavaScript* 和 *TypeScript* 代码中的潜在问题和编码规范。*ESLint* 通过可配置的规则来检查代码,并可以与 *Prettier* 结合使用,以确保代码质量和风格的一致性。
3. *Babel*:*Babel* 是一个 *JavaScript* 编译器,用于将新版 *JavaScript*(如 *ES6+*)转换为兼容旧版浏览器的代码。*Babel* 支持插件系统,可以进行语法转换、优化和其他代码转换任务。
4. *Terser*:*Terser* 是一个 *JavaScript* 压缩器,用于移除无用的代码、空格和注释,从而减小代码的文件大小。*Terser* 支持 *ES6+* 语法,并可以用于压缩和优化生产环境的 *JavaScript* 代码。
像上面所罗列的这些东西就是前端开发中常用的工具,这些工具一般是在 部署上线 之前会使用,而且很明显的可以看到,一个工具就是负责做一些事情。另外就是上面所罗列的仅仅是前端中最最最常用的工具,工具本身的数量是非常非常多的,取决于你要做的事情,你要做的事情越多,那么自然你用到的工具也就越多。
## 构建工具
现在我们有了一堆工具,每个工具负责做一件事情,那么我们在部署上线之前,会做的一件事情就是将项目代码先交给工具 A 进行处理,处理完成后拿到处理结果交给工具 B 进行第二次处理,之后交给工具 C、D、E、F... 每一次使用下一个工具的时候需要基于上一个工具的处理结果。
此时你就会发现这种方式非常非常繁琐,而且一旦我们对项目的代码有改动,那么上面的流程全部重新走一遍。
因此我们期望有一个工具能够帮助我们自动化完成从工具 A 到工具 Z 的处理工作,我们将从工具 A 到工具 Z 的处理工作称之为构建,对应的工具称之为构建工具。
构建工具顾名思义就是构建部署上线之前的代码,通过构建工具,可以将从工具A到工具Z的处理工作自动的跑一遍。
下面介绍一些常见的构建工具:
- *Grunt*:*Grunt* 是一个任务运行器,它使用基于配置的方法来定义任务。*Grunt* 有丰富的插件生态系统,可以执行各种前端构建任务。
- *Gulp*:*Gulp* 是一个基于流的任务运行器,它允许开发者编写简洁的任务来处理文件。*Gulp* 使用插件系统处理各种任务,如编译 *Sass*、压缩图片、合并文件等。
- *Webpack*:*Webpack* 是一个非常流行的模块打包器,它可以处理 *JavaScript、CSS、HTML* 和其他文件类型。*Webpack* 提供了许多插件和加载器,以便在打包过程中执行各种任务,如压缩、转换、热替换等。
- *Parcel*:*Parcel* 是一个零配置的 *Web* 应用打包器,它提供了快速的构建性能和自动代码拆分。*Parcel* 支持多种文件类型,并且可以自动处理模块热替换和资源优化。
- *Rollup*:*Rollup* 是一个 *JavaScript* 模块打包器,专注于生成高效的 *ES6* 模块。*Rollup* 支持插件系统,可以处理各种任务,如编译、压缩、处理 *CSS* 等。
- *esbuild*:*esbuild* 是一个极速的 *JavaScript* 打包器和压缩器,它使用 *Go* 语言编写,并利用了 *Go* 的并发特性来实现高速构建。*esbuild* 提供了一种简单易用的方式来打包 *JavaScript、TypeScript* 和 *JSX* 代码。它还支持 *CSS、JSON* 和其他文件类型的导入。*esbuild* 的目标是实现最小的配置和最快的构建速度,因此它可能不像其他构建工具那样具有丰富的插件生态系统。
构建工具和前端工具之间的关系如下图所示:
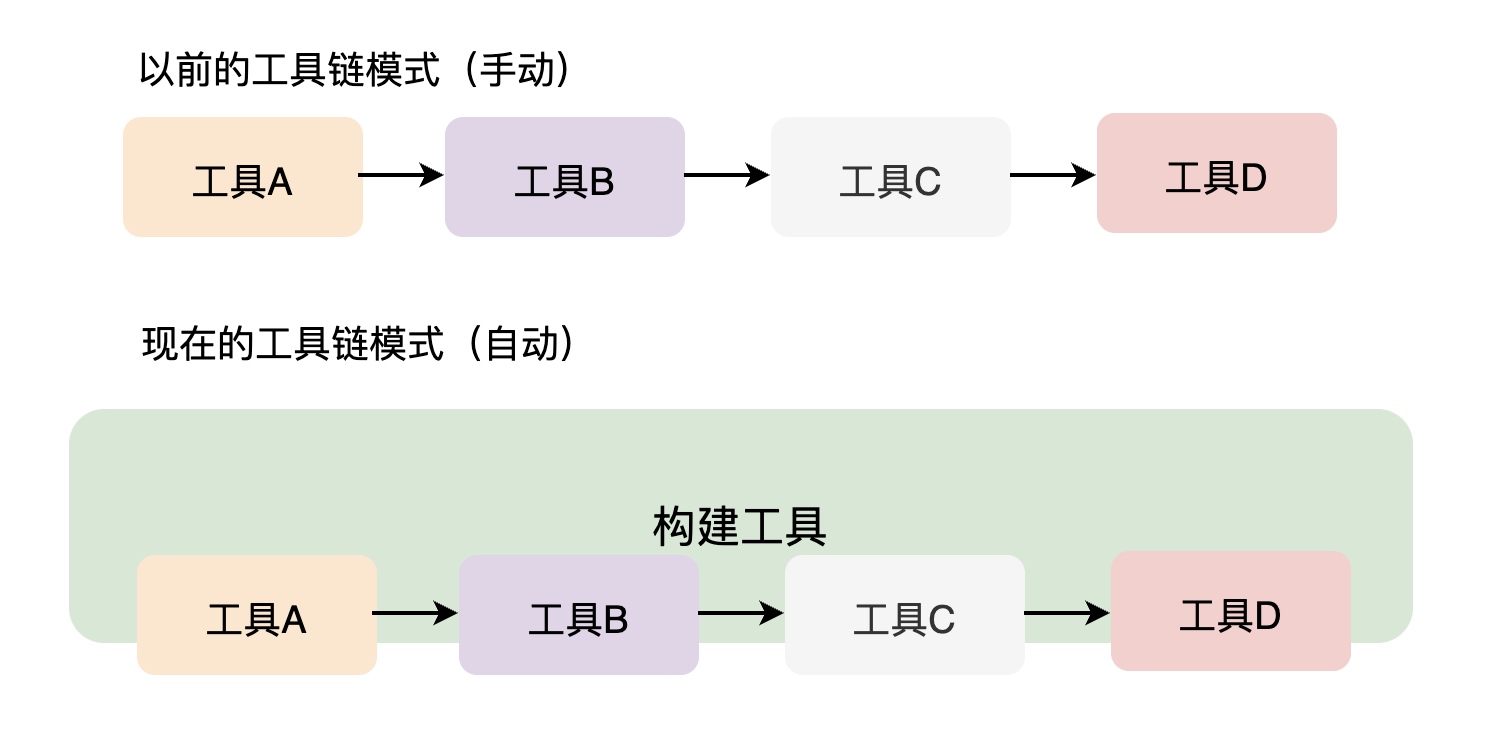
以前的众多工具之间会形成一个链条,但是需要我们手动进行操作,而有了构建工具之后,这种工具链的操作就变成自动化的了。
## 脚手架
实际上脚手架的主要工作是负责搭建项目的整体框架。
假设没有脚手架这个东西,现在我们要从一个空目录开始搭建项目,那么我们需要做一些什么:
- 安装各种依赖
- 对一些工具进行相应的配置
- 确定项目整体的目录结构
就是上面那么一些事情,我们可能就会面临:
- 你所搭建的项目结构并非最佳实践
- 需要研究各种工具的配置
- 在搭建项目上面花费大量的时间
脚手架的出现主要就是帮助我们解决上述的问题。脚手架也是一种自动化的工具,主要是帮助我们自动化的搭建项目结构、配置文件和项目基础代码。使用脚手架,可以帮助我们快速的搭建项目,让我们可以以最快的速度进入到编写业务代码的阶段。
下面是一些关于脚手架的优点:
1. 快速启动:脚手架可以快速生成项目的基本结构和文件,让开发者无需从头开始搭建项目。这可以节省大量时间,让开发者能够更快地进入开发阶段。
2. 最佳实践:脚手架通常包含了某个技术栈或框架的最佳实践,这可以帮助开发者遵循良好的编码规范和项目结构。这有助于提高项目的可维护性和可扩展性。
3. 统一团队标准:使用脚手架可以确保整个团队遵循相同的项目结构和编码规范。这对于团队协作和代码审查非常有帮助,可以提高团队的工作效率。
4. 减少配置错误:脚手架通常包含了预先配置好的开发环境、构建工具和自动化任务。这可以减少手动配置过程中产生的错误,提高开发和部署的稳定性。
5. 易于更新和维护:许多脚手架提供了更新和升级功能,开发者可以通过简单的命令来更新项目的依赖和配置。这可以确保项目始终使用最新的技术和最佳实践。
6. 插件和扩展支持:许多脚手架支持插件系统,开发者可以根据需要添加额外的功能和工具。这可以帮助开发者定制项目的开发环境,以满足特定的需求。
现在你就应该能够明白构建工具是构建工具,脚手架是脚手架,两者虽然都是自动化工具,但是两者做的事情是不一样的。脚手架负责的是自动化的搭建开发环境下的项目结构,构建工具是负责自动化的运行工具链任务,打包成最终能够部署上线的项目代码。
同学们之所以容易混淆这两个概念,原因往往也是因为现代的脚手架在搭建项目的时候就已经把构建工具就包含进去。
常见的脚手架有:
1. *vue-cli*:*vue-cli* 是 *Vue.js* 官方提供的一种命令行工具,用于快速生成 *Vue.js* 项目。它提供了一个带有预配置的开发环境,包括构建系统(基于 *webpack* 或 *Vite*)、代码检查(*ESLint*)、单元测试(*Jest* 或 *Mocha*)等。*vue-cli* 还支持插件系统,允许开发者添加额外的功能,例如 *Vuex*(状态管理)、*Vue Router*(路由)等。*vue-cli* 通过可视化的 *Web* 界面,让开发者可以轻松地管理项目和插件。
2. *create-react-app*:*create-react-app* 是 *React* 官方提供的一种脚手架,用于快速创建基于 *React* 的单页应用(*SPA*)。*create-react-app* 为开发者提供了一个预配置的开发环境,包括热重载、构建优化、代码检查(*ESLint*)等。*create-react-app* 的目标是让开发者无需关注配置,而可以专注于编写 *React* 代码。需要注意的是,*create-react-app* 对于配置的自定义性较低,如果需要高度自定义配置,可以选择其他的技术,例如 *Next.js* 或 *Gatsby*。
3. *Vite*:*Vite* 是一种新型的构建工具和脚手架,由 *Vue.js* 的作者尤雨溪创建。*Vite* 使用原生的 *ES modules* 特性,实现了极快的开发服务器和构建性能。*Vite* 支持 *Vue.js、React、Preact* 等多种框架,并提供了一套预配置的开发环境,包括热模块替换(*HMR*)、*CSS* 预处理器、代码检查(*ESLint*)等。*Vite* 还支持插件系统,可以轻松地扩展功能和集成其他工具。
4. *Angular CLI*:*Angular CLI* 是 *Angular* 官方提供的脚手架,用于创建、开发和部署 *Angular* 应用。它提供了一个预配置的开发环境,包括构建系统(基于 *webpack*)、代码检查(*TSLint*)、单元测试(*Karma* 或 *Jest*)等。*Angular CLI* 还支持插件系统,可以轻松地添加额外功能,如 *Angular Material*(*UI* 库)等。
## 学习此专栏,你可以收获什么
这一门我们主要聚焦到“前端工具”,介绍一些前端最最最常用的工具:
- prettier
- ESLint
- Babel
- 其他工具
# 抽象语法树
抽象语法树是一个非常非常重要,也是一个非常非常常见的知识点,弄清楚抽象语法树有助于我们后面的学习。
上面是抽象语法树呢?当我们遇到一个比较困难的, 感觉难以理解的词的时候,最简单的方式就是拆词,针对抽象语法树我们就可以拆解为三个部分:抽象、语法、树,接下来我们要做的就是针对这三个词注意击破,只要把这三个词搞懂了,那么抽象语法树整体的概念也就能够理解了。
## 树
树实际上是一种数据结构,我们都知道计算机使用来处理数据,处理数据的第一步就是先要将数据存储进去,那么存储数据的方式就有多种多样。
例如举一个现实生活中的例子,比如我们有一个书柜(计算机)放 10 本书(数据),那么我放置着 10 本书的方式是多种多样的,我可以横着放,也可以竖着放,也可以斜着放。
所谓数据结构,实际上就是数据(书)在计算机(书柜)中组织和管理的一种方式,根据不同的场景,使用合适的数据结构能够帮助我们高效的对数据进行访问和操作。
数据结构如果从大类上面去分类的话,可以分为两大类:线性数据结构 和 非线性数据结构
线性数据结构:数据以线性的方式来进行存储,这种结构又被称之为序列,每个数据在序列中最多只有一个前驱和后驱数据,常见的线性的数据结构如下:
- 数组(*Array*):一种连续存储空间中的固定大小的数据项集合。数组将相同类型的元素存储在连续的内存位置中,允许通过索引快速访问元素。
- 链表(*Linked List*):一种由节点组成的线性集合,每个节点包含数据和指向下一个节点的指针。链表允许在不重新分配整个数据结构的情况下插入和删除元素。
- 栈(*Stack*):一种遵循后进先出(*LIFO,Last In First Out*)原则的线性数据结构。在栈中,数据项的添加和移除都在同一端进行,称为栈顶。
- 队列(*Queue*):一种遵循先进先出(*FIFO,First In First Out*)原则的线性数据结构。在队列中,数据项的添加在一端进行(队尾),移除在另一端进行(队头)。
非线性数据结构:数据之间的存储和关系不是线性的,常见的非线性数据结构:
- 树(*Tree*):一种分层结构,由节点组成,其中有一个特殊的节点称为根节点,其余节点按照层级组织。每个节点(除根节点外)都有一个父节点,可以有多个子节点。常见的树结构有二叉树、红黑树、*AVL* 树等。
- 图(*Graph*):一种由顶点(节点)和边组成的数据结构,边连接了顶点。图可以是有向的(边有方向)或无向的(边无方向)。图可用于表示具有复杂关系的数据集合。
没有什么最优秀的数据结构,只有根据你的处理场景最合适的数据结构。
例如数组,它在内存中是一段连续的地址:
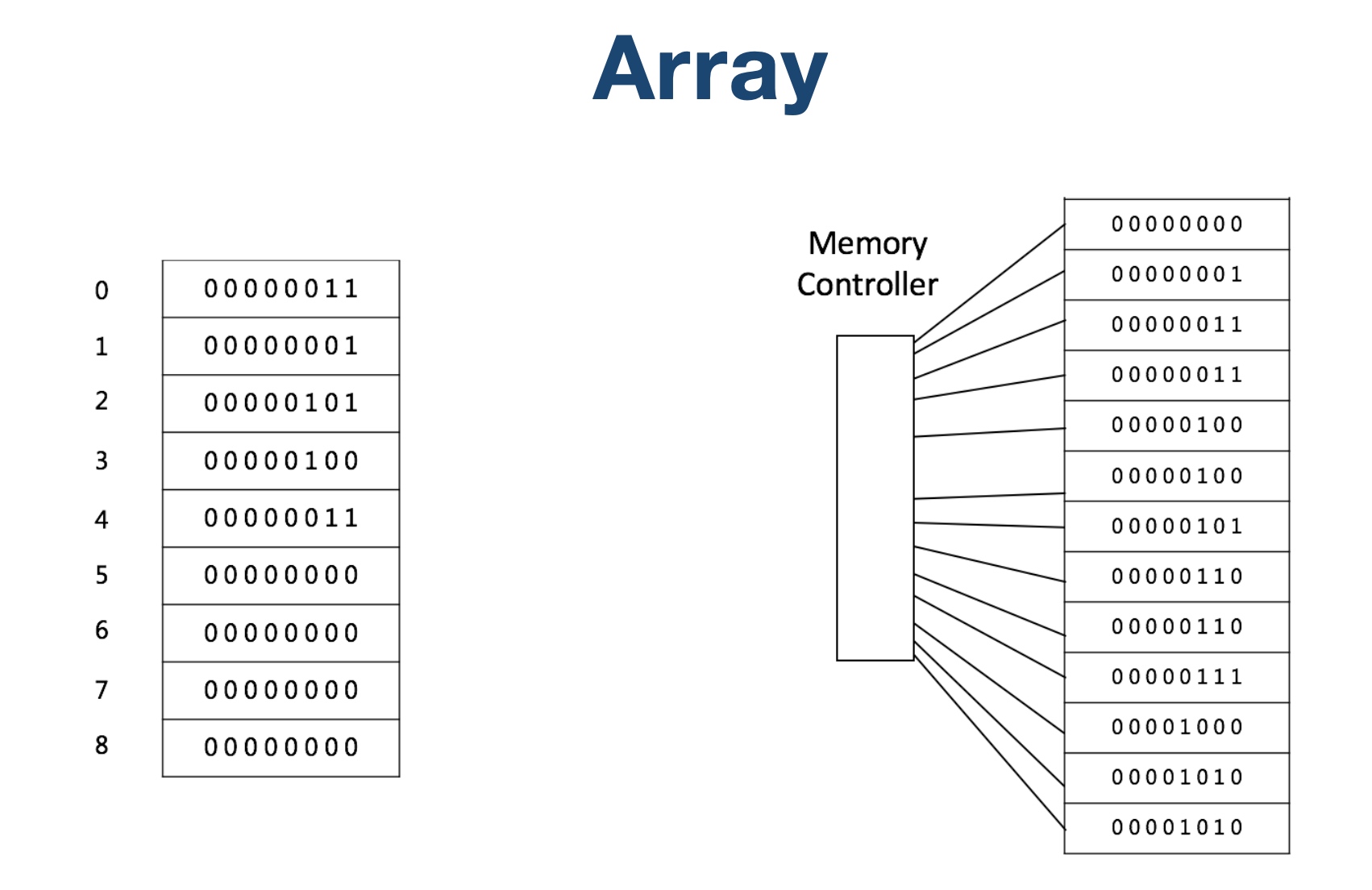
这种数据结构的特点就决定了当我们要查找一个数据的时候就会非常的方便,速度很快,因为只需要指定下表,然后通过内存地址的偏移量就能够查找到该数据。但是当我们要插入或者删除一个数据的时候,要做的工作就比较多了,例如当插入一个数据当中间的时候,需要将插入位置后面的所有元素全部进行后移。
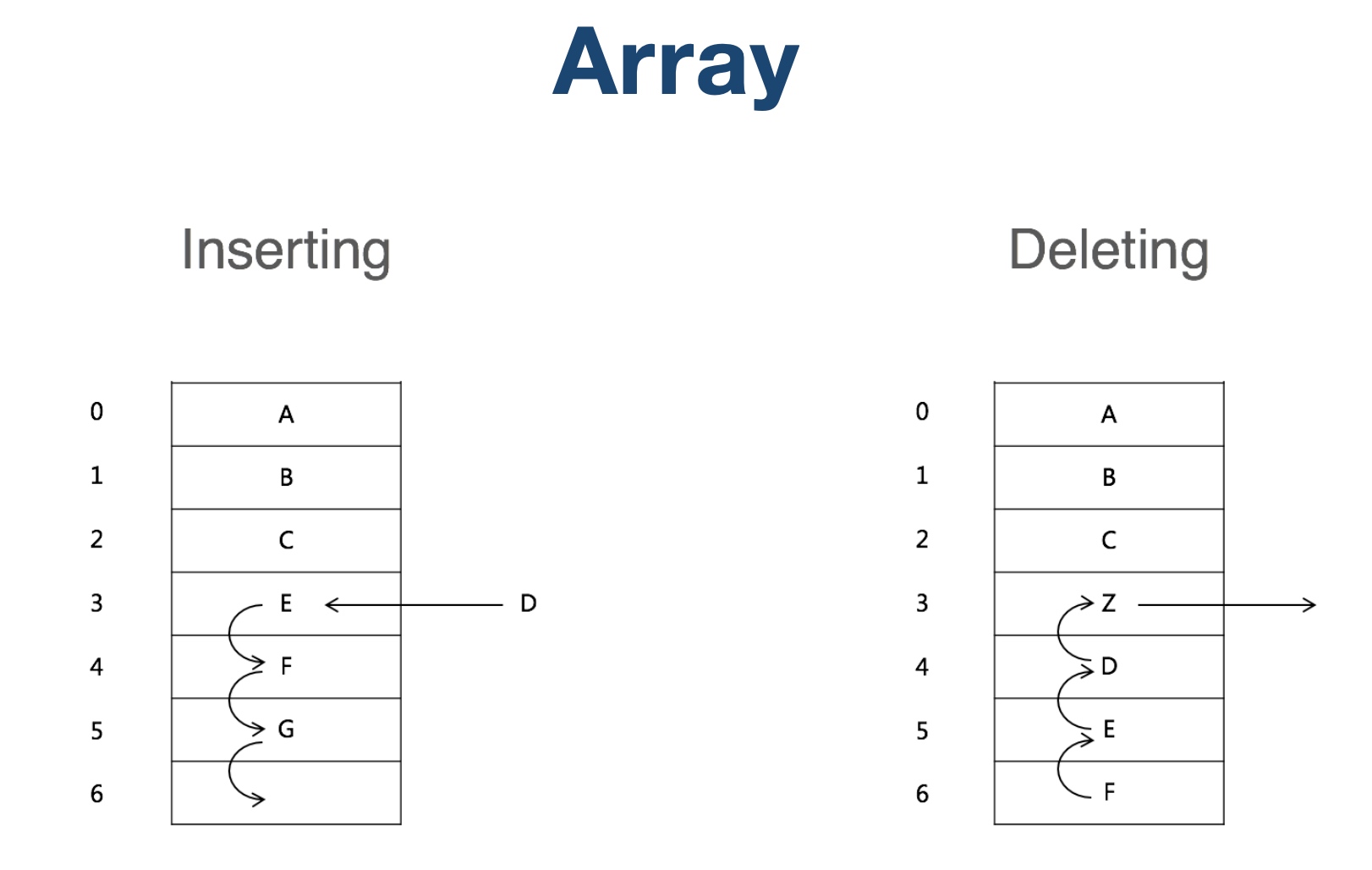
再比如说另外一种线性数据结构链表,它的特点就是在内存中并非连续的存储,而是通过一个 next 字段指向下一个数据的内存地址。
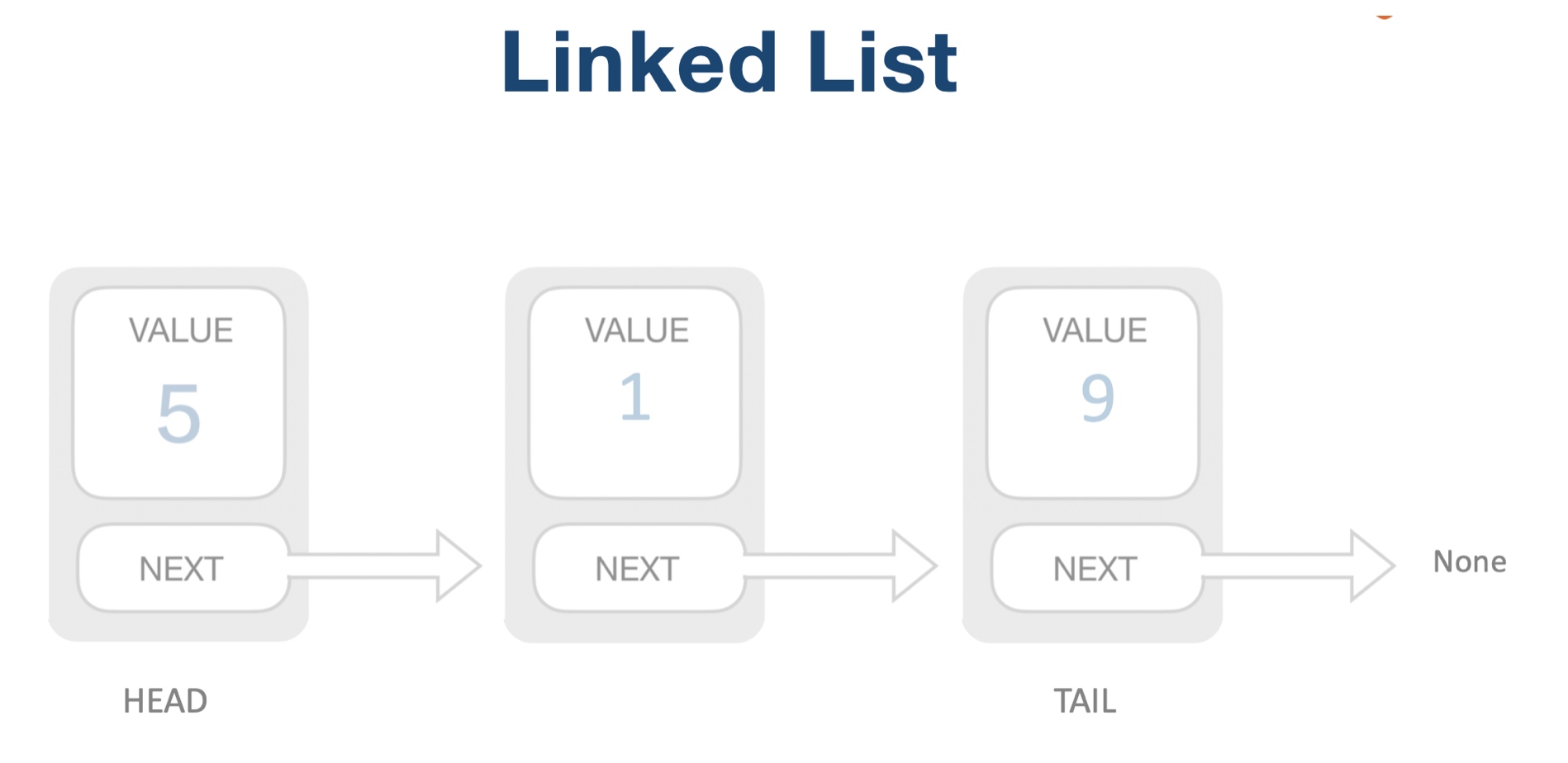
这种数据结构的特点,就决定了链表在插入和删除元素的时候,相比数组会更加高效,例如下面是插入元素的图解:
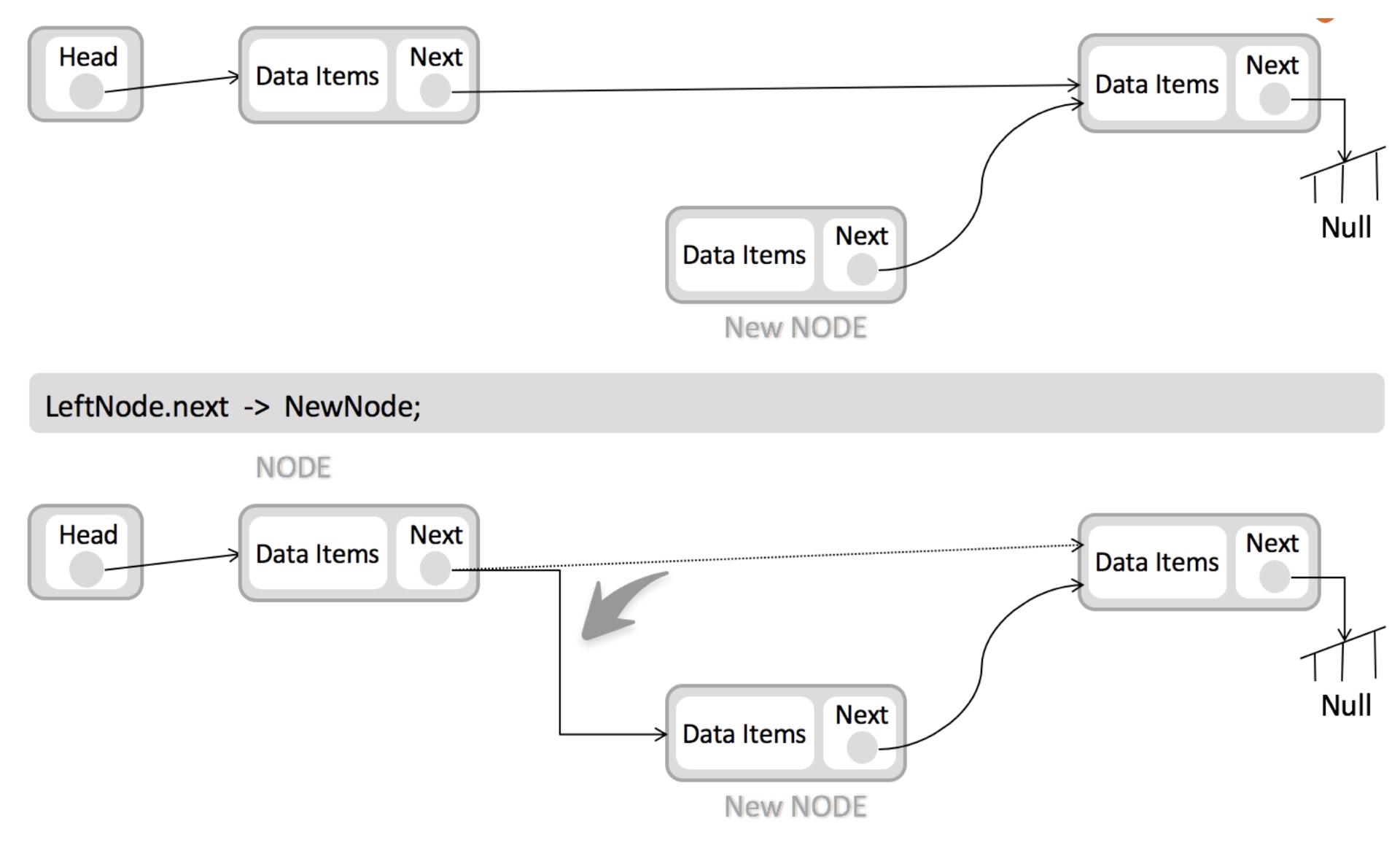
下面是链表删除元素的图解:
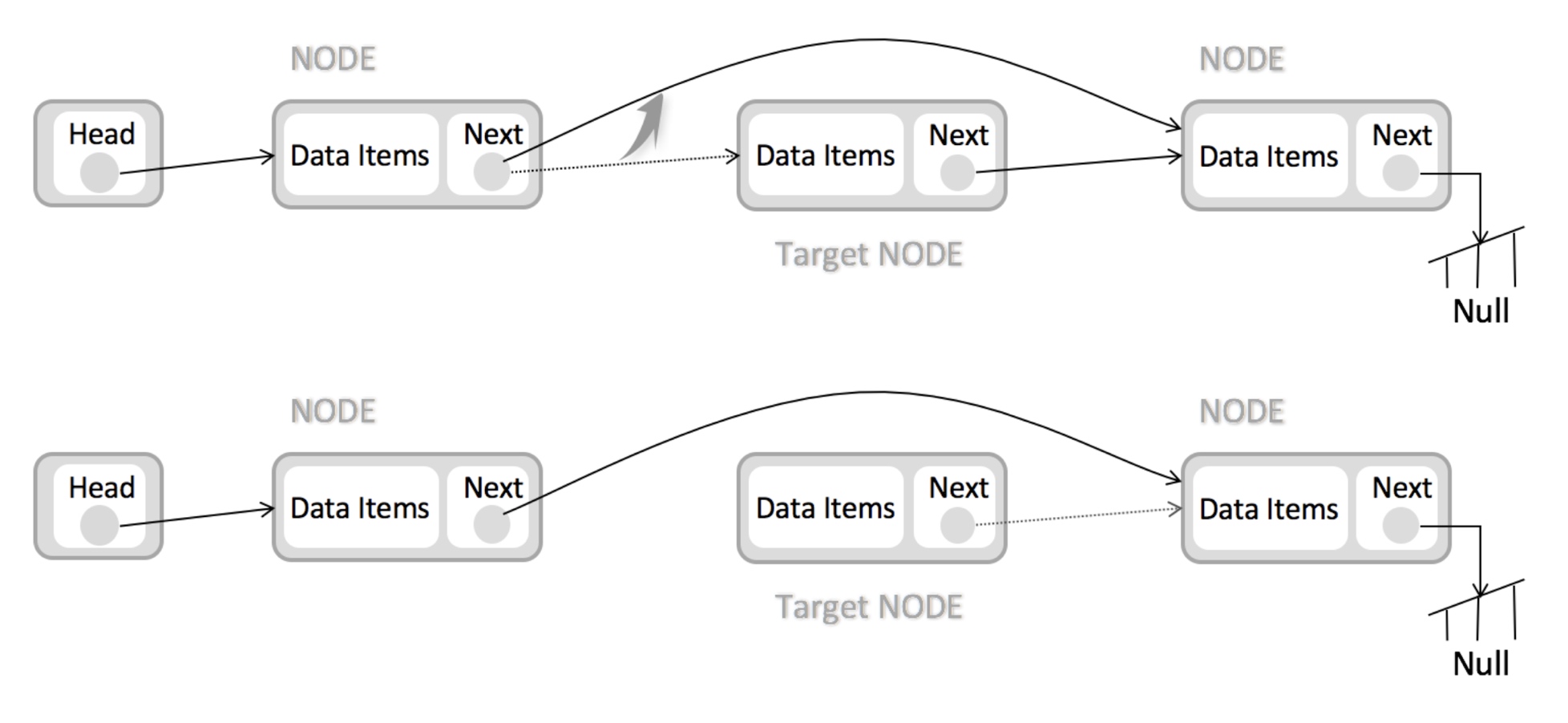
但是链表要去查找元素的效率就比数组要低,需要一个一个的去查询。
因此通过上面的例子,我们可以知道一件事情:没有一种数据结构是完美的,假设有那么一种完美的数据结构,那么其他数据结构就没有存在的意义了。
接下来让我们回到“树”这种数据结构,树这种非线性的数据结构在解决某些问题的时候,具有如下的优点:
1. 层次关系:树结构可以非常自然地表示数据之间的层次关系,如文件系统中的目录结构、组织结构、语法分析树等。通过树结构,可以清晰地展示数据的从属关系和分层结构。
2. 搜索效率:对于某些类型的树(如二叉搜索树、AVL树、红黑树等),在保持某种顺序或平衡条件的情况下,搜索效率比线性数据结构(如链表、数组)要高得多。在平衡二叉搜索树中,搜索、插入和删除操作的时间复杂度通常为 O(log n),其中 n 为树中节点的数量。
3. 动态数据集合:与数组等固定大小的数据结构相比,树结构可以方便地添加、删除和重新组织节点。这使得树结构非常适合用于动态变化的数据集合。
4. 有序存储:在二叉搜索树等有序树结构中,数据按照一定的顺序进行组织。这允许我们在 O(log n) 时间内完成有序数据集合的操作,如查找最大值、最小值和前驱、后继等。
5. 空间优化:在某些应用场景中,树结构可以有效地节省空间。例如,字典树(*Trie*)可以用于存储大量字符串,同时节省空间,因为公共前缀只存储一次。
6. 分治策略:树结构天然地适应分治策略,可以将复杂问题分解为较小的子问题并递归求解。许多高效的算法都基于树结构,如排序算法(归并排序、快速排序)、图算法(最小生成树、最短路径等)。
上面的这些优点,如果你没有系统的学习过数据结构相关的知识,是比较难理解的,但是并不影响我们后面的学习。
目前,你只需要知道“树”是一种数据结构,并“树”这种数据结构有很多的优点即可。正因为“树”这种数据结构有上述的那么些优点,所以你在很多地方都能看到它的身影:DOM树、CSSOM树、Vue模板树、语法树。
## 语法树
什么是语法树呢?简单来讲,就是将我们所写的代码转为树的结构。
假设有如下的代码:
```js
var a = 42;
var b = 5;
function addA(d) {
return a + d;
}
var c = addA(2) + b;
```
对于上面的这段代码,编译器或者解释器是看不懂的,对于它们来讲,就是一段连续的字符串:
```js
'var a = 42;var b = 5;function addA(d) {return a + d;}var c = addA(2) + b;'
```
编译器或者解释器会对上面的代码进行整体的扫描分析,分析出来上面的字符串中哪些是关键字、哪些是标志符,哪些是运算符,形成一个一个的 token(最小的不可再拆分的单位)
例如上面的那一段代码,分析出来的结果如下:
```
Keyword(var) Identifier(a) Punctuator(=) Numeric(42) Punctuator(;) Keyword(var)
Identifier(b) Punctuator(=) Numeric(5) Punctuator(;) Keyword(function)
Identifier(addA) Punctuator(() Identifier(d) Punctuator()) Punctuator({)
Keyword(return) Identifier(a) Punctuator(+) Identifier(d) Punctuator(;)
Punctuator(}) Keyword(var) Identifier(c) Punctuator(=) Identifier(addA)
Punctuator(() Numeric(2) Punctuator()) Punctuator(+) Identifier(b) Punctuator(;)
```
最终,会采用“树”这种数据结构来存储上面的 token 数据,最终形成一颗语法树
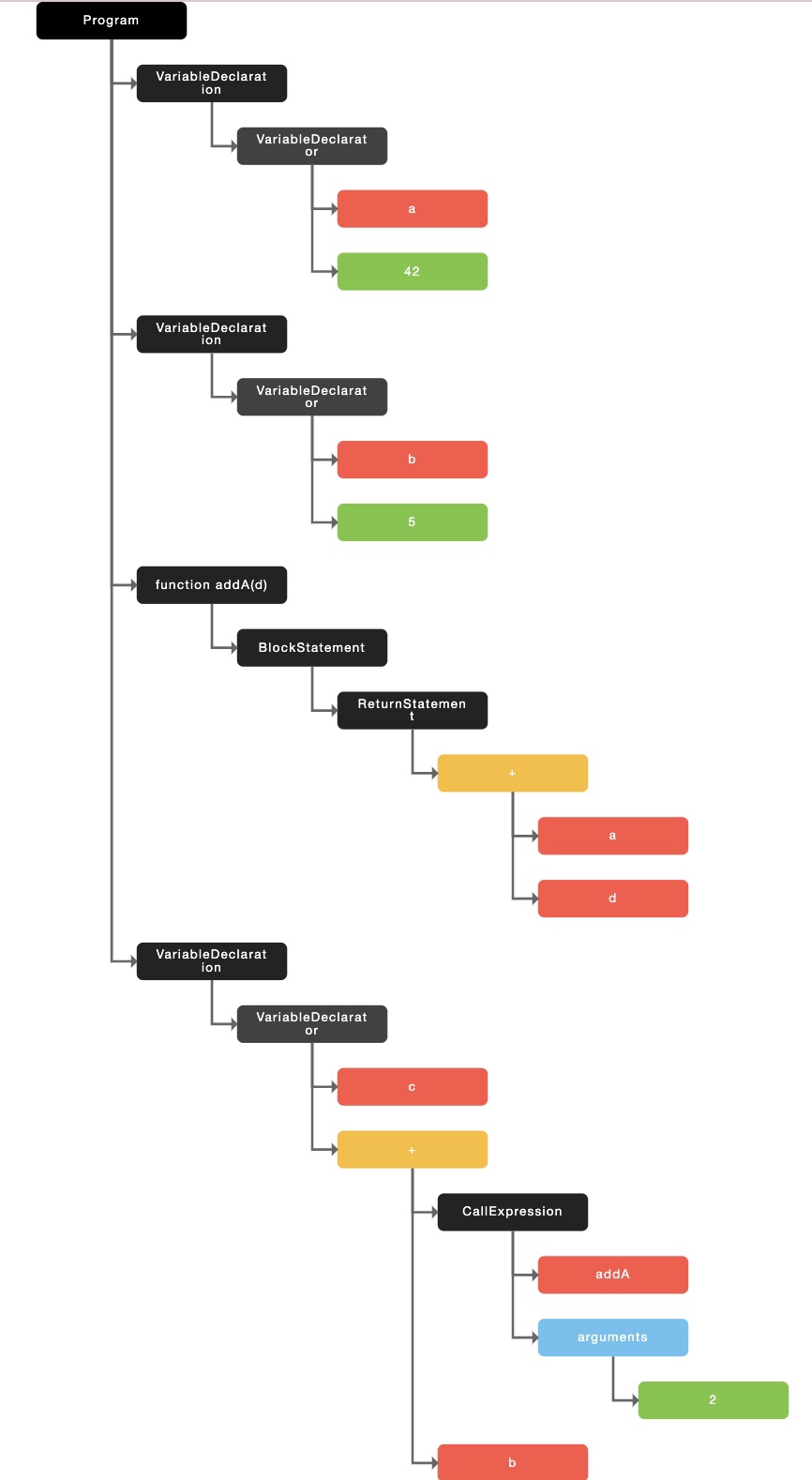
有一个在线的网站,大家可以将自己的源码放上去,能够看到对应源码所生成的语法树:https://www.jointjs.com/demos/abstract-syntax-tree
## 抽象
最后解释一下“抽象”。
需要注意一下,在计算机科学里面的“抽象”这个词和现实生活中“抽象”这个词的含义是不太相同的,现实生活中“抽象”的含义是指“很模糊”的意思。
在计算机科学里面,抽象是一种思维方式,具体指的是从一个具体事物中提取出 本质特征、概念和规律,忽略 不相关的细节。这个实际上是一种非常非常重要的方式,通过这种方式,我们可以将某个复杂的问题分解成更简单的,更纯粹的小问题,从而帮助我们更容易的解决复杂问题。
明白了抽象的概念之后,我们再来看抽象语法树,在将源代码转换为树结构的时候,只会关注代码的结构和语法,会忽略具体的字符、空格、换行这些表达细节,像这些不重要的表达细节,在形成树结构的时候通通会被丢弃掉。
## 抽象语法树
抽象语法树(*Abstract Syntax Tree*,简称 *AST*)是编程语言中一种树形的数据结构,用于表示源代码的语法结构。
在 *AST* 中,每个节点代表源代码中的一个语法元素(如变量、表达式、语句等),并且描述了这些元素之间的层次关系。在从源代码转为语法树的过程中,会采用到抽象的思想,只关注代码的结构和语法,忽略具体的字符、空格、换行等表达细节。通过这种抽象表示,我们可以更方便地理解、分析和操作源代码,而无需直接处理文本格式的代码。
抽象语法树在编译器和解释器设计、代码分析、代码转换等领域具有广泛的应用。使用 *AST* 可以简化代码处理过程,提高代码操作的精确性和可扩展性,并有助于实现高效的代码优化和转换算法。
# Prettier介绍
*Prettier* 是一个代码风格的修正工具。
## 基本介绍
代码风格是所有程序员都要遇到的问题,不管是团队协作还是个人练习。有的喜欢有分号,代码更安全;有的喜欢没分号,能少打一个字符;有的喜欢单引号,能少按一下 *Shift*;有的喜欢反引号,扩展更高;*camelCase*、 *PascalCase*、 *snake_case* 总是在团队里无法统一,就算统一了,有些队员心里也不服,因为代码风格太主观了,根本无法让谁信服谁,每个程序最喜欢看的代码还是自己的代码。
那么有没有一种非常标准且又好看的代码风格来停止这场代码风格的圣战呢?
*Prettier* 这时就出来了。*Prettier* 是一个流行的代码格式化工具,它可以自动调整代码的样式,使其更具可读性和一致性。它支持多种编程语言,包括 *JavaScript、TypeScript、HTML、CSS、SCSS、GraphQL、JSON、Markdown* 等。
*Prettier* 的核心特点包括:
- 一致的代码风格:*Prettier* 可以帮助团队成员统一代码风格,减少代码审查时关于代码格式的讨论。
- 无需配置:*Prettier* 的默认配置就足以满足大多数项目的需求。使用 *Prettier* 时,通常不需要花费时间调整和维护配置文件。
- 集成多种编辑器:*Prettier* 支持许多流行的代码编辑器,如 *Visual Studio Code、Sublime Text、Atom* 等都有相应的插件,可以在编写代码时自动运行 *Prettier*。
- 可配置性:虽然 *Prettier* 默认配置通常已经足够,但它仍支持自定义配置。你可以在项目根目录下创建一个 .*prettierrc* 文件,根据项目需求调整格式化选项。
- 自动格式化:*Prettier* 可以自动格式化文件,无需手动调整代码格式。
- 支持多种语言:*Prettier* 支持多种编程语言和文件格式,提供广泛的适用性。
*Prettier* 官网:*https://prettier.io/*
*Prettier* 的诞生让代码风格得到了统一:我格式化后的代码是最好看的,谁同意,谁反对?

“我反对!凭什么你说最好看就是最好看?”

就凭你不会写论文!

其实在很早之前已经有人开始研究哪种方式来格式化长文本是最好的(*Prettier Printer*),比如 *Philip Wadler* 在 《*[A prettier printer](https://homepages.inf.ed.ac.uk/wadler/papers/prettier/prettier.pdf)*》这里给出了一些自动格式化换行的理论依据。
>*A good pretty printer must strike a balance between ease of use, flexibility of format, and optimality of output.*
*Prettier* 的作者 *James* 在这篇论文基础上再完善了一些代码风格规则,最终成为了 *Prettier* 格式化代码的最终方案。比如像下面的链式调用,*Prettier* 输出的就比原来论文描述的要好看一些:
```js
// 原版 "A prettier printer" 的实现
hello().then(() => {
something()
}).catch(console.error)
// Prettier 的实现
hello()
.then(() => {
something()
})
.catch(console.error)
```
## 工作原理
那么,*Prettier* 是如何能够做到代码的格式化的呢?
首先,*Prettier* 会把代码转换成 *AST* (*Abstract Syntax Tree*),这里用到的是一个叫 *[Recast](https://github.com/benjamn/recast)* 的库,而 *Recast* 实际上也用了 *[Esprima](https://github.com/jquery/esprima)* 来解析 ES6。
>*Esprima can be used to perform lexical analysis (tokenization) or syntactic analysis (parsing) of a JavaScript program.*
>
>*A simple example on Node.js REPL*:
>```js
>> var esprima = require('esprima');
>> var program = 'const answer = 42';
>> esprima.tokenize(program);
>> [ { type: 'Keyword', value: 'const' },
> { type: 'Identifier', value: 'answer' },
> { type: 'Punctuator', value: '=' },
> { type: 'Numeric', value: '42' } ]
>> esprima.parseScript(program);
>> { type: 'Program',
> body:
> [ { type: 'VariableDeclaration',
> declarations: [Object],
> kind: 'const' } ],
> sourceType: 'script' }
>```
所以无论之前的代码怎么乱,怎么屎,*Prettier* 都抹掉之前的所有样式,抽成最本质的语法树。
然后再用 *Prettier* 的代码风格规则来输出格式化后的代码。
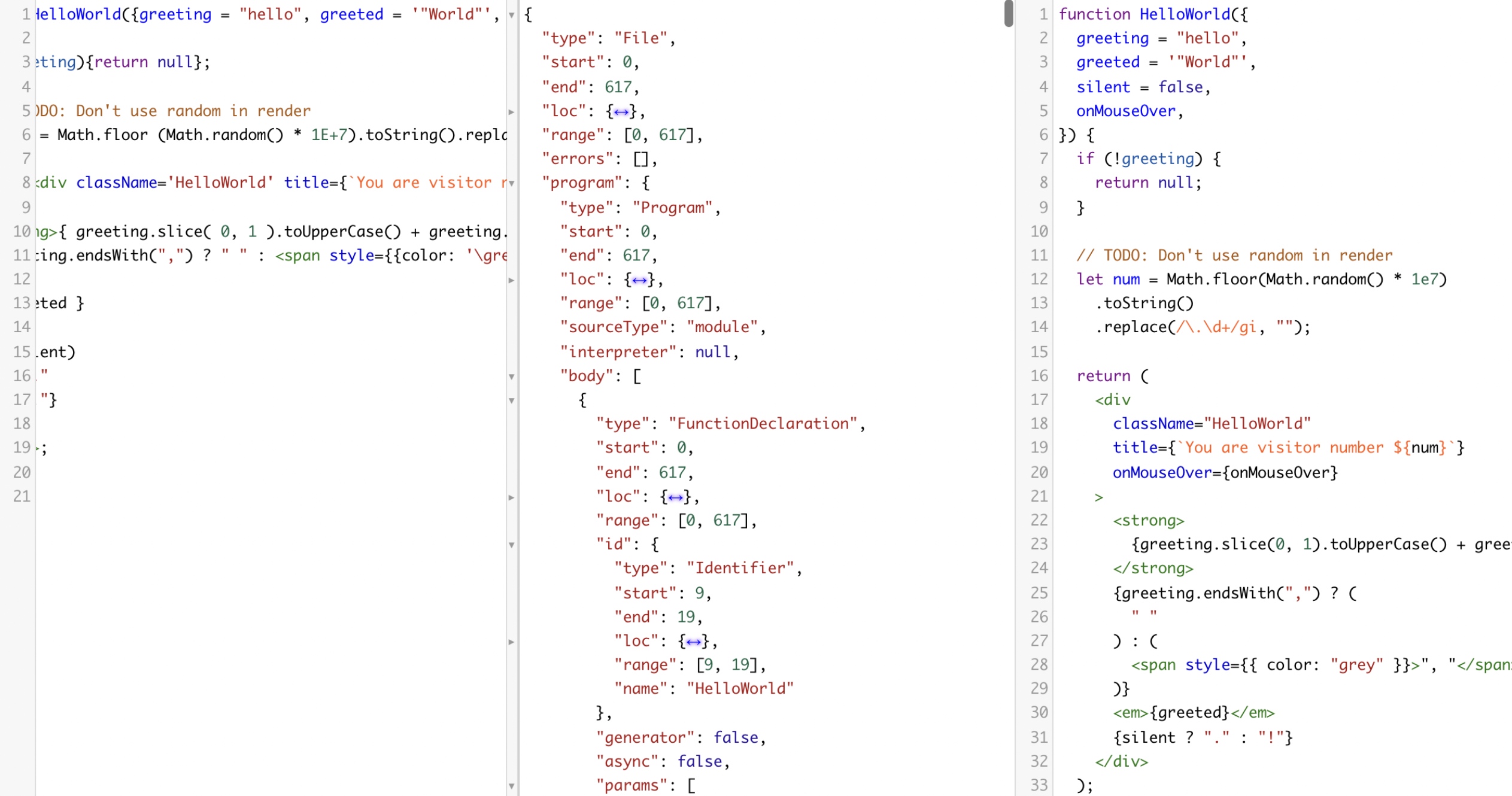
*Prettier* 能够支持的格式化语言是多种多样的,并非仅仅只为 *JS* 服务:
理论上来讲,只要把一门语言的代码抽象为语法树,然后再有对应的格式化规则,那么无论什么语言都是可以的。
*Prettier* 官方以及社区就提供了一些插件,通过使用插件,你可以让 *Prettier* 格式化更多种类的代码,添加对新语言和文件类型的支持。*Prettier* 插件通常是单独的 *npm* 包,你需要安装它们作为项目的依赖。插件的名称通常遵循 *prettier*-*plugin*-* 的命名规范。安装插件后,*Prettier* 会自动发现并使用它们。
以下是一些常见的 *Prettier* 插件示例:
- *prettier-plugin-svelte*:这个插件为 *Svelte* 组件提供了格式化支持。安装这个插件后,你可以使用 *Prettier* 格式化 *Svelte* 文件。
- *prettier-plugin-toml*:这个插件为 *TOML* 配置文件提供了格式化支持。安装这个插件后,你可以使用 *Prettier* 格式化 *TOML* 文件。
- *prettier-plugin-java*:这个插件为 *Java* 语言提供了格式化支持。安装这个插件后,你可以使用 *Prettier* 格式化 *Java* 文件。
- *prettier-plugin-php*:这个插件为 *PHP* 语言提供了格式化支持。安装这个插件后,你可以使用 *Prettier* 格式化 *PHP* 文件。
另外,*Prettier* 的官方文档里一直在强调自己是一个 *Opinionated* 的工具,这里想展开跟大家聊聊 *Opinionated*。
其实不仅 *Prettier*,我们日常使用的一些库和框架都会标明自己是 *opinionated* 还是 *unopinionated*:


按照框架/库的 *opinionated* 还是 *unopinionated* 思路来使用它们非常重要。
*Opinionated* 的思路是 你的一切我全包了,使用者就别自己发明设计模式和轮子,用我的就行,有锅我背。
*Unopinionated* 的思路则是 我就给你一堆零件,每个有优有劣,自己组装来玩了,相当于每人都是装机猿。
*Prettier* 属于 *Opinionated* 哲学,这意味着它提供的代码风格已经是最优的,不希望使用者做太多自定义的内容,而应该相信 *Prettier* 已经服务到位了。
## 快速上手
新建一个项目目录 prettier-demo,使用 pnpm init 进行一个项目初始化,安装 prettier
```bash
pnpm add --save-dev --save-exact prettier
```
--save-exact 表示在安装 prettier 的时候在 package.json 里面记录具体的版本号。
接下来可以书写一些需要格式化的代码:
```js
const str = "Helo World";
const arr = [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30];
const obj = {
name: "John Doe",
age: 30,
address: {
city: "New York",
state: "NY"
}
}
```
然后在 package.json 里面添加命令行脚本
```js
"scripts": {
// ...
"format": "prettier --write ."
},
```
之后就可以使用 pnpm format 这条命令来进行格式化代码操作。
如果想要自定义规则,可以在项目根目录下面创建一个 .prettierrc,之后使用对象的形式写入自定义规则即可:
```js
{
"singleQuote": true,
"semi": false,
"printWidth": 80,
"trailingComma": "es5"
}
```
- singleQuote:单引号
- semi:语句末尾是否添加分号
- printWidth:一行的最长长度
- trailingComma:对象或者数组字面量中的最后一个元素是否添加逗号
关于更多的规则,在下一节课会进行介绍。
我们也可以通过安装 vscode 插件的方式来使用 prettier。使用脚本命令和使用 vscode 插件两者之间的差别如下:
- 实时性:使用 *Prettier* 的 vscode 插件,你可以在编写代码时立即看到格式化效果,而不需要等待执行脚本命令。这有助于在编写代码时就保持良好的代码风格。
- 范围:通过运行脚本命令 "*prettier --write .*",你可以一次性格式化整个项目中的所有文件。而 *Prettier* 插件只会在你需要时(如保存文件)格式化当前打开的文件。
专栏所有代码地址:https://github.com/Sunny-117/js-toochain-book
# 命令行工具
在最初的时候,我们在 pacakge.json 里面做了一个命令行的配置:
```js
"scripts": {
//...
"format": "prettier --write ."
},
```
关于 prettier 究竟支持哪些 CLI 命令,我们可以在官网中看到:https://prettier.io/docs/en/cli.html
关于 CLI 命令有一个最基本的格式:
```js
prettier [options] [file/dir/glob ...]
```
- options: 格式化的选项
- file/dir/glob:要格式化的文件或者目录
接下来我们来看一下在第一节课写的命令:
prettier --write .
- --write 就是配置选项,本来 prettier 格式化完成后是在控制台输出的, --write 代表写入到原本的文件,--write 还有一个别名就是 -w
- . 是第二个参数,代表的是要格式化的路径,正常情况下你可以写一个文件或者写一个目录,例如
```bash
prettier --write file.js # 只格式化 file.js 这个文件
prettier -w "src/**/*.js" # 格式化 src 目录下面的所有的 js 文件(包含 src 下面的子目录)
```
上面的 . 表示当前目录以及子目录下所有支持的文件,全部格式化之后写回原来的文件。
接下来介绍一些常见的 options
- --check:该配置参数用于检查文件是否已经按照 prettier 规则进行了格式化,如果匹配的路径下面的所支持的文件已经全部被格式化,那么会输出 *All matched files use Prettier code style!*,否则会显示哪些文件还没有被 prettier 格式化
- `--find-config-path` and --config:指定配置文件的路径,正常情况下,prettier 会自动去找项目下面的配置文件。但是如果你的配置文件不在项目中,而是在其他的位置,那么这个也是可以指定的
```bash
prettier --config ~/configs/prettier.json --write .
```
- --no-config: 不读取任何配置文件,直接使用 prettier 里面默认的配置。
- --ignore-path:指定忽略文件的路径,正常情况下也是在当前项目中去寻找,但是如果你的忽略文件不在项目中,而是在其他位置,也是可以指定的
```bash
prettier --ignore-path ~/configs/ignore/.prettierignore --write .
```
- 规则的配置:上一节课介绍了的 prettier 所有的规则都可以在 CLI 命令里面进行配置的。不过这种只适用于单独的一两个规则,如果你的规则比较多还是应该单独拿一个配置文件来配置规则。
# Eslint
# Linter介绍
从这一章我们进入到 *ESLint* 的学习。
## *linter* 发展史
首先和大家来聊一聊关于 *linter* 的发展史。
### 静态代码分析
早在 *1978* 年,*Stephen C. Johnson* 在 *Debug* 自己的 *C* 语言项目时,突然想到为什么不做一个工具来提示自己写的代码哪里有问题呢? 这个工具也被称为 *Linter*。
*Linter* 本意指的是衣服上多出来的小球、绒毛和纤维等,如果你刚把晾晒好的衣服收下来就会发现这些小玩意。以前如果想把这些多出来的“残渣”去掉,最简单的方法就是找一个单面胶粘一下再撕开,后来有的人发明了这个神器,一滚就能清除掉:

这就是 *Linter* 的由来,不过区别是神器重点在 “清除”,而 *Linter* 重点在 “上报错误”。
*Linter* 想要提示错误,那首先就得阅读代码,这也是为什么 *Linter* 也被称为静态代码分析的工具。阅读完之后,再加上我们人为自定义好的一些规则,那么 *Linter* 就拥有了提示错误的能力了。
### *JSLint*
在 *2002* 年,*Douglas Crockfor*d 就为 *JavaScript* 写了第一个 *Linter* 工具:*JSLint*。

你现在也可以在[这个网站](https://www.jslint.com/)上粘贴你的 *JavaScript* 代码来检查有没有问题。
*JSLint* 的优点就是 开箱即用,不需要配置太多的东西,相当于拎包入住。但优点也是缺点,就是 规则太严格,完全不可扩展和自定义配置,连配置文件都没有。
### *JSHint*
在 *JSLint* 的基础上,在 *2010* 年的时候 *Anton Kovalyov* 跟其它人就 *fork* 了一份 *JSLint* 然后改造成了 *JSHint*。
你可以在[这个网站](https://jshint.com/)访问到 *JSHint*

这个工具与 *JSLint* 的思路正好相反,它的默认规则非常松散,自由度非常高。但是也同样带来了问题:你需要非常了解这些规则才能配出一个好用的规则表。因为规则太不严格,过于自由,所以单纯靠默认的规则跟没有配置 *Linter* 一样。
### *JSCS*
前面的 *JSLint* 和 *JSHint* 主要功能都是检查代码质量问题的,*JSCS* (*JavaScript Coding Style*) 则是一个代码风格检查器。
它有超过 *90* 条规则,你也能自己创建规则,不过这些规则主要是和代码风格、代码格式化有关,它不会报任何和 *JS* 代码质量相关的错误。
尽管 *JSCS* 在其活跃时期非常受欢迎,但它已于 *2016* 年被宣布停止维护,并建议用户迁移到 *ESLint*。*ESLint* 是一个更强大、更灵活的工具,它不仅可以检查代码风格,还可以发现潜在的错误和代码质量问题。另一个流行的代码格式化工具是 *Prettier*,它专注于自动格式化代码,而不提供任何代码质量检查。
虽然 *JSCS* 不再被维护,但它的一些功能和理念已经被 *ESLint* 和 *Prettier* 等现代工具所采纳。如果你正在寻找一个代码风格检查器和格式化器,建议使用 *ESLint* 和 *Prettier* 来替代 JSCS。这两个工具可以很好地协同工作,*ESLint* 负责检查代码质量,而 *Prettier* 负责自动格式化。
### *ESLint*
接下来就是我们的主角 *ESLint* 了。
*2013* 年,一个叫 *JSChecker* 的小项目被改名成我们如今非常熟悉的 *ESLint*。
*ES6* 上线了之后,*JSHint* 受不了直接投降了,因为它不支持这些 *ES6* 新语法。而 *ESLint* 正好异军突起,马上用 *Esprima* (一个高性能的 *ECMAScript parser*)支持所有 *ES6* 新语法,并对新语法做好了校验。
除了基础的 *ES6* 代码质量校验,*ESLint* 还支持代码风格的规则。开发者不仅可以自定义项目要用哪些规则,也能直接无脑使用社区上制定的规则(比如 *eslint-config-airbnb*)。
这一波操作也让 *ESLint* 成为现在 *JavaScript* 的一个标准的 *Linter* 了。然而,关于 *Linter* 的故事还没结束。
*2012* 年微软公布了第一版的 *TypeScript*,随之而来的还有一个叫 *TSLint* 的 *Linter*。
在那段时间里,*TSLint* 是 *TypeScript* 的标准 *Linter* 工具,*ESLint* 则为 *JavaScript* 标准 *Linter*。它们各有自身特色:*ESLint* 有 *TSLint* 所没有的一些语法特性支持,而 *TSLint* 可以对代码进行静态分析和类型检查。
可是,一份代码还要两个 *Linter* 并行检查属实有点让人不爽。*TSLint* 也经常和 *ESLint* 的人探讨应该用哪个作为主力 *Linter*。*TS* 的社区也有很多声音希望优先满足 *JSer* 的需求,毕竟 *TS* 是 *JS* 的超集嘛,还是以 *ESLint* 为主。
最终,在 *2019* 年 *TSLint* 宣告不再维护,以后就是 *ESLint* 的天下了。
## *ESLint* 核心概念
接下来我们来了解一下 *ESLint* 的核心概念,这个部分很重要,因为我们后期的学习就是围绕着这几个方面展开的。
*ESLint* 的核心概念包括以下几点:
1. 规则 (*Rules*):规则是 *ESLint* 的核心,它们是独立的脚本,用于检查代码中的特定问题。*ESLint* 有许多内置规则,这些规则可以覆盖各种编码风格和潜在错误。规则是可配置的,每个规则可以被启用或禁用,并可以设置为警告或错误级别。
2. 配置 (*Configuration*):*ESLint* 允许通过配置文件自定义规则的启用和设置。配置文件可以是 .*eslintrc*.* 格式的文件或 *package.json* 文件里的 *eslintConfig* 字段。配置可以继承其他配置,这使得可以轻松地共享和组合规则集。共享配置通常是一个 *npm* 包,可以被多个项目使用。
3. 插件 (*Plugins*):插件是可扩展 *ESLint* 功能的方式,它们包含一组自定义规则和/或处理器(见下文)。这使得 *ESLint* 可以适应不同的编码风格和技术栈。插件可以通过 *npm* 安装并在配置文件中引用。
4. 处理器 (*Processors*):处理器是一个可选的插件特性,它可以对非 *JavaScript* 文件进行预处理,以便 *ESLint* 可以检查这些文件中嵌入的 *JavaScript* 代码。例如,*HTML* 文件中的 \<*script*> 标签或 *Markdown* 文件中的代码块。
5. 命令行接口 (*CLI*):*ESLint* 提供了一个命令行接口,用于在终端中执行 *linting* 操作。*CLI* 允许用户指定一个或多个文件、目录或 *glob* 模式以进行检查。*CLI* 还支持许多选项,这些选项可以覆盖配置文件中的设置,如禁用特定规则、规定输出格式等。
## ESLint 快速上手
首先创建一个 eslint-demo 的项目,使用 pnpm init 进行格式化,安装 eslint
```bash
pnpm add eslint -D
```
接下来在项目根目录下面创建一个 src/index.js,代码如下:
```js
const hello = "world";
console.log(hello);
function sayHello(name) {
console.log("Hello, " + name + "!");
}
sayHello("world");
```
上面随便写了一些代码,接下来在项目根目录下面创建一个 eslint 的配置文件 .eslintrc,里面会书写一些配置信息:
```js
{
"env": {
"browser": true,
"es2021": true
},
"extends": "eslint:recommended",
"parserOptions": {
"ecmaVersion": 12,
"sourceType": "module"
},
"rules": {
"indent": ["error", 2],
"quotes": ["error", "single"],
"semi": ["error", "always"]
}
}
```
- env:主要是定义预设的全局变量
- browser:这份配置适用于浏览器环境,预定义了诸如 window、document 之类的浏览器才会有的全局变量
- es2021: 表示我们使用的是 ES 2021 的标准,肯定会预定义一些新版本的全局变量,Promise、Symbol 这些全局变量是支持的
- extends:这里我们所设置的值为 eslint:recommended,这其实是 ESLint 团队推荐的一组核心规则,你可以将其视为最佳实践
- parserOptions:和解析器相关的配置
- ecmaVersion:使用的 ECMAScript 的版本,12 也就是 2021
- sourceType:模块类型,这里设置为 module,表示我们使用的 ESM 模块规则,支持 import 和 export 语法
- rules:定义代码风格,功能类似于 prettier
- indent:缩进,我们这里设置的是两个空格,如果不符合要求,会报 error 类型的错误
- quotes:引号的设置,这里我们设置的是单引号,如果不符合要求,会报 error 类型的错误
- semi:每一条语句添加分号,如果不符合要求,会报 error 类型的错误
最后修改 package.json,添加如下的 script 脚本命令:
```js
"scripts": {
// ...
"lint": "eslint ."
},
```
上面的脚本命令表示对当前项目所有的 js 文件进行 lint 检查。
使用 ESlint 进行代码检查的时候,是支持自动修复的,但是并非所有的错误都能够自动修复,只能够修复一部分。
要自动进行修复,只需要添加命令行参数 --fix 即可
```js
"scripts": {
// ...
"lint": "eslint --fix ."
},
```
# 检查规则
这节课我们主要学习 ESLint 里面的规则相关的知识。规则是 ESLint 中一个比较重要的核心概念之一,因为究竟报不报错,是由规则来确定的。
## 规则的重要性
在 ESLint 中,本身可以配置规则的重要性,总共分为三个级别:
- off 或者 0: 关闭这条规则
- warn 或者 1:这条规则的级别为警告级别
- error 或者 2:这条规则的级别为错误级别
例如:
```js
{
"rules": {
"no-undef": "error",
"semi": ["warn", "always"]
}
}
```
在上面的规则配置中,semi 对应的值为一个数组,数组的第一项是上面所说的规则重要性,第二项则是该条规则配置可选项,关于这个配置可选项,不同的规则能够填入的值是不一样的。关于具体能够填写的值,那么就要去这条规则的说明页面去查阅。
接下来我们就针对 semi 这条规则做一个介绍,semi 可配置值如下:
- always:这是默认值,代表语句结束需要插入分号
- never: 在没有 ASI 风险情况下,不需要插入分号
ASI 英语全称叫做 automatic semicolon insertion,这个翻译成中文就是自动分号插入。所谓 ASI 风险,是指由于有这个机制,可能会导致意外的行为或者错误。
```js
function example() {
return
{
message: 'Hello, world!'
}
}
```
在上面的代码中,我们本意是要返回一个对象,但是由于 ASI 机制,这里就会产生意外的行为,导致这个函数返回一个 undefined 而非预期的对象。
如果值为 always,那么还可以配置一个额外的对象:
- omitLastInOneLineBlock:配置为 true,表示禁止在单行代码块中的最后一个语句使用分号
- omitLastInOneLineClassBody:配置为 true,表示禁止在单行类里面的最后一个语句使用分号
如果值为 never,那么也是可以配置一个额外的名为 beforeStatementContinuationChars 的对象:
- "*beforeStatementContinuationChars*": "*any*"(默认):如果下一行以[, (, /, +, 或 -]开始,则忽略语句末尾的分号(或缺少分号)
```js
let a = 1
+1 // 正确:分号被忽略
let b = 2
;+2 // 正确:分号也可以
```
- "*beforeStatementContinuationChars*": "*always*":如果下一行以[, (, /, +, 或 -]开始,则要求在语句末尾使用分号
```js
let a = 1
+1 // 错误:要求在语句末尾使用分号
let b = 2
;+2 // 正确:添加了分号
```
- "*beforeStatementContinuationChars*": "*never*":即使下一行以[, (, /, +, 或 -]开始,只要没有引起 *ASI*(*Automatic Semicolon Insertion*,自动分号插入)的风险,也禁止在语句末尾使用分号
```js
let a = 1
+1 // 正确:没有 ASI 风险,不需要分号
let b = 2
;+2 // 错误:不允许在没有 ASI 风险的情况下使用分号
```
## 规则注释
在具体的代码文件里面,可以以注释的方式来配置规则
```js
/* eslint eqeqeq: "off", curly: "error" */
/* eslint eqeqeq: 0, curly: 2 */
/* eslint quotes: ["error", "double"], curly: 2 */
```
规则注释的优先级会高于配置文件里面的规则。
一般在如下的场景中可能会涉及到使用注释规则:
1. 针对特定的文件或者代码片段需要指定特殊规则,比如我们针对某一个代码片段去禁用 ESLint 检查
```js
/* eslint-disable */
console.log('Hello')
/* eslint-enable */
```
或者只禁用某一个规则
```js
/* eslint-disable semi */
console.log("Hello");
/* eslint-enable semi */
```
2. 指定某个文件的特殊配置,有时我们需要针对某个文件指定和其他文件不同的 ESLint 配置,这种情况下也可以使用注释的形式,这样就不需要去修改主要的配置文件
```js
/* eslint-env node, mocha */
```
在上面的注释汇总,我们声明 ESLint 的检查环境为 node 和 mocha,这就意味着在检查该文件的时候,ESLint 会预设一些 node 和 mocha 中的全局变量,比如 process、describe、it。
3. 临时禁用某条规则
```js
// eslint-disable-next-line no-unused-vars
const tempVariable = 'Temporarily not used';
```
在上面的注释中,我们使用了 eslint-disable-next-line,代表只禁用下一行的代码检查,后面跟上了具体的规则,表示禁用下一行代码的某一条规则的检查,不影响之后的代码。
另外在配置文件中,有如下的配置选项:
- noInlineConfig:禁止行内注释形式的规则
- reportUnusedDisableDirectives:用于是否报告有未使用的 eslint-disable 指令
例如:
```js
/* eslint-disable-next-line no-console */
console.log('Hello');
```
上面的代码是可以正常工作的,eslint-disable-next-line no-console 这条行内注释规则是有用的,但是如果我们把下面的 console 注释调用:
```js
/* eslint-disable-next-line no-console */
// console.log('Hello');
```
那么上面的这一条行内注释规则就变成了一条无用的注释规则
更多关于行内注释规则,可以参阅官网资料:https://eslint.org/docs/latest/use/configure/rules#using-configuration-comments
## 规则参照表
你可以在 https://eslint.org/docs/latest/rules/ 看到 ESLint 里面的所有规则
在官方的规则参照表中,每一条规则后面有三个符号,对应的含义如下:
| ✅ | 🔧 | 💡 |
| ------------------------------------------------------------ | --------------------------------------------------- | ------------------------------------------------ |
| 在配置文件中的 "*extends*": "*eslint*:*recommended*" 属性会启用此规则。 | 此规则报告的一些问题可以通过 --*fix* 参数自动修复。 | 此规则报告的一些问题可以通过编辑器建议手动修复。 |
# 配置文件
# 配置文件 part1
首先需要注意,配置文件系统处于一个更新期,存在两套配置文件系统,旧的配置文件系统适用于 v9.0.0 之前的版本,而新的配置文件系统适用于 v9.0.0之后的版本,但是目前,还处于 v8.x.x 的大版本。
## 配置文件格式
在 ESLint 中,支持如下格式的配置文件:
- JavaScript:使用 .eslintrc.js 并且导出一个包含你配置的对象
- JavaScript(ESM):在 v9.0.0 之前 ESLint 是不支持 ESM 风格模块化的,假设我们的源码使用的 ESM 模块化风格,并且我们在 pacakge.json 中明确配置了 type: module,这个时候就需要将 ESLint 的配置文件命名为 .eslintrc.cjs(也就是说要使用 CommonJS 风格来命令 ESLint 的配置文件)
- YAML:使用 .eslintrc.yaml 或者 .eslintrc.yml
- JSON:使用 .eslintrc.json 来配置 ESLint
- package.json:在 pacakge.json 中,可以创建一个名为 eslintConfig 的属性,然后对 ESLint 进行配置
如果在项目的同一目录下存在多种格式的配置文件,那么这些配置文件之间是有一个优先级顺序的。顺序如下:
1. `.eslintrc.js`
2. `.eslintrc.cjs`
3. `.eslintrc.yaml`
4. `.eslintrc.yml`
5. `.eslintrc.json`
6. `package.json`
在早期的时候(v7.0.0之前),ESLint 支持使用 .eslintrc 文件来作为 ESLint 的配置文件,但是从 v7.0.0 开始,官方就已经明确废弃掉这种用法,从 v7.0.0 之后,就建议使用上述的格式来作为 ESLint 的配置文件。但是为了兼容性,之前的 .eslintrc 格式的配置文件依然能够使用,但是还是建议最好使用官方推荐的格式来进行配置。
## 使用配置文件
想让我们的配置文件生效,有两种方式:
- 在项目中创建上述的配置文件,ESLint 在做检查的时候会自动寻找配置文件并应用里面的配置
- 在 CLI 命令中通过 --config 选项来手动指定配置文件的位置
```js
eslint -c myconfig.json myfiletotest.js
```
## 配置文件的层叠
在 ESLint 中支持配置文件的层叠,这是一种管理项目中多个配置文件的方式,这种特性允许你在项目中根据不同的部分应用不同的规则。
例如我们在 src/.eslintrc.js 中,有如下的配置:
```js
module.exports = {
env: {
browser: true,
es2021: true,
node: true
},
rules: {
semi: ['error', 'always']
}
};
```
那么现在,我们就存在两份 ESLint 的配置,此时 ESLint 会在当前目录下查找配置文件,然后会一层一层往上寻找,将找到的所有的配置文件进行一个规则合并。
如果子目录下配置文件的规则和父目录下的配置文件规则发生重合,那么子目录下的配置文件规则会覆盖父目录下配置文件的同名规则。
如果我们需要就应用当前目录的配置文件,不要再往上找了,那么可以在当前的配置文件中添加一个 root:true,添加了此配置项后,表示就应用当前目录下找到的配置文件,停止继续往上搜索。
目前我们知道,要对 ESLint 进行配置有多种方式:
- 配置文件方式
- 行内注释方式
- CLI 命令行
那么有这么几种方式,优先级如何呢?优先级顺序从高到低如下:
- 行内注释配置方式
- CLI 命令行配置方式
- 配置文件的方式(虽然它的优先级是最低的,但却是用得最多的)
- 从 ESLint v8.0.0 开始,已经不再支持个人配置文件(你把你的配置文件是写在项目之外的,放在你的主目录 ~ 下面的),也就是说,如果你的电脑主目录下存在配置文件,ESLint 不会去搜索到那儿,会自动忽略那里的配置文件。
## 扩展配置文件
这里所谓的扩展,实际上更准确的来讲,叫做继承。
```js
{
"extends": "eslint:recommended",
}
```
在上面的配置中,extends 对应的值为 eslint:recommended,表示采用 ESLint 团队推荐的规则规范。
在继承了 eslint:recommended 规则规范的基础上, 是可以进行额外的配置。
```js
{
"extends": "eslint:recommended",
"rules" : {
"no-console": "warn"
}
}
```
但是在进行原有配置规则的扩张的时候,有一个细节上面的问题:
```js
{
"extends": "eslint:recommended", // "eqeqeq": ["error", "allow-null"]
"rules" : {
"eqeqeq": "warn"
}
}
```
在上面的扩展中,我们修改了 eqeqeq 这条规则的重要性,从 error 修改为了 warn,当你修改规则重要性的时候,原本的配置选项会保留,也就是说,上面关于 eqeqeq 这条规则,最终会变为
```js
"eqeqeq": ["warn", "allow-null"]
```
但是如果你更改的是配置选项,那么则是完全覆盖。
```js
{
"extends": "eslint:recommended", // "quotes": ["error", "single", "avoid-escape"]
"rules" : {
"quotes": ["error", "double"]
}
}
```
在上面的例子中,我们修改了 quotes 规则的配置选项,改为了 double,那么新的配置选项会对旧的("single", "avoid-escape")进行完全覆盖。
另外关于 extends 对应的值还可以是一个数组:
```js
{
"extends": [
"./node_modules/coding-standard/eslintDefaults.js",
"./node_modules/coding-standard/.eslintrc-es6",
"./node_modules/coding-standard/.eslintrc-jsx"
],
"rules": {
"quotes": "warn"
}
}
```
## 局部重写
有些时候,我们需要对配置进行更加精确的控制,例如都是在同一个目录下,不同的文件使用不同的配置,这种情况下就可以使用局部重写(overrides)
```js
{
"rules": {
"quotes": ["error", "double"]
},
"overrides": [
{
"files": ["bin/*.js", "lib/*.js"],
"excludedFiles": "*.test.js",
"rules": {
"quotes": ["error", "single"]
}
}
]
}
```
例如,假设我们有如下的项目结构:
```js
any-project/
├── .eslintrc.js
├── lib/
│ ├── util.js
│ └── other.js
└── src/
├── index.js
└── main.js
```
在 .eslintrc.js 配置文件中,我们书写了如下的配置代码:
```js
{
"rules": {
"quotes": ["error", "double"]
},
"overrides": [
{
"files": ["lib/*.js"],
"rules": {
"quotes": ["error", "single"]
}
}
]
}
```
在上面的配置文件中,我们使用了局部重写,src 目录下面的所有 js 文件使用双引号,lib 目录下面所有的 js 文件使用单引号。
overrides 对应的值是一个数组,那么这意味着可以有多个配置项,当多个配置项之间匹配上了相同的文件,那么以后面的配置项为准。
```js
{
"rules": {
"quotes": ["error", "double"]
},
"overrides": [
{
"files": ["**/*.js"],
"rules": {
"quotes": ["error", "single"]
}
},
{
"files": ["lib/*.js"],
"rules": {
"quotes": ["error", "double"]
}
}
]
}
```
overrides 是支持嵌套,例如:
```js
{
"rules": {
"quotes": ["error", "double"]
},
"overrides": [
{
"files": ["lib/*.js"],
"rules": {
"quotes": ["error", "single"]
},
"overrides": [
{
"files": ["util.js"],
"rules": {
"quotes": ["error", "double"]
},
}
]
}
]
}
```
# 配置文件part2
首先再次强调,目前新版本的配置文件系统还没有正式生效,因为目前最新的版本为 v8.x.x,新版本的配置文件系统要到 v9.0.0 才正式生效。
这也意味着当前所介绍的内容,在未来还有变化的余地,未来以官方为准。
## 配置文件的书写
从 v9.0.0 开始,官方推荐的配置文件格式为 eslint.config.js,并且支持 ESM 模块化风格,可以通过 export default 来导出配置内容
```js
export default [
{
rules: {
semi: "error",
"prefer-const": "error"
}
}
];
```
之所以导出的是一个数组,是因为为了支持项目中不同的文件或者文件类型定义不同的规则。
例如,你的项目里面既有 JS 代码,也有 TS 代码,你可能想要针对不同的代码类型配置不同的 ESLint 检查规则,这里就可以这样写:
```js
module.exports = [
{
files: ["*.js"],
rules: {
"no-var": "error"
}
},
{
files: ["*.ts"],
rules: {
"@typescript-eslint/no-var": "error"
}
}
];
```
如果你在 package.json 里面没有指定 type: module,那么就代表你使用的是 CommonJS 规范,那么 ESLint 配置文件在做模块导出的时候,也需要使用 CommonJS 模块规范
```js
module.exports = [
{
rules: {
semi: "error",
"prefer-const": "error"
}
}
];
```
## 配置对象的选项
具体的配置选项如下:
- *files* - 一个含有 *glob* 模式的数组,指示应用配置对象的文件。如果未指定,配置对象应用于所有由任何其他配置对象匹配的文件。
- *ignores* - 一个含有 *glob* 模式的数组,指示配置对象不应用于的文件。如果未指定,配置对象应用于所有由 *files* 匹配的文件。
- *languageOptions* - 一个包含与 *JavaScript* 的 *lint* 设置有关的设置对象。。
- *ecmaVersion* - 支持的 *ECMAScript* 版本。可能是任何年份(例如,*2022*)或版本(例如,*5*)。设置为 "*latest*" 表示最近支持的版本。(默认:"*latest*")
- *sourceType* - *JavaScript* 源码的类型。可能的值为 "*script*" 表示传统脚本文件,"*module*" 表示 *ECMAScript* 模块(*ESM*),以及 "*commonjs*" 表示 *CommonJS* 文件。(默认情况下 "*module*" 对应 .*js* 和 .*mjs* 文件,"*commonjs*" 对应 .*cjs* 文件)
- *globals* - 一个对象,指定在 *linting* 过程中应添加到全局作用域的额外对象。
- *parser* - 包含 *parse*( ) 方法或 *parseForESLint*( ) 方法的对象。(默认值为 *espree*)
- *parserOptions* - 一个对象,指定直接传递给 *parser* 上的 *parse*( ) 或 *parseForESLint*( ) 方法的额外选项。可用的选项依赖于解析器。
- *linterOptions* - 包含与 *linting* 相关配置的对象。
- *noInlineConfig* - 布尔值,指示是否允许内联配置。
- *reportUnusedDisableDirectives* - 布尔值,控制是否报告未使用的 *eslint-disable* 指令
- *processor* - 包含 *preprocess*( ) 和 *postprocess*( ) 方法的对象,或者指示插件内部处理器名称的字符串(例如,"*pluginName/processorName*")。
- *plugins* - 包含插件名称到插件对象的名称-值映射的对象。当指定了 *files* 时,这些插件仅对匹配的文件可用。
- *rules* - 包含具体配置规则的对象。当指定了 *files* 或 *ignores* 时,这些规则配置仅对匹配的文件可用。
- *settings* - 一个包含键值对信息的对象,这些信息应对所有规则都可用。
整体来讲,上面的配置项不算多,而且很多配置项我们在前面是已经接触过的。
下面是一些之前没有接触过的配置项:
globals:该配置项位于 languageOptions 配置项下面,用于配置一些全局的设定:
```js
export default [
{
files: ["**/*.js"],
languageOptions: {
globals: {
var1: "writable",
var2: "readonly"
}
}
}
];
```
在上面的配置中,我们指定了 var1 这个变量是可写的,但是 var2 这个变量是只读的。
假设你有如下的代码
```js
var1 = 100;
var2 = 200; // 报错
```
parsers:配置解析器。解析器的作用是负责将源码解析为抽象语法树。ESLint 默认使用的解析器为 Espree,但是你可以指定其他的 parser,parser 需要是一个对象,该对象里面包含了 parse 或者 parseForESLint 方法。
```js
import babelParser from "@babel/eslint-parser";
export default [
{
files: ["**/*.js", "**/*.mjs"],
languageOptions: {
parser: babelParser
}
}
];
```
在上面的配置中,我们就指定了其他的 parser 来解析源码。
processor:这个是处理器,主要用于处理 ESLint 默认不能够处理的文件类型。举个例子,假设有一个 markdown 类型的文件,里面有一些 JS 代码,默认这些 JS 代码是不能够被 ESLint 处理的,通过添加额外的处理器,让 ESLint 能够对这些格式的文件进行 lint 检查
```js
import markdown from "eslint-plugin-markdown";
export default [
{
files: ["**/*.md"],
plugins: {
markdown
},
processor: "markdown/markdown",
settings: {
sharedData: "Hello"
}
}
];
```
# CLI命令行工具
关于 CLI 命令行工具,我们在第一节课的时候就用到过一个:
```js
eslint --fix .
```
在官网,我们可以看到 CLI 命令行工具的基本格式为:
```bash
eslint [options] [file|dir|glob]*
```
我们先来看后面的 [file|dir|glob]* , 这个部分主要是用来指定 ESLint 应该检查哪些文件:
- file:用于指定一个具体的文件名
```bash
eslint app.js # 使用 eslint 检查 app.js 这个文件
```
- dir:指定一个目录
```bash
eslint src/
# 检查 src 目录下面的所有文件
```
- glob:这个 glob 是一种模式,有点类似于正则表达式,专门用来匹配文件的路径,glob 模式下面可以使用一些特殊的字符( * ? [])来匹配文件名
```bash
eslint src/**/*.js
# 检查 src 以及下面所有子目录下的所有 js 文件
```
- \*:表示你可以指定多个文件或者目录或者 glob 模式
学习 CLI 命令行工具,主要是 options 这一块,这一块的配置选项是相当丰富的,这里我们对众多的 options 选项进行一个分类,然后每一类选择几个典型的命令来进行介绍。
- 基本配置
- 特殊规则和插件的配置
- 自动修复
- 忽略文件
- 输出
- 缓存
## 基本配置
#### `--no-eslintrc`
告诉 ESLint 忽略所有的配置文件,当你使用这个 option 的时候,ESLint 只会使用内置的规则集来对匹配上的文件进行检查
```bash
eslint --no-eslintrc .
```
#### `-c`, `--config`
允许我们指定配置文件的路径
```bash
eslint -c ~/my-eslint.json file.js
```
> ~ 在类 Unix 系统里面表示用户根目录
#### `--env`
该配置项允许我们指定一些环境,当指定了具体的环境之后,那么就会预设一些该环境下才会有的全局变量。
```bash
eslint --env browser,node file.js
eslint --env browser --env node file.js
```
在上面的 CLI 命令中,指定了 browser 以及 node 环境,指定了这两个环境之后,就会预设一些 window、process 之类的全局变量
#### `--ext`
允许我们指定 ESLint 要检查的文件的扩展名,默认情况下,ESLint 只检查 js 文件。
```bash
eslint . --ext .ts # 检查 ts 文件
eslint . --ext .js --ext .ts # 检查 js 和 ts 文件
eslint . --ext .js,.ts # 和上面一样,换了一种写法
```
#### `--global`
该配置项允许我们定义全局变量。例如我们的项目使用到了 jQuery,但是这个 ESLint 是不认识的,所以这里我们就可以使用 global 来定义这个全局变量
```bash
eslint --global jQuery:true .
```
#### `--parser`
这个选项允许你指定一个自定义的 *JavaScript* 解析器。默认情况下,*ESLint* 使用 *Espree*,但是你可以使用其他的解析器。例如,你可以使用 *Babel-ESLint*,如果你的项目中使用了 *Babel* 和 *ESLint*,你可以使用它来解析你的 *JavaScript* 代码。
## 特殊规则和插件的配置
#### `--plugin`
该配置项是用来指定要使用插件。
```bash
eslint --plugin jquery file.js # 指定使用 jquery 这个插件
```
#### `--rule`
该配置项就是指定检查的规则,一般来讲,检查规则是写到配置文件里面。但是针对某些场景下单独的一两条规则要改变,可以使用这种方式
```bash
eslint --rule 'quotes: [error, double]' .
```
## 自动修复
#### `--fix`
表示自动修复,但是需要主要,不是所有的问题 ESLint 都可以帮你修复。
#### `--fix-type`
允许你指定修复问题的类型,对应的值有 problem、suggestion、layout、directive
- *problem*:修复代码中的潜在错误,这种类型的问题通常是代码错误,如果不修复,可能会导致程序运行错误。
- *suggestion*:对代码应用改进性的修复,这种类型的问题通常不会导致程序错误,但修复它们可以改进代码,使代码更易读、更易维护,或更符合最佳实践。这些问题可能涉及到代码的优化、重构或者一些编程习惯的改进。例如,未使用的变量、复杂的表达式可以简化、不必要的代码重复等,都属于 *suggestion* 类型的问题。
- *layout*:应用不改变程序结构(抽象语法树,*AST*)的修复,主要涉及到代码的格式和样式。这些问题不会影响代码的功能或语义,但是修复它们可以使代码更具可读性和一致性。例如,不正确的缩进、缺失的分号、超过设定长度的行等,都属于 *layout* 类型的问题。
- *directive*:对内联指令(如 // *eslint-disable*)应用修复
注意上面的修复问题类型是可以同时指定多个的
```bash
eslint --fix --fix-type suggestion --fix-type problem .
```
## 忽略文件
#### `--ignore-path`
很明显是指定忽略文件的路径。
所谓忽略文件,就是指在项目中可以创建一个 .eslintignore 的文件,该文件里面记录一些文件名或者目录名,ESLint 在进行代码检查的时候,会忽略这些匹配上的文件名或者目录下面的文件
```bash
eslint --ignore-path tmp/.eslintignore file.js
```
#### `--no-ignore`
忽略所有的忽略指令。本来 .eslintignore 文件里面记录了 ESLint 在进行检查的时候要忽略那鞋文件,当你用了这个指令之后,相当于你的 .eslintignore 文件失效了,里面记录的那些文件都要被 ESLint 检查
```bash
eslint --no-ignore .
```
#### `--ignore-pattern`
简单来说,就是将原本你应该写在 .eslintignore 里面的文件或者目录,写在了命令行里面
```bash
eslint --ignore-pattern "/lib/" --ignore-pattern "/src/vendor/*" .
```
## 输出
#### `-o`, `--output-file`
允许将 ESLint 的检查报告输出到一个文件里面
```bash
eslint -o report.txt .
```
在上面的配置中,ESLint 会将最终的检查结果报告输出到 report.txt 的文件中
#### `-f`, `--format`
正常情况下,ESLint 的检查报告在控制台进行输出,那么这个指令可以配置输出的格式
- "*stylish*"(默认):这是 *ESLint* 默认的格式化选项。它以易于读取的方式显示 *linting* 结果,对于每个文件,它会列出所有的错误和警告,然后在下面显示一个摘要,包括总的错误和警告数量。
- "*compact*":这种格式更加简洁。它将每个错误或警告限制为一行,其中包括文件名、行号、列号和问题描述。这种格式适合那些希望尽可能节省空间的情况。
- "*tap*" 是一个代表 "*Test Anything Protocol*" 的缩写,这是一个简单的文本格式,用于记录和通信测试结果。*ESLint* 会按照 *TAP* 规范来输出 *linting* 结果。这种格式特别适合于 *CI/CD*(持续集成和持续部署)环境,因为很多 *CI/CD* 工具都支持解析 *TAP* 格式的输出。
## 缓存
#### `--cache`
该配置项表示在进行ESLint检查的时候,生成一个缓存文件 .eslintcache,缓存文件默认在当前目录下面,有了缓存文件之后,下一次 ESLint 在做检查的时候速度会更快
```bash
eslint --cache .
```
#### `--cache-location`
我们可以指定缓存文件的位置
```bash
eslint "src/**/*.js" --cache --cache-location "/Users/user/.eslintcache/"
```
#### `--cache-strategy`
指定生成缓存时的缓存策略,对应的策略值有两个:
1. `metadata`:这是默认值,使用文件的元数据(修改时间和文件大小)来判断文件是否发生了变化
2. `content`:基于文件的内容来判断文件是否发生变化
```bash
eslint "src/**/*.js" --cache --cache-strategy content
```
# APIs
*While ESLint is designed to be run on the command line, it’s possible to use ESLint programmatically through the Node.js API. The purpose of the Node.js API is to allow plugin and tool authors to use the ESLint functionality directly, without going through the command line interface.*
一般在如下的场景中,我们会涉及到使用 API 来编程:
- 要将工具集成到代码编辑器或者 IDE 里面
- 自定义 linter 工具
- 一些在线的学习平台
首先我们初始化一个项目 eslint-api-demo,然后使用 pnpm init 进行一个初始化,之后安装 eslint 依赖:
```bash
pnpm add eslint
```
安装的时候一定要注意,这一次安装是安装为项目依赖,而非开发依赖,因为我们是使用的 API 的形式来检查其他项目,本项目类似于提供给其他项目的一个第三方库,因此在我们这个项目中,eslint 即便是在运行期间也是需要的。
接下来在 src 目录下面创建一个 eslint-integration.js 文件,这个是我们的核心逻辑文件
```js
const { ESLint } = require("eslint");
/**
* 创建并返回 eslint 实例对象
* @param {*} overrideConfig
*/
function createESLintInstance(overrideConfig) {
new ESLint({
useEslintrc: false,
overrideConfig,
fix: true,
});
}
/**
* 向外部暴露的方法,用于检查对应的文件
* @param {*} filePaths 要做 lint 检查的文件路径
*/
function lintFiles(filePaths) {
// 创建一个配置对象
// 你可以在这里指定你的配置,也可以通过读取文件的方式从外部进行读取
const overrideConfig = {
env: {
browser: true,
es2021: true,
},
extends: "eslint:recommended",
parserOptions: {
ecmaVersion: 12,
sourceType: "module",
},
rules: {
indent: ["error", 2],
quotes: ["error", "single"],
semi: ["error", "always"],
"no-console": "error",
},
};
// 创建一个 eslint 的实例
createESLintInstance(overrideConfig);
}
module.exports = {
lintFiles,
};
```
在上面的代码中,有一个 new ESLint,ESLint 是 eslint 里面提供的一个类,关于在实例化这个类的时候,配置对象提供了哪些配置项,可以参阅:https://eslint.org/docs/latest/integrate/nodejs-api#-new-eslintoptions
之后我们创建了一个名为 lintAndFix 的方法,该方法负责对具体的代码文件进行 lint 检查以及修复工作:
```js
/**
* 该函数负责对传入的文件做 lint 检查以及修复
* @param {*} eslint
* @param {*} filePaths
*/
async function lintAndFix(eslint, filePaths){
// 要做 lint 检查,很明显就是调用 eslint 实例对象上面的方法
const results = await eslint.lintFiles(filePaths);
console.log(results);
}
```
可以看到,内部实际上调用了 eslint 实例对象上面的 lintFiles 方法,关于 eslint 实例对象有哪些方法,可以参阅官方的 API 文档:
https://eslint.org/docs/latest/integrate/nodejs-api#-eslintlintfilespatterns
最后,我们要对检查的结果做一个友好的控制台输出:
```js
/**
* 该方法负责对 lint 后的结果进行一个友好的输出
* @param {*} results
*/
function outputLintingResults(results){
// 拿到 lint 后错误的总数(包含警告)
const problems = results.reduce((a, b)=> a + b.errorCount + b.warningCount, 0);
if(problems > 0) {
console.log("Linging errors found! \n");
const messages = results[0].messages;
for(let i=0;i,eslint-plugin-jquery、eslint-plugin-react
插件还可以使用 scope 包的形式:
- @\/eslint-plugin-\<插件名称>
- @jquery/eslint-plugin-jquery
- 还可以只有前面的 scope:@jquery/eslint-plugin
在 npm 官网上面搜索 eslint-plugin 能够找到很多 ESLint 相关的插件。
## 使用插件的方式
使用现有的插件,方式非常简单,就分为两步:
- 安装插件
- 在配置文件中进行配置
假设你要使用一个名为 eslint-plugin-react 的插件,首先安装该插件:
```bash
pnpm add eslint-plugin-react -D
```
接下来在配置文件中进行配置:
```js
{
"plugins": ["react"]
}
```
配置完成后,就可以在配置文件添置该插件所提供的各种规则:
```js
{
"plugins": [
"react"
],
"rules": {
"react/jsx-uses-react": "error",
"react/jsx-uses-vars": "error",
}
}
```
## 使用插件实例演示
这里我们来演示 eslint-plugin-vue 插件的使用。
该插件对应的官网地址:https://eslint.vuejs.org/
首先我们初始化一个 vue 的项目:
```bash
npm init vue@latest
```
接下来控制台会出现交互式选择,我们选择安装 ESLint 以及 Prettier
eslint-plugin-vue 提供了一些预定义配置的选项,说明如下:
- "*plugin:vue/base*":提供设置和规则以启用正确的 *ESLint* 解析。
针对使用 *Vue.js 3.x* 的配置:
- "*plugin:vue/vue3-essential*":包括 "*plugin:vue/base*",并添加了一些规则以防止错误或意外行为。
- "*plugin:vue/vue3-strongly-recommended*":在上述配置的基础上,添加了一些能显著提高代码可读性和/或开发体验的规则。
- "*plugin:vue/vue3-recommended*":在上述配置的基础上,添加了一些强制执行社区主观默认的规则,以确保一致性。
针对使用 *Vue.js 2.x* 的配置:
- "*plugin:vue/essential*":包括 "*plugin:vue/base*",并添加了一些规则以防止错误或意外行为。
- "*plugin:vue/strongly-recommended*":在上述配置的基础上,添加了一些能显著提高代码可读性和/或开发体验的规则。
- "*plugin:vue/recommended*":在上述配置的基础上,添加了一些强制执行社区主观默认的规则,以确保一致性。
插件安装好了后,接下来就是这个插件具体带来了哪些规则。例如:
```js
rules: {
'vue/html-quotes': ['error', 'double'],
'vue/html-self-closing': [
'error',
{
html: {
void: 'always',
normal: 'never',
component: 'always'
},
svg: 'always',
math: 'always'
}
]
},
```
这些规则你在插件的官网都是能够查询到的。
# 自定义ESLint插件
ESLint插件主要是用来扩展ESLint本身没有的功能,这里包括扩展规则、扩展配置、扩展解析器。
90%的ESLint插件都是以扩展规则为主,所以这些插件里面会包含大量的自定义规则。
像这一类的插件,一般一条规则会对应一个 JS 文件,JS 文件里面需要导出一个对象:
```js
module.exports = {
// 元数据信息
meta: {
},
// 规则具体的实现
create: function(){
return {}
}
}
```
1. meta
这个字段提供这条规则相应的元数据信息:
- *type*: 描述规则的类型。可以是以下的一个:
- "*problem*":表示这个规则识别的是可能导致错误的代码问题。
- "*suggestion*":表示这个规则识别的是可能的改进,以使代码更易于阅读和/或更具可维护性。
- "*layout*":表示这个规则识别的是布局问题,即风格指南中的问题,而不会影响代码的功能。
- *docs*:提供关于规则的文档信息,可以包含以下字段:
- *description*:规则的简短描述,通常用于生成文档。
- *recommended*:一个布尔值,表示这个规则是否在配置为 "*recommended*"(推荐)的情况下被启用。
- *url*:指向规则文档的 *URL*。
- *fixable*:说明是否可以自动修复由此规则识别的问题,以及如何修复。如果规则可以自动修复问题,此字段应为 "*code*" 或 "*whitespace*",否则应为 *null* 或省略。
- *deprecated*:一个布尔值,表示这个规则是否已被弃用。默认为 *false*。
2. create
这个字段对应的是一个函数,该函数会返回一个对象,对象里面又是一个一个的方法,例如有如下的方法:
> 我们所书写的源代码最终会被解析一个抽象语法树,这个抽象语法树就是一个树结构,里面由一个一个的节点组成的,每一个节点是一个 token,工具在处理你的源码的时候,实际上就会去遍历这棵树,遍历到对应的节点,然后针对对应节点做出相应的处理。
- *Program*: 这个方法会在遍历抽象语法树开始时被调用。
- *FunctionDeclaration*:这个方法会在遍历到一个函数声明时被调用。
- *VariableDeclaration*:这个方法会在遍历到一个变量声明时被调用。
- *ExpressionStatement*:这个方法会在遍历到一个表达式语句时被调用。
- *CallExpression*:这个方法会在遍历到一个函数调用时被调用。
- *ReturnStatement*:这个方法会在遍历到一个 *return* 语句时被调用。
上面这些方法所对应的名称实际上都来源于 ESTree 规范里面所定义的 AST 节点类型。
这些方法里面接收一个参数,该参数是当前所遍历到的 AST 节点对象,你通过这个节点对象就可以拿到当前节点一些具体的信息以及该节点对应的子节点。
```js
create: function(){
return {
CallExpression(node){
// ...
}
}
}
```
除了节点处理函数以外,create 方法还会自动传入一个 context 参数
```js
create: function(context){
return {
CallExpression(node){
// ...
}
}
}
```
该参数提供了一些方法:
- *context.report(descriptor)*:这个方法用于报告一个问题。*descriptor* 是一个对象,包含了问题的信息,如问题的位置、消息等。
- *context.getSourceCode( )*:这个方法返回一个 *SourceCode* 对象,你可以使用它来访问源代码的文本和 *AST*。
- *context.getAncestors( )*:这个方法返回一个包含当前节点的所有祖先节点的数组,数组中的第一个元素是最近的祖先。
- *context.getScope( )*:这个方法返回一个代表当前作用域的 *Scope* 对象。
> 补充:
>
> 视频中忘记说了,同学们可以在 https://eslint.org/docs/latest/extend/custom-rules 看到自定义规则的完整结构,包括 meta 完整的配置项有哪些,context 完整的方法有哪些等信息。
接下来我们来看一个插件的实战案例。
首先我们需要创建一个插件项目 eslint-plugin-\<插件名称>
例如我们的项目叫做 eslint-plugin-customrules,首先使用 pnpm init 进行一个项目初始化,然后在项目根目录中创建 rules 目录,该目录用于存放我们的自定义规则。
接下来我们创建了如下的两条规则:
```js
// 不允许有 alert 语句
// alert("xxx")
module.exports = {
meta: {
type: "problem",
docs: {
description: "disallow the use of alert",
category: "Best Practices",
},
fixable: null,
},
create(context) {
return {
// 这个方法会在遍历到一个函数调用时被调用
CallExpression(node) {
if (node.callee.name === "alert") {
// 说明当前是一个 alert 的函数调用
context.report({
node,
message: "不允许出现 alert 语句呀,兄弟",
});
}
},
};
},
};
```
```js
// console.log("xxx")
module.exports = {
meta: {
type: "problem",
docs: {
description: "disallow the use of console.log",
category: "Best Practices",
},
fixable: null,
},
create(context) {
return {
CallExpression(node) {
if (
node.callee.object &&
node.callee.object.name === "console" &&
node.callee.property.name === "log"
) {
context.report({
node,
message: "不允许出现 console.log 语句呀,兄弟",
});
}
},
};
},
};
```
每一条规则对应一个 JS 文件,该 JS 文件导出一个对象,该对象里面包含了基本的 meta 和 create 配置项。
下一步我们需要去 package.json 中,修改如下配置项:
```js
"peerDependencies": {
"eslint": "^7.0.0"
}
```
- peerDependencies:该配置项指定了我们这个包需要和哪些其他包在同一环境中使用。例如我们上面指定了 eslint ^7.0.0,也就是告诉别人,在使用我们这个包的时候,需要安装 eslint,并且 eslint 的版本要在 7.0.0 以上。
最后是创建入口文件,用于将所有的规则导出:
```js
// index.js
// 该文件是整个包的入口文件,用于导出所有的规则
module.exports = {
rules: {
// 规则名称 : 规则文件
"no-alert": require("./rules/no-alert"),
"no-console-log": require("./rules/no-console-log"),
},
};
```
至此,我们一个简单的示例插件就书写完毕了。
接下来我们需要测试这个插件。这里我们选择通过 link 的方式来进行本地链接,从而方便我们的测试。
来到插件的根目录,执行 npm link,这样的话该项目就会创建一个软链接到全局包目录里面,回头其他项目就可以通过 link 的方式来链接这个包。
之后我们创建一个测试项目,例如名字叫做 eslint-test-customplugin,使用 npm 进行初始化(因为 npm 和 pnpm 在 link的时候执行机制有一些区别,npm link 时的速度比 pnpm 快一些),然后安装 eslint
```bash
npm i eslint -D
```
然后在 src/index.js 中书写一些测试代码:
```js
alert("Hello");
console.log("World");
```
最后是链接对应的插件包,然后配置文件中配置该插件即可:
```bash
npm link eslint-plugin-customrules
```
配置文件 .eslintrc.json 中配置:
```js
{
"plugins": ["customrules"],
"rules": {
"customrules/no-console-log": "warn",
"customrules/no-alert": "error"
}
}
```
# 集成Prettier
目前我们所学习的两个工具:Pretter 和 ESLint,两者都有管理代码风格的功能,因此两者往往就会在代码风格的管理上面存在一些冲突。
例如举一个例子:
- ESLint 配置了单引号规则
- Prettier 配置了要使用双引号
那么现在假设你使用双引号,ESLint 会提示错误,然后我们将引号手动改为单引号,但是我们一格式化,因为会应用 Prettier 的格式化规则,又会被格式化为双引号,也就是说只要一格式化就会报错。
下面是一个具体的示例:
首先我们初始化了一个名为 eslint-prettier-demo 的项目,使用 pnpm init 进行一个初始化,之后分别安装 eslint 以及 prettier
接下来创建这两个工具的配置文件
prettier 配置文件:
```js
{
"singleQuote": true,
"semi": false,
"printWidth": 80,
"trailingComma": "es5"
}
```
eslint 配置文件
```js
module.exports = {
env: {
browser: true,
es2021: true,
node: true,
},
extends: 'eslint:recommended',
parserOptions: {
ecmaVersion: 12,
sourceType: 'module',
},
rules: {
indent: ['error', 2],
quotes: ['error', 'double'],
semi: ['error', 'always'],
},
}
```
src/index.js
```js
const str = 'Helo World'
const arr = [
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22,
23, 24, 25, 26, 27, 28, 29, 30,
]
const obj = {
name: 'John Doe',
age: 30,
address: {
city: 'New York',
state: 'NY',
},
}
console.log(str)
console.log(arr)
console.log(obj)
```
此时,我们就会发现两份配置之间就存在了冲突。只要一格式化(prettier),eslint 就会报错。
为了解决这个问题,有两个思路:
- 手动的将其中一个工具的配置文件进行修改,改成和另外一个工具的配置是相同的。这种方式肯定是没有问题的,但是缺点在于这种方式是手动的,如果涉及到大量的规则,那么手动操作比较繁琐
- 使用一些插件来帮助我们解决这个
- *eslint-config-prettier* 会关闭所有与 *Prettier* 冲突的 *ESLint* 规则
- *eslint-plugin-prettier* 将 *Prettier* 作为 *ESLint* 规则来运行,这样在运行 *ESLint* 时也会运行 *Prettier*。
接下来我们来安装这两个插件:
```bash
pnpm add eslint-config-prettier eslint-plugin-prettier -D
```
之后修改 ESLint 的配置文件,代码如下:
```js
module.exports = {
env: {
browser: true,
es2021: true,
node: true,
},
extends: ['eslint:recommended', 'plugin:prettier/recommended'],
parserOptions: {
ecmaVersion: 12,
sourceType: 'module',
},
rules: {
'prettier/prettier': [
'warn',
{
semi: false,
},
],
},
}
```
在上面的配置文件中,我们在 extends 里面添加了一个 plugin:prettier/recommended 配置项目,该配置项表示应用 prettier 来作为 ESLint 的插件来运行,当遇到 ESLint 和 Prettier 冲突的规则的时候,关闭 ESLint 的然后用 Prettier 的。
我们也可以书写 rules,但是rules注意就不要再和 ESLint 冲突了,一般只修改规则的重要级别,不修改其他的配置项。
# Babel介绍
*Babel* 是一个编译器,主要用于将最新的 *JavaScript* 代码转化为向后兼容的代码,以便在老版本的浏览器或环境中运行。
例如,你可能在开发时使用了 *ES6、ES7* 或者更高级的 *JavaScript* 特性,但是有些浏览器可能并不支持这些新特性,这时就可以用 *Babel* 来将代码转化为 *ES5* 或者更早版本的 *JavaScript*,以确保代码能在多数浏览器中正常运行。
其次,*Babel* 更像是一个平台,它本身的核心功能就是解析代码到抽象语法树(*AST*),然后再将 *AST* 转回 *JavaScript* 代码。所有的语法转换(例如将 *ES6* 转化为 *ES5*)和功能添加(例如 *polyfills*)都是通过各种插件来实现的。这一点有点类似于前面我们学习 *CSS* 工具链时介绍的 *PostCSS*。
*Babel* 官网:*https://babeljs.io/*
以下是 *Babel* 的一些主要功能:
- 语法转换:将新的 *JavaScript* 语法(如 *JSX,TypeScript,ES2015+* 特性等)转换为旧的 *ES5* 语法。
- 源码映射:在编译后的代码中添加源码映射,以方便调试。
- *Polyfills*:添加缺失的特性,如 *Promise,Symbol* 等,这称为 *polyfill*。*Babel* 提供了一个 *Polyfill* 功能,能自动引入所需的 *Polyfill*。这个功能通过 *core-js* 模块实现(*Babel v7.4.0* 之前使用的是 *@babel/polyfill*),可以模拟整个 *ES2015+* 环境。
> Array.prototype.includes 这个 API 是 ES2016 的新特性,但是一些旧的浏览器是不支持,像这种情况就需要通过 polyfill 天补充缺失的特性,polyfill 就是一段 JS 代码而已,polyfill 这段代码会去检查当前的浏览器是否支持该 API,如果不支持,polyfill 里面提供了该 API 的实现
>
> ```js
> if(!Array.prototype.includes){
> Array.prototype.includes = function() {...}
> }
> ```
- 插件和预设:*Babel* 提供了大量的插件支持,你可以通过插件来使用特定的 *JavaScript* 特性。预设是一组插件的集合,例如,*@babel/preset-env* 会根据你的环境自动决定需要使用哪些插件。
在前端开发中,*Babel* 被广泛用于现代 *JavaScript* 项目,它能确保你的代码能在各种环境中运行,而不需要你手动处理各种浏览器和 *JavaScript* 版本的兼容性问题。
## Babel快速入门
新建一个项目 babel-demo,使用 pnpm init 进行一个初始化,之后安装依赖:
```bash
pnpm add --save-dev @babel/core @babel/cli @babel/preset-env
```
- @babel/core: 这个是 Babel 的核心包,提供了核心 API
- @babel/cli:该依赖提供 CLI 命令行工具
- @babel/preset-env:预设环境,Babel 在做代码转换的时候,是需要依赖插件的,但是会有一种情况,就需要的插件很多。所谓预设,指的就是内置了一组插件,这样我们只需要引入一个预设即可,不需要再挨着挨着引入众多的插件
在 src/index.js 中书写我们的测试代码:
```js
const greet = (name) => `Hello, ${name}!`;
console.log(greet("World"));
```
接下来在项目的根目录下创建 .babelrc 配置文件,书写如下的配置:
```js
{
"presets": ["@babel/preset-env"]
}
```
该配置就是指定我们的预设是什么。
之后在 package.json 里面添加 script 脚本命令
```js
"scripts": {
// ...
"babel": "babel src --out-dir lib"
},
```
编译 src 目录下的文件,输出到 lib 目录下面。
编译结果如下:
```js
"use strict";
var greet = function greet(name) {
return "Hello, ".concat(name, "!");
};
console.log(greet("World"));
```
之后我们修改配置文件,指定了浏览器范围:
```js
{
"presets": [
[
"@babel/preset-env",
{
"targets": {
"edge": "17",
"firefox": "60",
"chrome": "67",
"safari": "11.1"
},
"useBuiltIns": "usage",
"corejs": "3.6.5"
}
]
]
}
```
这一次编译出来的结果如下:
```js
"use strict";
const greet = name => "Hello, ".concat(name, "!");
console.log(greet("World"));
```
为什么两次不一样呢?原因很简单,第二次我们指定了浏览器版本范围,那么在指定的浏览器版本范围里面的这些浏览器,某一些特性已经支持了,所以就不需要再做转换了。
# 配置文件
- 配置文件格式
- 配置文件选项
## 配置文件的格式
在 babel 中,配置文件本身又可以分为两种:
- 项目范围的配置文件
- 文件相关配置文件
**项目范围配置文件**
顾名思义,就是该配置文件针对整个项目生效的一个配置,这种类型的配置文件一般放在项目根目录下面,babel 对项目范围级别的配置文件是有格式要求的,一般是指 babel.config.* 这种格式的配置文件,后面的 * 支持各种类型的扩展名:.json .js .cjs .mjs .cts ...
- babel.config.js ✅
- babel.config.json ✅
- .babelrc ❌
**文件相关配置文件**
这种类型的配置文件就是对特定的文件或者特定的目录以及子目录生效。在 babel 中,如下格式的配置文件是文件级别:
- .babelrc.* (.json .js .cjs .mjs .cts)
- .babelrc.js
- .babelrc.json
- .babelrc
- package.json 文件里面的 babel 键
接下来我们来看一个结构示例:
```js
/my-project
|-- frontend
| |-- .babelrc.json
| |-- src
|-- backend
| |-- .babelrc.json
| |-- src
|-- babel.config.json
```
假设 babel.config.json 配置如下:
```js
{
"presets": [
"@babel/preset-env"
]
}
```
上面配置文件中所指定的预设,会在整个项目中国都被用到。
假设 frontend/.babelrc.json 有如下的配置:
```js
{
"plugins": [
"@babel/plugin-transform-react-jsx"
]
}
```
该配置就只会在 frontend 目录范围内生效。babel 在对 frontend 目录下的文件进行编译的时候,会自动的去合并多个 babel 配置文件,最终 frontend 目录下的文件在进行编译的时候,就会使用 @babel/preset-env 预设以及 @babel/plugin-transform-react-jsx 这个插件。
## 配置文件选项
有关 babel 配置文件所支持的配置项有哪些,可以在官网的 https://babeljs.io/docs/options 看到。
所支持的配置项还是比较多,官方进行一个简单的分类:
- 主要选项
- 配置加载选项
- 插件和预设配置
- 输出目标选项
- 配置合并选项
- 源码映射选项
- 其他选项
- 代码生成器选项
- *AMD / UMD / SystemJS* 选项
- 选项概念
这里我们不需要一开始就对所有的配置项完全掌握,下面我们就介绍一些常见的配置项。
### 插件和预设配置
- plugins:对应的值为一个数组,配置要使用的插件,可以配置多个,注意在配置文件中配置的插件需要提前进行安装
```js
{
"plugins": [["@babel/plugin-transform-arrow-functions", {}]]
}
```
- presets:配置一个预设,对应的值也是一个数组,表示可以配置多个
```js
{
"presets": ["@babel/preset-env"]
}
```
### 输出目标选项
- targets: 该配置项目用于指定要兼容的浏览器版本范围
```js
{
"targets": "> 0.25%, not dead"
}
```
关于指定浏览器范围,有多种多样的形式,例如可以在项目根目录下创建一个 .browserslistrc 配置文件来指定范围,也可以在 package.json 中通过 browserslist 这个键来指定范围。
优先级顺序如下:
1. targets
2. .browserslistrc
3. package.json
- browserlistConfigFile:默认值是 true,表示允许 babel 去搜寻项目中和 browserlist 相关的配置。例如 babel 配置文件中没有 targets 的配置,但是项目中有 .browserslistrc 这个文件,里面指定了浏览器范围,那么 babel 在进行编译的时候,会去搜索和 browserlist 相关的配置,并在编译的时候应用对应的浏览器范围配置。这个配置对应的值还可以是一个字符串形式的路径,该路径就指定了具体的 browserlist 文件的位置
```js
{
"presets": [
["@babel/preset-env", {
"browserslistConfigFile": "./.browserslistrc"
}]
]
}
```
### 配置合并选项
- extends:允许你扩展其他的 babel 配置文件,你可以提供一个路径,该路径对应的 babel 配置文件就会作为基础的配置
```js
{
"extends": "./base.babelrc.json"
}
```
- env:为你不同的环境提供不同的配置,例如在开发环境或者生成环境需要使用不同的插件或者预设,那么就可以通过 env 来指定环境。
```js
{
"env": {
"development": {
"plugins": ["pluginA"]
},
"production": {
"plugins": ["pluginB"]
}
}
}
```
- overrides :该配置项用于对匹配上的特定文件或者目录应用不同的配置
- test:做匹配
- include:包含哪些目录
- exclude:排除哪些目录
```js
{
"overrides": [
{
"test": ["*.ts", "*.tsx"],
"exclude": "node_modules",
"presets": ["@babel/preset-typescript"]
}
]
}
```
- ignore 和 only :ignore 控制忽略文件,only 指定特有文件
```js
{
"ignore": ["node_modules"],
"only": ["src"]
}
```
### 源码映射选项
- sourceMaps:告诉 babel 是否要生成 source map
```js
{
"sourceMaps": true
}
```
- sourceFileName:指定 source map 文件的文件名
```js
{
"sourceFileName": "customFileName.js"
}
```
- sourceRoot:source map 文件对应的 URL 前缀
```js
{
"sourceMaps": true,
"sourceRoot": "/root/path/to/source/files/" // 前缀
}
```
### 其他选项
- sourceType:指定 babel 应该如何去解析 js 代码
- module:如果你的代码使用的 ESM 模块化,里面涉及到了 export 、import,那么应该指定为这个值
- script:普通的 JS 脚本,没有使用模块化
- unambiguous:让 babel 自己来判断,babel 检查到你的代码使用了 export 、 import,就会视为模块文件,否则就会视为普通的 script 脚本
- assumptions:从 babel 7.13.0 开始引入的一项配置项,让开发者对自己的代码做一个假定(更像是对 babel 的一个承诺)
```js
{
"assumptions": {
"noClassCalls": true
}
}
```
上面配置表示我的代码中不会直接调用类(不会像调用函数一样去调用类),babel 就可以省略生成检查类是否被正确调用的代码。
# CLI
关于 babel 所提供的 CLI,你可以在 https://babeljs.io/docs/babel-cli 看到所有所支持的 CLI 命令。
要使用 CLI 命令,首先第一步是安装:
```bash
pnpm add --save-dev @babel/core @babel/cli
```
注意在安装 @babel/cli 这个包的时候,需要同时安装 @babel/core 这个包,这个包是提供 babel 核心 API 的。CLI 背后实际上就是使用的 API 来实现的。
## 编译文件相关的 CLI
在使用 babel 的 CLI 命令的时候,有一个基本的格式:
```bash
babel [file | dir | glob] --out-[file | dir]
```
如果你没有指定 --out,那么 babel 会将编译后的结果输出到控制台。
常见的格式如下:
```bash
# 编译结果输出到控制台
babel script.js
# 编译结果输出到指定文件
babel script.js --out-file script-compiled.js
# 编译整个目录到指定目录下
babel src --out-dir lib
# 编译整个目录下的文件,输出到一个文件里面
babel src --out-file script-compiled.js
# 监视文件,当文件发生变化时自动重新编译
babel script.js --watch --out-file script-compiled.js
```
我们在进行编译的时候,可以指定是否要生成 source map:
```bash
babel script.js --out-file script-compiled.js --source-maps
babel script.js --out-file script-compiled.js --source-maps inline
```
## 忽略文件和拷贝文件
有些时候我们在进行编译的时候,想要忽略某些文件
```bash
# 忽略 src 目录下面的所有测试文件
babel src --out-dir lib --ignore "src/**/*.spec.js","src/**/*.test.js"
```
有些文件我们想要原封不动的进行拷贝,不需要 babel 进行编译
```bash
# 将 src 目录下的文件原封不动的复制到 lib 目录下
babel src --out-dir lib --copy-files
# 进行拷贝的时候忽略文件中匹配的文件不要拷贝
babel src --out-dir lib --copy-files --no-copy-ignored
```
## 使用插件和预设
在 CLI 命令行里面也是可以指定插件和预设的
```bash
# 指定插件
babel script.js --out-file script-compiled.js --plugins=@babel/transform-class-properties,@babel/transform-modules-amd
# 指定预设
babel script.js --out-file script-compiled.js --presets=@babel/preset-env,@babel/flow
```
## 使用配置文件
通过 --config-file 可以指定配置文件的位置
```bash
babel --config-file /path/to/my/babel.config.json --out-dir dist ./src
```
如果想要忽略已经有了的配置文件中的配置,可以使用 --no-babelrc
```bash
babel --no-babelrc script.js --out-file script-compiled.js --presets=@babel/preset-env,@babel/preset-react
```
# 使用插件
在 babel 要使用一个插件,步骤实际上非常简单,就分为两步:
- 安装插件
- 在配置文件或者 CLI 中指定插件
举个例子,例如有一个专门将箭头函数转为普通函数的插件:
```bash
pnpm add @babel/plugin-transform-arrow-functions -D
```
之后在配置文件中进行插件配置即可
```js
{
"plugins": ["@babel/plugin-transform-arrow-functions"]
}
```
## **插件使用的细节**
1. 插件的运行顺序
plugins 对应的值为一个数组,说明是可以指定多个插件的
```js
{
"plugins": ["transform-decorators-legacy", "transform-class-properties"]
}
```
在上面的配置中,插件的运行会从左往右运行,也就是说,会先运行 transform-decorators-legacy 这个插件,然后运行 transform-class-properties 这个插件。
如果配置文件中既配置了插件,又配置了预设,那么 babel 会先运行插件,然后在运行预设里面的插件,也就是说,插件运行的时机是要早于预设的。
2. 插件选项
在使用插件的时候,是可以传递插件选项的,例如有三种写法:
```js
{
"plugins": ["pluginA", ["pluginA"], ["pluginA", {}]]
}
```
上面的三种写法目前来讲是等价的,而第三种写法,数组第二项的对象实际上就是用来传递插件配置项
```js
{
"plugins": [
[
"transform-async-to-module-method",
{
"module": "bluebird",
"method": "coroutine"
}
]
]
}
```
关于插件究竟有哪些配置项,这个需要去参阅插件相关的文档。
## 插件列表
你可以在 https://babeljs.io/docs/plugins-list 看到 babel 中支持的大多数插件。
一般来讲,每个插件点击进去会包含该插件对应的说明信息,一般包含这些内容:
- 该插件的说明
- 插件编译前后代码的区别
- 该插件的使用方法
- 该插件的配置选项
# 使用预设
## 预设的基本使用
首先第一步仍然是先要安装对应的预设
```bash
pnpm add --save-dev @babel/preset-env
```
安装完成后,在配置文件中进行配置:
```js
{
"presets": ["@babel/preset-env"]
}
```
预设对应的值是一个数组,说明也是能够配置多个预设的,但是一定要注意顺序
```js
{
"presets": ["@babel/preset-env", "@babel/preset-react"]
}
```
上面的配置中,会先运行 @babel/preset-react 预设里面的插件,然后运行 @babel/preset-env 这套预设里面的插件。
运行的顺序刚好和插件是相反的,从后往前运行。
## 官方预设
官方提供了 4 套预设:
- *@babel/preset-env* 用于编译 *ES2015* 及以上版本的语法
- *@babel/preset-typescript* 用于 *TypeScript*
- *@babel/preset-react* 用于 *React*
- *@babel/preset-flow* 用于 *Flow*
### stage-x 预设
在 babel v7.0.0 之前,支持一种叫做 state-x 的预设特性。
JavaScript 的新特性是由 TC39 的小组提出并且通过一系列的阶段来推动的。一般来讲,这个阶段分为从 0 到 4,每个阶段对应了新特性的不同状态:
- *Stage 0 - Strawman*:只是一个想法或者提案,还没有任何实现。
- *Stage 1 - Proposal*:这是一个正式的提案,包含 *API* 的描述,但可能还没有完全实现。
- *Stage 2 - Draft*:初步版本,已经有了初步的规范文本,并且大部分细节都已经确定。
- *Stage 3 - Candidate*:候选阶段,规范已经完成,并且已经完成了浏览器的初步实现,这个阶段主要是为了获取反馈和评估。
- *Stage 4 - Finished*:完成阶段,已经在多个浏览器中实现并通过了实际使用的测试,可以被添加到 *ECMAScript* 标准中。
在早期的时候(babel v7.x.x 之前),可以安装对应阶段的预设
```bash
npm install --save-dev @babel/preset-stage-2
```
这个预设对应了 stage2 阶段的新特性的编译
```js
{
"presets": ["@babel/preset-stage-2"]
}
```
之后你在做开发的时候,就可以只用 stage 2 阶段的新语法了。
但是上面的 stage-x 的预设从 v7.0.0 版本开始就已经废弃了。
>As of Babel 7, we've decided to deprecate the Stage-X presets and stop publishing them. Because these proposals are inherently subject to change, it seems better to ask users to specify individual proposals as plugins vs. a catch all preset that you would need to check up on anyway.
目前官方推荐的做法是要使用哪个新特性,直接安装对应的插件即可。
### @babel/preset-env
这里我们主要看一下这一套插件对应的 options
```js
{
"presets": [
[
"@babel/preset-env",
{
"useBuiltIns": "entry",
"corejs": "3.22",
"modules": false
}
]
]
}
```
在上面的配置中,我们就使用了 @babel/preset-env 预设,并且对这套预设做了一些配置。
- targets:指定浏览器需要支持的版本范围
```js
{
"presets": [
["@babel/preset-env", {
"targets": "> 0.25%, not dead"
}]
]
}
```
- useBuiltIns:让你决定如何使用 polyfills
- entry:该选项值会根据项目中 browserslist 对应的浏览器版本范围来添加 polyfills,这个选项不会管你源码中是否用到缺失的特性,只要对应的浏览器版本是缺失的,那么就会添加对应的特性。而且在使用这个选项值的时候,还需要在源码的入口文件中手动引入 core-js
- usage:根据你的源码中是否使用了缺失的特性,如果使用到了缺失的特性,那么才添加对应的 polyfills
- false:这个是默认值,关闭自动引入 polyfills。
- corejs:指定你的 corejs 版本,polyfills 实际上就是通过 corejs 来实现的。该配置项一般就和 useBuiltIns 一起使用
```js
{
"presets": [
["@babel/preset-env", {
"useBuiltIns": "usage",
"corejs": 3
}]
]
}
```
corejs 支持的配置项有 2、3 还有 false:
- "*2*": 使用 *core-js* 的版本 *2*。这是旧版本的 *core-js*,它包含 *ES5、ES6* 和 *ES7* 的特性。在 *Babel 7.4.0* 之前,这是默认值。
- "*3*": 使用 *core-js* 的版本 *3*。这是新版本的 *core-js*,它包含 *ES5、ES6、ES7、ES8* 和更高版本的特性。在 *Babel 7.4.0* 及更高版本,这是推荐的值。
- *false*: 不使用 *core-js*。如果你不想让 *Babel* 添加任何 *polyfill*,你可以将 *corejs* 设置为 *false*。
- modules:设置模块的类型
- amd
- umd
- systemjs
- commonjs
- cjs
- auto
- false
默认值为 auto,根据你的环境和代码自动来决定使用的模块版本。
- include:允许你显式的指定要包含的插件(这个插件是本身在预设里面,但是因为 targets 的设置,可能会被排除掉)
```js
{
"presets": [
["@babel/preset-env", {
"targets": "> 0.25%, not dead",
"include": ["@babel/plugin-proposal-optional-chaining"]
}]
]
}
```
假设 preset-env 里面有 pluginA、pluginB、pluginC,假设我现在指定了浏览器范围,所指定的这些浏览器范围已经实现了特性 A 和 特性B,那么这里就只会用到 pluginC。那么 include 配置项就可以强行指定要包含的插件
# APIs
关于 babel 里面的 APIs 主要位于 @babel/core 这个依赖里面,你可以在官网左下角的 Tooling Packages 分类下找到这个依赖包。
这里顺便介绍一下每一种依赖包的作用:
- *@babel/parser*: 是 *Babel* 的解析器,用于将源代码转换为 *AST*。
- *@babel/core*: *Babel* 的核心包,它提供了 *Babel* 的核心编译功能。这个包是使用 *Babel* 必须安装的。
- *@babel/generator*: 是 *Babel* 的代码生成器,它接收一个 *AST* 并将其转换为代码和源码映射(*sourcemap*)。
- *@babel/code-frame*: 提供了一种用于生成 *Babel* 错误消息的方法,可以在代码帧中高亮显示错误。
- *@babel/runtime*: 提供了 *Babel* 运行时所需要的辅助函数和 *polyfills*,以避免在每个文件中都重复这些代码。
- *@babel/template*: 提供了一种编写带有占位符的 *Babel AST* 模板的方法。
- *@babel/traverse*: 是 *Babel* 的 *AST* 遍历器,它包含了一些用于处理 *AST* 的工具。
- *@babel/types*: 提供了一种用于 *AST* 节点的 *Lodash-esque* 实用程序库。
在第一节课的时候,我们安装了三个依赖:core、cli、preset,但是我们使用 babel 进行编译的时候发现最终是生成了编译后的代码的,而从 AST 生成编译后代码是 generator 的工作,实际上当你安装 core 的时候,就会间接的安装 generator、traverse 等需要用到的依赖包。
通过对官方 API 的观察,我们发现 babel/core 的 API 主要分为三大类:
- transformXXX
- parseXXX
- loadXXX
## transformXXX
这一组方法一看就是做和编译相关的操作,之所以有这么多,其实就是同步或者异步、编译代码或者文件的区别,每个方法的具体含义如下:
- *transform(code: string, options: Object)*: 这是一个异步函数,用于将源代码字符串转换为 *Babel* 的结果对象。结果对象包含了转换后的代码,源码映射,以及 *AST*。
- *transformSync(code: string, options: Object)*: 这个函数和 *transform* 函数功能相同,但它是同步执行的。
- *transformAsync(code: string, options: Object)*: 这个函数和 *transform* 函数功能相同,它返回一个 *Promise*,这个 *Promise* 会在转换完成后解析为结果对象。
- *transformFile(filename: string, options: Object, callback: Function)*: 这个函数会读取并转换指定的文件。转换完成后,会调用提供的回调函数,并将结果对象传递给回调函数。
- *transformFileSync(filename: string, options: Object)*: 这个函数和 *transformFile* 函数功能相同,但它是同步执行的。
- *transformFileAsync(filename: string, options: Object)*: 这个函数和 *transformFile* 函数功能相同,它返回一个 *Promise*,这个 *Promise* 会在转换完成后解析为结果对象。
- *transformFromAst(ast: Object, code: string, options: Object)*: 这个函数接受一个 *AST* 对象,然后将这个 *AST* 转换为 *Babel* 的结果对象。这个函数可以用于在已经有 *AST* 的情况下避免重新解析代码。
- *transformFromAstSync(ast: Object, code: string, options: Object)*: 这个函数和 *transformFromAst* 函数功能相同,但它是同步执行的。
- *transformFromAstAsync(ast: Object, code: string, options: Object)*: 这个函数和 *transformFromAst* 函数功能相同,它返回一个 *Promise*,这个 *Promise* 会在转换完成后解析为结果对象。
上面这些方法中,只要搞懂一个,其他的也就搞懂了。
## parseXXX
该系列方法主要负责将源码转为抽象语法树(AST),之后就不管了。
- *parse(code: string, options: Object)*: 这是一个异步函数,用于解析源代码字符串并返回一个 *AST*。你可以通过选项对象来配置解析过程,例如是否包含注释,是否包含 *location* 信息等。
- *parseSync(code: string, options: Object)*: 这个函数和 *parse* 函数功能相同,但它是同步执行的。
- *parseAsync(code: string, options: Object)*: 这个函数和 *parse* 函数功能相同,它返回一个 *Promise*,这个 *Promise* 会在解析完成后解析为 *AST*。
## loadXXX
这一系列方法主要是做配置文件的加载工作的
- *loadOptions(options: Object)*: 这个函数接受一个选项对象,然后返回一个完整的、已解析的 *Babel* 配置对象。这个配置对象包括了所有的预设,插件,和其他配置选项。如果提供的选项对象中没有指定配置,那么这个函数会尝试从 .*babelrc* 文件或 *babel.config.js* 文件中加载配置。
例如:
```js
const babel = require('@babel/core');
const options = {
filename: './src/myFile.js',
};
const config = babel.loadOptions(options);
console.log(config);
```
在这个例子中,我们首先导入了 *@babel/core*,然后定义了一个选项对象。这个对象中,*filename* 属性指定了我们正在处理的文件的路径。然后我们使用 *@babel/core* 的 *loadOptions* 方法来加载 *Babel* 的配置。
*loadOptions* 方法返回一个配置对象,这个对象包括了所有的预设,插件,和其他配置选项。在这个例子中,我们将这个配置对象打印到控制台。
- *loadPartialConfig(options: Object)*: 这个函数和 *loadOptions* 函数类似,但是返回的配置对象可能是部分的,也就是说,它可能没有包括所有的预设和插件。这个函数主要用于在构建工具中,当你需要对 *Babel* 配置进行更精细的控制时。
# 自定义插件part1
关于 babel 中如何创建自定义插件,官方是有一个 handbook:https://github.com/jamiebuilds/babel-handbook/blob/master/translations/en/plugin-handbook.md
- AST
- Babel处理代码流程
- 遍历
## AST
开发者所书写的源码文件里面的代码,最终会被表现为一颗树结构
```js
function square(n) {
return n * n;
}
```
最终上面的代码,就会被转为如下的树结构:
```
- FunctionDeclaration:
- id:
- Identifier:
- name: square
- params [1]
- Identifier
- name: n
- body:
- BlockStatement
- body [1]
- ReturnStatement
- argument
- BinaryExpression
- operator: *
- left
- Identifier
- name: n
- right
- Identifier
- name: n
```
上面的树结构如果使用 JS 来表示,结构如下:
```js
{
type: "FunctionDeclaration",
id: {
type: "Identifier",
name: "square"
},
params: [{
type: "Identifier",
name: "n"
}],
body: {
type: "BlockStatement",
body: [{
type: "ReturnStatement",
argument: {
type: "BinaryExpression",
operator: "*",
left: {
type: "Identifier",
name: "n"
},
right: {
type: "Identifier",
name: "n"
}
}
}]
}
}
```
你可以在 https://astexplorer.net/ 看到一段源码转换为的 AST
在上面的 JS 对象中,我们会发现每一层有一些相同的结构:
```js
{
type: "FunctionDeclaration",
id: {...},
params: [...],
body: {...}
}
```
```js
{
type: "Identifier",
name: ...
}
```
```js
{
type: "BinaryExpression",
operator: ...,
left: {...},
right: {...}
}
```
每一个拥有 type 属性的对象,我们可以将其称之为一个节点,那么一颗 AST 树实际上就是由成百上千个节点构成的。不同的节点有不同的类型,通过 type 来表示当前节点的类型。
除了 type 以外,还会有一些额外的属性,这些属性就提供了该节点额外的一些信息。
```js
{
type: ...,
start: 0,
end: 38,
loc: {
start: {
line: 1,
column: 0
},
end: {
line: 3,
column: 1
}
},
...
}
```
## Babel处理代码流程
Babel 对代码进行处理的时候,核心的流程就分为三步:
- 解析(parse)
- 转换(transform)
- 生成(generate)
### 解析(parse)
将接收到的源代码转为抽象语法树,这个步骤又分为两个小阶段:
- 词法分析
- 语法分析
所谓词法分析,就是将源码转为 token
```js
let i = "Hello";
```
```
let、i、=、 "Hello"
```
转为 token 时,每一个 token 会包含一些额外的信息:
```js
n * n;
```
会形成如下的 token:
```js
[
{ type: { ... }, value: "n", start: 0, end: 1, loc: { ... } },
{ type: { ... }, value: "*", start: 2, end: 3, loc: { ... } },
{ type: { ... }, value: "n", start: 4, end: 5, loc: { ... } },
]
```
每一个 token 里面专门有一个 type 属性来描述这个 token:
```js
{
type: {
label: 'name',
keyword: undefined,
beforeExpr: false,
startsExpr: true,
rightAssociative: false,
isLoop: false,
isAssign: false,
prefix: false,
postfix: false,
binop: null,
updateContext: null
},
...
}
```
形成一个一个 token 之后,接下来就会进入到语法分析阶段,该阶段就是将所得到的 token 转为 AST 树结构,便于后续的操作。
### 转换(transform)
目前我们已经得到了一颗 AST 树结构,接下来对这棵树进行一个遍历操作,在遍历的时候,就可以对树里面的节点进行一些添加、删除、更新等操作,这个其实就是 babel 转换代码的核心。
例如我们的一些插件,就是在转换阶段介入并进行工作的。
### 生成(generate)
经历过转换之后,你现在得到的树结构已经和之前不一样,接下来我们要做的事情,就是将这颗 AST 重新转为代码(字符串)
## 遍历
在对 AST 进行遍历的时候,采用的是深度优先遍历,例如:
```js
{
type: "FunctionDeclaration",
id: {
type: "Identifier",
name: "square"
},
params: [{
type: "Identifier",
name: "n"
}],
body: {
type: "BlockStatement",
body: [{
type: "ReturnStatement",
argument: {
type: "BinaryExpression",
operator: "*",
left: {
type: "Identifier",
name: "n"
},
right: {
type: "Identifier",
name: "n"
}
}
}]
}
}
```
1. 于是我们从 *FunctionDeclaration* 开始并且我们知道它的内部属性(即:*id,params,body*),所以我们依次访问每一个属性及它们的子节点。
2. 接着我们来到 *id*,它是一个 *Identifier*。*Identifier* 没有任何子节点属性,所以我们继续。
3. 之后是 *params*,由于它是一个数组节点所以我们访问其中的每一个,它们都是 *Identifier* 类型的单一节点,然后我们继续。
4. 此时我们来到了 *body*,这是一个 *BlockStatement* 并且也有一个 *body* 节点,而且也是一个数组节点,我们继续访问其中的每一个。
5. 这里唯一的一个属性是 *ReturnStatement* 节点,它有一个 *argument*,我们访问 *argument* 就找到了 *BinaryExpression**(二元表达式)。
6. *BinaryExpression* 有一个 *operator*,一个 *left*,和一个 *right*。*Operator* 不是一个节点,它只是一个值因此我们不用继续向内遍历,我们只需要访问 *left* 和 *right*。
### 访问者
所谓访问者其实就是一个对象,该对象上面会有一些特殊的方法,这些特殊的方法会在你到达特定的节点的时候触发。
```js
const MyVisitor = {
Identifier() {
console.log("Called!");
}
};
```
该访问者对象会在遍历这颗树的时候,当遇见 Identifier 节点的时候就会被调用。
例如上面的那颗 AST 树,我们只表示 type,表示出来的形式如下:
```js
- FunctionDeclaration
- Identifier (id)
- Identifier (params[0])
- BlockStatement (body)
- ReturnStatement (body)
- BinaryExpression (argument)
- Identifier (left)
- Identifier (right)
```
因此在遍历上面这颗树的时候,Identifier 方法就会被调用四次。
有些时候我们可以针对特定的节点定义进入时要调用的方法,退出时要调用的方法
```js
const MyVisitor = {
Identifier: {
enter() {
console.log("Entered!");
},
exit() {
console.log("Exited!");
}
}
};
```
这里还是以上面的抽象语法树为例,整体的进入节点和退出节点的流程如下:
```js
进入 FunctionDeclaration
进入 Identifier (id)
走到尽头
退出 Identifier (id)
进入 Identifier (params[0])
走到尽头
退出 Identifier (params[0])
进入 BlockStatement (body)
进入 ReturnStatement (body)
进入 BinaryExpression (argument)
进入 Identifier (left)
走到尽头
退出 Identifier (left)
进入 Identifier (right)
走到尽头
退出 Identifier (right)
退出 BinaryExpression (argument)
退出 ReturnStatement (body)
退出 BlockStatement (body)
退出 FunctionDeclaration
```
现在你可能比较好奇的是访问者对象除了 Identifier 方法,还能够有哪些方法?
一般来讲,不同的节点类型就有节点 type 所对应的方法,例如:
- *Identifier(path, state)*: 这个方法在遍历到标识符节点时会被调用。
- *FunctionDeclaration(path, state)*: 这个方法在遍历到函数声明节点时会被调用。
至于节点究竟有哪些类型,可以参阅 estree:https://github.com/estree/estree/blob/master/es5.md
### 路径
AST 是由一个一个的节点组成的,但是这些节点之间并非孤立的,而是彼此之间有一些联系的。因此有一个 path 对象,该对象主要就是记录节点和节点之间的一些关系。path 对象里面不仅仅包含了节点本身的信息,还包含了节点和父节点、子节点、兄弟节点之间的关系。
这样做的好处在于我们使用了一个相对简单的对象来表示节点之间复杂关系,不需要在每个节点里面来保存节点之间关系的信息。
在实际编写插件的时候,我们经常就会利用 path 对象来获取节点的相关信息:
```js
const babel = require("@babel/core");
const traverse = require("@babel/traverse").default;
const code = `function square(n) {
return n * n;
}`;
const ast = babel.parse(code);
// traverse 接收两个参数
// 第一个参数就是抽象语法树
// 第二个参数就是访问者对象
traverse(ast, {
enter(path) {
console.log(path.node.type);
},
});
```
### 状态
在遍历和修改抽象语法树的时候,应该尽量避免全局状态的问题
例如,现在我们有一个需求,重命名一个函数的参数。
```js
let paramName; // 存储函数参数名
const MyVisitor = {
FunctionDeclaration(path) {
const param = path.node.params[0]; // 同 path 对象拿到当前节点的参数
paramName = param.name; // 将参数的名称存储到 paramName 里面(全局变量)
param.name = "x";
},
Identifier(path) {
// 之后,进入到每一个 Identifier 类型的节点的时候
// 判断当前节点的名称是否等于 paramName(之前的函数参数名称)
if (path.node.name === paramName) {
// 进行修改
path.node.name = "x";
}
}
};
```
上面的代码看上去没有什么问题,但是上面的代码可能在某些情况下不能够正常的工作。
例如在我们要转换的源码文件中就存在 paramName 这个变量,那么这段代码就会出现问题
为了解决这样的问题,我们需要避免全局状态,我们可以在一个访问者对象里面再定义一个访问者对象专门拿来存储状态。
```js
const updateParamNameVisitor = {
Identifier(path) {
if (path.node.name === this.paramName) {
path.node.name = "x";
}
}
};
const MyVisitor = {
FunctionDeclaration(path) {
const param = path.node.params[0];
const paramName = param.name;
param.name = "x";
path.traverse(updateParamNameVisitor, { paramName });
}
};
path.traverse(MyVisitor);
```
# 自定义插件part2
要自定义 babel 的插件,实际上有一个固定的格式:
```js
module.exports = function(babel){
// 该函数会自动传入 babel 对象
// types 也是一个对象,该对象上面有很多的方法,方便我们对 AST 的节点进行操作
const { types } = babel;
return {
name: "插件的名字",
visitor: {
// ...
// 这里书写不同类别的方法,不同的方法会被进入不同类别的节点触发
}
}
}
```
## 示例一
创建一个自定义插件,该插件能够把 ES6 里面的 ** 转换为 Math.pow
在编写自定义插件的时候,会使用到 types 对象的一些方法:
- t.callExpression(callee, arguments):这个函数用于**创建一个**表示函数调用的 *AST* 节点。*callee* 参数是一个表示被调用的函数的表达式节点,*arguments* 参数是一个数组,包含了所有的参数表达式节点。
- *t.memberExpression(object, property, computed = false)*:这个函数用于**创建一个**表示属性访问的 ***AST* 节点**。*object* 参数是一个表示对象的表达式节点,*property* 参数是一个表示属性名的标识符或表达式节点。*computed* 参数是一个布尔值,表示属性名是否是动态计算的。
- *t.identifier( )*: 创建 AST 节点,只不过**创建**的是 identifier 类型的 **AST 节点**。
插件的核心,其实就是创建一些新的 AST 节点,去替换旧的 AST 节点。
插件的代码如下:
```js
// 该插件负责将 ** --> Math.pow
// 例如 2 ** 3 ---> Math.pow(2, 3)
module.exports = function (babel) {
const { types: t } = babel;
return {
name: "transform-to-mathpow",
visitor: {
// 当你遍历 AST 节点的时候
// 遍历到二元表达式的时候会自动执行该方法
BinaryExpression(path) {
// 二元表达式比较多
// 5 + 3
// 1 / 2
// 检查当前的节点的运算符是否是 **
// 如果不是,直接返回
if (path.node.operator !== "**") {
return;
}
// 说明当前是 ** 我们要做一个替换操作
// 首先需要生成新的 AST 节点,因为替换使用新的 AST 节点来替换的旧的 AST 节点
// t.identifier("Math") // ---> Math
// t.identifier("pow") // ---> pow
// pow 需要作为 Math 的一个属性
// Math.pow
// t.memberExpress(t.identifier("Math"), t.identifier("pow"));
const mathpowAstNode = t.callExpression(
t.memberExpression(t.identifier("Math"), t.identifier("pow")),
[path.node.left, path.node.right]
);
// 用新的 AST 节点替换旧的 AST 节点
path.replaceWith(mathpowAstNode);
},
},
};
};
```
在上面的代码中,我们就创建了一个自定义的插件,该插件首先对外暴露一个函数,该函数需要返回一个对象,对象里面就有访问器对象,访问器对象里面会有一些特定的方法,这些方法会在进入到特定的节点的时候被调用。
插件内部做的核心的事情:创建新的 AST 节点,然后去替换旧的 AST 节点。
## 示例二
编写一个自定义插件,该插件能够将箭头函数转为普通的函数。
```js
// a => {...}
// function(a){...}
module.exports = function (babel) {
const { types: t } = babel;
return {
name: "transform-arrow-to-function",
visitor: {
// 当你的节点类型为箭头函数表达式的时候
// 执行特定的方法
ArrowFunctionExpression(path) {
let body; // 存储函数体
if (path.node.body.type !== "BlockStatement") {
// 进入此 if,说明箭头函数是一个表达式,需要将 body 部分转为返回语句
// a => b
// function(a){return b}
body = t.blockStatement([t.returnStatement(path.node.body)]);
} else {
// 可以直接使用箭头函数的方法体
body = path.node.body;
}
// 该方法创建一个普通函数表达式的 AST 节点( function(){} )
const functionExpression = t.functionExpression(
null, // 函数名
path.node.params, // 函数参数,和箭头函数的参数是一致的
body, // 函数方法体
false, // 不是一个生成器函数
path.node.async // 是否是异步函数,和箭头函数是一致的
);
path.replaceWith(functionExpression);
},
},
};
};
```
# 更多工具学习方法
通过学习前面的三个工具,我们发现这些工具有一些共同的特点:
- API
- CLI
- 配置文件
- 规则
- 插件
- VSCode 扩展
## API
这个 API 是每个工具一定会提供的部分,也是一个工具 最最核心 的部分。从本质上来讲,API 就是工具内部对外所暴露的接口,外部可以调用这些接口来完成某项具体的工作。
假设有一个名为 A 的工具:
```js
function doSomethingA(){}
function doSomethingB(){}
module.exports = {
doSomethingA,
doSomethingB
}
```
在上面的代码中,doSomethingA 以及 doSomethingB 就是 A 这个工具对外部所提供的接口。
外界就可以利用这些接口来做一些事情:
```js
const A = require("A");
A.doSomethingA();
A.doSomethingB();
```
回顾我们之前所学习的工具,API 部分基本上都是这么来使用的:
```js
// prettier
const prettier = require("prettier");
// ...
prettier.format(jsSource, options).then((res) => {
// ...
});
// babel
var babel = require('@babel/core');
var result = babel.transform('code();', options);
```
作为一个成熟的工具,一般来讲会有一个专门的页面来描述工具所提供的 API,方便开发者进行查询。
## CLI
CLI 英语全称为 Command line interface,翻译成中文叫做命令行接口,作为一个前端的工具,CLI 部分一般来讲也是会提供。
因为即便上面所提供的 API 部分完全能够满足功能需要,但是作为开发者会比较麻烦,有些时候开发者只是想要简单的使用你的工具,但是你只有 API 的话,开发者还会涉及到自己去编码。因此一般会提供 CLI 命令行工具,开发者只需要通过这些命令就可以实现对应的功能。
```js
prettier --write .
eslint --fix .
```
工具学习多了之后,你会发现这些工具所提供的 CLI 命令行工具,格式基本上都是相同的
```bash
工具名 选项 路径
```
在学习 CLI 这部分的时候,一般来讲主要就是学习 选项 这个部分,看这个工具提供了哪些选项。一般工具的官网也会有一个专门的页面来介绍该工具的 CLI 命令。
CLI 背后仍然是调用的该工具的 API,核心原理就是拿到用户在命令行所输入的参数,然后根据不同的参数来调用对应的 API。
有了这些 CLI 命令行工具后,我们在使用时,一般是将其配置到 package.json 里面:
```js
"scripts": {
"format": "prettier --write .",
"lint": "eslint . --fix"
}
```
## 配置文件
一个成熟的工具,是一定会有配置文件的,配置文件可能存在多种格式,但是一定是会有的。原因很简单,因为再完美的工具都没办法预判开发者在使用时所有的场景。
针对配置文件的学习,主要有以下几个点:
- 支持的配置项有哪些
- 有一些配置项可能你没有配置,但是有默认值
- 配置文件的格式
- 很多工具都可能支持多种格式的配置文件
- 多配置文件的权重文件
- 多配置文件的层叠问题
- 如何在 CLI 中临时指定配置
## 规则
关于这一条,就不是所有的工具都有,具体取决于你的这个工具是做什么的。
例如前面我们所学习的 Prettier 以及 ESLint 就存在规则,因为他俩是做代码格式化和 lint 检查的,如何格式化以及如何 lint 检查需要规则的支持。
无论是 Prettier 还是 ESLint 都提供了一套默认的规则标准,一般来讲,这套默认的规则标准就已经是行业的最佳实践了,因此如果没有什么意外的时候,不要去瞎改,不仅不要去瞎改,而且你自己在写代码的时候,也应该遵循这套规则标准。
```js
// 你写的代码
hello().then(() => {
something()
}).catch(console.error)
// Prettier 格式化的代码
hello()
.then(() => {
something()
})
.catch(console.error)
```
因为有些时候我们不是规则的制定者,可能在公司内部会有统一的规则要求,所以我们还需要知道如何自定义规则。关于规则,一般数量会比较多,但是一般都比较简单,不需要去背,一般用一条就会记住一条。
规则一般也是有一个专门的页面来介绍该工具支持哪些规则配置。
## 插件
插件的本质是一段遵循特定规则的代码,它的作用是用来扩展工具的功能,因此插件的表现不仅仅是一个函数,它可能是一组函数、一个对象、一个配置。
举一个例子,下面是一个 ESLint 里面的插件:
```js
module.exports = {
rules: {
"my-custom-rule": {
create: function (context) {
return {
Identifier(node) {
if (node.name === "badIdentifier") {
context.report({
node,
message: "Don't use 'badIdentifier' as a name!",
});
}
},
};
},
},
},
};
```
另外需要说一下的是,插件不是一个工具的必需项,有的工具支持插件,有的工具不支持插件,取决于你这个工具是做什么的。
比如像 Babel 或者 PostCSS,这些工具本身做的事情非常简单,就是将代码转为抽象语法树,剩下的功能全靠插件来支持。但是有一些工具本身做的事情比较单一,不需要再扩展功能了(terser),你会发现这个工具就不支持插件来扩展功能。
## VSCode 扩展
VSCode 扩展的本质实际上也是在调用这些工具所提供的 API,这就意味着它是在 JS 代码中直接引用和使用工具。
```js
const prettier = require("prettier");
const sourceCode = "function hello ( ) { return 'world'; }";
const formattedCode = prettier.format(sourceCode, { parser: "babel" });
console.log(formattedCode);
```
VSCode 里面关于 Prettier 的扩展,底层做的事情就是类似于上面的事情,只不过会只用更加复杂的配置,并且会将格式化后的结果插入到编辑器的文件里面,而非打印到控制台。
## 总结
前端的工具是无穷无尽的,比起学习这些工具本身,更重要的是学会如何学习这些工具的正确姿势,授人以鱼不如授人以渔。
一般来讲一款工具会包含如下的东西:
✅ 一定会有 ⭕️ 可能会有
- 这个工具是做什么的(这个你首先肯定需要知道)
- *API* ✅
- *CLI* ✅
- 配置文件 ✅
- 规则 ⭕️
- 插件 ⭕️
- *VSCode* 扩展 ⭕️
# Terser
*Terser* 是一个流行的 *JavaScript* 解析器和压缩器,它可以帮助你优化 *JavaScript* 代码以减少其大小,从而提高 *web* 页面的加载速度。*Terser* 是 *Uglify-es* 的替代品,后者已经停止维护,*Terser* 支持 *ES6* 和更高版本的 *JavaScript*。
*Terser* 官网:*https://terser.org/*
以下是 *Terser* 的一些主要功能:
- 删除无用的代码:*Terser* 可以自动删除你的代码中的无用代码(也称为 "*dead code*"),例如未被调用的函数和未被使用的变量。
- 压缩和混淆代码:*Terser* 可以将你的代码压缩到尽可能小的大小。它可以移除空格和注释,将变量和函数名重命名为短的名称,以及使用其他的压缩技术。这也有助于混淆你的代码,使得它更难被人类理解,从而提高代码的安全性。
- 保留注释:虽然 *Terser* 默认会移除所有的注释,但你可以配置它保留某些注释,例如包含特定关键词的注释。
- 源码映射支持:*Terser* 支持生成源码映射(*source map*),这可以帮助你在压缩后的代码中进行调试。
- 支持 *ES6* 及更高版本:*Terser* 支持最新版本的 *JavaScript*,包括 *ES6、ES7、ES8* 等。
这一次我们在学习这个新工具的时候,我们就按照上一节课介绍的方式来学习:
- API
- CLI
- 配置文件
## API
首先创建一个项目 terser-demo,使用 pnpm init 进行一个初始化,安装相应的依赖:
```js
pnpm add terser -D
```
接下来在 src/index.js 文件里面写入了一些要压缩的代码,之后在 src 下面创建 compress.js,打算利用 terser 的 api 对文件进行压缩。
compress.js 的代码如下:
```js
// 对源码进行压缩
const { minify } = require("terser");
const path = require("path");
const fs = require("fs");
// 定义输入和输出文件的路径
const codePath = path.resolve("src", "index.js");
const outDir = "dist";
const outPath = path.resolve(outDir, "index.js");
const outSourcemapPath = path.resolve(outDir, "index.js.map");
// 读取源码文件
const code = {
"index.js": fs.readFileSync(codePath, "utf8"),
};
// 压缩对应的配置项
const options = {
sourceMap: {
filename: "index.js",
url: "index.js.map",
},
};
// 准备工作完成后,接下来就调用 API 进行压缩
minify(code, options)
.then((result) => {
// console.log(result)
// 将压缩后的内容写入到规定的位置
if (!fs.existsSync(outDir)) {
fs.mkdirSync(outDir, { recursive: true });
}
fs.writeFileSync(outPath, result.code);
// 生成 sourcemap
if (result.map) {
fs.writeFileSync(outSourcemapPath, result.map);
}
console.log("压缩工作已完成...");
})
.catch((err) => {
console.log("压缩工作失败,错误信息如下:");
console.error(err);
});
```
在上面的代码中,我们用到了 terser 的 minify 这个方法来对代码进行压缩。其中关于 options 压缩配置对象这一块,可以在 https://terser.org/docs/api-reference/#minify-options-structure 看到能够配置的所有选项。
关于 terer 具体的 API,可以参阅官网:https://terser.org/docs/api-reference/
## CLI
CLI 部分背后调用的就是 API,在官网的 https://terser.org/docs/cli-usage/ 这个位置可以看到该工具所支持的 CLI
基本的格式如下:
```bash
terser [input files] [options]
```
- input files:要压缩的文件
- options:压缩配置项
例如:
```js
"scripts": {
// ...
"compress": "terser ./src/index.js -o ./dist/index.js --source-map -o ./dist/index.js"
},
```
## 配置文件
terser 由于这个工具比较小,所以没有支持单独的配置文件,但是你要注意不支持单独的配置文件不代表不支持配置,作为一个工具,肯定是支持配置的。
你可以在 https://terser.org/docs/options/ 看到该工具所有的配置项。
# SWC
*SWC* 英文全称为 *Speedy Web Compiler*,翻译成中文为“快速网页编译器”。
官网地址:https://swc.rs/

来看一下官方的介绍:
>*SWC is an extensible Rust-based platform for the next generation of fast developer tools. It's used by tools like Next.js, Parcel, and Deno, as well as companies like Vercel, ByteDance, Tencent, Shopify, and more.*
>
>*SWC can be used for both compilation and bundling. For compilation, it takes JavaScript / TypeScript files using modern JavaScript features and outputs valid code that is supported by all major browsers.*
中文的意思就是:
*SWC* 是一个基于 *Rust* 的可扩展平台,用于下一代高速开发工具。它被 *Next.js、Parcel、Deno* 等工具,以及 *Vercel*、字节跳动、腾讯、*Shopify* 等公司广泛使用。
*SWC* 既可以用于编译,也可以用于打包。在编译方面,它接受使用现代 *JavaScript* 功能的 *JavaScript / TypeScript* 文件,并输出由所有主流浏览器支持的有效代码。
那么 *SWC* 的特点是什么呢?就一个特点:快。
看一看官方对于 *SWC* 速度的描述:
>*SWC is 20x faster than Babel on a single thread and 70x faster on four cores.*
也就是说,当只使用一个 *CPU* 核心(即单线程环境)时,*SWC* 比 *Babel* 快 *20* 倍。而当使用四个 *CPU* 核心(即四核环境,能够进行并行处理)时,*SWC* 比 *Babel* 快 *70* 倍。
没错,*SWC* 对标的就是 *Babel*,力图成为 *Babel* 的替代品。而 *SWC* 之所以可以那么快,主要是由于以下几个因素:
1. 编程语言:*SWC* 是用 *Rust* 语言编写的。*Rust* 是一种系统编程语言,它旨在提供内存安全性,无数据竞争,并且有着高效的性能。*Rust* 的执行速度通常比 *JavaScript* 快。
2. 并行处理:*Rust* 具有优秀的并行处理和并发能力。当在多核 *CPU* 上运行时,*SWC* 能够有效地利用这些核心并行执行任务,从而大大提高了处理速度。
3. 优化的设计:*SWC* 设计上对性能进行了优化。例如,它使用一次性遍历(*single-pass traversal*)来转换代码,这种方法比 *Babel* 使用的多次遍历更高效。
4. 跳过不必要的工作:与 *Babel* 不同,*SWC* 可以跳过一些不必要的工作,例如不需要生成和处理 *source maps*,除非明确需要。
早期各种前端工具都是基于 Node.js 来写的,Node.js 本身只是一个 JS 的运行时,JS 本身又是一门单线程解释语言,所以 JS 的运行速度不会比像 Rust、Go 这种语言快。
这几年开始就有一种趋势,用其他的编程语言来编写前端工具,甚至还专门出现了一个词语 rustification(锈化),就是指使用 rust 语言来翻新已有的前端工具,从而提升工具的性能。
- *SWC*:使用 *Rust* 编写的超快速的 *JavaScript/TypeScript* 编译器。它的目标是替代*Babel*。
- *Turbopack*:*Vercel* 声称这是 *Webpack* 的继任者,用 *Rust* 编写,在大型应用中,展示出了 *10* 倍于 *Vite*、*700* 倍于 *Webpack* 的速度。
- *esbuild*: *esbuild* 是由 *Go* 编写的构建打包工具,对标的是 *webpack、rollup* 和 *parcel* 等工具,在静态语言的加持下,*esbuild* 的构建速度可以是传统 *js* 构建工具的 *10-100* 倍,就好像跑车和自行车的区别。
- *Rome*: 是一个使用 *Rust* 编写的全栈工具链,它打算整合各种前端开发工具的功能,从而提供一个统一的、一体化的开发体验。*Rome* 的目标是替代或集成诸如 *Babel、ESLint、Webpack、Prettier、Jest* 等多个分散的工具。
- *Deno*: 是一个使用 *Rust* 和 *TypeScript* 编写的 *JavaScript/TypeScript* 运行时,它的目标是成为一个更安全、更高效的 *Node.js* 替代品。
虽然编写这些工具的语言发生了变化,但是我们使用这些工具的方法是没变的:
- API
- CLI
- 配置
## API
新建一个项目 swc-demo,使用 pnpm init 进行初始化,安装依赖
```bash
pnpm add @swc/core -D
```
接下来在 src/index.js 中书写测试代码:
```js
const greet = (name) => `Hello, ${name}!`;
console.log(greet("World"));
```
之后在项目根目录下创建 compile.js,在该文件中利用 swc 提供的 api 对文件进行编译
```js
const swc = require("@swc/core");
const fs = require("fs");
const path = require("path");
// 拼接路径
const codePath = path.resolve("src", "index.js");
const sourceCode = fs.readFileSync(codePath, "utf8");
const outDir = path.resolve(__dirname, "dist");
swc
.transform(sourceCode, {
jsc: {
target: "es5", // 设置目标JavaScript版本
parser: {
syntax: "ecmascript", // 设置源代码的语法
},
},
})
.then((res) => {
// console.log(res.code)
if (!fs.existsSync(outDir)) {
fs.mkdirSync(outDir);
}
const outputFilePath = path.join(outDir, "index.js");
fs.writeFileSync(outputFilePath, res.code);
})
.catch((err) => {
console.error(err);
});
```
## CLI
首先需要安装相应的 CLI 工具
```bash
pnpm add @swc/cli -D
```
之后就可以在 https://swc.rs/docs/usage/cli 看到 swc 所支持的所有的 CLI 命令
然后在 package.json 中进行 CLI 的配置即可,例如:
```js
"scripts": {
// ...
"swc": "swc src -d lib"
},
```
## 配置
我们在使用 transform 方法的时候,第二个参数就是一个配置对象。
你可以在 https://swc.rs/docs/configuration/compilation 看到所有所支持的配置选项。
如果你没有配置文件,那么会有一个默认的配置设置:
```js
{
// 这个配置项用于设置 JavaScript的 编译选项
"jsc": {
// 这个配置项用于设置解析器的选项
"parser": {
// 设置源代码的语法,可以是 ecmascript、jsx、typescript 或 tsx
"syntax": "ecmascript",
// 是否启用JSX语法
"jsx": false,
// 是否启用动态 import() 语句
"dynamicImport": false,
// 是否启用私有方法和访问器
"privateMethod": false,
// 是否启用函数绑定语法(::操作符)
"functionBind": false,
// 是否启用 export v from 'mod' 语法
"exportDefaultFrom": false,
// 是否启用 export * as ns from 'mod' 语法
"exportNamespaceFrom": false,
// 是否启用装饰器语法
"decorators": false,
// 是否在导出之前应用装饰器
"decoratorsBeforeExport": false,
// 是否启用顶级 await 语法
"topLevelAwait": false,
// 是否启用 import.meta 语法
"importMeta": false,
// 是否保留所有注释
"preserveAllComments": false
},
// 设置转换插件,通常不需要手动设置
"transform": null,
// 设置目标 JavaScript 版本
// 例如 es3、es5、es2015、es2016、es2017、es2018、es2019、es2020
"target": "es5",
// 是否启用宽松模式,这会使编译后的代码更简短,但可能不完全符合规范
"loose": false,
// 是否引用外部的 helper 函数,而不是内联它们
"externalHelpers": false,
// 是否保留类名,这需要版本 v1.2.50 或更高
// 且 target 需要设置为 es2016 或更高
"keepClassNames": false
},
// 这个配置项用于指示输入的源代码是否是模块代码。
// 如果是,那么 import 和 export 语句将被正常处理
// 否则,它们将被视为语法错误
"isModule": false
}
```