https://github.com/TencentARC/SmartEdit
Official code of SmartEdit [CVPR-2024 Highlight]
https://github.com/TencentARC/SmartEdit
Last synced: over 1 year ago
JSON representation
Official code of SmartEdit [CVPR-2024 Highlight]
- Host: GitHub
- URL: https://github.com/TencentARC/SmartEdit
- Owner: TencentARC
- Created: 2023-12-05T14:58:15.000Z (over 2 years ago)
- Default Branch: main
- Last Pushed: 2024-06-21T11:29:00.000Z (about 2 years ago)
- Last Synced: 2025-03-23T14:08:32.985Z (over 1 year ago)
- Language: Python
- Homepage:
- Size: 1.7 MB
- Stars: 309
- Watchers: 13
- Forks: 11
- Open Issues: 19
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
- awesome-diffusion-categorized - [Code
- Awesome-Segment-Anything - [code
README

## SmartEdit: Exploring Complex Instruction-based Image Editing with Multimodal Large Language Models (CVPR-2024 Highlight)
[[Paper](https://arxiv.org/abs/2312.06739)]
[[Project Page](https://yuzhou914.github.io/SmartEdit/)]
[Demo]
🔥🔥 2024.04. SmartEdit is released!
🔥🔥 2024.04. SmartEdit is selected as highlight by CVPR-2024!
🔥🔥 2024.02. SmartEdit is accepted by CVPR-2024!
If you are interested in our work, please star ⭐ our project.
### SmartEdit Framework
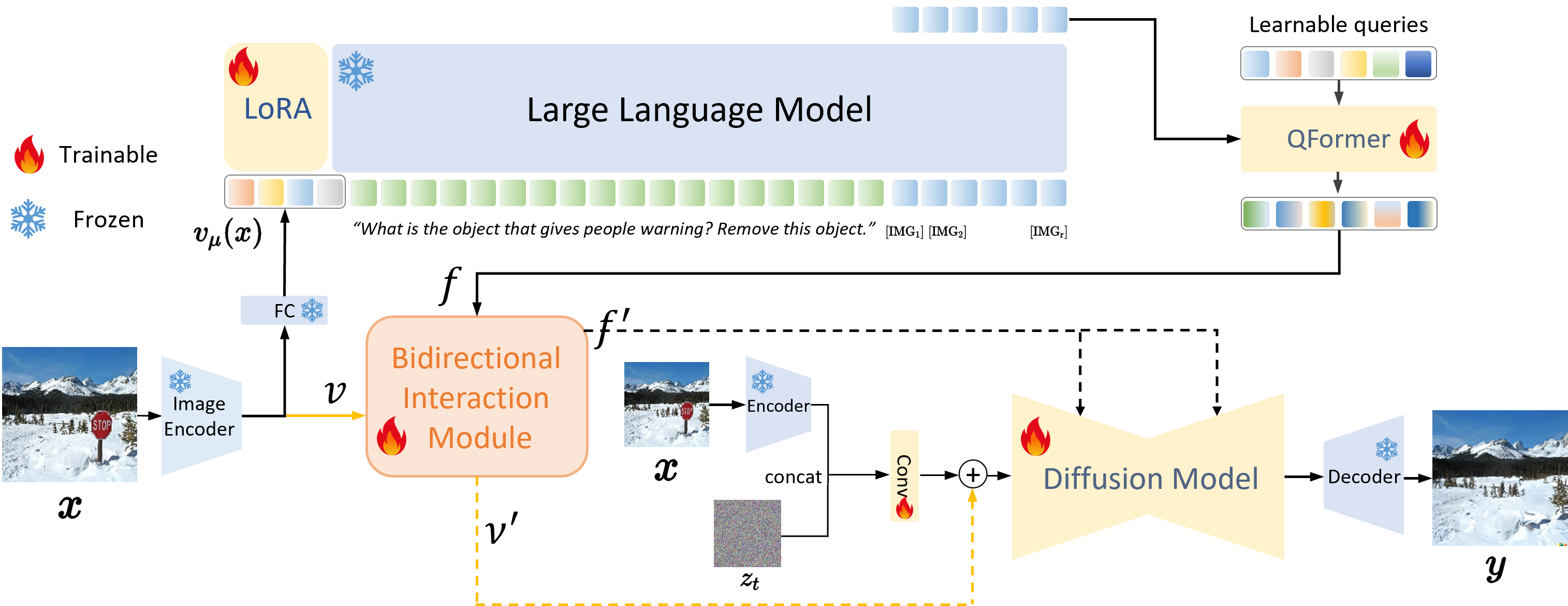
### SmartEdit on Understanding Scenarios

### SmartEdit on Reasoning Scenarios

### Dependencies and Installation
pip install torch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 --index-url https://download.pytorch.org/whl/cu118
pip install -r requirements.txt
git clone https://github.com/Dao-AILab/flash-attention.git
cd flash-attention
pip install . --no-build-isolation
cd ..
### Training model preparation
- Please put the prepared checkpoints in file `checkpoints`.
- Prepare Vicuna-1.1-7B/13B checkpoint: please download [Vicuna-1.1-7B](https://huggingface.co/lmsys/vicuna-7b-v1.1) and [Vicuna-1.1-13B](https://huggingface.co/lmsys/vicuna-13b-v1.1) in link.
- Prepare LLaVA-1.1-7B/13B checkpoint: please follow the [LLaVA instruction](https://github.com/haotian-liu/LLaVA/blob/main/docs/MODEL_ZOO.md) to prepare LLaVA-1.1-7B/13B weights.
- Prepare InstructDiffusion checkpoint: please download [InstructDiffusion(v1-5-pruned-emaonly-adaption-task.ckpt)](https://github.com/cientgu/InstructDiffusion/tree/main) and the repo in link. Download them first and use `python convert_original_stable_diffusion_to_diffusers.py --checkpoint_path "./checkpoints/InstructDiffusion/v1-5-pruned-emaonly-adaption-task.ckpt" --original_config_file "./checkpoints/InstructDiffusion/configs/instruct_diffusion.yaml" --dump_path "./checkpoints/InstructDiffusion_diffusers"`.
### Training dataset preparation
- Please put the prepared checkpoints in file `dataset`.
- Prepare CC12M dataset: https://storage.googleapis.com/conceptual_12m/cc12m.tsv.
- Prepare InstructPix2Pix and MagicBrush datasets: these two datasets [InstructPix2Pix](https://huggingface.co/datasets/timbrooks/instructpix2pix-clip-filtered) and [MagicBrush](https://huggingface.co/datasets/osunlp/MagicBrush) are prepared in diffusers website. Download them first and use `python process_HF.py` to process them from "parquet" file to "arrow" file.
- Prepare RefCOCO, GRefCOCO and COCOStuff datasets: please follow [InstructDiffusion](https://github.com/cientgu/InstructDiffusion/tree/main/dataset) to prepare them.
- Prepare LISA ReasonSeg dataset: please follow [LISA](https://github.com/dvlab-research/LISA#dataset) to prepare it.
- Prepare our synthetic editing dataset: please download in [link](https://drive.google.com/drive/folders/1SMkQe1U9av4YNML5wqOLN7crLiNs0aTF).
### Stage-1: textual alignment with CC12M
- Use the script to train:
bash scripts/TrainStage1_7b.sh
bash scripts/TrainStage1_13b.sh
- Then, use the script to inference:
python test/TrainStage1_inference.py --model_name_or_path "./checkpoints/vicuna-7b-v1-1" --LLaVA_model_path "./checkpoints/LLaVA-7B-v1" --save_dir './checkpoints/stage1_CC12M_alignment_7b/Results-100000' --pretrain_model "./checkpoints/stage1_CC12M_alignment_7b/embeddings_qformer/checkpoint-150000.bin" --get_orig_out --LLaVA_version "v1.1-7b"
python test/TrainStage1_inference.py --model_name_or_path "./checkpoints/vicuna-13b-v1-1" --LLaVA_model_path "./checkpoints/LLaVA-13B-v1" --save_dir './checkpoints/stage1_CC12M_alignment_13b/Results-100000' --pretrain_model "./checkpoints/stage1_CC12M_alignment_13b/embeddings_qformer/checkpoint-150000.bin" --get_orig_out --LLaVA_version "v1.1-13b"
### Stage-2: SmartEdit training
- Use the script to train first:
bash scripts/MLLMSD_7b.sh
bash scripts/MLLMSD_13b.sh
- Then, use the script to train:
bash scripts/SmartEdit_7b.sh
bash scripts/SmartEdit_13b.sh
### Inference
- Please download [SmartEdit-7B](https://huggingface.co/TencentARC/SmartEdit-7B) and [SmartEdit-13B](https://huggingface.co/TencentARC/SmartEdit-13B) checkpoints and put them in file `checkpoints`
- Please download [Reason-Edit evaluation benchmark](https://drive.google.com/drive/folders/1QGmye23P3vzBBXjVj2BuE7K3n8gaWbyQ) and put it in file `dataset`
- Use the script to inference on understanding and reasoning scenes:
python test/DS_SmartEdit_test.py --is_understanding_scenes True --model_name_or_path "./checkpoints/vicuna-7b-v1-1" --LLaVA_model_path "./checkpoints/LLaVA-7B-v1" --save_dir './checkpoints/SmartEdit-7B/Understand-15000' --steps 15000 --total_dir "./checkpoints/SmartEdit-7B" --sd_qformer_version "v1.1-7b" --resize_resolution 256
python test/DS_SmartEdit_test.py --is_reasoning_scenes True --model_name_or_path "./checkpoints/vicuna-7b-v1-1" --LLaVA_model_path "./checkpoints/LLaVA-7B-v1" --save_dir './checkpoints/SmartEdit-7B/Reason-15000' --steps 15000 --total_dir "./checkpoints/SmartEdit-7B" --sd_qformer_version "v1.1-7b" --resize_resolution 256
python test/DS_SmartEdit_test.py --is_understanding_scenes True --model_name_or_path "./checkpoints/vicuna-13b-v1-1" --LLaVA_model_path "./checkpoints/LLaVA-13B-v1" --save_dir './checkpoints/SmartEdit-13B/Understand-15000' --steps 15000 --total_dir "./checkpoints/SmartEdit-13B" --sd_qformer_version "v1.1-13b" --resize_resolution 256
python test/DS_SmartEdit_test.py --is_reasoning_scenes True --model_name_or_path "./checkpoints/vicuna-13b-v1-1" --LLaVA_model_path "./checkpoints/LLaVA-13B-v1" --save_dir './checkpoints/SmartEdit-13B/Reason-15000' --steps 15000 --total_dir "./checkpoints/SmartEdit-13B" --sd_qformer_version "v1.1-13b" --resize_resolution 256
- You can use different resolution to inference on reasoning scenes:
python test/DS_SmartEdit_test.py --is_reasoning_scenes True --model_name_or_path "./checkpoints/vicuna-7b-v1-1" --LLaVA_model_path "./checkpoints/LLaVA-7B-v1" --save_dir './checkpoints/SmartEdit-7B/Reason-384-15000' --steps 15000 --total_dir "./checkpoints/SmartEdit-7B" --sd_qformer_version "v1.1-7b" --resize_resolution 384
python test/DS_SmartEdit_test.py --is_reasoning_scenes True --model_name_or_path "./checkpoints/vicuna-13b-v1-1" --LLaVA_model_path "./checkpoints/LLaVA-13B-v1" --save_dir './checkpoints/SmartEdit-13B/Reason-384-15000' --steps 15000 --total_dir "./checkpoints/SmartEdit-13B" --sd_qformer_version "v1.1-13b" --resize_resolution 384
### Explanation of new tokens:
- The original vocabulary size of LLaMA-1.1 (both 7B and 13B) is 32000, while LLaVA-1.1 (both 7B and 13B) is 32003, which additionally expands 32000="", 32001="", 32002="". In SmartEdit, we maintain "" and "" in LLaVA and remove "". Besides, we add one special token called "img" for system message to generate image, and 32 tokens to summarize image and text information for conversation system ("..."). Therefore, the original vocabulary size of SmartEdit is 32035, where "img"=32000, ""=32001, ""=32002, and the 32 new tokens are 32003~32034. Only the 32 new tokens are effective embeddings for QFormer.
- We especially explain the meanings of new embeddings here to eliminate misunderstanding, and there is no need to merge lora after you download SmartEdit checkpoints. If you have download the checkpoints of SmartEdit before 2024.4.28, please only re-download checkpoints in LLM-15000 folder. Besides, when preparing [LLaVA checkpoints](https://github.com/haotian-liu/LLaVA/blob/main/docs/MODEL_ZOO.md), you must firstly convert the LLaMA-delta-weight, since it is under policy protection, and LLaVA fine-tunes the whole LLaMA weights.
### Metrics Evaluation
- Use the script to compute metrics on Reason-Edit (256x256 resolution):
python test/metrics_evaluation.py --edited_image_understanding_dir "./checkpoints/SmartEdit-7B/Understand-15000" --edited_image_reasoning_dir "./checkpoints/SmartEdit-7B/Reason-15000"
python test/metrics_evaluation.py --edited_image_understanding_dir "./checkpoints/SmartEdit-13B/Understand-15000" --edited_image_reasoning_dir "./checkpoints/SmartEdit-13B/Reason-15000"
### Todo List
- [ ] Release checkpoints that could conduct "add" functionality (e.g., "Add a smaller eleplant").
### Contact
For any question, feel free to email yuzhouhuang@link.cuhk.edu.cn and lb.xie@siat.ac.cn
### Citation
```
@inproceedings{huang2024smartedit,
title={Smartedit: Exploring complex instruction-based image editing with multimodal large language models},
author={Huang, Yuzhou and Xie, Liangbin and Wang, Xintao and Yuan, Ziyang and Cun, Xiaodong and Ge, Yixiao and Zhou, Jiantao and Dong, Chao and Huang, Rui and Zhang, Ruimao and others},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={8362--8371},
year={2024}
}
```