https://github.com/YoongiKim/AutoCrawler
Google, Naver multiprocess image web crawler (Selenium)
https://github.com/YoongiKim/AutoCrawler
bigdata chromedriver crawler customizable deep-learning google image-crawler multiprocess python selenium thread
Last synced: about 1 year ago
JSON representation
Google, Naver multiprocess image web crawler (Selenium)
- Host: GitHub
- URL: https://github.com/YoongiKim/AutoCrawler
- Owner: YoongiKim
- License: apache-2.0
- Created: 2018-11-21T16:01:14.000Z (over 7 years ago)
- Default Branch: master
- Last Pushed: 2024-04-15T10:15:21.000Z (over 2 years ago)
- Last Synced: 2025-04-14T19:59:29.496Z (over 1 year ago)
- Topics: bigdata, chromedriver, crawler, customizable, deep-learning, google, image-crawler, multiprocess, python, selenium, thread
- Language: Python
- Homepage:
- Size: 168 MB
- Stars: 1,659
- Watchers: 44
- Forks: 420
- Open Issues: 2
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- awesome-python-resources - AutoCrawler
README
# AutoCrawler
Google, Naver multiprocess image crawler (High Quality & Speed & Customizable)

# How to use
1. Install Chrome
2. pip install -r requirements.txt
3. Write search keywords in keywords.txt
4. **Run "main.py"**
5. Files will be downloaded to 'download' directory.
# Arguments
usage:
```
python3 main.py [--skip true] [--threads 4] [--google true] [--naver true] [--full false] [--face false] [--no_gui auto] [--limit 0]
```
```
--skip true Skips keyword if downloaded directory already exists. This is needed when re-downloading.
--threads 4 Number of threads to download.
--google true Download from google.com (boolean)
--naver true Download from naver.com (boolean)
--full false Download full resolution image instead of thumbnails (slow)
--face false Face search mode
--no_gui auto No GUI mode. (headless mode) Acceleration for full_resolution mode, but unstable on thumbnail mode.
Default: "auto" - false if full=false, true if full=true
(can be used for docker linux system)
--limit 0 Maximum count of images to download per site. (0: infinite)
--proxy-list '' The comma separated proxy list like: "socks://127.0.0.1:1080,http://127.0.0.1:1081".
Every thread will randomly choose one from the list.
```
# Full Resolution Mode
You can download full resolution image of JPG, GIF, PNG files by specifying --full true

# Data Imbalance Detection
Detects data imbalance based on number of files.
When crawling ends, the message show you what directory has under 50% of average files.
I recommend you to remove those directories and re-download.
# Remote crawling through SSH on your server
```
sudo apt-get install xvfb <- This is virtual display
sudo apt-get install screen <- This will allow you to close SSH terminal while running.
screen -S s1
Xvfb :99 -ac & DISPLAY=:99 python3 main.py
```
# Customize
You can make your own crawler by changing collect_links.py
# How to fix issues
As google site consistently changes, you may need to fix ```collect_links.py```
1. Go to google image. [https://www.google.com/search?q=dog&source=lnms&tbm=isch](https://www.google.com/search?q=dog&source=lnms&tbm=isch)
2. Open devloper tools on Chrome. (CTRL+SHIFT+I, CMD+OPTION+I)
3. Designate an image to capture.
4. Checkout collect_links.py
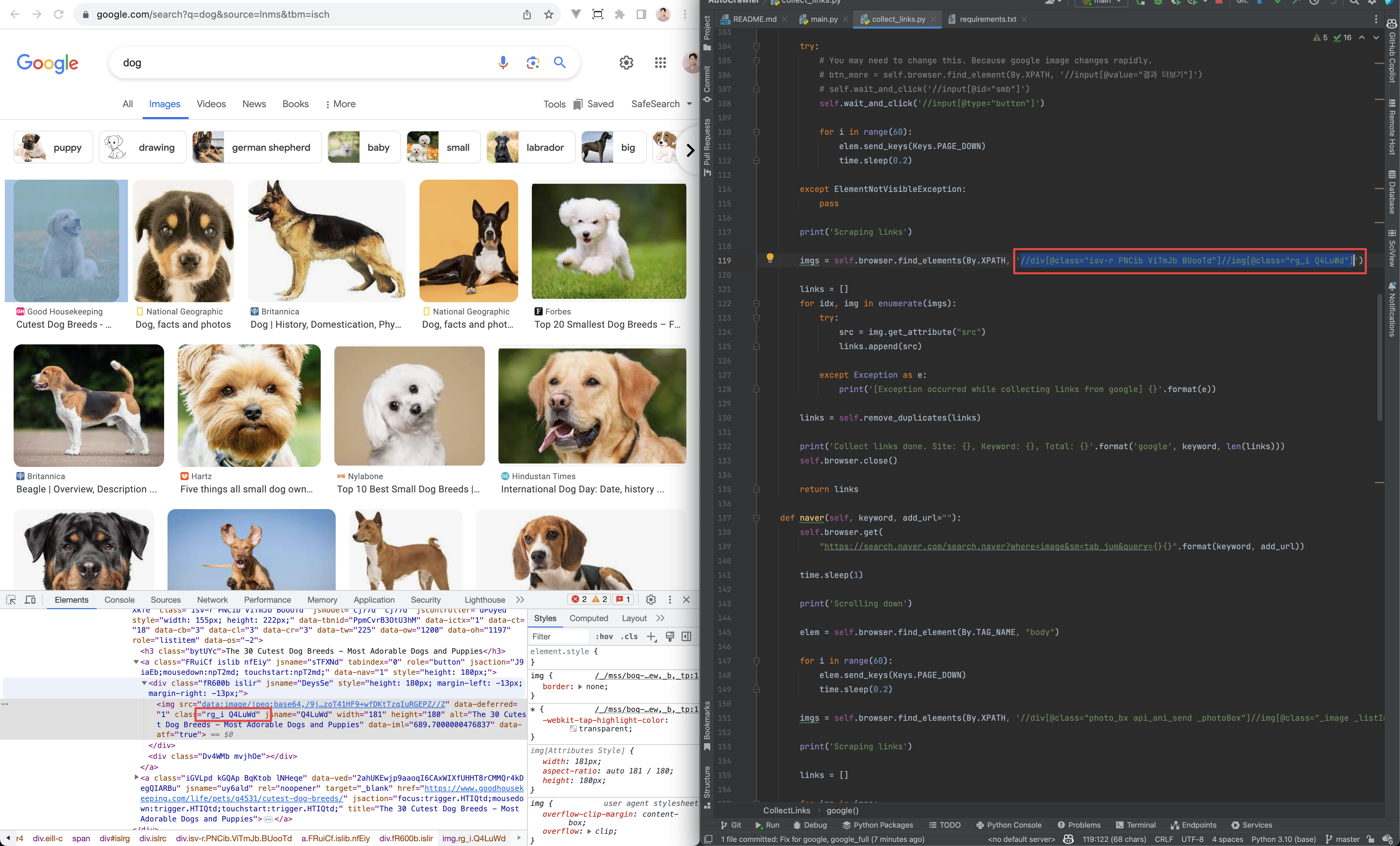
5. Docs for XPATH usage: [https://www.w3schools.com/xml/xpath_syntax.asp](https://www.w3schools.com/xml/xpath_syntax.asp)
6. You can test XPATH using CTRL+F on your chrome developer tools.
7. You need to find logic to crawling to work.