https://github.com/YoungXIAO13/ObjectPoseEstimationSummary
Resources (papers, datasets, rendering methods) in the domain of object pose estimation.
https://github.com/YoungXIAO13/ObjectPoseEstimationSummary
Last synced: over 1 year ago
JSON representation
Resources (papers, datasets, rendering methods) in the domain of object pose estimation.
- Host: GitHub
- URL: https://github.com/YoungXIAO13/ObjectPoseEstimationSummary
- Owner: YoungXIAO13
- License: mit
- Created: 2019-07-18T11:52:58.000Z (almost 7 years ago)
- Default Branch: master
- Last Pushed: 2023-07-09T09:55:31.000Z (about 3 years ago)
- Last Synced: 2024-08-01T04:02:07.690Z (almost 2 years ago)
- Language: Python
- Homepage:
- Size: 16 MB
- Stars: 701
- Watchers: 28
- Forks: 87
- Open Issues: 1
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- awesomeai - Object Pose Estimation
- awesome-ai-awesomeness - Object Pose Estimation
- awesome-6d-object - here
README
# Awesome Object Pose Estimation [\[Paper List\]](https://github.com/YoungXIAO13/ObjectPoseEstimationSummary/blob/master/paper.md)
A repo to summarize resources used in object pose estimation as well as viewpoint estimation.
In the following tables, 3D CAD model is noted as **model** and 2D pictured object is noted as **object**.
## Contributing
Contributions are welcome.
Please see the **Table of Content** which lists the things included in this repo.
If you wish to contribute within these boundaries, feel free to send a PR.
If you have suggestions for new sections to be included, please raise an issue and discuss before sending a PR.
## Table of Content
* [Resources :sunglasses:](https://github.com/YoungXIAO13/ObjectPoseEstimationSummary/blob/master/paper.md)
* [Objects in the wild :camera:](#objects-in-the-wild-camera)
* [Objects in the controlled environments :movie_camera:](#objects-in-the-controlled-environments-movie_camera)
* [3D model datasets :bike:](#3d-model-datasets-bike)
* [Rendering methods :bicyclist:](#rendering-methods-mountain_bicyclist)
## Objects in the wild :camera:
In this table, **Pix3D** provides accurate 2D-3D alignment
while others provide a coarse alignment.
**PASCAL3D+** is the de facto benchmark used for viewpoint estimation.
| Dataset | Sample image | Annotation | Statistics | Reference |
| :-----: | :-----: | :-----: | :-----: | :-----: |
| [Objectron](https://github.com/google-research-datasets/Objectron/) |  | 3D Bounding Box | **15K** annotated videos and **4M** annotated images | [CVPR 2021](https://openaccess.thecvf.com/content/CVPR2021/html/Ahmadyan_Objectron_A_Large_Scale_Dataset_of_Object-Centric_Videos_in_the_CVPR_2021_paper.html) |
| [ApolloCar3D](http://apolloscape.auto/car_instance.html) |  | 6D Pose + Mask | **34** car models with **60K+** objects in **5,277** images | [CVPR 2019](https://arxiv.org/abs/1811.12222) |
| [Pix3D](http://pix3d.csail.mit.edu/) |  | 6D Pose + Mask | **9** categories containing **395 models** in **10,069** images | [CVPR 2018](http://pix3d.csail.mit.edu/papers/pix3d_cvpr.pdf) |
| [ObjectNet3D](http://cvgl.stanford.edu/projects/objectnet3d/) |  | Euler Angles + BoundingBox | **100** categories with **201,888** objects in **90,127** images | [ECCV 2016](http://cvgl.stanford.edu/papers/xiang_eccv16.pdf) |
| [PASCAL3D+](http://cvgl.stanford.edu/projects/pascal3d.html) |  | Euler Angles + BoundingBox | **12** categories with **36,292** objects in **30,889** images | [WACV 2014](https://www-cs.stanford.edu/~roozbeh/papers/wacv14.pdf) |
| [KITTI](http://www.cvlibs.net/datasets/kitti/eval_object.php) |  | 3D BoundingBox | **80,256** objects in **14,999** images | [CVPR 2012](http://www.cvlibs.net/publications/Geiger2012CVPR.pdf) |
## Objects in the controlled environments :movie_camera:
This table lists the datasets commonly known as **BOP: Benchmark 6D Object Pose Estimation**,
which provide accurate 3D object models and accurate 2D-3D alignment.
You can download all the BOP datasets [**here**](https://bop.felk.cvut.cz/datasets/) and
use the [**toolkit**](https://github.com/thodan/bop_toolkit) provided by the organizers.
After downloading the data,
you can use our code ```data/BOP/ply2obj.py``` to convert original **.ply** files to **.obj** files,
and run ```data/BOP/create_annotation.py``` to create a single annotation file for all the scenes in a dataset.
Datasets format can be found [here](https://github.com/thodan/bop_toolkit/blob/master/docs/bop_datasets_format.md),
we use **instance id** in our annotation to indicate different instances pictured in the same image.
| Dataset | Sample image | Annotation | Statistics | Reference |
| :-----: | :-----: | :-----: | :-----: | :-----: |
| [GraspNet-1B](https://graspnet.net/index.html) | 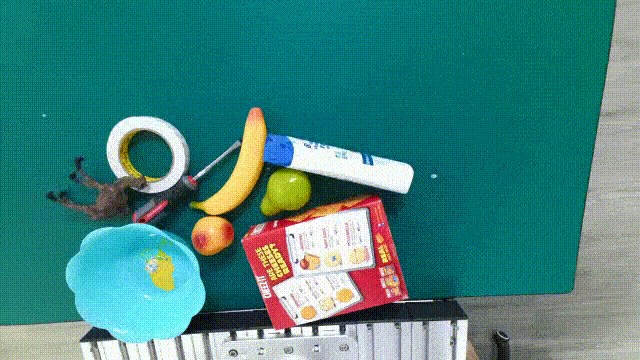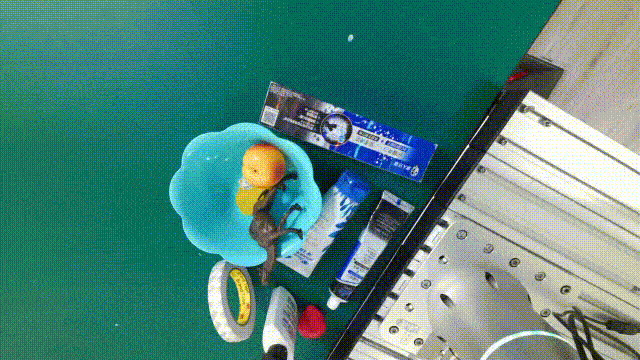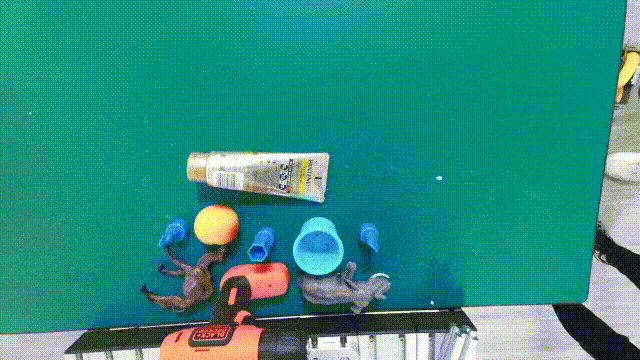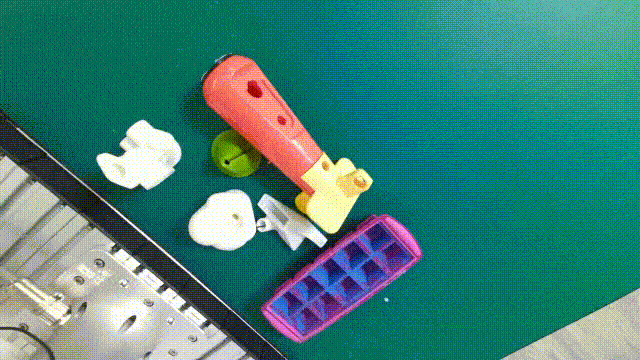 | 6D pose + Depth + Mask| **88** models in **190** videos with **97,280** frames| [CVPR 2020](https://openaccess.thecvf.com/content_CVPR_2020/papers/Fang_GraspNet-1Billion_A_Large-Scale_Benchmark_for_General_Object_Grasping_CVPR_2020_paper.pdf)|
| [NOCS](https://hughw19.github.io/NOCS_CVPR2019) |  | 6D pose + Depth + NOCS| **6** categories in **300K** composited images and **8K** real images| [CVPR 2019](https://arxiv.org/abs/1901.02970)|
| [YCBInEOAT](https://github.com/wenbowen123/iros20-6d-pose-tracking) |  | 6D pose + RGBD Video| **5** models in **9** videos with **7449** frames with **moving** objects| [IROS 2020](https://arxiv.org/pdf/2007.13866.pdf)|
| [YCB-Video](https://rse-lab.cs.washington.edu/projects/posecnn/) |  | 6D Pose + Depth + Mask | **21** models in **92** videos with **133,827** frames| [RSS 2018](https://arxiv.org/abs/1711.00199) |
| [T-LESS](http://cmp.felk.cvut.cz/t-less/)|  | 6D Pose + Depth | **30** models in **20** videos with **~49K** frames | [WACV 2017](https://arxiv.org/abs/1701.05498)|
| [Doumanoglou](http://rkouskou.gitlab.io/research/6D_NBV.html)| | 6D Pose + Depth | **2** models in **3** videos with **183** frames| [CVPR 2016](https://arxiv.org/abs/1512.07506)|
| [Tejani](http://rkouskou.gitlab.io/research/LCHF.html) |  | 6D Pose + Depth | **6** models in **6** videos with **2,067** frames | [ECCV 2014](http://rkouskou.gitlab.io/publications/docs/ECCV_2014.pdf)|
| [Occluded-LINEMOD](https://bop.felk.cvut.cz/datasets/) |  | 6D Pose + Depth | **8** models in **1,214** frames with **8,992** objects | [ECCV 2014](http://wwwpub.zih.tu-dresden.de/~cvweb/publications/papers/2014/PoseEstimationECCV2014.pdf) |
| [LINEMOD](https://bop.felk.cvut.cz/datasets/) |  | 6D pose + Depth for one object | **15** models in **15** videos with **18,273** frames | [ACCV 2012](http://www.stefan-hinterstoisser.com/papers/hinterstoisser2012accv.pdf) |
## 3D model datasets :bike:
In order to testify the network **generalization** ability
(tested on images containing **unseen** 3D models from the training set),
the following dataset could be used to generate synthetic training data.
Notice that **ABC** contains generic and arbitrary industrial CAD models
while **ShapeNetCore** and **ModelNet** contain common category objects such as cars and chairs.
| Dataset | Categories | Models in total | Reference |
| :-----: | :-----: | :-----: | :-----: |
| [ABC](https://deep-geometry.github.io/abc-dataset/) | - | 1 million | [CVPR 2019](https://arxiv.org/pdf/1812.06216.pdf) |
| [ShapeNetCore](https://www.shapenet.org/download/shapenetcore) | 55 | ~51,300 | [ArXiv 2015](https://arxiv.org/abs/1512.03012) |
| [ModelNet-40](http://modelnet.cs.princeton.edu/) | 40 | 12,311 | [CVPR 2015](https://3dshapenets.cs.princeton.edu/paper.pdf) |
## Rendering methods :mountain_bicyclist:
### Differentiable Renderer
* [Neural 3D Mesh Renderer](http://hiroharu-kato.com/projects_en/neural_renderer.html): Kato el al. CVPR 2018
* [RenderNet](https://github.com/thunguyenphuoc/RenderNet): Thu et al. NIPS 2018
### Blender Render :
* [BlenderProc](https://github.com/DLR-RM/BlenderProc)
* [blender-cli-rendering](https://github.com/yuki-koyama/blender-cli-rendering)
* [pvnet-rendering](https://github.com/zju3dv/pvnet-rendering)
* [bpycv](https://github.com/DIYer22/bpycv)
### Physical Simulator
[PyBullet](https://github.com/bulletphysics/bullet3/tree/master/examples/pybullet):
a very popular one in the Robotics community.
### Others
* [Glumpy](https://github.com/glumpy/glumpy): does not support headless rendering (failed on ssh mode)
* [UnrealCV](https://github.com/unrealcv/unrealcv): extension of Unreal Engine 4,
helps interact with virtual world and communicate with external program.
* [SyntheticComputerVision](https://github.com/unrealcv/synthetic-computer-vision):
resuming a lot of techniques used to generate synthetic image