https://github.com/aai-institute/pyDVL
pyDVL is a library of stable implementations of algorithms for data valuation and influence function computation
https://github.com/aai-institute/pyDVL
banzhaf-index data-centric-ai data-cleaning data-pruning data-quality data-valuation game-theory influence-functions least-core machine-learning robust-machine-learning shapley-value transferlab
Last synced: about 1 year ago
JSON representation
pyDVL is a library of stable implementations of algorithms for data valuation and influence function computation
- Host: GitHub
- URL: https://github.com/aai-institute/pyDVL
- Owner: aai-institute
- License: lgpl-3.0
- Created: 2021-04-02T19:46:57.000Z (over 5 years ago)
- Default Branch: develop
- Last Pushed: 2024-08-15T20:17:19.000Z (almost 2 years ago)
- Last Synced: 2024-08-17T21:42:41.646Z (almost 2 years ago)
- Topics: banzhaf-index, data-centric-ai, data-cleaning, data-pruning, data-quality, data-valuation, game-theory, influence-functions, least-core, machine-learning, robust-machine-learning, shapley-value, transferlab
- Language: Python
- Homepage: https://pydvl.org
- Size: 337 MB
- Stars: 92
- Watchers: 4
- Forks: 8
- Open Issues: 109
-
Metadata Files:
- Readme: README.md
- Changelog: CHANGELOG.md
- Contributing: CONTRIBUTING.md
- License: COPYING.LESSER
- Citation: CITATION.cff
Awesome Lists containing this project
- awesome-data-valuation - pyDVL - institute/pyDVL) | | (Libraries / Task Agnostic)
README

A library for data valuation.







**pyDVL** collects algorithms for **Data Valuation** and **Influence Function**
computation. Here is the list of [all methods implemented](https://pydvl.org/devel/getting-started/methods/).
**Data Valuation** for machine learning is the task of assigning a scalar
to each element of a training set which reflects its contribution to the final
performance or outcome of some model trained on it. Some concepts of
value depend on a specific model of interest, while others are model-agnostic.
pyDVL focuses on model-dependent methods.

Comparison of different data valuation methods
on best sample removal.
The **Influence Function** is an infinitesimal measure of the effect that single
training points have over the parameters of a model, or any function thereof.
In particular, in machine learning they are also used to compute the effect
of training samples over individual test points.
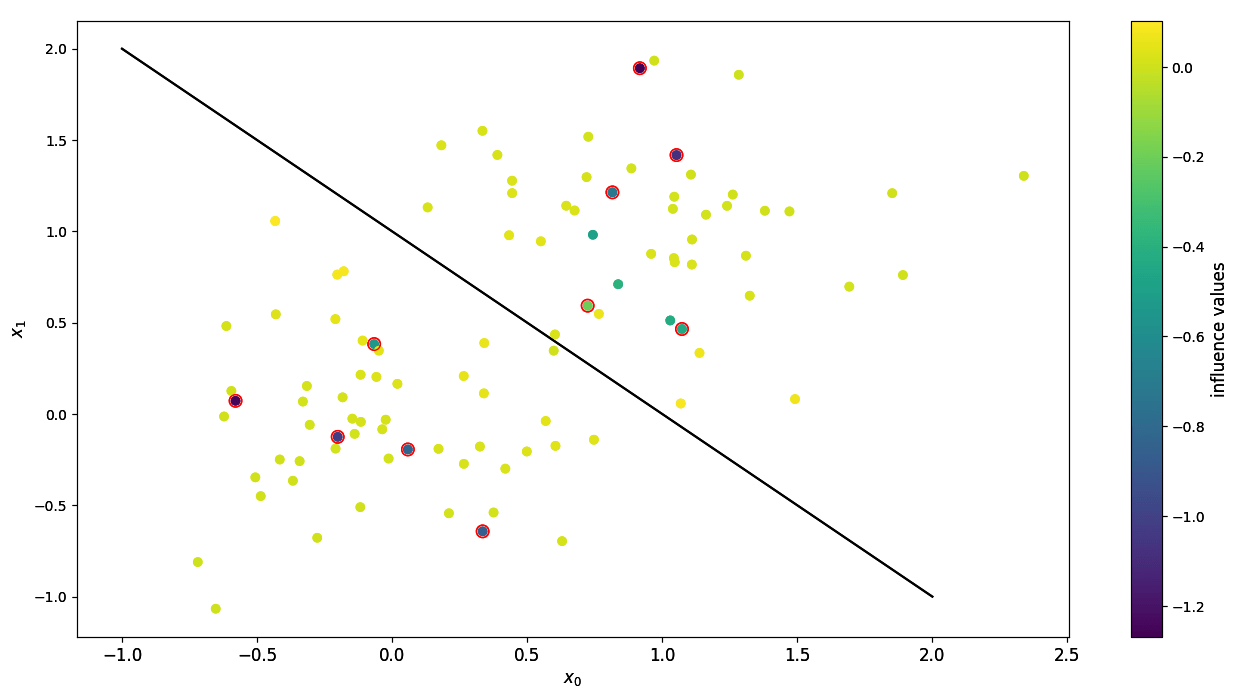
Influences of input points with corrupted data.
Highlighted points have flipped labels.
# Installation
To install the latest release use:
```shell
$ pip install pyDVL
```
You can also install the latest development version from
[TestPyPI](https://test.pypi.org/project/pyDVL/):
```shell
pip install pyDVL --index-url https://test.pypi.org/simple/
```
pyDVL has also extra dependencies for certain functionalities,
e.g. for using influence functions run
```shell
$ pip install pyDVL[influence]
```
For more instructions and information refer to [Installing pyDVL
](https://pydvl.org/stable/getting-started/#installation) in the documentation.
# Usage
Please read [Getting
Started](https://pydvl.org/stable/getting-started/first-steps/) in the
documentation for more instructions. We provide several examples for data
valuation and for influence functions in our [Example
Gallery](https://pydvl.org/stable/examples/).
## Influence Functions
1. Import the necessary packages (the exact ones depend on your specific use case).
2. Create PyTorch data loaders for your train and test splits.
3. Instantiate your neural network model and define your loss function.
4. Instantiate an `InfluenceFunctionModel` and fit it to the training data
5. For small input data, you can call the `influences()` method on the fitted
instance. The result is a tensor of shape `(training samples, test samples)`
that contains at index `(i, j`) the influence of training sample `i` on
test sample `j`.
6. For larger datasets, wrap the model into a "calculator" and call methods on
it. This splits the computation into smaller chunks and allows for lazy
evaluation and out-of-core computation.
The higher the absolute value of the influence of a training sample
on a test sample, the more influential it is for the chosen test sample, model
and data loaders. The sign of the influence determines whether it is
useful (positive) or harmful (negative).
> **Note** pyDVL currently only support PyTorch for Influence Functions. We plan
> to add support for Jax next.
```python
import torch
from torch import nn
from torch.utils.data import DataLoader, TensorDataset
from pydvl.influence import SequentialInfluenceCalculator
from pydvl.influence.torch import DirectInfluence
from pydvl.influence.torch.util import (
NestedTorchCatAggregator,
TorchNumpyConverter,
)
input_dim = (5, 5, 5)
output_dim = 3
train_x, train_y = torch.rand((10, *input_dim)), torch.rand((10, output_dim))
test_x, test_y = torch.rand((5, *input_dim)), torch.rand((5, output_dim))
train_data_loader = DataLoader(TensorDataset(train_x, train_y), batch_size=2)
test_data_loader = DataLoader(TensorDataset(test_x, test_y), batch_size=1)
model = nn.Sequential(
nn.Conv2d(in_channels=5, out_channels=3, kernel_size=3),
nn.Flatten(),
nn.Linear(27, 3),
)
loss = nn.MSELoss()
infl_model = DirectInfluence(model, loss, hessian_regularization=0.01)
infl_model = infl_model.fit(train_data_loader)
# For small datasets, instantiate the full influence matrix:
influences = infl_model.influences(test_x, test_y, train_x, train_y)
# For larger datasets, use the Influence calculators:
infl_calc = SequentialInfluenceCalculator(infl_model)
# Lazy object providing arrays batch-wise in a sequential manner
lazy_influences = infl_calc.influences(test_data_loader, train_data_loader)
# Trigger computation and pull results to memory
influences = lazy_influences.compute(aggregator=NestedTorchCatAggregator())
# Trigger computation and write results batch-wise to disk
lazy_influences.to_zarr("influences_result", TorchNumpyConverter())
```
## Data Valuation
The steps required to compute data values for your samples are:
1. Import the necessary packages (the exact ones will depend on your specific
use case, but most of the interface is exposed through `pydvl.valuation`).
2. Create two `Dataset` objects with your train and test splits. There are
some factories to do this from arrays or scikit-learn toy datasets.
3. Create an instance of a `SupervisedScorer`, with any sklearn scorer and a
"valuation set" over which your model will be scored.
4. Wrap model and scorer in a `ModelUtility`.
5. Use one of the methods defined in the library to compute the values. In the
example below, we use the most basic *Montecarlo Shapley* with uniform
sampling, an approximate method for computing Data Shapley values.
6. Call `fit` in a joblib parallel context. The result is a variable of type
`ValuationResult` that contains the indices and their values as well as other
attributes. This object can be sliced, sorted and inspected directly, or you
can convert it to a dataframe for convenience.
The higher the value for an index, the more important it is for the chosen
model, dataset and scorer. Reciprocally, low-value points could be mislabelled,
or out-of-distribution, and dropping them can improve the model's performance.
```python
from joblib import parallel_config
from sklearn.datasets import load_iris
from sklearn.svm import SVC
from pydvl.valuation import Dataset, ShapleyValuation, UniformSampler,\
MinUpdates, ModelUtility, SupervisedScorer
seed = 42
model = SVC(kernel="linear", probability=True, random_state=seed)
train, val = Dataset.from_sklearn(load_iris(), train_size=0.6, random_state=24)
scorer = SupervisedScorer(model, val, default=0.0)
utility = ModelUtility(model, scorer)
sampler = UniformSampler(batch_size=2 ** 6, seed=seed)
stopping = MinUpdates(1000)
valuation = ShapleyValuation(utility, sampler, stopping, progress=True)
with parallel_config(n_jobs=32):
valuation.fit(train)
result = valuation.result
```
### Deprecation notice
Up until v0.9.2 valuation methods were available through the `pydvl.value`
module, which is now deprecated in favour of the design showcased above,
available under `pydvl.valuation`. The old module will be removed in a future
release.
# Contributing
Please open new issues for bugs, feature requests and extensions. You can read
about the structure of the project, the toolchain and workflow in the [guide for
contributions](CONTRIBUTING.md).
# License
pyDVL is distributed under
[LGPL-3.0](https://www.gnu.org/licenses/lgpl-3.0.html). A complete version can
be found in two files: [here](LICENSE) and [here](COPYING.LESSER).
All contributions will be distributed under this license.