https://github.com/abeed04/object-detection-model-using-cv2
Leverage OpenCV (cv2) to build an object detection system. This system would combine a pre-trained MobileNet model, trained on the COCO dataset, with a frozen inference graph for real-time object identification within images or videos.
https://github.com/abeed04/object-detection-model-using-cv2
cocodataset frozen mobilenetv3 opencv pycharm-ide
Last synced: 6 months ago
JSON representation
Leverage OpenCV (cv2) to build an object detection system. This system would combine a pre-trained MobileNet model, trained on the COCO dataset, with a frozen inference graph for real-time object identification within images or videos.
- Host: GitHub
- URL: https://github.com/abeed04/object-detection-model-using-cv2
- Owner: abeed04
- License: mit
- Created: 2024-06-23T11:16:01.000Z (about 2 years ago)
- Default Branch: main
- Last Pushed: 2024-07-02T05:31:41.000Z (about 2 years ago)
- Last Synced: 2025-04-06T02:31:49.876Z (over 1 year ago)
- Topics: cocodataset, frozen, mobilenetv3, opencv, pycharm-ide
- Language: Python
- Homepage:
- Size: 20 MB
- Stars: 1
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
Object Detection Model using Cv2 👨💻
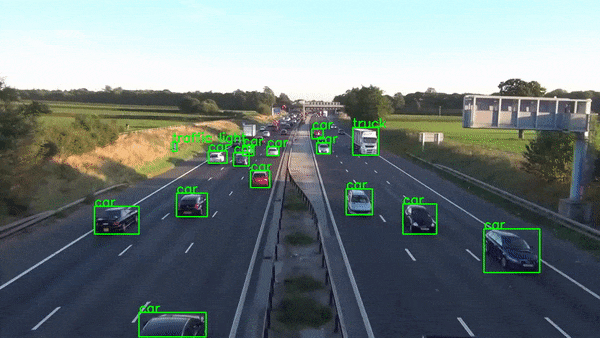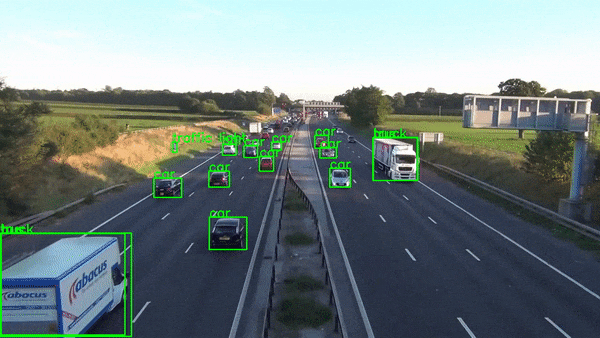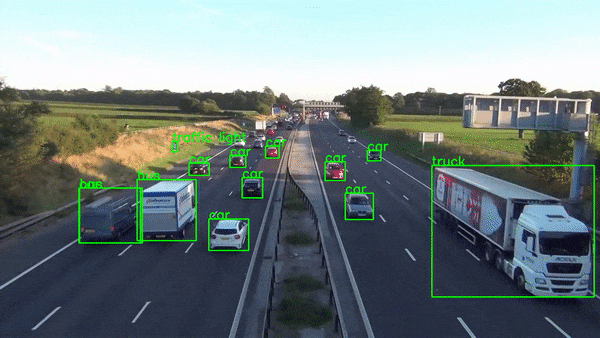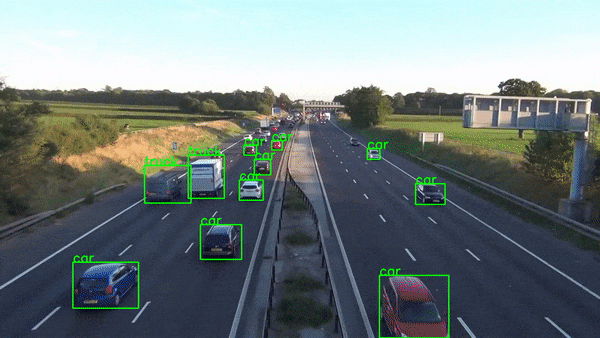
🔭 This project demonstrates real-time object detection using OpenCV (cv2), the MobileNet deep learning model, and the COCO dataset. It leverages a pre-trained frozen inference graph for efficient object identification within images or video streams.
Requirements
-Python 3.x
-OpenCV (cv2) library
-Pre-trained MobileNet, COCO model files and Frozen model (download them to local pc)
Usage
-The program automatically attempts to open the video file Streets.mp4(You can upload your own videos). If the file is unavailable, it defaults to your webcam stream.
-A window titled "Object Detection Program" will display the video feed with detected objects highlighted.
-Bounding boxes will be drawn around detected objects, and their corresponding class labels will be displayed.(Note:Only Objects that are labeled in labels.txt file are displayed)
-You can adjust the confidence threshold (confThreshold=0.55) in the code to control the minimum confidence required for a detection to be displayed.
-Press the 'q' key to exit the program.
Explanation
Imports
-The script imports necessary modules, including OpenCV (cv2)
Model and Label Loading
-The model configuration file (mobilenet_and_coco.txt) and the frozen inference graph (frozen_model.pb) are loaded using cv2.dnn_DetectionModel.
-Class labels are read from labels.txt and stored in a list class_labels.
Model Configuration
-The model's input size is set to 200x200 pixels.
-The input scale and mean values are adjusted for normalization.
-The input color channel order is swapped to BGR (OpenCV's default) if necessary.
Video Capture
-A video capture object cap is created, attempting to open the video file Streets.mp4 first. It then falls back to the webcam if the file is not found.
-Error handling is included to raise an exception if video capture fails.
Main Loop
-The loop continuously reads frames from the video stream using cap.read().
-The frame is resized to match the model's expected input size using OpenCV's resizing functions.
-model.detect is used for object detection in the frame. It returns class indices, confidence scores, and bounding boxes for detected objects that meet the specified confidence threshold.
-For each detected object:
1)A bounding box is drawn around the object using cv2.rectangle.
2)The corresponding class label from class_labels is retrieved and displayed on the frame using cv2.putText.
-The processed frame is displayed in the "Object Detection Program" window.
-The program exits when the 'q' key is pressed.
You can modify the script to:
-The video capture object is released using cap.release().
-OpenCV windows are destroyed using cv2.destroyAllWindows().
Customization
You can modify the script to:
-Use a different video file or image set for object detection.
-Experiment with different confidence thresholds (confThreshold) to adjust the detection sensitivity.
-Explore ways to integrate this object detection functionality into a larger application.
Further Considerations
-The pre-trained MobileNet model may not be ideal for all object detection tasks. Consider exploring other models or fine-tuning the provided model on your specific dataset for improved accuracy.
-The script currently processes frames one by one. For more efficient real-time performance, you might investigate techniques like multithreading or GPU acceleration.