https://github.com/abhi5h3k/phantom-ai-interview
🚀 Phantom-AI-Interview – A fun experiment exploring how AI can silently assist in virtual interviews, coding challenges, and exams. Uses OCR, LLMs, and automation to extract text, generate responses, and operate without a visible UI. 🔥
https://github.com/abhi5h3k/phantom-ai-interview
ai ai-interview coding-interviews hack-interview llm ocr ollama speach-to-text text-to-speech
Last synced: 7 months ago
JSON representation
🚀 Phantom-AI-Interview – A fun experiment exploring how AI can silently assist in virtual interviews, coding challenges, and exams. Uses OCR, LLMs, and automation to extract text, generate responses, and operate without a visible UI. 🔥
- Host: GitHub
- URL: https://github.com/abhi5h3k/phantom-ai-interview
- Owner: Abhi5h3k
- Created: 2025-03-09T16:10:19.000Z (7 months ago)
- Default Branch: main
- Last Pushed: 2025-03-09T18:35:04.000Z (7 months ago)
- Last Synced: 2025-03-09T19:29:39.397Z (7 months ago)
- Topics: ai, ai-interview, coding-interviews, hack-interview, llm, ocr, ollama, speach-to-text, text-to-speech
- Language: Python
- Homepage:
- Size: 43 KB
- Stars: 1
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# PhantomAI 🤖
[](https://www.linkedin.com/in/abhi5h3k/) [](https://stackoverflow.com/users/6870223/abhi?tab=profile)
This is a fun **Sunday AI experiment!** I wanted to explore how AI and LLMs could be used to **silently assist** in interviews, exams, and meetings—without anyone noticing. This project is purely conceptual and serves as a **demonstration of potential risks** and security concerns in AI-driven automation.
PhantomAI is something I put together as a solo project, designed to operate discreetly, allowing users to issue commands and receive responses without a visible interface. The original idea was to see if AI could listen to live audio feeds from meetings (such as interviews), detect specific questions, and generate responses—all while staying invisible during screen sharing.
This concept is intentionally not fully refined to the point where it poses a serious challenge for recruiters, but it remains stealthy and demonstrates how silent AI tools can operate discreetly. While it's just a fun experiment, it also raises important questions about the **future of virtual interviews and the traditional approach to interview and coding challenges**.

## 📺 Demo (Click for YouTube Video)
### 🤖 All responses are played as audio output, which you can listen to through your connected headset 🎧. Notifications are enabled only for demonstration purposes; by default, they are turned off 💡.
### 🎧 [Stereo Mode](https://www.wintips.org/how-to-enable-stereo-mix-if-not-showing-as-recording-device-in-windows-11-10/) – AI Listens to Interviewer Directly
This mode allows PhantomAI to listen to the interviewer's voice directly from the system audio instead of the microphone. This ensures that the AI captures exactly what the interviewer is saying and generates responses accordingly.
[](https://www.youtube.com/watch?v=xPOmbY0iaVE)
---
### 📝 On-Screen Text Extraction (OCR) – Extract Interview Questions
OCR mode is helpful when you need to extract a question from the interviewer's chat, a coding screen, or an online test. PhantomAI reads the text displayed on the screen and processes it for AI-assisted responses.
[](https://www.youtube.com/watch?v=YCq53T8dCfE)
---
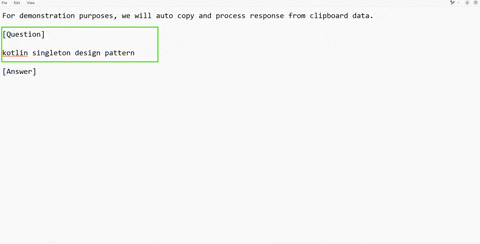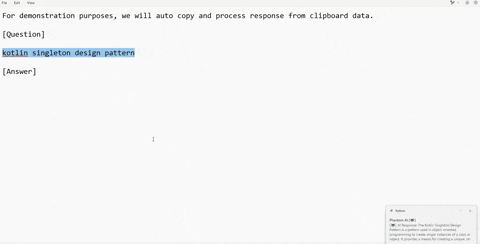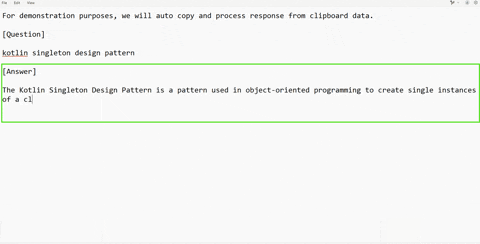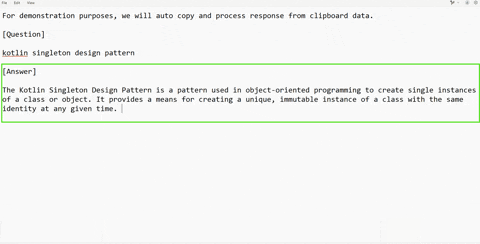
### 📋 Clipboard Jacking – Quick & Silent AI Assistance
Clipboard Jacking is the fastest way to get help from the AI without any visible UI activity. If an interviewer shares a coding question in chat or an online IDE, and you're stuck on syntax or logic, simply copy the part you need help with and press a hotkey. PhantomAI will silently send it to the LLM and provide a response.
[](https://www.youtube.com/watch?v=fHlCZ1uN0qo)
---
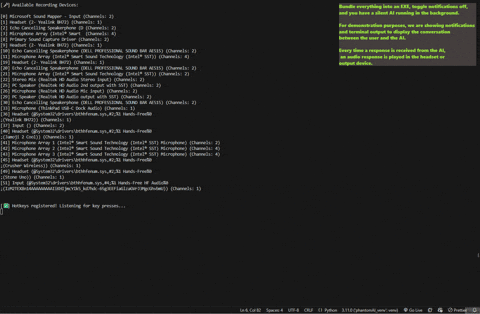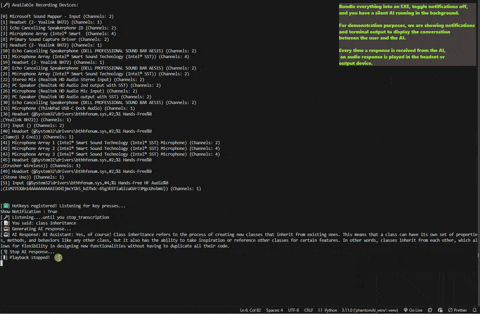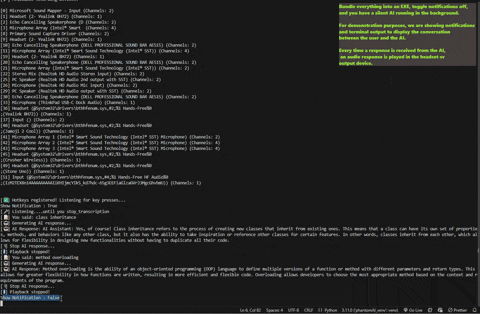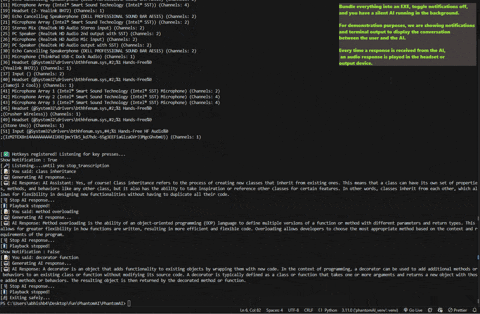
### 👨💻 AI-Assisted Response
**Active Listening Mode**
---
## 👀 What’s in this Project?
✅ **On-Screen Text Extraction** – Using EasyOCR to capture and process text from your screen.
✅ **AI-Assisted Response Automation** – Simulating realistic typing for coding and text-based questions.
✅ **Phantom Mode** – Operates entirely with hotkey shortcuts, eliminating the need for a visible GUI.
✅ **Active Listening Mode** – AI stays alert for real-time interactions and responses.
✅ **Clipboard Jacking** – Silently captures copied text, sends it to an LLM, and retrieves a response without detection.
**💡 Note:** This project uses an open-source LLM on CPU. Performance and accuracy can be significantly improved with GPU acceleration, larger models, or by switching to GPT API with optimized prompts.
**💡 Disclaimer:** This is a proof-of-concept and does not promote unethical behavior. The goal is to highlight how AI can be both a tool for productivity and a potential security concern.
---
## 👨💻 Technical Details
- **Live Audio Processing**: Uses Vosk for real-time speech recognition.
- **File-Based Transcription**: Uses Whisper for processing recorded audio files.
- **Customizable Hotkeys**: Modify key bindings via `config.ini` to trigger AI commands silently.
- **Screen Capture**: Uses EasyOCR to read input from screen.
---
## 💡 System Requirements
- **Tested on:** Windows 11
- **Processor:** Intel(R) Core(TM) i7-10510U CPU @ 1.80GHz 2.30GHz
- **RAM:** 32.0 GB (31.8 GB usable)
---
## 🚀 Installation & Setup
### Folder Structure
Your project directory should be structured as follows:
```
Phantom-AI-Interview/
│── whisper-bin-x64/ # Download [whisper-bin-x64](https://github.com/ggerganov/whisper.cpp/actions/runs/13716448084/) (Place at root)
│── Some whisper files
│── models
│── ggml-base.en.bin # Download ggml-base.en.bin [Whisper Models on Hugging Face](https://huggingface.co/ggerganov/whisper.cpp/tree/main)
│── vosk-model-en-in-0.5/ # Downloaded Vosk model (Place at root)
│── src/ # Source code
│── config # Config folder containing Configuration file for hotkeys
│── requirements.txt # Dependencies
│── run.py # Main script
```
### Setup Instructions
Since some required files are large and cannot be pushed to GitHub, follow these steps to set up your environment:

1. Download Whisper **[whisper-bin-x64](https://github.com/ggerganov/whisper.cpp/actions/runs/13716448084/)**

Extract it to the **root directory** of the project
2. Download ggml-base.en.bin [Whisper Models on Hugging Face](https://huggingface.co/ggerganov/whisper.cpp/tree/main)

3. Download the [Vosk Model](https://alphacephei.com/vosk/models)
Get the Vosk model (**vosk-model-en-in-0.5**)
### Project Setup:
### **1. Install Python 3.11.0**
Ensure you have Python 3.11.0 installed. You can download it from [python.org](https://www.python.org/downloads/release/python-3110/).
### **2. Create a Virtual Environment**
```sh
py -m venv phantomAI_venv
```
### **3. Activate the Virtual Environment**
- **Windows:**
```sh
phantomAI_venv\Scripts\activate
```
### **4. Install Dependencies**
```sh
pip install -r requirements.txt
```
### **5. Configure Hotkeys**
Check `config.ini` for hotkey shortcuts. You can update them as per your preference.
### **6. Run PhantomAI**
```sh
py run.py
```
---
## 📝 Technologies Used
### **1. Vosk for Real-Time Speech Recognition**
- Uses `vosk-model-en-in-0.5` for live transcription.
- Find better models here: [Vosk Models](https://alphacephei.com/vosk/models)
### **2. Whisper for File-Based Transcription**
- Uses `whisper-bin-x64` and `ggml-base.en.bin` for processing recorded audio.
- Find the latest builds: [Whisper.cpp Artifacts](https://github.com/ggerganov/whisper.cpp/actions/runs/13716448084/)
- More models available here: [Whisper Models on Hugging Face](https://huggingface.co/ggerganov/whisper.cpp/tree/main)
### **3. Ollama for LLM Inference**
- Docker setup:
```sh
docker-compose up -d
```
- Pull the model:
```sh
docker exec -it ollama ollama pull qwq
```
- Find more models: [Ollama Search](https://ollama.com/search)
---
## 🚀 Future Improvements & Suggestions
If you want to enhance PhantomAI for better performance and a more seamless experience, consider these improvements:
- **Use GPU & Larger Models** – For faster and more accurate responses, switch to a GPU-powered setup with a bigger local LLM.
- **Switch to GPT API** – If local inference is slow, using the GPT API provides better performance and higher accuracy.
- **Better Prompt Engineering** – Optimize response quality by designing improved prompt templates or dynamically selecting templates based on the question type.
- **Move to Containers** – This project was a quick Windows-based concept. For better portability and stability, consider switching to Docker/Linux-based deployment.
- **Bundle into a Single Executable** – Improve usability by packaging everything into a standalone .exe file for easy distribution.
---
## 🌍 Disclaimer
This project is purely for educational purposes and ethical AI research. It highlights the potential risks associated with silent AI in virtual environments but is not intended to be used for unethical activities.
---
## 📚 License
Feel free to use and modify as needed.
---