https://github.com/abhirockzz/cosmosdb-synapse-workshop
Near Real Time Analytics with Azure Synapse Link for Azure Cosmos DB
https://github.com/abhirockzz/cosmosdb-synapse-workshop
apache-spark azure-cosmos-db azure-synapse-analytics mongodb pyspark python
Last synced: 7 months ago
JSON representation
Near Real Time Analytics with Azure Synapse Link for Azure Cosmos DB
- Host: GitHub
- URL: https://github.com/abhirockzz/cosmosdb-synapse-workshop
- Owner: abhirockzz
- Created: 2020-12-08T11:49:37.000Z (almost 5 years ago)
- Default Branch: master
- Last Pushed: 2021-05-06T02:21:23.000Z (over 4 years ago)
- Last Synced: 2025-02-13T16:25:16.441Z (9 months ago)
- Topics: apache-spark, azure-cosmos-db, azure-synapse-analytics, mongodb, pyspark, python
- Homepage:
- Size: 7.81 KB
- Stars: 3
- Watchers: 3
- Forks: 1
- Open Issues: 5
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
- awesome-synapse - abhirockzz/cosmosdb-synapse-workshop - Azure Synapse Link for Azure Cosmos DB example. (Repositories / Tools & Samples)
README
# Near Real Time Analytics with Azure Synapse Link for Azure Cosmos DB
In this workshop, you will learn about **Azure Synapse Link for Azure Cosmos DB**. We will go through some of the notebooks from the official samples repository - https://aka.ms/cosmosdb-synapselink-samples
It will cover:
- [Azure Cosmos DB](https://docs.microsoft.com/azure/cosmos-db/?WT.mc_id=data-11340-abhishgu) and how it integrates with [Azure Synapse Analytics](https://docs.microsoft.com/azure/synapse-analytics/?WT.mc_id=data-11340-abhishgu) using [Azure Synapse Link](https://docs.microsoft.com/azure/cosmos-db/synapse-link?toc=/azure/synapse-analytics/toc.json&bc=/azure/synapse-analytics/breadcrumb/toc.json&WT.mc_id=data-11340-abhishgu).
- Basic operations such as setting up Azure Cosmos DB and Azure Synapse Analytics. Creating Azure Cosmos DB containers, setting up Linked Service.
- Scenarios with examples
- Batch Data Ingestion leveraging Synapse Link for Azure Cosmos DB and performing operations across Azure Cosmos DB containers
- Streaming ingestion into Azure Cosmos DB collection using Structured Streaming
- Getting started with Azure Cosmos DB's API for MongoDB and Synapse Link
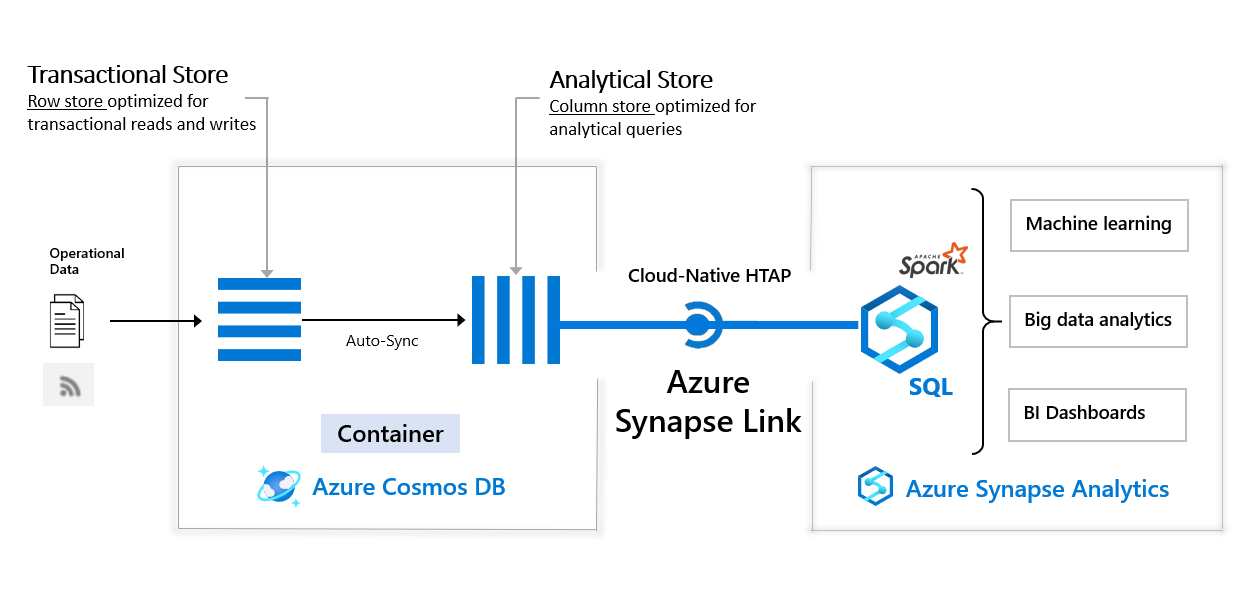
## Learning materials and resources
If you want to go back and learn some of the foundational concepts, the following resources might be helpful:
- Key [Azure Cosmos DB concepts](https://docs.microsoft.com/azure/cosmos-db/account-databases-containers-items?WT.mc_id=data-11340-abhishgu) and [how to choose the appropriate API for Azure Cosmos DB](https://docs.microsoft.com/learn/modules/choose-api-for-cosmos-db/?WT.mc_id=data-11340-abhishgu)
- [Basic terminology associated with Azure Synapse Analytics](https://docs.microsoft.com/azure/synapse-analytics/overview-terminology?WT.mc_id=data-11340-abhishgu)
- A Learn Module that covers [the features, components that Azure Synapse Analytics provides](https://docs.microsoft.com/learn/modules/introduction-azure-synapse-analytics/?WT.mc_id=data-11340-abhishgu)
- [An overview of Azure Synapse Link for Azure Cosmos DB](https://docs.microsoft.com/azure/cosmos-db/synapse-link?WT.mc_id=data-11340-abhishgu) and [how to configure and enable Azure Synapse Link to interact with Azure Cosmos DB.](https://docs.microsoft.com/learn/modules/configure-azure-synapse-link-with-azure-cosmos-db/?WT.mc_id=data-11340-abhishgu)
## Pre-requisites
The steps outlined in this section have completed in advance to save time. The following resources are already available:
- Azure Cosmos DB accounts (Core SQL API, Mongo DB API)
- Azure Synapse Analytics workspace along with a Apache Spark pool
**You can use an existing Azure account or create a [free account using this link](https://aka.ms/azure-account-free)**
First things first, [create a Resource Group](https://docs.microsoft.com/azure/azure-resource-manager/management/manage-resource-groups-portal?WT.mc_id=data-11340-abhishgu#create-resource-groups) to host the resources used for this workshop. This will make it easier to manage them and clean-up once you're done.
**Azure Cosmos DB**
- Create an [Azure Cosmos DB SQL (CORE) API account](https://docs.microsoft.com/en-us/azure/cosmos-db/create-cosmosdb-resources-portal?WT.mc_id=data-11340-abhishgu#create-an-azure-cosmos-db-account). For the purposes of this workshop, please choose **All networks** as the **Connectivity method** option (in the **Networking** section of the create account wizard)
- Create an [Azure Cosmos DB API for MongoDB account](https://docs.microsoft.com/azure/cosmos-db/create-mongodb-dotnet?WT.mc_id=data-11340-abhishgu#create-a-database-account). For the purposes of this workshop, please choose **All networks** as the **Connectivity method** option (in the **Networking** section of the create account wizard)
- For both the accounts (Core SQL and MongoDB), enable [Synapse Link for Azure Cosmos DB](https://docs.microsoft.com/en-us/azure/cosmos-db/configure-synapse-link?WT.mc_id=data-11340-abhishgu#enable-synapse-link)
**Azure Synapse Analytics**
- Create an [Azure Synapse Workspace](https://docs.microsoft.com/azure/synapse-analytics/quickstart-create-workspace?WT.mc_id=data-11340-abhishgu). Please ensure that you select the checkbox `Assign myself the Storage Blob Data Contributor role on the Data Lake Storage Gen2 account` in the creation wizard
- Create an [Azure Synapse Analytics Spark Pool](https://docs.microsoft.com/azure/synapse-analytics/quickstart-create-apache-spark-pool-portal?WT.mc_id=data-11340-abhishgu)
## Workshop setup
For Azure Cosmos DB **Core SQL API** account:
Create Azure Cosmos DB database (named **RetailSalesDemoDB**) and three containers (**StoreDemoGraphics**, **RetailSales**, and **Products**). Please make sure to:
- Set the database throughput to `Autoscale` and set the limit to `40000` instead of `400`, this will speed-up the loading process of the data, scaling down the database when it is not in use ([check the documentation](https://docs.microsoft.com/azure/cosmos-db/provision-throughput-autoscale?WT.mc_id=data-11340-abhishgu) on how to set throughput)
- Use **/id** as the Partition key for all 3 containers.
- **Analytical store** is set to **On** for all 3 containers.
> [Detailed steps are outlined in the documentation](https://docs.microsoft.com/azure/cosmos-db/configure-synapse-link?WT.mc_id=reactor-3reg-reactor&WT.mc_id=data-11340-abhishgu#create-analytical-ttl)
For Azure Cosmos DB **MongoDB API** account:
Create a database named **DemoSynapseLinkMongoDB** along with a collection named **HTAP** with a Shard key called **item**. Make sure you set the **Analytical store** option to **On** when you create your collection.
### Add a Linked Service and static data in Azure Synapse workspace
- [Create a "Linked Service" for the Azure Cosmos DB SQL API in Azure Synapse workspace](https://docs.microsoft.com/azure/synapse-analytics/synapse-link/how-to-connect-synapse-link-cosmos-db?toc=/azure/cosmos-db/toc.json&bc=/azure/cosmos-db/breadcrumb/toc.json&WT.mc_id=data-11340-abhishgu#connect-an-azure-cosmos-db-database-to-an-azure-synapse-workspace) - for this demo, we use the name `RetailSalesDemoDB`
- Load batch data in the [Azure Data Lake Storage Gen2 account](https://docs.microsoft.com/azure/storage/blobs/data-lake-storage-introduction?WT.mc_id=data-11340-abhishgu) associated with your Azure Synapse Analytics workspace. Create a `RetailData` folder within the root directory of the storage account. Download [these csv files](https://github.com/Azure-Samples/Synapse/tree/master/Notebooks/PySpark/Synapse%20Link%20for%20Cosmos%20DB%20samples/Retail/RetailData) to your local machine and upload them to the `RetailData` folder you just created.
You're all set to try out the Notebooks!
## Scenarios
**Batch Data Ingestion leveraging Synapse Link for Azure Cosmos DB**
We will go through how to ingest batch data into Azure Cosmos DB using using Synapse using [this notebook](https://github.com/Azure-Samples/Synapse/blob/master/Notebooks/PySpark/Synapse%20Link%20for%20Cosmos%20DB%20samples/Retail/spark-notebooks/pyspark/1CosmoDBSynapseSparkBatchIngestion.ipynb).
Clone or download the content from the [samples repo](https://github.com/Azure-Samples/Synapse), navigate to the `Synapse/Notebooks/PySpark/Synapse Link for Cosmos DB samples/Retail/spark-notebooks/pyspark` directory and import the `1CosmoDBSynapseSparkBatchIngestion.ipynb` file into your Azure Synapse workspace
> To learn more, read up on how to [Create, develop, and maintain Synapse Studio notebooks in Azure Synapse Analytics](https://docs.microsoft.com/azure/synapse-analytics/spark/apache-spark-development-using-notebooks?tabs=classical&WT.mc_id=data-11340-abhishgu)
**Join data across Cosmos DB containers**
Clone or download the content from the [samples repo](https://github.com/Azure-Samples/Synapse), navigate to the `Synapse/Notebooks/PySpark/Synapse Link for Cosmos DB samples/Retail/spark-notebooks/pyspark` directory and import the `2SalesForecastingWithAML.ipynb` file into your Azure Synapse workspace
**Streaming ingestion into Azure Cosmos DB collection using Structured Streaming**
We will explore [this notebook](https://github.com/Azure-Samples/Synapse/blob/master/Notebooks/PySpark/Synapse%20Link%20for%20Cosmos%20DB%20samples/IoT/spark-notebooks/pyspark/01-CosmosDBSynapseStreamIngestion.ipynb) to get an overview of how to work with streaming data using Spark.
Clone or download the content from the [samples repo](https://github.com/Azure-Samples/Synapse), navigate to the `Synapse/Notebooks/PySpark/Synapse Link for Cosmos DB samples/IoT/spark-notebooks/pyspark` directory and import the `01-CosmosDBSynapseStreamIngestion.ipynb` file into your Azure Synapse workspace
**Getting started with Azure Cosmos DB's API for MongoDB and Synapse Link**
We will explore [this notebook](https://github.com/Azure-Samples/Synapse/blob/master/Notebooks/PySpark/Synapse%20Link%20for%20Cosmos%20DB%20samples/IoT/spark-notebooks/pyspark/01-CosmosDBSynapseStreamIngestion.ipynb). Since it uses specific Python libraries you will need to upload the `requirements.txt` file located in `Synapse/Notebooks/PySpark/Synapse Link for Cosmos DB samples/E-Commerce/spark-notebooks/pyspark` directory to install these to your Spark pool packages.
> Here is detailed write-up on how to [Manage libraries for Apache Spark in Azure Synapse Analytics](https://docs.microsoft.com/azure/synapse-analytics/spark/apache-spark-azure-portal-add-libraries?WT.mc_id=data-11340-abhishgu)
Clone or download the content from the [samples repo](https://github.com/Azure-Samples/Synapse), navigate to the `Synapse/Notebooks/PySpark/Synapse Link for Cosmos DB samples/E-Commerce/spark-notebooks/pyspark` directory and import the `CosmosDBSynapseMongoDB.ipynb` file into your Azure Synapse workspace.
## Wrap up and next steps
That's all for this workshop. I encourage you to go through the [rest of this lab](https://github.com/Azure-Samples/Synapse/blob/master/Notebooks/PySpark/Synapse%20Link%20for%20Cosmos%20DB%20samples/Retail/spark-notebooks/pyspark/2SalesForecastingWithAML.ipynb) which includes using [AutoML in Azure Machine Learning](https://docs.microsoft.com/azure/machine-learning/concept-automated-ml?WT.mc_id=data-11340-abhishgu) to build a Forecasting Model.
### Important: Delete resources
Delete the [Azure Resource Group](https://docs.microsoft.com/azure/azure-resource-manager/management/manage-resource-groups-portal?WT.mc_id=data-11340-abhishgu#delete-resource-groups). This will delete all the resources inside the resource group.
## Continue to learn at your own pace!
- Learn more about [the use cases for Apache Spark in Azure Synapse Analytics](https://docs.microsoft.com/azure/synapse-analytics/spark/apache-spark-overview?WT.mc_id=data-11340-abhishgu#apache-spark-in-azure-synapse-analytics-use-cases), including Data Engineering, Machine Learning etc.
- Learn how to [enrich data in Spark tables with new machine learning models that you train using AutoML in Azure Machine Learning](https://docs.microsoft.com/azure/synapse-analytics/machine-learning/tutorial-automl?WT.mc_id=data-11340-abhishgu)
- A dedicated, multi-module **Learning Path** to guide you through how to [Perform data engineering with Azure Synapse Apache Spark Pools](https://docs.microsoft.com/learn/paths/perform-data-engineering-with-azure-synapse-apache-spark-pools/?WT.mc_id=data-11340-abhishgu)
- [Use this tutorial](https://docs.microsoft.com/azure/synapse-analytics/quickstart-sql-on-demand?WT.mc_id=data-11340-abhishgu) to try out how to query data in CSV, Apache Parquet, and JSON files using SQL Serverless pool in Azure Synapse Analytics.