https://github.com/abhy-kumar/nlpulse
This program aims to give a sentiment score to each headline featured in today's top stories. Eventually it aims to gather insights about the top headlines being reported.
https://github.com/abhy-kumar/nlpulse
finbert natural-language-processing news nlp nlp-machine-learning python roberta rss sentiment-analysis vader-sentiment-analysis
Last synced: about 2 months ago
JSON representation
This program aims to give a sentiment score to each headline featured in today's top stories. Eventually it aims to gather insights about the top headlines being reported.
- Host: GitHub
- URL: https://github.com/abhy-kumar/nlpulse
- Owner: abhy-kumar
- License: mit
- Created: 2024-10-09T07:24:35.000Z (over 1 year ago)
- Default Branch: main
- Last Pushed: 2024-10-19T05:16:53.000Z (over 1 year ago)
- Last Synced: 2024-10-19T11:25:00.030Z (over 1 year ago)
- Topics: finbert, natural-language-processing, news, nlp, nlp-machine-learning, python, roberta, rss, sentiment-analysis, vader-sentiment-analysis
- Language: Jupyter Notebook
- Homepage:
- Size: 892 KB
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- Changelog: news_sentiment.db
- License: LICENSE
Awesome Lists containing this project
README
## 📊 Overview
A comprehensive Python application that performs real-time sentiment analysis on news headlines, storing the results in a SQLite database and generating interactive visualizations. The system employs multiple sentiment analysis models, including VADER, FinBERT, and RoBERTa, to provide nuanced sentiment scoring.
## 🌟 Key Features
- **Multi-Model Sentiment Analysis**: Combines VADER, FinBERT, and RoBERTa models for robust sentiment scoring
- **Real-time RSS Feed Processing**: Automatically fetches and analyzes news headlines
- **Interactive Visualizations**: Comprehensive dashboards using Plotly
- **Efficient Data Storage**: SQLite database with optimized indexing
- **Duplicate Detection**: Intelligent similarity-based duplicate removal
- **Comprehensive Analysis**: Including timeline views, sentiment distributions, and statistical breakdowns
### Custom Configuration
```python
from news_analysis import DatabaseManager, SentimentAnalyzer, DataVisualizer
# Initialize components
db = DatabaseManager('custom_database.db')
analyzer = SentimentAnalyzer()
visualizer = DataVisualizer()
# Run specific analyses
visualizer.create_visualizations('custom_database.db')
```
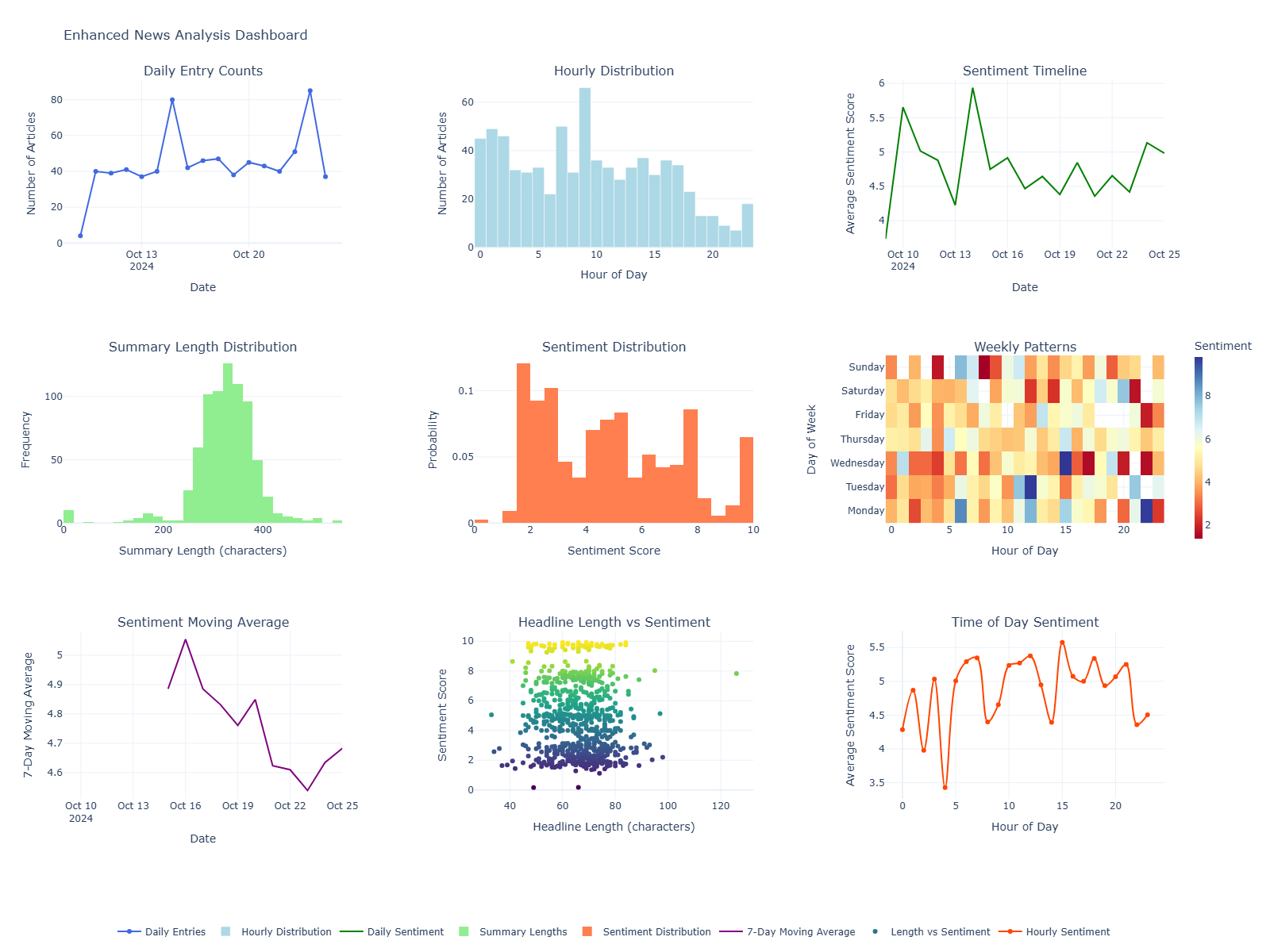
## 📊 Visualization Types
### Main Dashboard
- Daily Entry Counts
- Hourly Distribution
- Sentiment Timeline
- Summary Length Distribution
- Sentiment Distribution
- Weekly Patterns
- Sentiment Moving Average
- Headline Length vs Sentiment
- Time of Day Sentiment
### Headlines Analysis
- Recent Headlines Table
- Most Positive Headlines
- Most Negative Headlines
- Statistical Summaries
## 🗄️ Database Schema
### sentiment_scores Table
```sql
CREATE TABLE sentiment_scores (
date TEXT,
time TEXT,
title TEXT,
summary TEXT,
score REAL
)
```
### Indexes
- `idx_date`: Optimizes date-based queries
- `idx_title`: Facilitates headline searches
- `idx_score`: Improves sentiment-based filtering
## 🔍 Duplicate Detection
The project includes functions to:
- Eliminate duplicate or near-duplicate entries based on a similarity threshold.
- Provide analysis and cleanup of the dataset for better performance and accuracy.
### Configuration
```python
# Adjust similarity threshold (default: 0.85)
remove_duplicates(db_path='news_sentiment.db', similarity_threshold=0.90)
```
## 📈 Performance Optimization
### Database Optimization
- Write-Ahead Logging (WAL) mode
- Optimized cache settings
- Efficient indexing strategy
- Regular VACUUM operations
### Processing Optimization
- Thread pooling for parallel sentiment analysis
- LRU caching for frequently accessed data
- Batch processing capabilities
- GPU acceleration when available
## 📝 Contributing
Contributions are welcome! Please feel free to submit a Pull Request. For major changes, please open an issue first to discuss what you would like to change.
### Guidelines
1. Fork the repository
2. Create your feature branch (`git checkout -b feature/AmazingFeature`)
3. Commit your changes (`git commit -m 'Add some AmazingFeature'`)
4. Push to the branch (`git push origin feature/AmazingFeature`)
5. Open a Pull Request
## 📄 License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
## 🙏 Acknowledgments
- NLTK team for VADER sentiment analysis
- Hugging Face for transformer models
- Plotly team for visualization capabilities
- Contributors and maintainers of all dependent libraries