https://github.com/abus-aikorea/voice-pro
Gradio WebUI for creators and developers, featuring key TTS (Edge-TTS, kokoro) and zero-shot Voice Cloning (E2 & F5-TTS, CosyVoice), with Whisper audio processing, YouTube download, Demucs vocal isolation, and multilingual translation.
https://github.com/abus-aikorea/voice-pro
audiobook faster-whisper gradio karaoke podcasts speech-recognition speech-synthesis speech-to-text subtitles text-to-speech transcription translator tts voice-cloning voice-conversion webui whisper whisperx yt-dlp
Last synced: about 1 year ago
JSON representation
Gradio WebUI for creators and developers, featuring key TTS (Edge-TTS, kokoro) and zero-shot Voice Cloning (E2 & F5-TTS, CosyVoice), with Whisper audio processing, YouTube download, Demucs vocal isolation, and multilingual translation.
- Host: GitHub
- URL: https://github.com/abus-aikorea/voice-pro
- Owner: abus-aikorea
- License: mit
- Created: 2024-07-29T10:02:31.000Z (almost 2 years ago)
- Default Branch: main
- Last Pushed: 2025-05-09T02:31:01.000Z (about 1 year ago)
- Last Synced: 2025-05-09T03:34:48.405Z (about 1 year ago)
- Topics: audiobook, faster-whisper, gradio, karaoke, podcasts, speech-recognition, speech-synthesis, speech-to-text, subtitles, text-to-speech, transcription, translator, tts, voice-cloning, voice-conversion, webui, whisper, whisperx, yt-dlp
- Language: Python
- Homepage: https://r17wvy-t2.myshopify.com/
- Size: 78 MB
- Stars: 3,648
- Watchers: 24
- Forks: 271
- Open Issues: 18
-
Metadata Files:
- Readme: README.md
- Funding: .github/FUNDING.yml
- License: LICENSE
Awesome Lists containing this project
- awesome-ChatGPT-repositories - voice-pro - Gradio WebUI for audio processing, powered by Whisper (OpenAI-Whisper, Faster-Whisper, Whisper-Timestamped). Features Voice Changer(RVC), zero-shot Voice Cloning (E2, F5-TTS, CosyVoice), YouTube downloading, vocal isolation(UVR5), Text-to-Speech (Edge-TTS, kokoro), and multi-language translation. Perfect for content creators and developers. (Chatbots)
- awesome-starred - abus-aikorea/voice-pro - Gradio WebUI for creators and developers, featuring key TTS (Edge-TTS, kokoro) and zero-shot Voice Cloning (E2 & F5-TTS, CosyVoice), with Whisper audio processing, YouTube download, Demucs vocal isola (Python)
README
Voice-Pro
The best AI speech recognition, translation, and multilingual dubbing solution 🚀







## 🎙️ An AI-powered web application for speech recognition, translation, and dubbing
 한국어
한국어
∙
 English
English
∙
 中文简体
中文简体
∙
 中文繁體
中文繁體
∙
 日本語
日本語
∙
 Deutsch
Deutsch
∙
 Español
Español
∙
 Português
Português
Voice-Pro is a state-of-the-art web app that transforms multimedia content creation. It integrates YouTube video downloading, voice separation, speech recognition, translation, and text-to-speech into a single, powerful tool for creators, researchers, and multilingual professionals.
- 🔊 Top-tier speech recognition: **Whisper**, **Faster-Whisper**, **Whisper-Timestamped**, **WhisperX**
- 🎤 Zero-shot voice cloning: **F5-TTS**, **E2-TTS**, **CosyVoice**
- 📢 Multilingual text-to-speech: **Edge-TTS**, **kokoro** (Paid version includes **Azure TTS**)
- 🎥 YouTube processing & audio extraction: **yt-dlp**
- 🌍 Instant translation for 100+ languages: **Deep-Translator** (Paid version includes **Azure Translator**)
A robust alternative to **ElevenLabs**, Voice-Pro empowers podcasters, developers, and creators with advanced voice solutions.
## ⚠️ Please Note
- **Upgrading from v2.x to v3.x**: Not possible. We recommend deleting the `installer_files` folder and running the latest version of `start.bat`.
- **Upgrading from v3.x to v3.x**: Possible. After downloading the latest code, run `update.bat`.
- **First-time users**: Please refer to the installation instructions below.
- **Troubleshooting**: In most cases, issues can be resolved by deleting the `installer_files` folder and then running `configure.bat` followed by `start.bat`.
- 🎁 **Free Activation Key Request**: Please fill out this [Google Forms](https://forms.gle/anMSmsR5dH9wxE6N6) to receive your activation key. Activation keys are limited to one per email address.
- 🏆 **Request for Additional Activation Keys**: Create amazing content using Voice-Pro. Please share the link to your post in the [](https://github.com/abus-aikorea/voice-pro/discussions). We will gladly reward your contributions.
## 📰 News & History
version 3.1
- 🪄 Support for fine-tuned models of **F5-TTS**
- 🌍 Supported languages
- English & Chinese: SWivid/F5-TTS_v1
-  Finnish: AsmoKoskinen/F5-TTS_Finnish_Model
Finnish: AsmoKoskinen/F5-TTS_Finnish_Model
-  French: RASPIAUDIO/F5-French-MixedSpeakers-reduced
French: RASPIAUDIO/F5-French-MixedSpeakers-reduced
-  Hindi: SPRINGLab/F5-Hindi-24KHz
Hindi: SPRINGLab/F5-Hindi-24KHz
-  Italian: alien79/F5-TTS-italian
Italian: alien79/F5-TTS-italian
- Japanese: Jmica/F5TTS/JA_21999120
-  Russian: hotstone228/F5-TTS-Russian
Russian: hotstone228/F5-TTS-Russian
- Spanish: jpgallegoar/F5-Spanish
version 3.0
- 🔥 Removed the **AI Cover** feature.
- 🚀 Added support for **m-bain/whisperX**.
version 2.0
- 🐍 Built with Python 3.10.15, Torch 2.5.1+cu124, and Gradio 5.14.0.
- 🆓 Free trial supports media up to **60 seconds** in length.
- 🔥 Added the **AI Cover** feature.
- 🎤 Introduced support for **CosyVoice** and **kokoro**.
- ⏳ Initial run downloads **CozyVoice2-0.5B (9GB)**, which may take over an hour depending on network speed.
- 🎧 Voice samples for cloning will be continuously updated.
- 📝 Added **spaCy** for natural sentence-by-sentence translation and TTS.
- ☁️ Subscription version includes **Microsoft Azure** Translator and TTS.
- 🏪 Subscription offers **unlimited usage** (no 60-second limit) during the subscription period, available via [](https://r17wvy-t2.myshopify.com).
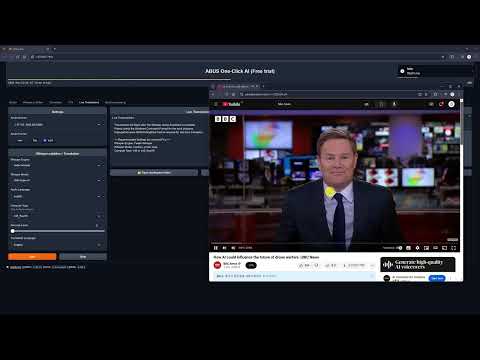
## 🎥 YouTube Showcase
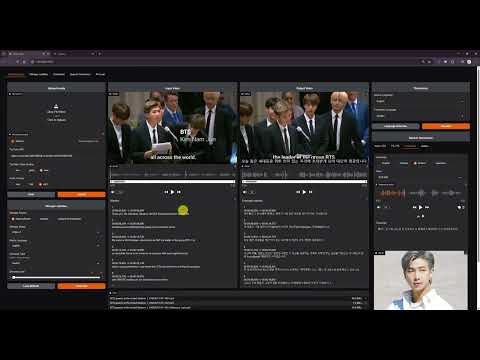
Demo for Voice-Pro (v2.0)

F5-TTS: Voice Cloning
Live Transcription & Translation

Multi-Lingual Voice Cloning: Korean - German

Multi-Lingual Voice Cloning: English - Korean

Multi-Lingual Voice Cloning: Korean - Japanese

NVIDIA RTX Video Super-Resolution

AI Karaoke

Multi-Lingual Voice Cloning: English - Korean
## ⭐ Key Features
### 1. Dubbing Studio
- YouTube video downloads & audio extraction
- Voice separation with **Demucs**
- Supports 100+ languages for speech recognition & translation
### 2. Speech Technologies
- **Speech-to-Text:** **Whisper**, **Faster-Whisper**, **Whisper-Timestamped**, **WhisperX**
- **Text-to-Speech:**
- **Edge-TTS**: 100+ languages, 400+ voices
- **E2-TTS**, **F5-TTS**, **CosyVoice**: Zero-shot cloning
- **kokoro**: Ranked #2 in HuggingFace TTS Arena
### 3. Real-Time Translation
- Instant speech recognition
- Multilingual translation on the fly
- Customizable audio inputs
## 🤖 WebUI
### `Dubbing Studio` Tab
- All-in-one hub: YouTube downloads, noise removal, subtitles, translation, & TTS
- Supports all ffmpeg-compatible formats
- Output options: WAV, FLAC, MP3
- Subtitles & recognition for 100+ languages
- TTS with speed, volume, & pitch controls

### `Whisper Caption` Tab
- Subtitle-focused: 90+ languages
- Video-integrated subtitle display
- Word-level highlighting & denoise options
### `Translate` Tab
- Translation for 100+ languages
- Supports subtitle files (ASS, SSA, SRT, etc.)
- Real-time voice recognition & translation

### `Speech Generation` Tab
- Options: **Edge-TTS**, **F5-TTS**, **CosyVoice**, **kokoro**
- Celeb voice podcasts & multilingual support

## 🎤✨ Reference Voice
- Please request the voice you want to add on the Issues page. [Issues](https://github.com/abus-aikorea/voice-pro/issues/50)
English

Andrew Bustamante

Andrew Huberman

Avi Loeb

Ben Shapiro

Brett Johnson

Brian Keating

Coffeezilla

Dan Carlin

David Buss

David Fravor

David Kipping

Dennis Whyte

Donald Hoffman

Donald Trump

Douglas Murray

Duncan Trussell

Elon Musk

Garry Nolan

Jack Barsky

James Sexton

Jeff Bezos

Joe Rogan

John Mearsheimer

Jordan Peterson

Kanye 'Ye' West

Mark Zuckerberg

Michael Levin

Michael Saylor

Michio Kaku

MrBeast

Nick Lane

Paul Rosolie

Ryan Graves

Sam Altman

Sam Harris

Stephen Wolfram

Tucker Carlson

Vitalik Buterin

Yuval Harari
Chinese

迪丽热巴 (Dílì Rèbā)

蔡依林 (Cài Yīlín)

吴亦凡 (Wú Yìfán)

李易峰 (Lǐ Yìfēng)

杨幂 (Yáng Mì)

赵丽颖 (Zhào Lìyǐng)
Korean

BTS 진 (Jin)

BTS RM

IU (아이유)

이병헌

이정재

유재석
Japanese

綾瀬はるか (Ayase Haruka)
## 💻 System Requirements
- **OS:** Windows 10/11 (64-bit) ※ Linux/Mac unsupported
- **GPU:** NVIDIA with CUDA 12.4 (recommended)
- **VRAM:** 4GB+ (8GB+ preferred)
- **RAM:** 4GB+
- **Storage:** 20GB+ free space
- **Internet:** Required
## 📀 Installation
Install Voice-Pro with ease using **configure.bat** and **start.bat**.
### 1. Get the Package
+ Clone or download the latest release (**Source code (zip)**) from [](https://github.com/abus-aikorea/voice-pro/)
```bash
git clone https://github.com/abus-aikorea/voice-pro.git
```
### 2. Install & Run
1. 🚀 **configure.bat**
- Sets up git, ffmpeg, and CUDA (if NVIDIA GPU)
- Run once; takes 1+ hour with internet
- Don’t close the command window
2. 🚀 **start.bat**
- Launches Voice-Pro WebUI
- First run installs dependencies (1+ hour)
- Retry after deleting **installer_files** if issues arise
### 3. Update
- 🚀 **update.bat**: Refreshes Python environment (faster than reinstall)
### 4. Uninstall
- Run **uninstall.bat** or delete the folder (portable install)
## ❓Tips & Tricks
#### If Browser does not run automatically
- Close the Windows-Commnad window and run start.bat again.
- Run the browser directly and enter the address displayed in the Windows-Command window (e.g. **http://127.0.0.1:7870**) in the address bar.
#### If a CUDA Out-Of-Memory error occurs
- Check the GPU memory status in Windows Task Manager - Performance tab.
- Set the Denoise level to 0 or 1. Denoise level 2 requires at least 8GB of GPU memory.
- Set Compute Type to int type. The float type has better quality, but requires more GPU memory.
#### How to improve the quality of subtitles?
- The quality of subtitles tends to improve with larger Whisper models, but this is not necessarily the case. large > medium > small > base > tiny
- Among compute types, float type has good performance. The int type is a model that reduces GPU usage and increases speed through model quantization. On the other hand, performance decreases.
- If you increase the denoise level, more background sounds will be removed, and only the remaining voice will be used for voice recognition. It does not always guarantee good results.
## 🚨 Notice
- This repository offers a **free trial** of Voice-Pro.
- The free trial version of Voice-Pro allows you to process up to **60 seconds** of media.
- The subscription version supports Microsoft Azure TTS and Translator. Purchase it on [](https://r17wvy-t2.myshopify.com).
Trial Version
☕Contributor Version
Subscription Version
Media Length Limit
60 seconds
Unlimited
Unlimited
Translation Service
Google Translate (Open Source)
Google Translate (Open Source)
Azure Translate (Microsoft)
Text-to-Speech Service
Edge TTS (Open Source)
Edge TTS (Open Source)
Azure TTS (Microsoft)
## ☕ Contributions
Hello, I'm David from the Voice-Pro team.
Our team discovers the best AI technologies in the industry and provides them for anyone to use easily and conveniently.
We are a small startup in Korea that has only been around for a year. We are working hard to help you and other creators produce great content.
Your ⭐⭐⭐⭐⭐ review would be greatly appreciated as it helps our business grow with you. Please help support our small team.
Thank you,
ABUS Customer Service
- If you want to participate in and help us with this project, feel free to create an [Issues](https://github.com/abus-aikorea/voice-pro/issues)
- If something goes wrong, please submit a [Pull requests](https://github.com/abus-aikorea/voice-pro/pulls) to improve this project.
- Any type of contribution is welcome.
- For inquiries related to purchases, business partnerships, technical tuning, investments, and other matters, please contact us by email. ()."
- If you like this project, please star this repository. We would greatly appreciate it. ⭐⭐⭐
- You can support Voice-Pro with a donation here:
## 📬 Contact
- Email:
- Homepage (Korean):
- Paid Version Purchase: [Shopify (Global)](https://r17wvy-t2.myshopify.com), [Naver (Korean)](https://smartstore.naver.com/abus)
## 🙏 Credits
* Demucs:
* yt-dlp:
* gradio:
* edge-TTS:
* F5-TTS:
* openai-whisper:
* faster-whisper:
* whisper-timestamped:
* whisperX:
* CosyVoice:
* kokoro:
* Deep-Translator:
* spaCy:
## ©️ Copyright
 by [ABUS](https://abuskorea.imweb.me)
by [ABUS](https://abuskorea.imweb.me)