https://github.com/adampaternostro/azure-databricks-with-spline
Using Spline with Azure Databricks
https://github.com/adampaternostro/azure-databricks-with-spline
azure-databricks lineage spline
Last synced: 7 months ago
JSON representation
Using Spline with Azure Databricks
- Host: GitHub
- URL: https://github.com/adampaternostro/azure-databricks-with-spline
- Owner: AdamPaternostro
- Created: 2020-04-30T19:34:05.000Z (over 5 years ago)
- Default Branch: master
- Last Pushed: 2020-05-01T13:26:43.000Z (over 5 years ago)
- Last Synced: 2025-01-31T04:32:38.163Z (8 months ago)
- Topics: azure-databricks, lineage, spline
- Size: 247 KB
- Stars: 3
- Watchers: 2
- Forks: 1
- Open Issues: 2
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Azure-Databricks-With-Spline
This is a manual walkthrough of using Spline with Azure Databricks. Everything for Spline is installed on a single VM and this is just for testing to see how things work (not a production setup).
For Spline see: https://absaoss.github.io/spline/
## Azure
1. Create a Linux VM Ubuntu 18.x (Enable ssh)
2. In the portal set the NSGs (allow inbound ports 8080, 8529, 9091)
- Note: Check you IP tables on the VM if you experience connectively issues remotely.
3. Note the Public IP address of the VM
## Prep VM
1. SSH to the VM
2. Install Docker (run each command one by one)
```
sudo apt update
sudo apt install apt-transport-https ca-certificates curl software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu bionic stable"
sudo apt update
apt-cache policy docker-ce
sudo apt install docker-ce
```
3. Install java:
```
sudo apt install openjdk-8-jre-headless
```
## Run Arango DB
1. Create another SSH session
2. Run the Docker image
```
sudo docker run -p 8529:8529 -e ARANGO_ROOT_PASSWORD=openSesame arangodb/arangodb:3.6.3
```
3. On your local computer login into
- http://REPLACE_VM_IP_ADDRESS:8529
- username: root
- password: openSesame
4. Initalize Spline database
```
wget https://repo1.maven.org/maven2/za/co/absa/spline/admin/0.5.0/admin-0.5.0.jar
java -jar admin-0.5.0.jar db-init arangodb://root:openSesame@REPLACE_VM_IP_ADDRESS:8529/spline
```
5. Login to Arango (again) and you should be able to select the Spline Database
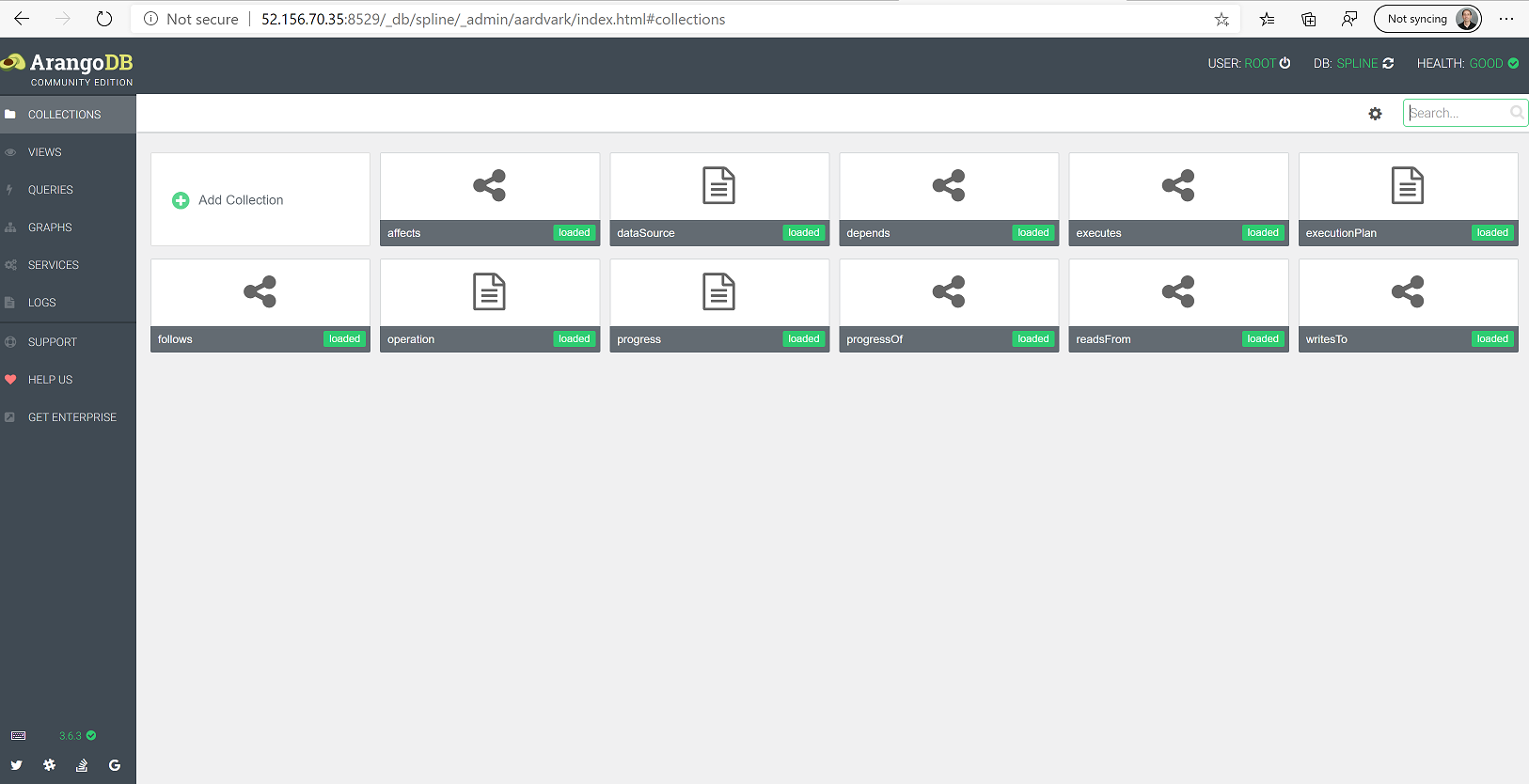
## Run Spline (REST Server)
1. Create another SSH session
2. Run the container
```
sudo docker container run \
-e spline.database.connectionUrl="arangodb://root:openSesame@REPLACE_VM_IP_ADDRESS:8529/spline" \
-p 9091:8080 \
absaoss/spline-rest-server
```
- Test on Linux locally: ```curl http://localhost:9091/about/version```
- Sample Result: {"build":{"timestamp":"2020-04-28T16:40:35Z","version":"0.5.0"}}
- Test from your machine: ```curl http://REPLACE_VM_IP_ADDRESS:9091/about/version```
## Run Spline (User Interface)
1. Create another SSH session
2. Run the container
```
sudo docker container run \
-e spline.consumer.url="http://REPLACE_VM_IP_ADDRESS:9091/consumer" \
-p 9090:8080 \
absaoss/spline-web-client
```
3. Open the interface from your computer: http://REPLACE_VM_IP_ADDRESS:9090/app/dashboard
## Create Databricks
1. Create a Databricks Workspace in Azure
2. Open the workspace
3. Create a cluster and get the Cluster id from the URL (e.g. 0430-135102-edits521) from url: #/setting/clusters/0430-135102-edits521)
4. Click on the user in the top right and generate an access token
3. Install the Databricks CLI
5. Configure Databricks CLI
```
databricks configure --token
```
6. Download the Spline files (download by hand or using cURL on Windows)
```
wget https://repo1.maven.org/maven2/za/co/absa/spline/spark-agent-bundle-2.4/0.4.2/spark-agent-bundle-2.4-0.4.2.jar
```
7. Upload and install on Databricks
```
databricks fs cp spark-agent-bundle-2.4-0.4.2.jar "dbfs:/lib/spline/spark-agent-bundle-2.4-0.4.2.jar" --overwrite
databricks libraries install --cluster-id YOUR_CLUSTER_ID_HERE --jar "dbfs:/lib/spline/spark-agent-bundle-2.4-0.4.2.jar"
```
8. Verify the Library is installed, you can install by hand by using a DBFS path of: dbfs:/lib/spline/spark-agent-bundle-2.4-0.4.2.jar

9. Create a Notebook (Scala) with 3 cells
```
System.setProperty("spline.mode", "REQUIRED")
System.setProperty("spline.persistence.factory", "za.co.absa.spline.persistence.mongo.MongoPersistenceFactory")
System.setProperty("spline.mongodb.url","arangodb://root:openSesame@REPLACE_VM_IP_ADDRESS:8529/spline")
System.setProperty("spline.producer.url","http://REPLACE_VM_IP_ADDRESS:9091/producer")
System.setProperty("spline.mongodb.name", "spline")
```
```
import za.co.absa.spline.harvester.SparkLineageInitializer._
spark.enableLineageTracking()
```
```
%python
rawData = spark.read.option("inferSchema", "true").json("/databricks-datasets/structured-streaming/events/")
rawData.createOrReplaceTempView("rawData")
sql("select r1.action, count(*) as actionCount from rawData as r1 join rawData as r2 on r1.action = r2.action group by r1.action").write.mode('overwrite').csv("/tmp/pyaggaction.csv")
```
## View the Lineage in Spline
1. Open the Spline UI: http://REPLACE_VM_IP_ADDRESS:9090/app/dashboard
2. You should see something like this.
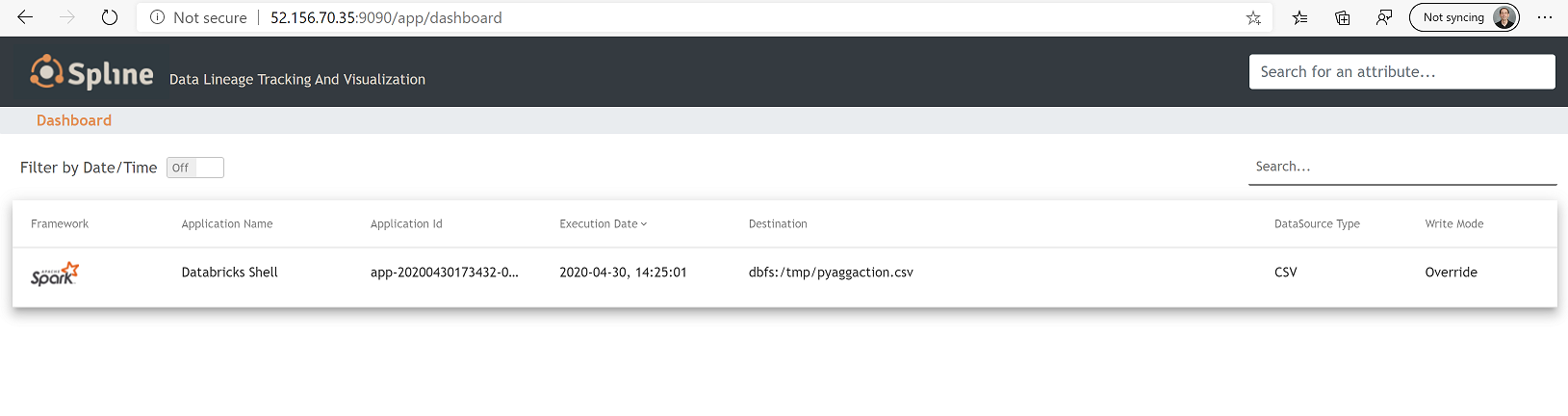
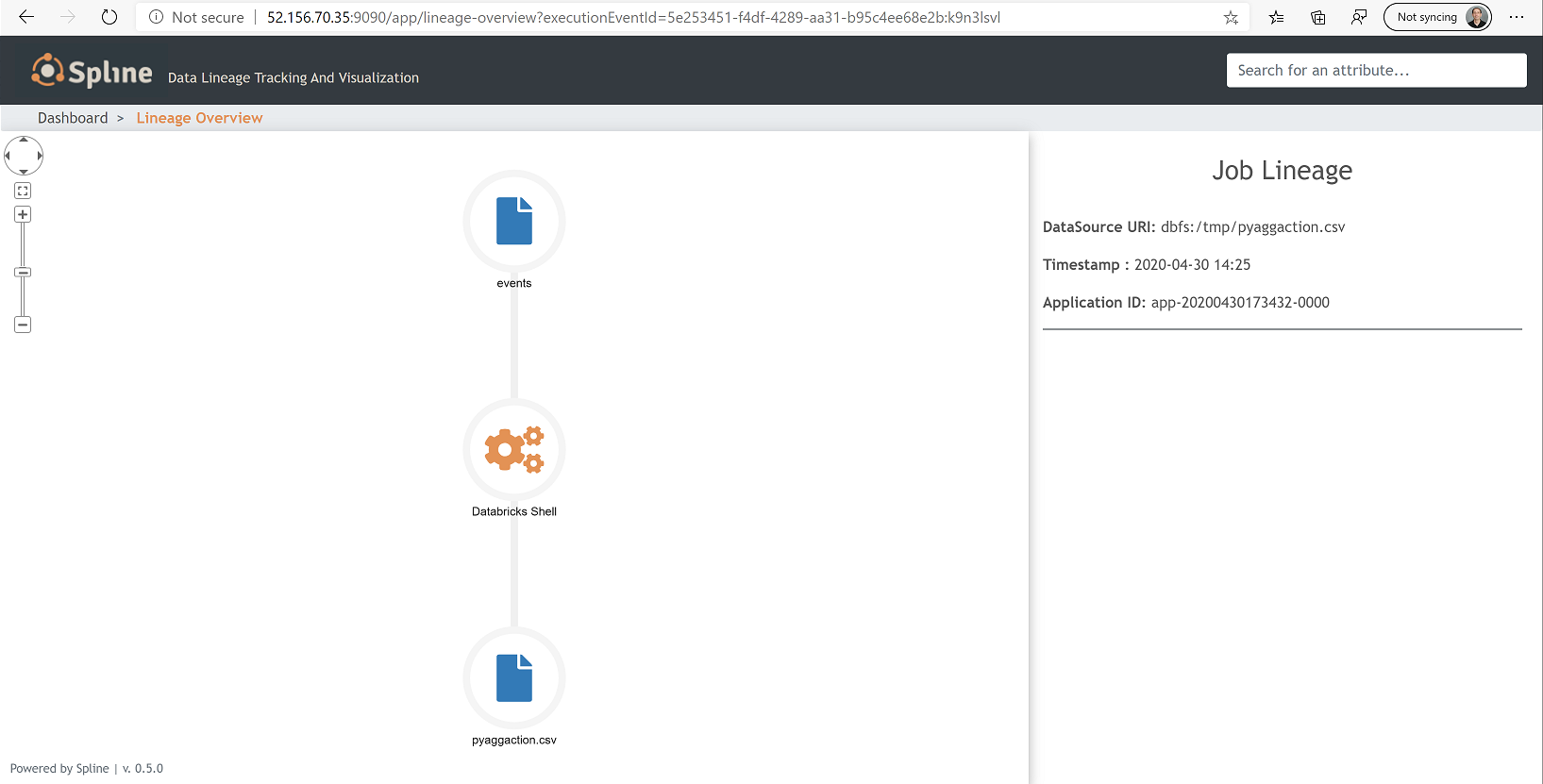
3. Click on it and you should see:
## References
- https://absaoss.github.io/spline/
- https://cloudarchitected.com/2019/04/data-lineage-in-azure-databricks-with-spline/
- https://github.com/algattik/databricks-lineage-tutorial
- https://www.slideshare.net/SparkSummit/spline-apache-spark-lineage-not-only-for-the-banking-industry-with-marek-novotny-jan-scherbaum
- https://medium.com/@reenugrewal/data-lineage-tracking-using-spline-on-atlas-via-event-hub-6816be0fd5c7
- https://repo1.maven.org/maven2/za/co/absa/spline/spark-agent-bundle-2.4/0.4.2/
- https://forums.databricks.com/questions/14366/install-spline-data-lineage-tracking-and-visualiza.html
- https://databricks.com/session/spline-apache-spark-lineage-not-only-for-the-banking-industry
- https://github.com/AbsaOSS/spline-spark-agent/blob/release/0.5.0/core/src/main/scala/za/co/absa/spline/harvester/SparkLineageInitializer.scala
- https://blogs.knowledgelens.com/index.php/2019/11/20/spark-data-lineage-on-databricks-notebook-using-spline/