https://github.com/addy999/onequery
AI web agent to find answers to any question
https://github.com/addy999/onequery
ai llm rag scraping-api selenium web webdev
Last synced: about 1 year ago
JSON representation
AI web agent to find answers to any question
- Host: GitHub
- URL: https://github.com/addy999/onequery
- Owner: addy999
- License: mit
- Created: 2025-01-03T15:37:20.000Z (over 1 year ago)
- Default Branch: main
- Last Pushed: 2025-02-04T15:14:41.000Z (over 1 year ago)
- Last Synced: 2025-04-01T00:42:46.131Z (over 1 year ago)
- Topics: ai, llm, rag, scraping-api, selenium, web, webdev
- Language: Python
- Homepage: https://www.onequery.app/
- Size: 13.2 MB
- Stars: 31
- Watchers: 1
- Forks: 1
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# OneQuery
[](https://github.com/addy999/onequery/blob/main/LICENSE)
[](https://github.com/addy999/onequery/commits/main)
> 🔨 **Note:** This repository is still in development. Contributions and feedback are welcome!
## Setup
- Requirements: `pip install -r requirements.txt`
- Install browser: `python -m playwright install`
- This project uses Playwright to control the browser. You can install the browser of your choice using the command above.
- Write your environment variables in a `.env` file (see `.env.test`)
- Install OmniParser
- For webpage analysis, we use the [OmniParser](https://huggingface.co/spaces/microsoft/OmniParser) model from Hugging Face. You'll need to host it via an [API](https://github.com/addy999/omniparser-api) locally.
## Examples
- Finding issues on a github repo
[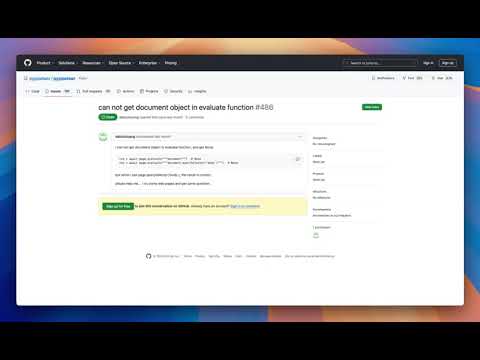](https://youtu.be/a_QPDnAosKM?si=pXtZgrRlvXzii7FX "Finding issues on a GitHub repo")
- Finding live events
[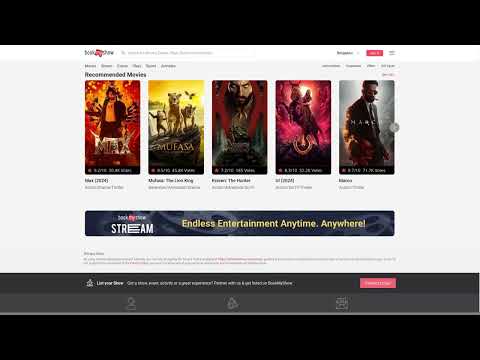](https://youtu.be/sp_YuZ1Q4wU?feature=shared "Finding live events")
## Usage
### General query with no source to start with
```python
task = "Find 2 recent issues from PyTorch repository."
class IssueModel(BaseModel):
date: str
title: str
author: str
description: str
class OutputModel(BaseModel):
issues: list[IssueModel]
scraper = WebScraper(task, None, OutputModel)
scraper.run()
```
### If you know the URL
```python
start_url = "https://in.bookmyshow.com/"
task = "Find 5 events happening in Bangalore this week."
class EventsModel(BaseModel):
name: str
date: str
location: str
class OutputModel(BaseModel):
events: list[EventsModel]
scraper = WebScraper(task, start_url, OutputModel)
scraper.run()
```
### Serving with a REST API
Server:
```bash
pip install fastapi[all]
```
```python
uvicorn server:app --reload
```
Client:
```python
import requests
url = "http://0.0.0.0:8000/scrape"
payload = {
"start_url": "http://example.com",
"task": "Scrape the website for data",
"schema": {
"title": (str, ...),
"description": (str, ...)
}
}
response = requests.post(url, json=payload)
print(response.status_code)
print(response.json())
```
> 💡 **Tip:** For a hosted solution with a lightning fast Zig based browser, worldwide proxy support, and job queuing system, check out [onequery.app](https://www.onequery.app).
## Testing
In the works
## Status
- ✅ Basic functionality
- 🛠️ Testing
- 🛠️ Documentation
## Architecture
(needs to be revised)
### Flowchart
```mermaid
graph TD;
A[Text Query] --> B[WebLLM];
B --> C[Browser Instructions];
C --> D[Browser Execution];
D --> E[OmniParser];
E --> F[Screenshot & Structured Info];
F --> G[AI];
C --> G;
G --> H[JSON Output];
```
### Stack
- Browser: [Playwright](https://github.com/microsoft/playwright-python)
- VLLM: [OmniParser](https://github.com/addy999/omniparser-api)
## Alternatives
- https://github.com/CognosysAI/browser/