https://github.com/adobe-research/custom_motion
https://github.com/adobe-research/custom_motion
Last synced: 9 months ago
JSON representation
- Host: GitHub
- URL: https://github.com/adobe-research/custom_motion
- Owner: adobe-research
- License: other
- Created: 2024-08-13T21:06:26.000Z (over 1 year ago)
- Default Branch: main
- Last Pushed: 2024-12-09T02:05:21.000Z (about 1 year ago)
- Last Synced: 2025-03-24T12:55:31.151Z (10 months ago)
- Language: Python
- Size: 6.37 MB
- Stars: 11
- Watchers: 2
- Forks: 1
- Open Issues: 1
-
Metadata Files:
- Readme: README.md
- License: LICENSE.md
Awesome Lists containing this project
- awesome-diffusion-categorized - [Code
README
## Customizing Motion in Text-to-Video Diffusion Models
[Project Page](https://joaanna.github.io/customizing_motion/), [Arxiv](https://arxiv.org/pdf/2312.04966)
## Results
Given a few examples of the "Carlton dance", our customization method incorporates the depicted motion into a pretrained text-to-video diffusion model using a new motion identifier "V* dance". We generate the depicted motion across a variety of novel contexts, including with different subject scale (toddler), multiple subjects (a group of nurses), and a non-humanoid subject (robot).
https://github.com/user-attachments/assets/77247717-bed4-4fd4-a3db-30acabe34cab
## Method Design
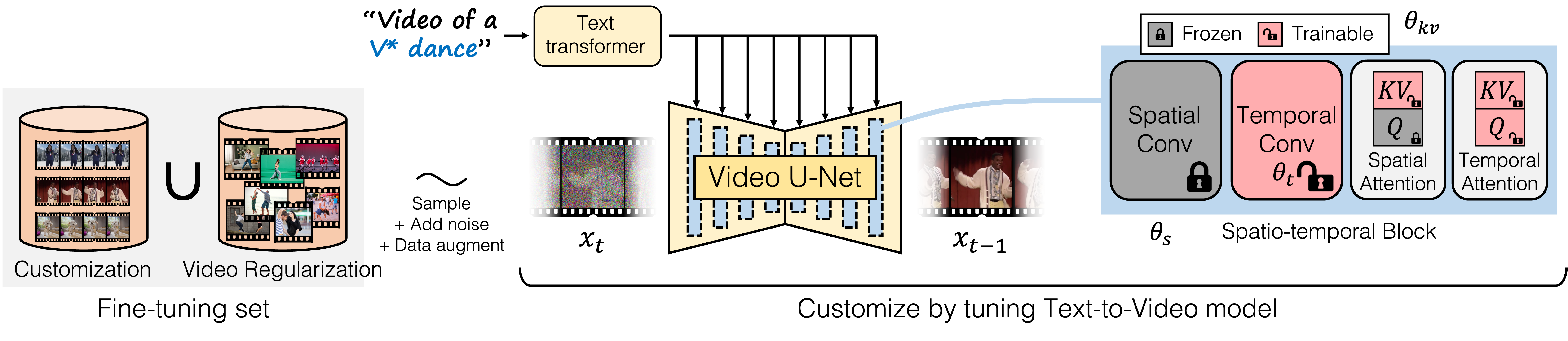
Given a small set of exemplar videos, our approach fine-tunes the U-Net of a text-to-video model using a reconstruction objective. The motion is identified with a unique motion identifier and can be used at test time to synthesize novel subjects performing the motion. To represent the added motion but preserve information from the pretrained model, we tune a subset of weights -- the temporal convolution and attention layers, in addition to the key and value layers in the spatial attention layer. A set of related videos is used to regularize the tuning process.
## Getting Started
git clone https://github.com/adobe-research/customizing_motion.git
cd customizing_motion
conda create -n customizing_motion python=3.10
conda activate customizing_motion
pip install -r requirements.txt
## Training
To run the training specify your hyperparameters in the config file and run the following command.
```
python train_model.py --config config.yaml
```
## Inference
To generate videos, you can either create a txt file with your prompts, specifying coma-separated seed and text prompt, or directly write a prompt in a command line.
```
python generate_pretrained.py -m PATH_TO_MODEL_WEIGHTS -o OUTPUT_FOLDER -p data/prompts/PROMPTS.txt
python generate_pretrained.py -m PATH_TO_MODEL_WEIGHTS -o OUTPUT_FOLDER -p "An example prompt involving the learned motion" -s "random"
```
To visualize videos in a folder, place the file `utils/video_lightbox.html` in the folder containing the videos and open the file in a browser.
## References
```
@inproceedings{materzynska2024newmove,
title={NewMove: Customizing text-to-video models with novel motions},
author={Materzy{\'n}ska, Joanna and Sivic, Josef and Shechtman, Eli and Torralba, Antonio and Zhang, Richard and Russell, Bryan},
booktitle={Proceedings of the Asian Conference on Computer Vision},
pages={1634--1651},
year={2024}
}
```
## Acknowledgements
This code is based on the following [repository](https://github.com/ExponentialML/Text-To-Video-Finetuning). We would like to thank Kabir Swain for helpful discussions.