https://github.com/aershov24/mlsc_candidates_test
MLSC pilot repo for candidates testing
https://github.com/aershov24/mlsc_candidates_test
Last synced: 8 months ago
JSON representation
MLSC pilot repo for candidates testing
- Host: GitHub
- URL: https://github.com/aershov24/mlsc_candidates_test
- Owner: aershov24
- Created: 2021-07-03T01:57:01.000Z (over 4 years ago)
- Default Branch: main
- Last Pushed: 2021-12-21T06:05:18.000Z (almost 4 years ago)
- Last Synced: 2025-01-19T09:12:14.609Z (10 months ago)
- Size: 31.3 KB
- Stars: 1
- Watchers: 3
- Forks: 12
- Open Issues: 2
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
> ⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️
>
> **NOTE: Our vacancy is closed! Please don't send any pull requests as we won't process them. Thanks**
>
> ⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️⚠️
# Welcome to MLSC Candidate Repo
Please read this document carefully before submitting your MLSC candidate challenge.
> The fact is, if you DO read, complete and pass the challenge successfully you most likely lie outside of 3 times the standard deviation from the average candidate, thus you are the "anomaly" on the market, thus we want hire you :)
# What You Need to Do
* Carefully read the `README.md`
* Fork this repository
* Create the `Logistic_Regression_youremail_TEST.md` file in the forked repo and add **`3` questions and answers (QAS) relevant to Logistic Regression topic that you would ask on a real interview** if you would hire ML/DS devs for your own project. Again, questions must be answered :)
* Make sure you add:
* one **Junior** question for Junior position
* one **Medium** difficulty question for Mid position, and
* one **Senior** question for Senior position.
* Make sure that for all QA you'll include:
* Question Title
* Question Description (optional)
* Answer + Code (if needed) + Math expressions (if needed) (see the examples below)
* Link(s) to sources (you don't need to write answer by yourself, just combine and research best sources that are available)
* QA Difficulty Level (`entry`, `junior`, `mid`, `senior`, `expert`)
* Look at the `QAS_Examples.md` file in this repo for examples of QAS Markdown file formatting. Please strictly follow these formatting conventions. That's the key to pass the challenge ;)
* Create a [pull request](https://docs.github.com/en/github/collaborating-with-pull-requests/proposing-changes-to-your-work-with-pull-requests/creating-a-pull-request-from-a-fork) from your repo to the MLSC Candidate repo
* Send us email or DM us on UpWork when you happy us to verify it
# How To Choose/Write Good Interview Questions
When choosing a good interview question use several simple tactics:
* The QA should not be too **broad**, like
* 🚫 `What is Machine Learning?`
* The QA should be **opened** and invite the candidate for a conversation rather than strictly test his/her/their specific knowledge. Compare:
* 🚫 `Write down the formula and steps for the Standard algorithm of naive k-means Clustering`
* ✅ `When would you use Clustering vs Classification?`
* Keep answers **short** and **succinct**. If you feel your answer is growing in size and covering different topics - split it!
* Avoid very specific highly practical questions like
* 🚫 `How to install pandas?` - we won't accept that type of questions
* Don't submit questions related to personal candidate experience. That questions are valid for an interview but don't fit to the format of MLSC like
* 🚫 `Have you ever worked with Tensorflow?`
* 🚫 `Describe your experience building ML models on your previous job?`
* Don't submit behavioral questions like:
* 🚫 `Describe your strengths and weakness` and so on
* Use that that types of questions:
* ✅ `When to use X vs Y?`
* ✅ `Why would you use X?`
* ✅ `Compare X vs Y for solving Z`
* ✅ `What types of X do you know?`
* ✅ `Are there any problems when using X for solving Z?`
* ✅ `Name some advantages of using X vs Y for solving Z?`
* ✅ `Explain X to 5 yo/your grandparents`
* ✅ `What is example of Y in real life?`
* ✅ `Provide an intuitive explanation of X`
* The best **rule of thumb** to follow is
* ✅ question yourself would you ask this question to someone on a real ML interview? If answer is Yes - go for it!
# Where To Find ML/DS Interview Questions
Remember, **you don't need to write the interview questions and answer by yourself** unless you are 100% sure your can provide the best most brilliant answer to the question you're asking. Your task is to research the best sources that are available in the Internet (blog posts, books, videos, tutorials), combine and convert that knowledge to answer.
There is just a fraction of quality resources you can do you research on:
* towardsdatascience.com
* en.wikipedia.org
* stats.stackexchange.com
* datascience.stackexchange.com
* www.mathsisfun.com
* ml-cheatsheet.readthedocs.io
* becominghuman.ai
* lionbridge.ai
* machinelearningmastery.com
* scikit-learn.org
* blog.paperspace.com
* blogs.oracle.com
* statisticsbyjim.com
* www.datatechnotes.com
* etc ...
⚠️ **Warning**: Don't use/copy information from the websites with bad grammar and poor QAs quality. We won't accept QAs that will be copied from shady sources. You can recognize these sites by deficient crappy design, tons of ads, lack of formatting and content _with no attribution to the sources_ like:
* onlineinterviewquestions.com
* geekforgeeks.com
* etc ...
💡 **Hint**: Don't blindly copy all answers from one source for the same topic. Try to find at least 2-3 source of the information and choose the best explanation **you like most**.
💡**Hint**: Search Github for Machine Learning interview questions repos that other people did. Usually they already formatted as Markdown and can get you great amount of QAS for the topic
💡**Hint**: When research on some topic look at the `Table of Content` in your favorite ML/DS book to get a sense on what subtopics you can cover. Most of the Coursera and Udemy courses will work too!
# How To Format Interview Questions
All interview questions must be formatted using those rules:
* use only **Markdown** ([Github flavour](https://guides.github.com/features/mastering-markdown/))
* use [Katex](https://katex.org/docs/supported.html) for inclusion of math expressions. **Note**: Github doesn't render Katex syntax in Markdown but VS Code will (with use of some Markdown extensions).
* **Do** include images (include them as links), graphs and math (using Katex) into your answers if they help to explain concepts you cover
* **Do** use and reformat original source of answer using **lists** for better readability
See some examples of QA formatting below. Note how to format **list**, **code**, **file names**, **terms**, **links**, QA **difficulties**, **math expressions** and so on:
---
## Q: Explain how to use _Standard Deviation_ for _Anomalies Detection_?
**Difficulty:** `Junior`
**Source:**
https://towardsdatascience.com/5-ways-to-detect-outliers-that-every-data-scientist-should-know-python-code-70a54335a623
**Details**:
Visualize your answer with example.
**Answer:**
In statistics, if a **data distribution** is approximately **normal** then:
* about `68%` of the data values lie within **one standard deviation** of the mean and
* about `95%` are within **two standard deviations**, and
* about `99.7%` lie within **three standard deviations**:
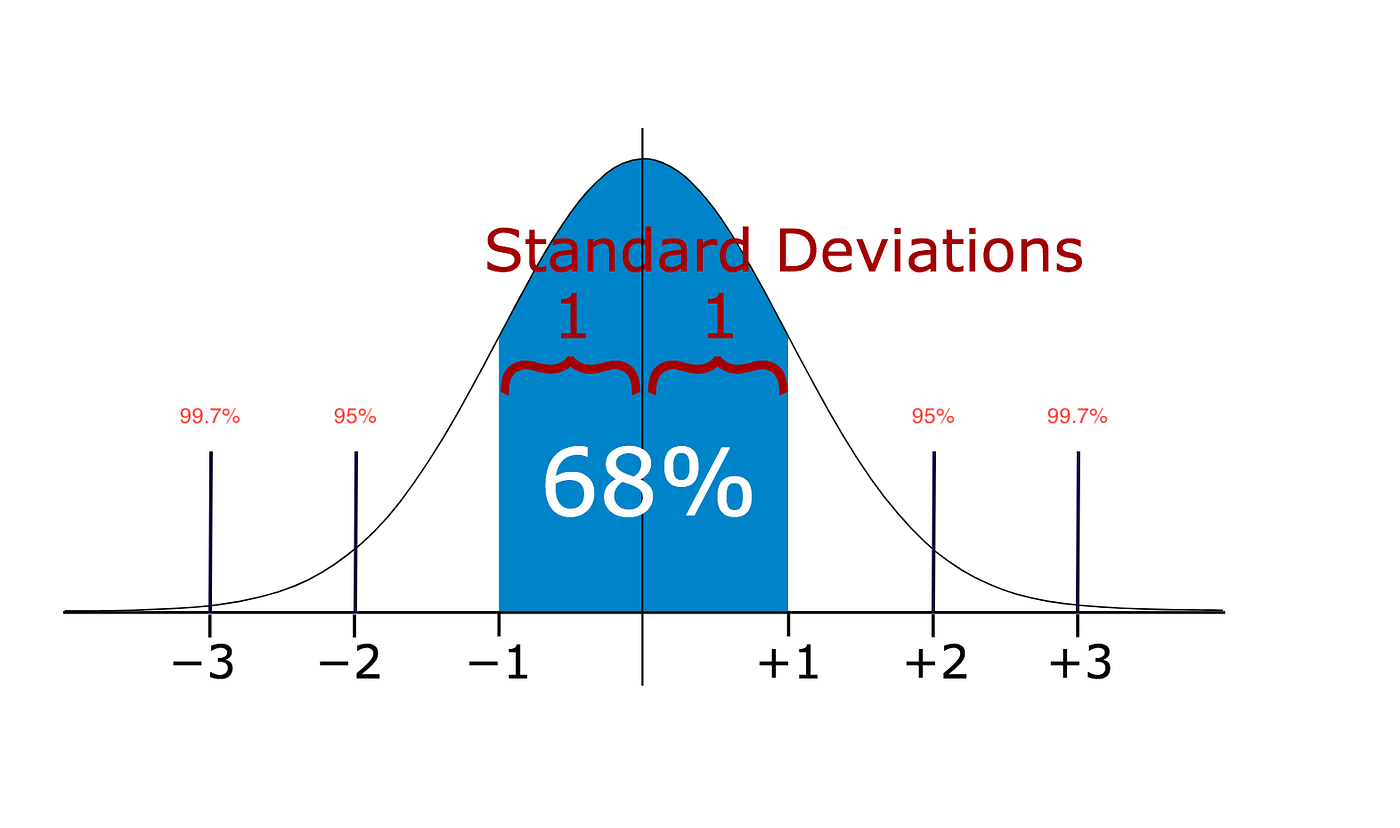
Therefore, if you have any data point that is more than 3 times the standard deviation, then those points are very likely to be **anomalous** or **outliers**.
---
## Q: What is the difference between _Cost Function_ vs _Gradient Descent_?
**Difficulty**: `Junior`
**Source:**
https://towardsdatascience.com/5-ways-to-detect-outliers-that-every-data-scientist-should-know-python-code-70a54335a623
**Answer:**
* A **Cost Function** is _something we want to minimize_. For example, our cost function might be the sum of squared errors over the training set like:
$$J(\theta_0,\theta_1)=\frac{1}{2m}\sum\limits_{i=1}^m (h_{\theta}(x^{(i)})-y^{(i)})^2$$
* **Gradient Descent** is a method for _finding the minimum_ of a function of multiple variables.
# How We Asses Your Work
Look at this list of criteria that we will keep in mind assessing your submission:
* Variety and Quality of Sources you have used - don't copy/source QAs from one source for the test
* Markdown Formatting Quality - don't blindly copy answer, **RE**format it to increase _readability_, for example:
* Use paragraphs and new lines to visually separate different parts of the answer
* Use **bold** for terms and acronyms
* Use **lists** to visually separate different concepts especially if they presented in one long sentence in the source
* Use _italic_ to stress attention on critical/important _idea_ or _concepts_ or _hints_ for a reader
* Use _italic_ in QA Title for terms and acronyms
* Use `code` for numbers: `123`, percentages: `68%`, `file_names.md` and code `