https://github.com/afa-farkhod/huffman-code
Huffman coding, Data compression
https://github.com/afa-farkhod/huffman-code
data-compression huffman-coding java
Last synced: 9 months ago
JSON representation
Huffman coding, Data compression
- Host: GitHub
- URL: https://github.com/afa-farkhod/huffman-code
- Owner: afa-farkhod
- License: mit
- Created: 2023-04-18T01:01:54.000Z (about 3 years ago)
- Default Branch: main
- Last Pushed: 2023-07-01T08:54:54.000Z (almost 3 years ago)
- Last Synced: 2025-08-26T09:02:29.881Z (9 months ago)
- Topics: data-compression, huffman-coding, java
- Language: Java
- Homepage: https://en.wikipedia.org/wiki/Huffman_coding
- Size: 13.7 KB
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# [Huffman-Code](https://en.wikipedia.org/wiki/Huffman_coding)
## Huffman coding & Data compression
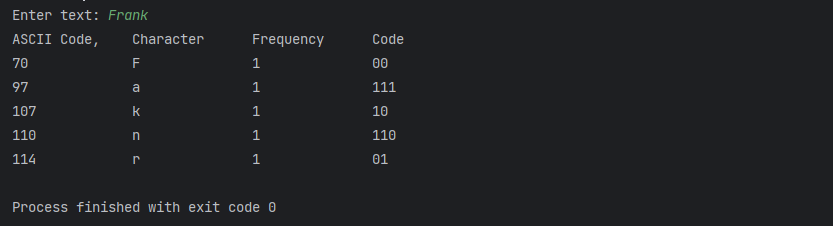
- `Huffman coding` compresses data by using fewer bits to encode characters that occur more frequently. The codes for the characters are constructed based on the occurrence of the characters in the text using a binary tree, called the Huffman coding tree. Compressing data is a common task. There are many utilities available for compressing files.
- Huffman coding invented by David Huffman in 1952. In ASCII, every character is encoded in 8 bits. If a text consists of 100 characters, it will take 800 bits to represent the text. The idea of Huffman coding is to use a fewer bits to encode frequently used characters in the text and more bits to encode less frequently used characters to reduce the overall size of the file.
- In Huffman coding, the characters’ codes are constructed based on the characters’ occurrence in the text using a binary tree, called the Huffman coding tree. Suppose the text is Mississippi. Its Huffman tree can be shown as in the following Figure. The left and right edges of a node are assigned a value 0 and 1, respectively. Each character is a leaf in the tree. The code for the character consists of the edge values in the path from the root to the leaf, as shown in the Figure. Since i and s appear more than M and p in the text, they are assigned shorter codes.

- To construct a Huffman coding tree, we weill use an algorithm as following:
- Begin with a forest of trees. Each tree contains a node for a character. The weight of the node is the frequency of the character in the text.
- Repeat the following action to combine trees until there is only one tree: Choose two trees with the smallest weight and create a new node as their parent. The weight of the new tree is the sum of the weight of the subtrees.
- For each interior node, assign its left edge a value 0 and right edge a value 1. All leaf nodes represent characters in the text.
- Java API implementation demo run: