https://github.com/ahmed-alnassif/net-spider
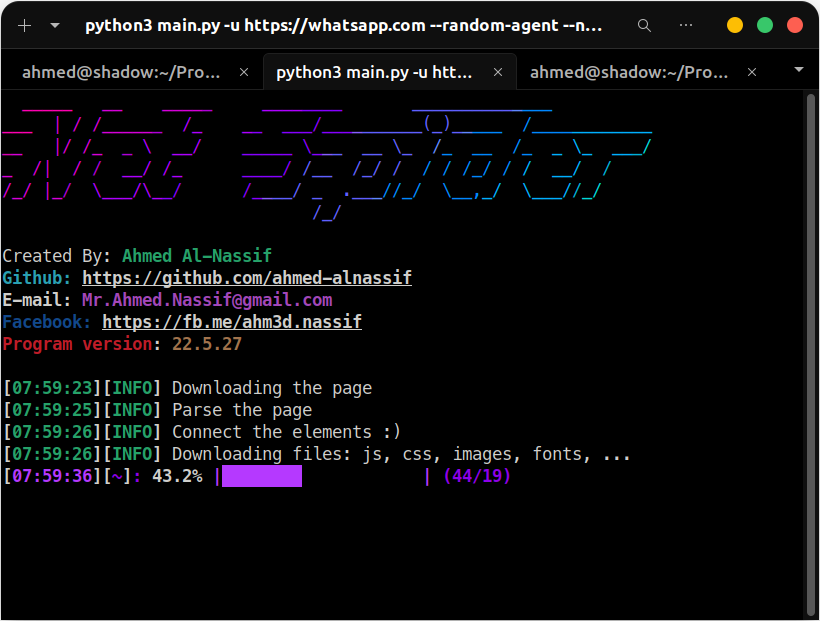
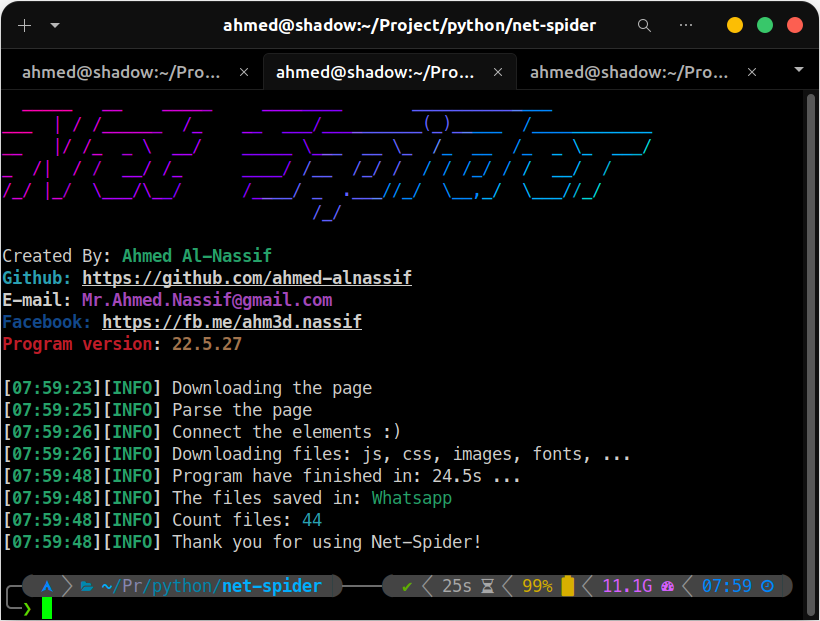
Net-Spider is a web scraping tool designed to retrieve the source code for a web page, including front-end elements such as JavaScript, CSS, images, and fonts. It allows you to crawl and download the source code from a target website.
https://github.com/ahmed-alnassif/net-spider
beautifulsoup4 command-line-interface front-end-web-development python3 source-code-extraction web-automation web-crawling web-development-tool web-optimization web-scraping
Last synced: 5 months ago
JSON representation
Net-Spider is a web scraping tool designed to retrieve the source code for a web page, including front-end elements such as JavaScript, CSS, images, and fonts. It allows you to crawl and download the source code from a target website.
- Host: GitHub
- URL: https://github.com/ahmed-alnassif/net-spider
- Owner: ahmed-alnassif
- License: mit
- Created: 2022-05-27T23:04:08.000Z (over 3 years ago)
- Default Branch: main
- Last Pushed: 2024-06-10T07:38:59.000Z (over 1 year ago)
- Last Synced: 2025-04-14T12:56:51.584Z (7 months ago)
- Topics: beautifulsoup4, command-line-interface, front-end-web-development, python3, source-code-extraction, web-automation, web-crawling, web-development-tool, web-optimization, web-scraping
- Language: Python
- Homepage: https://cyber-wise.blogspot.com/
- Size: 2.65 MB
- Stars: 5
- Watchers: 1
- Forks: 1
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# Net-Spdier
This tool scrapes the source code of an HTML page, including all the content within it, such as external files like JavaScript, CSS, images, fonts, and more. Additionally, it analyzes the CSS files and extracts any external links found within them. The tool is designed to assist developers in understanding the code used by large companies, focusing specifically on front-end development. It only retrieves front-end code and does not handle back-end or server-side code.

# Installation
Packages needed for installation
# Arch Linux:
```bash
sudo pacman -Syu git python python-pip
```
# Fedora:
```bash
sudo dnf update
sudo dnf install git python python-pip
```
# Ubuntu or Debian:
```bash
sudo apt update
sudo apt install git python python-pip -y
```
# Termux (Android):
```bash
apt update
apt install git python -y
```
Installation
```bash
git clone --depth=1 https://github.com/ahmed-alnassif/net-spider.git
```
Installation packages python
```bash
cd net-spider
python -m pip install -r requirements.txt
# OR
python setup.py install
```
Run
```bash
python main.py -u [url]
# Example
python main.py -u https://example.com
```
# Usage
```bash
python main.py --help
```
```
_____ __ _____ ________ ______________
___ | / /______ /_ __ ___/__________(_)_____ /____________
__ |/ /_ _ \ __/ _____ \___ __ \_ /_ __ /_ _ \_ ___/
_ /| / / __/ /_ ____/ /__ /_/ / / / /_/ / / __/ /
/_/ |_/ \___/\__/ /____/ _ .___//_/ \__,_/ \___//_/
/_/
Created By: Ahmed Al-Nassif
Github: https://github.com/ahmed-alnassif
E-mail: Mr.Ahmed.Nassif@gmail.com
Facebook: https://fb.me/ahm3d.nassif
Program version: 24.6.4
usage: python main.py -u [url]
This project designed to retrieve the source code for a web page, including front-end elements such as JavaScript, CSS, images, and fonts.
Net-Spider:
--help Show usage and help parameters
-u Target URL (e.g. http://example.com)
-d, --domain Pull links from the primary website address only
--name NAME The name of the folder in which to save the site files
--hide Hide the progress bar [----]
-v Give more output.
--page RAW Parse an HTML file and retrieve all files from it
--update Automatically update the tool
Requests settings:
--random-agent Random user agent
--mobile make requests as mobile default: PC, Note: this option will active random agent
--cookie Set cookie (e.g {"ID": "1094200543"})
--header Set header (e.g {"User-Agent": "Chrome Browser"})
--proxy PROXY Set proxy (e.g. {"https":"https://10.10.1.10:1080"})
```
# Screenshots