https://github.com/ahmetfurkandemir/artificial-neural-networks-and-cnn
Artificial Neural Networks and CNN
https://github.com/ahmetfurkandemir/artificial-neural-networks-and-cnn
Last synced: 7 months ago
JSON representation
Artificial Neural Networks and CNN
- Host: GitHub
- URL: https://github.com/ahmetfurkandemir/artificial-neural-networks-and-cnn
- Owner: AhmetFurkanDEMIR
- Created: 2020-03-05T19:24:13.000Z (over 5 years ago)
- Default Branch: master
- Last Pushed: 2020-03-05T20:43:13.000Z (over 5 years ago)
- Last Synced: 2025-01-17T08:22:25.444Z (9 months ago)
- Size: 49.8 KB
- Stars: 15
- Watchers: 3
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Artificial Neural Networks and CNN
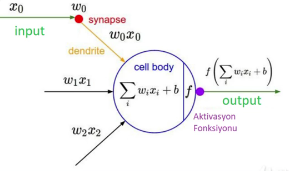
(Nöronun matamatiksel yapısı.)
L = X . W + B
X = input
W = Ağırlık
B = Bias
eğitim sonucu W ve B değerleri değişir.
ve bu L değerini aktivasyon fonksiyonundan geçiririz.
Y = sigmoid(L) şeklinde
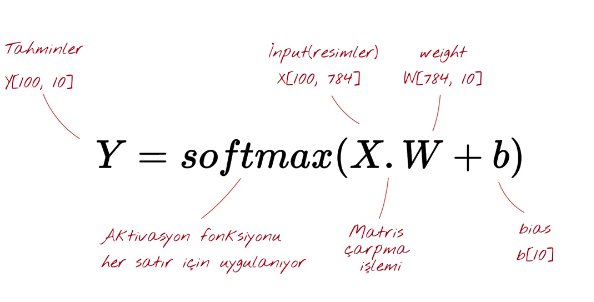
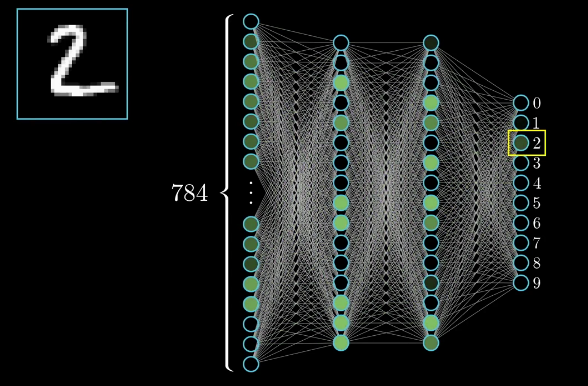
(Resimde 2 rakamının yapay sinir ağlarından geçişi)
# Aktivasyon fonksiyonları

1-) Sigmoid
* Sayıları [0,1] arasında sıkıştırır.
* Gradient ölümlü olabiliyor.
* 0 odaklı değil.
* exp() hesaplaması yapar ve yavaş çalışır.
2-) Tanh
* [-1,1] arasına sıkıştırır.
* Sıfır odaklı.
* Hayla gradient ölümlü olabiliyor.
3-) ReLu
* Negatifse 0, pozitifse olduğu gibi geçer.
* Gradient ölümü yok.
* Bilgisayarın hesaplaması daha kolay.
* Biyolojik nörona daha yakın.
* 0 odaklı değil.
* Bazı nöronlar ölebiliyor.
4-) Leaky Relu
* Relu 'nun getirdiği tüm avantajlar.
* 0 odaklı olduğu için nöron ölümü yok.
5-) Exponential Linear Unit (ELU)
* Leaky relu ile aynı avantaja sahip.
* exp() kullandığı için biraz daha yavaştır.
6-) Maxout
* Relu ve Leaky Relu 'yu genelleştiriyor.
* Nöron ölümü yok.
* Parametre sayısı iki katına çıkar.
# LOSS (Cost) Fonksiyonları
* Tahmin edilen değerin gerçek değerden ne kadar uzak olduğunu hesaplar.
* Eğitim esnasında zamanla sıfıra yaklaşmasını bekleriz.
* y_vals = tf.abs(tagret - x_vals)
* Tahmin ne kadar doğru diye matematiksel işlem yaparız.
# L2 Loss Fonksiyonları
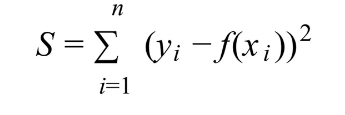
y = doğru olan değer
f(x) = tahmin
Hedeften ne kadar uzaklaşırsa o kadar fazla ceza veririz.
# Cross Entropy Loss Fonksiyonu
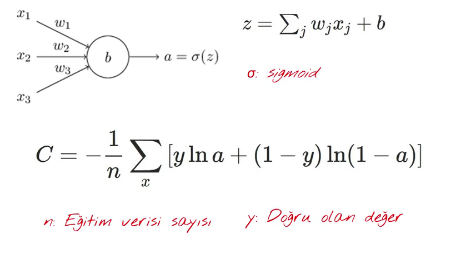
Bilgi teorisinde, iki olasılık dağılımı arasındaki ve aynı temel olaylar kümesinin üzerindeki çapraz entropi, küme için kullanılan bir kodlama şeması tahmini bir olasılık dağılımı için optimize edilmişse kümeden çizilen bir olayı tanımlamak için gereken ortalama bit sayısını ölçer.
# Öğrenme Oranı (Learning Rate)
* Atacağımız adımları sembolize eder.
* Çok küçük bir sayı atanır (örn: 0,0005)
* Büyük olursa minumuma ulaşamaz.
* Küçük olursa model yavaş eğitilir.
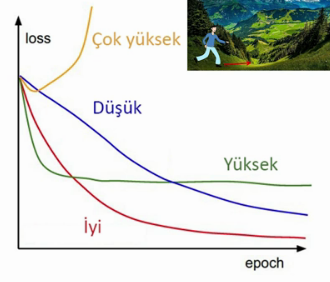
# Gradient Descent
Minumum değere ulaşmak için uygulanan adım.
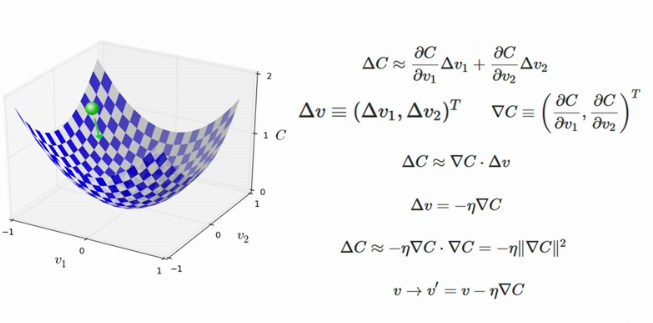
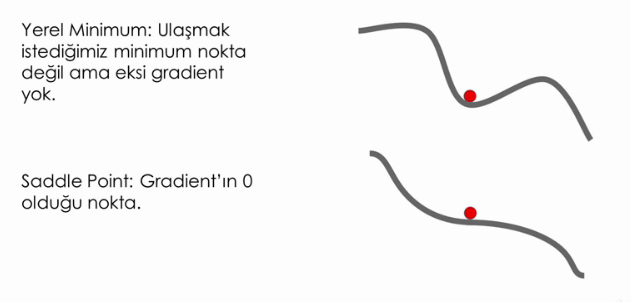
(Karşılaştığımız hatalar)
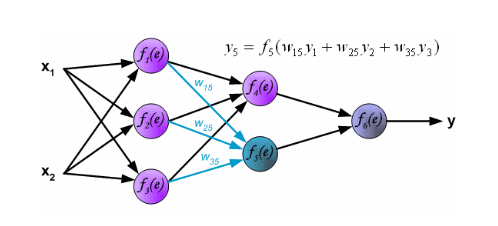
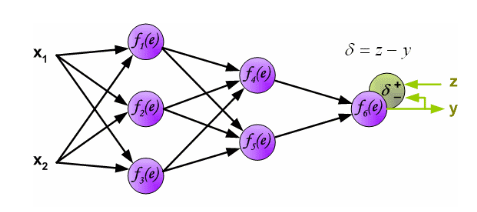
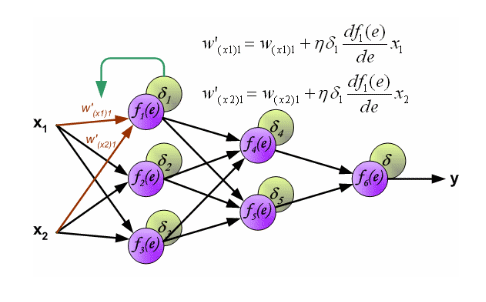
# Back Propagation (Geri Besleme)
* Weight Bias değerlerini günceller.
* Her nöronun hataya ne kadar katkısı olduğunu hesaplamak için kullanırız.
# Overfitting
* Eğitilen modelin eğitim setini çok iyi öğrenip genelleştirme yapamamasına denir
* Underfitting ise tam tersi, modelin veriyi hiç öğrenememesidir.
* Algoritma ezber yapar, daha önce karşılaşmadığı bir veri görünce yanlış sonuçlar verir.
# Regularization
* Daha iyi genelleştirme yapılmasını sağlar
1-) Daha fazla data
Algoritmaya verdiğiniz veri sayısı ve verinin verimliliği size daha iyi sonuçlar verir.
2-) Data Augmentation
Verilerin üzerinde oynamalar yaparak (ters çevirme, büyültme küçültme gibi) yeni veri oluşturulur.
böylece az bir veriyi 2 katına çıkarta biliriz.
3-) Loss fonksiyonuna ekstra fonksiyon ekle
4-) Dropout
Bağzı nöronları sıfırlayarak, eğitimi eşit bir şekilde dağıtırız yani verileri bir kaç nörona odaklamayız.
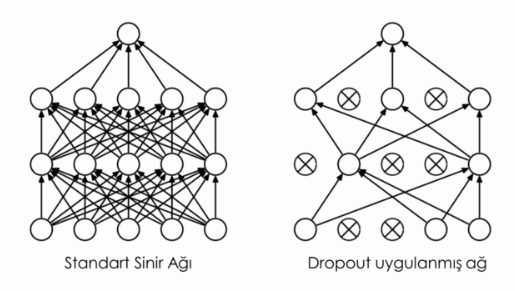
# CNN (Konvolüsyonel Sinir Ağları)
* Resmi düzeltip vektör haline getirmeyiz, yani resmi üç boyutlu kullanırız.
* weight olarak küçük filitreler kullanacağız (örn: 3x3x3 bir filitre)
* Filitre resim üzerinde pixel pixel kayar.
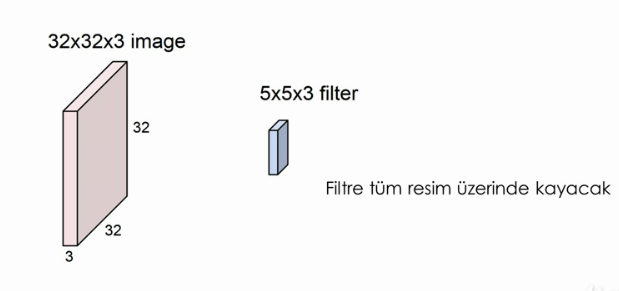
* Output derinliği kaç tane filitre kullandıysak ona eşit olacak.
* ilk layerler basit olur sonraki layerler komplex olur.
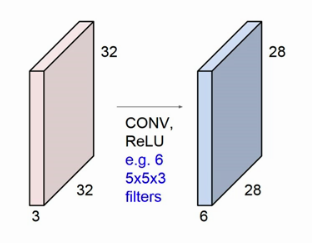
örnek (Konvolüsyonel Layer): 32x32x3 lük bir resmi 6*( 5x5x3 ) bir filitreden geçirirsek yeni oluşacak çıktı 24x24x6 bir resim olur.
* Stride = 2 olarak ayarlarsak filitre 1 pixel olarak kayacağına artık 2 pixel olarak kayar.
bu da çıktının boyutunu değiştirir.
* Boyutun küçülmesine engel olmak için kenar pixellere 0 ekleyerek resmi tekrardan büyütebiliriz.
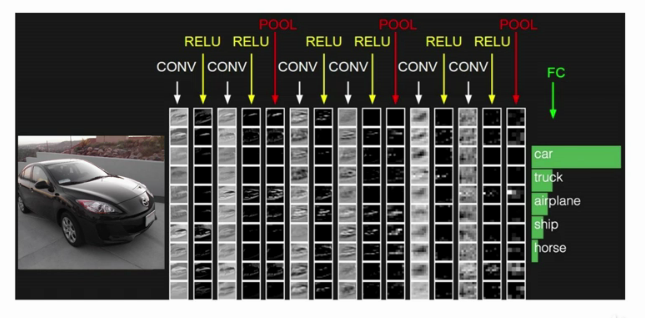
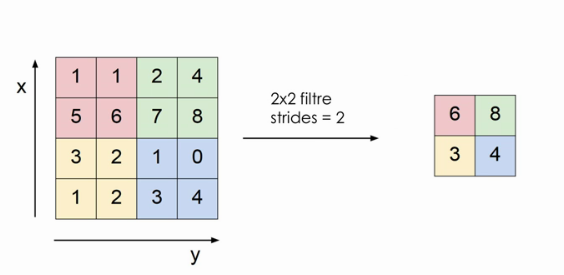
# Poolin layer
* Parametre sayısını azaltmak için max pooling kullanırız.
* Her aktivasyon haritası için ayrı ayrı uygularız (Derinliği etkilemez.)
* Filitrelemedeki en büyük değeri alır.
# ---------------------
Bu öğrendiklerinizi pekiştirmek için:
1-) https://github.com/AhmetFurkanDEMIR/Artificial-Neural-Networks
2-) https://playground.tensorflow.org/
adreslerini ziyaret ediniz.