https://github.com/ahmetfurkandemir/introduction-to-machine-learning
What is machine learning? What is a model and how to build it?
https://github.com/ahmetfurkandemir/introduction-to-machine-learning
Last synced: about 1 month ago
JSON representation
What is machine learning? What is a model and how to build it?
- Host: GitHub
- URL: https://github.com/ahmetfurkandemir/introduction-to-machine-learning
- Owner: AhmetFurkanDEMIR
- Created: 2020-06-19T08:08:02.000Z (over 5 years ago)
- Default Branch: master
- Last Pushed: 2020-06-19T12:54:30.000Z (over 5 years ago)
- Last Synced: 2025-08-09T06:25:37.837Z (about 2 months ago)
- Size: 259 KB
- Stars: 13
- Watchers: 2
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
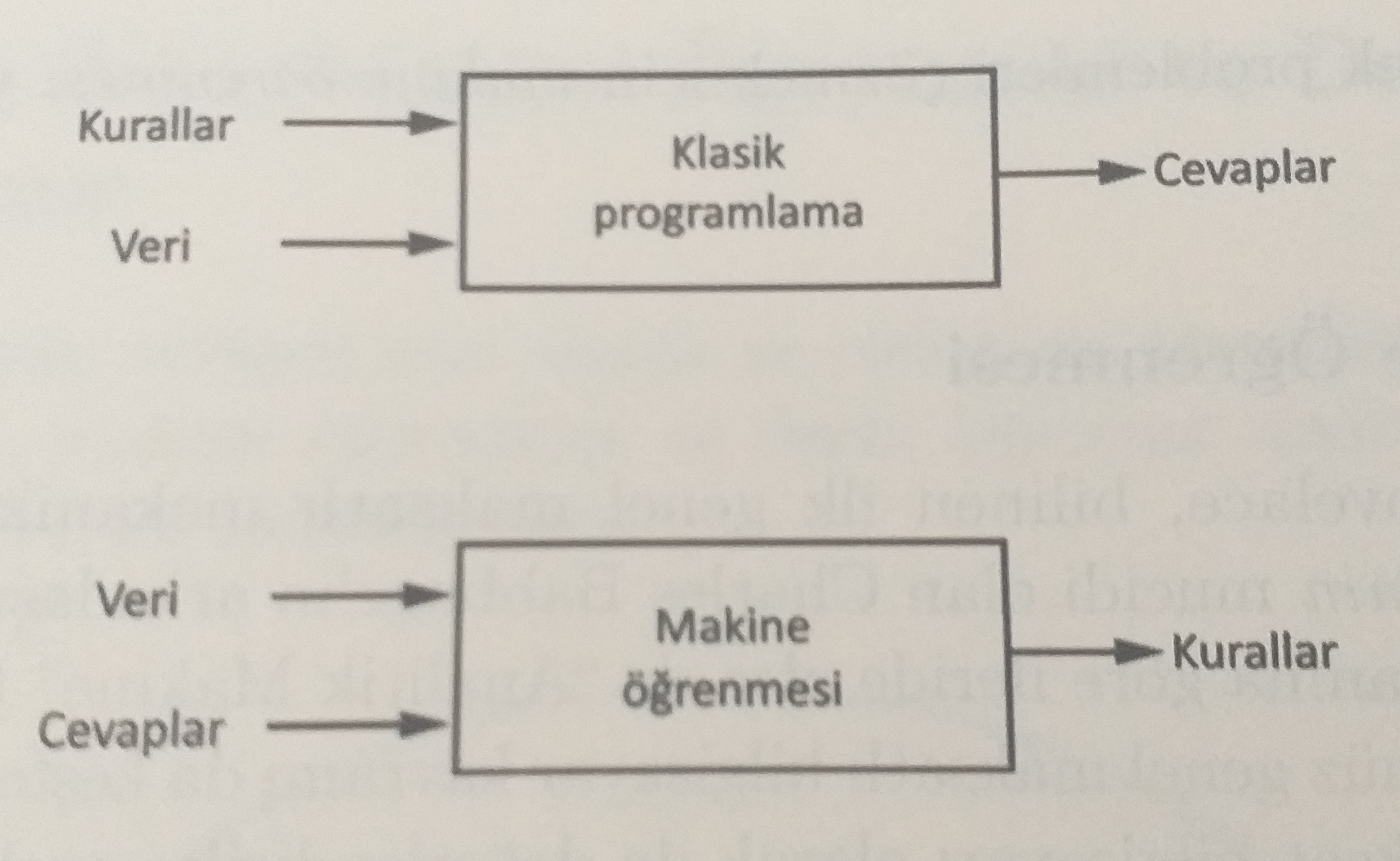
#  Makine Öğrenmesi Nedir ?

Makine öğrenimi, bilgisayarların algılayıcı verisi ya da veritabanları gibi veri türlerine dayalı öğrenimini olanaklı kılan algoritmaların tasarım ve geliştirme süreçlerini konu edinen bir bilim dalıdır. Makine öğrenimi araştırmalarının odaklandığı konu bilgisayarlara karmaşık örüntüleri algılama ve veriye dayalı akılcı kararlar verebilme becerisi kazandırmaktır. Bu, makine öğreniminin istatistik, olasılık kuramı, veri madenciliği, örüntü tanıma, yapay zekâ, uyarlamalı denetim ve kuramsal bilgisayar bilimi gibi alanlarla yakından ilintili olduğunu göstermektedir.
* Uygulamaları : Makine öğreniminin başlıca uygulamaları makine algılaması, bilgisayarlı görme, doğal dil işleme, sözdizimsel örüntü tanıma, arama motorları, tıbbi tanı, biyoinformatik, beyin-makine arayüzleri ve kiminformatik, kredi kartı dolandırıcılığı denetimi, borsa çözümlemesi, DNA dizilerinin sınıflandırılması, konuşma ve elyazısı tanıma, bilgisayarlı görmede nesne tanıma, oyun oynama, yazılım mühendisliği, uyarlamalı web siteleri ve robot gezisidir.
#  Makine Öğrenmesinin Dört Kategorisi
##  Denetimli Öğrenme :
En sık kullanılan kategoridir. Bir veri seti üzerindeki girdilerden bilinen çıktılara olan eşleştirmeyi öğrenmeyi kapsar.
Her ne kadar Denetimli öğrenme temelde sınıflandırma ve bağlanım barındırsa da daha ilginç biçimleride bulunmaktadır.
Bağımlı değişken ve bağımlı değişkeni meydana getiren bağımsız değişkenler bir aradaysa, bu duruma gözetimli öğrenme denir.(Etiket-Veri)
* Dizi oluşturma : Verilen bir resimden başlığını tanımlamak. Dizi oluşturma genellikle arka arkaya sınıflandırma problemi olarak formüle edilmektedir.
* Sözdizimi ağacı tahmini : Verilen bir cümleden sözdizimi ağacını çözümlemek.
* Nesne Tespiti : Verilen bir resimden resim içindeki nesneleri çerçeve içine almak. Bu da aslında sınıflandırma problemi olarak ya da çerçevelerin kordinatlarının vektör bağlanımı ile tahmin edildiği sınıflandırma ve bağlanım problemlerinin birleşimi olarak görülebilir.
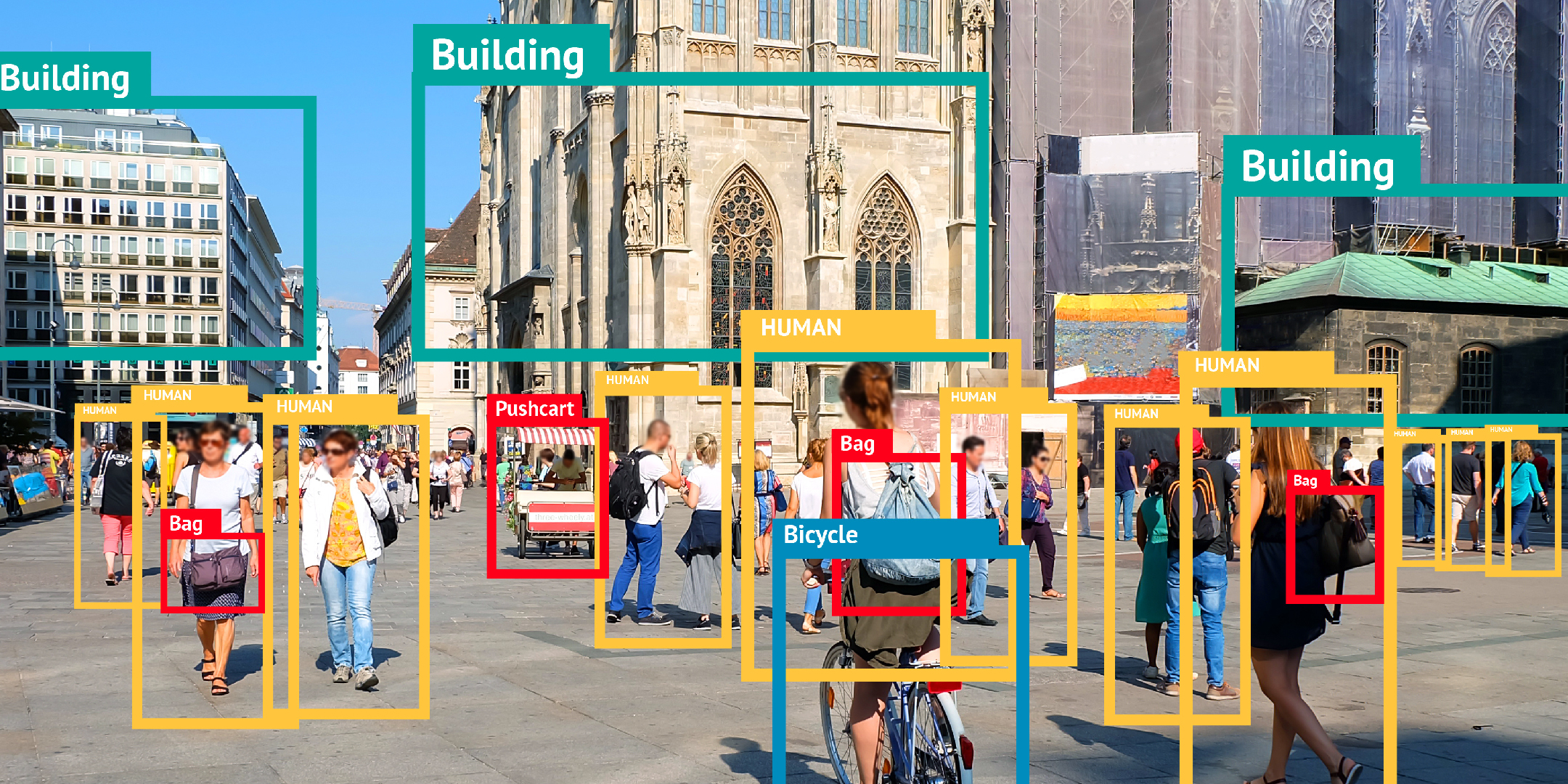
* Resim Bölütleme : Verilen bir resimde nesneye özel görüntü noktası seviyesinde maske oluşturmak.
###  Sınıflandırma (Classification) Yöntemleri
* Destek Vektör Makineleri
* Ayrıştırma Analizi
* Naive Bayes
* En Yakın Komşu
###  Bağlanım (Regression) Yöntemleri
* Lineer bağlanım
* Karar ağaçları
* Yapay sinir ağları
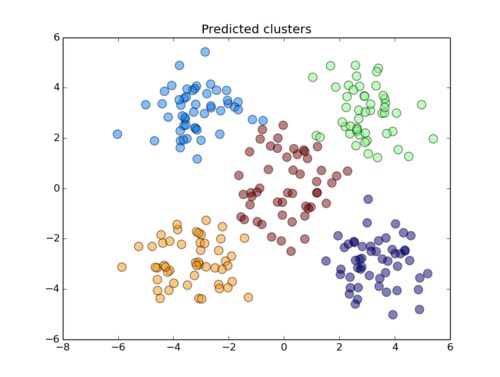
##  Denetimsiz Öğrenme :
Makine öğrenmesinin bu kategorisinin amacı veriyi görselleştirmek, verileri sıkıştırmak, verilerdeki gürültüyü azaltmak ya da eldeki veriler arasındaki korelasyonu anlamak için girdilerden herhangi bir bilinen olmaksızın amaca uygun dönüşümleri bulmaktır.
Bağımlı değişkenin çalışmanının içinde olmadığı öğrenme türüdür.(Veri var, Etiket yok) Birbirlerine benzer özellikler ile bir araya getirilir.
###  Bağlanım (Regression) Yöntemleri
* K - Ortalama, Bulanık, C - Ortalama
* Gauss karışımı
* Saklı markov modeli
* Yapay sinir ağları
##  Yarı Denetimli Öğrenme :
Denetimli öğrenmenin özel bir örneğidir ama kendi özel kategorisini hak etmektedir. Yarı-Denetimli öğrenme, Denetimli öğrenmenin etkili verilerinin olmadığı halidir. Denetimli öğrenmenin insanın olmadığı döngüsü olarak düşünebilirsiniz. Hayla etiketleri vardır ama bunlar girdilerden keşifsel olarak oluşturulur. Örneğin : Otokodlayıcılar(autoencoder) yarı denetimli öğrenmenin çok bilinen bir örneğidir, hedef girdilerden öğrenilmektedir.

##  Pekiştirmeli Öğrenme :
Makine öğrenmesini bu kategorisi uzun süre dikkate alınmamış ancak Google DeepMind tarafından geliştirilen ve ateri oyunları(En son GO oyununda en üst seviye oyuncuları yenebilmiştir.) oynamayı öğrenmesi ile yeniden dikkatleri üzerine çekebilmiştir. Pekiştirmeli öğrenmede bir ajan çerçevesi ile ilgili bir bilgi alır ve ödülünü arttırmak için bir hareket seçer. Örneğin bir sinir ağı, bilgisayar oyununun ekranına bakarak ve skorunu artıracak hareketi seçebilmek için pekiştirmeli öğrenme ile eğitilebilir.

#  Temel Kavramlar
* Bu başlık altında ise Makine Öğrenmesi için gerekli olan temel kavramları göreceğiz.
##  Bağımlı Değişken - Bağımsız Değişken
* Bağımlı Değişken : Makine öğrenmesi probleminde tahmin etmek için hedeflediğimiz ana değişkendir(Etiket).
* Bağımsız Değişken : Bağımlı değişkenlerin belirlenmesinde öncü olur. KM, Hasar durumu, Marka, Model gibi.
##  Regresyon - Sınıflandırma
* Regresyon : Bağımlı değişken, sayısal/sürekli bir değişken ise bu bir regresyon problemidir.(Ev tahmin problemi(Ev fiyati 150000 TL))
* Sınıflandırma Problemi : Bağımlı değişken kategorik bir değiken ise bu bir sınıflandırma problemidir.(Hastanın yaşayıp yaşayamaması(0,1))
##  Değişken Seçimi (Variable Selection)
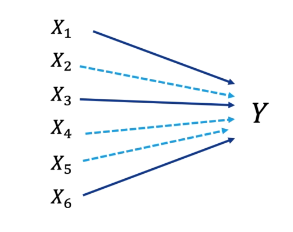
* Amaç : En az değişkenle en fazla açıklanabilirliği yakalamak
##  Makine Öğrenme Modellerinin Değerlendirilmesi (Test-Train)
* Makine öğrenmesinde amaç, modellerin GENELLEŞTİRMESİDİR. Hiç görmediği verilerde başarılı olmalıdır. Önündeki en büyük engel de aşırı uydurmadır.
* Elimzideki veri setinin bir kısmını modeli eğitirken kullanırız diğer kısmını ise eğitilen modeli test ederken kullanırız.

##  Model Seçimi
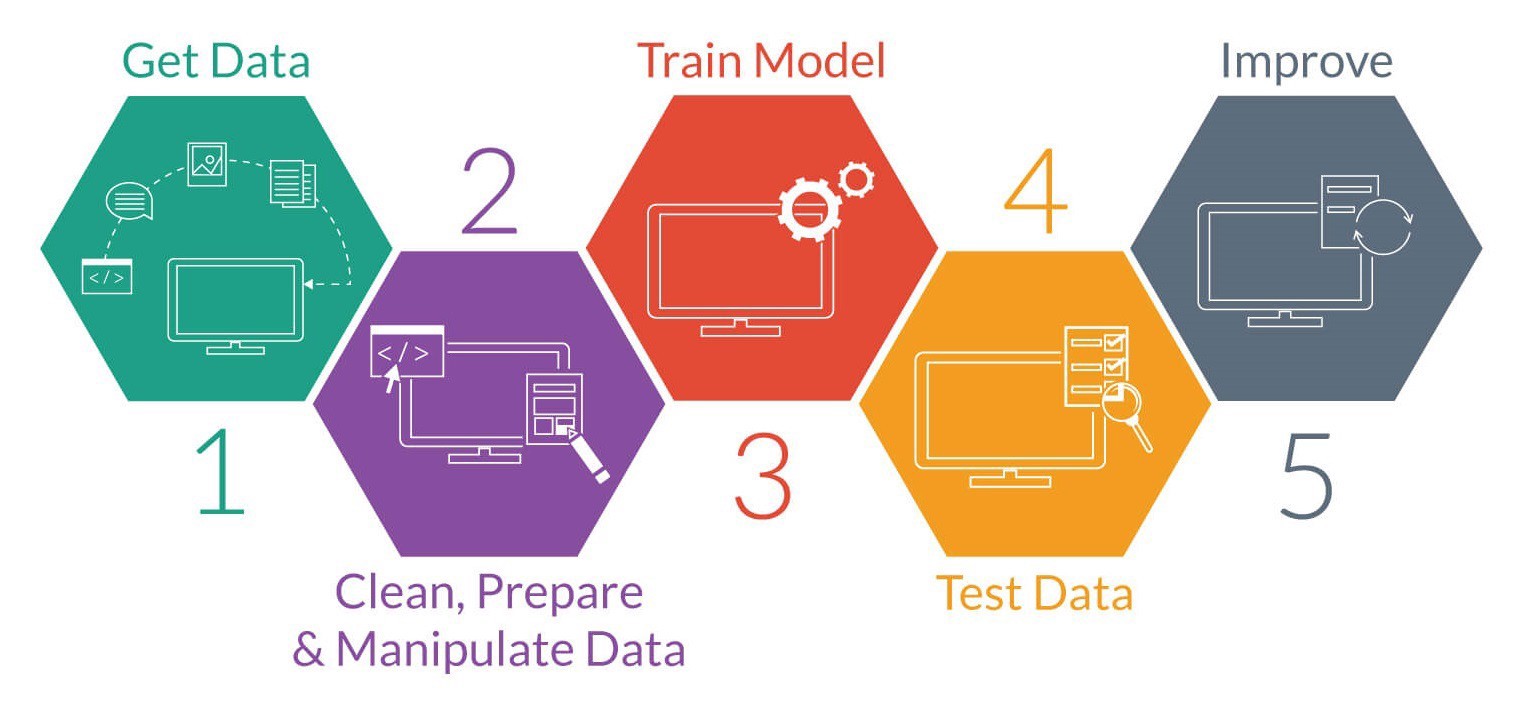
* Oluşabilecek değişken kombinasyonları ile oluşturulan modeller arasından en iyi modelin seçilmesi.
* Model neye göre seçilir ? :
* Regresyon için açıklanabilirlik oran ve RMSE türevi bir değer.
* Sınıflandırma için doğru sınıflandırma oranı türevi bir değer
##  Aşırı Öğrenme (Overfitting)
* Algoritmanın veri setini ezberlemesi, yeni veriler üzerinden tahmin yapılmak istendiğinde modelin başarısız olması.
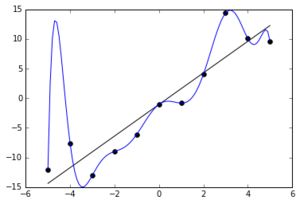
##  Deterministik - Stokastik Modeller
* Deterministik modeller : Değişken arasında kesin bir ilişki olduğu varsayılan modeller.
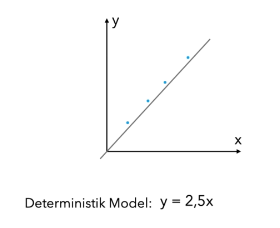
* Stokastik Modeller : Olasılıksal modeller bizim kullanacağımız modeller.
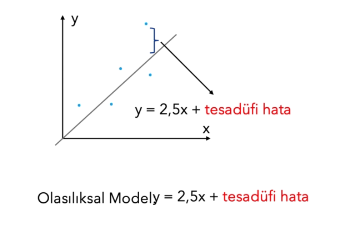
##  Doğrusal Modeller - Doğrusal Olmayan Modeller
* Doğrusal modeller : Doğru ile ifade edilebilmeli.
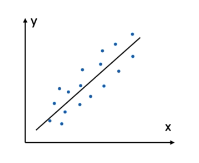
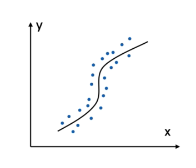
* Doğrusal olmayan modeller : Eğri aracılığıyla, ağaca dayalı yöntemler veya yöntemler ile değişkenler arasındaki ilişkilerin modellenmeye çalışmak.
##  Makine Öğrenmesi - Matematik - İstatistik - Olasılık
* Makine öğrenmesi, matematikten istatistiğe geçiş ve matematik istatistik optimizasyon arasında bir yerde konumlanmaktadır.
* Matematikte kesinlik vardır. İstatistik ve olasılıkta kesinlik yoktur.

#  Model Doğrulama Yöntemleri (Model Validation)
* Modellerin ürettiği sonuçların doğru değerlendirilmesi çalışmaları.
* Model kurmak : Bağımlı değişken ile bağımsız değişkenler arasındaki ilişkiyi modellemek demektir.
##  Yöntemler
###  Holdout Yöntemi (Sınama Testi)

* Belli bir orana göre veri seti parçalanır. Bir kısmı eğitimde kullanılır bir kısmı testte kullanılır.
###  K - Katlı Çapraz Doğrulama (K Fold Cross Validation)
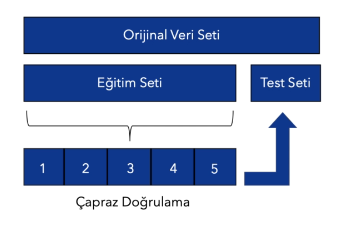
* Veri seti K adet parçaya ayrılır, belirlenen alt kümelerden birisi dışarıda bıraklır. Diğer kümeler eğitim verisi olur ve seçilen küme test verisi olur. Aynı işlem diğer kümeler içinde tekrar eder, bu işlem sonucunda elde edilen hataların ortlaması alındığında bu doğrulama hatası olur.
En son ayrılan test verisiyle test ederiz.
###  Leave One Out

* Eğitim seti n kadar alt kümeye ayrılır ve bu kümelerden biri haricinde diğer tüm kümeler eğitim için kullanılır. Seçilen küme test için kullanılır, bu şekilde seçilen küme değiştirilerek devam eder.
En sonayrılan test veri setiyle model test edilir.
* Veri seti boyutu büyüdükçe bu doğrulamanın gerçekleşmesi imkansızlaşır.
###  Bootstrap

* Yeniden örnek oluşturacak şekilde çalışır, orjinal veri seti içersinden seçilen örneklerle bootstrap örnekler oluşturulur.
x kadar bootstrap veri ile model kurulur ve test edilir. Yerine koymalı bir şekilde veri seti içerisinden veri türetmek şeklinde kullanılır.
#  Model Başarı Değerlendirme Yöntemleri
* Modelin tahmin başarısının değerlendirilmesi. Ortalama hata hesaplamaya çalışılır.
##  Regresyon Modelleri İçin Başarı Değerlendirme
###  MSE (Hata Kareleri Ortalaması)
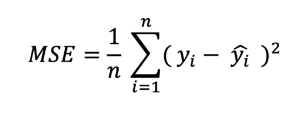
* n = Gözlem sayısı
* yi = Gerçek değerler (Etiket)
* y' = Tahmin edilen değerler
* Bir ev fiyatlandırma problemi düşünelim, model evi 150000 tl olarak tahmin etti ama evin gerçek değeri 151000 tl.
((151000 - 150000)² / örnek sayısı) olarak düşünebiliriz.
###  RMSE (Hata Kareleri Ortalaması Karekökü)
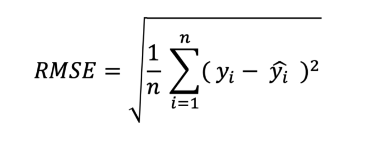
* n = Gözlem sayısı
* yi = Gerçek değerler (Etiket)
* y' = Tahmin edilen değerler
* MSE 'nin karekökü alınmış hali
* Bir ev fiyatlandırma problemi düşünelim, model evi 150000 tl olarak tahmin etti ama evin gerçek değeri 151000 tl.
√((151000 - 150000)² / örnek sayısı) olarak düşünebiliriz.
###  MAE (Ortalama Mutlak Hata)
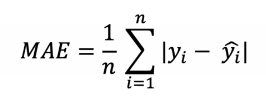
* n = Gözlem sayısı
* yi = Gerçek değerler (Etiket)
* y' = Tahmin edilen değerler
* Bir ev fiyatlandırma problemi düşünelim, model evi 150000 tl olarak tahmin etti ama evin gerçek değeri 151000 tl.
(|151000 - 150000| / örnek sayısı) olarak düşünebiliriz.
##  Sınıflandırma Modelleri İçin Başarı Değerlendirme

* a : True Pozitif (TP)
* d : True Negatif (TN)
* c : False Pozitif (FP)
* b : False Negatif (FN)
* Modeldeki doğruluk için : (TP + TN) / Hepsi
* Modeldeki hata oranı için : (FN + FP) / Hepsi
* Modeldeki kesinlik için : TP / (TP + FP)
* Modeldeki anma için : TP / (TP + FN)
###  ROC Eğrisi
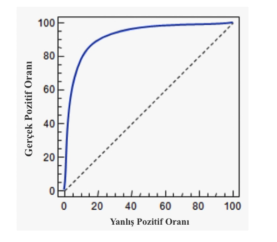
* AUC (Area Under Curuve - Eğri Altındaki Alan) : Bu alan büyük olursa model başarılı olmuş demektir. Alan küçük ise model başarısız olmuş demektir.
* Ortadaki kesikli çizgi hiç bir modeli kullanmasaydık elde edeceğimiz başarı oranı.
#  Yalınlık - Varyans Değiş Tokuşu (Bias - Variance Tradeoff)
* Modelin tahmin başarısının değerlendirilmesi
* Eğitim hatası -> modeli kurmak için kullandığımız veri seti üzerinden elde ettiğimiz hata.
* Test hatası -> kurulan modeli test etmek için kullandığımız veri seti için oluşan hatadır.
##  Esneklik
* Verinin fonksiyonel yapısının uygun bir şekilde yorumlanmasıdır. Ortalama test hatasına göre belirlenir.
##  Yanlılık
* Gerçek değerler ile tahmin edilen değerler arasındaki fark.
##  Varyans
* Değişkenlik demektir, modelin esnekliğidir. Oldukça detaylı öğrenmek demektir.
##  Underfitting - Doğru Model - Overfitting
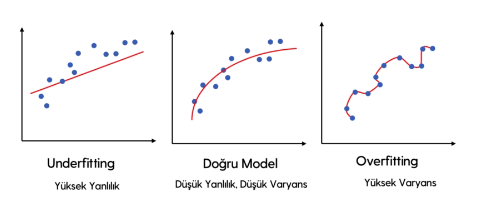
* İlk grafikte Underfitting yani yüksek yanlılık var. (Fark çok, Eksik öğrenme var)
* İkinci grafikte doğru bir model kurulmuştur. Düşük yanlılık ve düşük varyans var.
* Üçüncü grafikte ise Overfitting yani yüksek varyans vardır. Fonksiyon verisetini çok iyi öğrenmiştir, ezber yapmıştır.
#  Eğitim Hatası İle Test Hatasının Karşılaştırılması
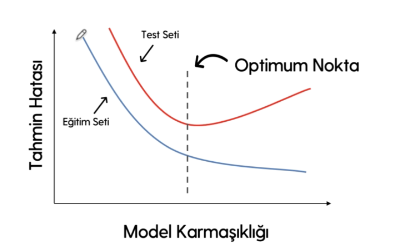
* Bir model üretirken, yeni değişken üretmek, hiper parametreleri optimizie etmek gibi modelin tahmin başarısını artıracak işlemler yaparız. Bu işlemlerin artmasıyla eğitim seti hatamız düşer, model daha karmaşıklaşır.
* Model karmaşıklığı artıkça, eğitim setimizdeki hata düştükçe, başarımız artıkça bir noktadan sonra test setindeki hata artmaya başlar, test setine negatif olarak yansır, model veri setini ezberlemeye çalışır.
#  Model Tunning (Model Optimizasyonu)
* Parametre, Hiperparametre, Parametre tuning, Model tuning.
* Modelin tahmin performansını artırmak.
* Bütüncül bir kavramdır.
##  Model Parametreleri
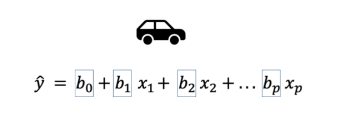
* Veriden Öğrenilen Parametreler(Ağırlıklar)
* Burada b harfleri parametrelerimiz, x harfleri ise verilerimizdir, verilerimizin yönü eksi(-) olabilir. Mesela aracın kaza durumu fiyatın düşmesine sebep olur.
##  Model Hiperparametreleri
* Kullanıcı tarafından belirlenen ve veriler ile optimize edilen parametrelerdir. Verinin içinden elde edemeyeceğimiz parametreler, yani dışsal kullanıcı tarafından belirlenir.
#  Kaynaklar
* https://www.udemy.com/course/python-ile-makine-ogrenmesi/
* https://www.amazon.com/Deep-Learning-Python-Francois-Chollet/dp/1617294438
* https://tr.wikipedia.org/wiki/Makine_%C3%B6%C4%9Frenimi