https://github.com/ahmz1833/ai-project
AI Course Project 14032 - Dr. TanGhatari
https://github.com/ahmz1833/ai-project
attention-mechanism pytorch q-learning reinforcement-learning sac skip-connections softmax unet-image-segmentation
Last synced: about 1 month ago
JSON representation
AI Course Project 14032 - Dr. TanGhatari
- Host: GitHub
- URL: https://github.com/ahmz1833/ai-project
- Owner: ahmz1833
- Created: 2025-09-13T20:04:26.000Z (10 months ago)
- Default Branch: master
- Last Pushed: 2025-09-14T06:52:29.000Z (10 months ago)
- Last Synced: 2025-09-14T08:29:37.648Z (10 months ago)
- Topics: attention-mechanism, pytorch, q-learning, reinforcement-learning, sac, skip-connections, softmax, unet-image-segmentation
- Homepage:
- Size: 3.78 MB
- Stars: 0
- Watchers: 0
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# پروژه درس هوش مصنوعی
این مخزن برای پروژه درس هوش مصنوعی ساخته شده است که شامل دو زیر مخزن فاز یک (سگمنتکردن تصاویر هوایی و ساخت Mask جادهها) و فاز دو (یادگیری تقویتی با الگوریتم Soft Actor Critic و راهرفتن یک سگ) میباشد.
## اطلاعات پروژه
### اعضای گروه
- [امیرمهدی طهماسبی](https://github.com/ta-tahmasebi) (۴۰۲۱۰۶۱۷۸)
- [امیرحسین محمدزاده](https://github.com/ahmz1833) (۴۰۲۱۰۶۴۳۴)
- [محمدنوید آتشینبار](https://github.com/NavidATB) (۴۰۲۱۰۵۵۸۱)
### ترم تحصیلی و مدرس
این پروژه برای ترم تحصیلی بهار ۱۴۰۴ (۱۴۰۳۲) و در تابستان ۱۴۰۴ انجام شده است.
#### **مدرس: دکتر تنقطاری**
## فاز اول پروژه
### هدف
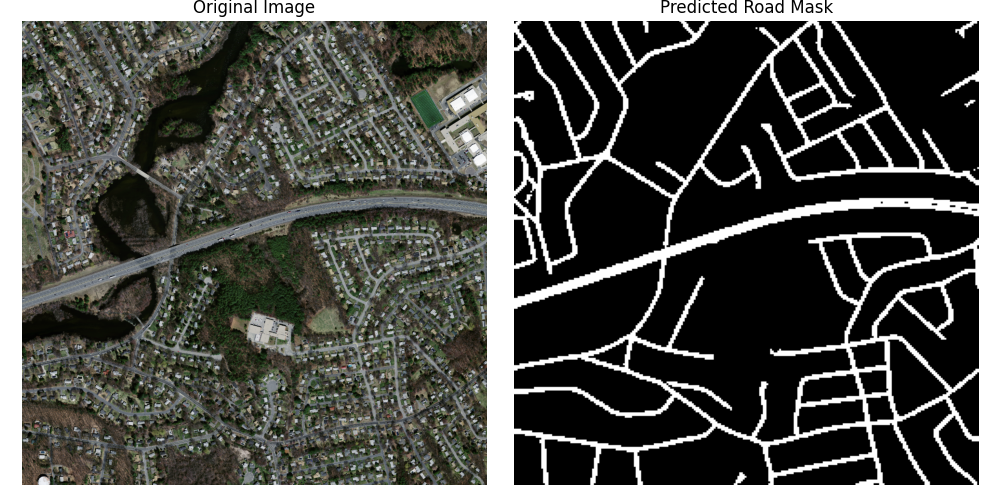
در این فاز، هدف بخشبندی معنایی (Semantic Segmentation) تصاویر هوایی برای استخراج ماسک دقیق جادهها بود. این کار یکی از مسائل اساسی در زمینه پردازش تصاویر ماهوارهای و سیستمهای نقشهبرداری خودکار است. برای این منظور، از معماری قدرتمند **UNet** استفاده کردیم.
| نمونه خروجیهای مدل | |
| :---: | :---: |
| 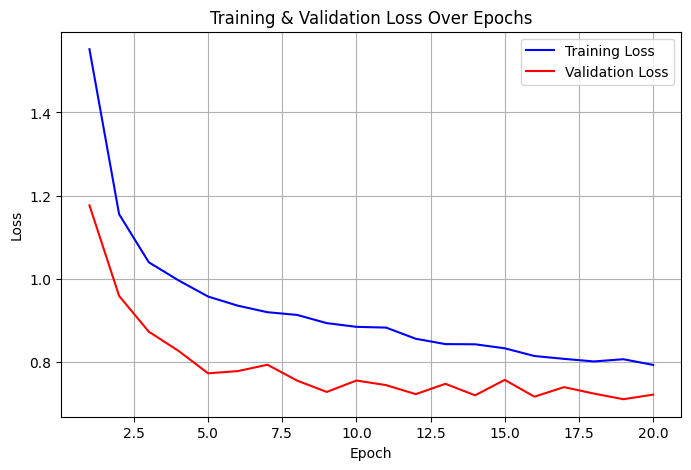 |
| 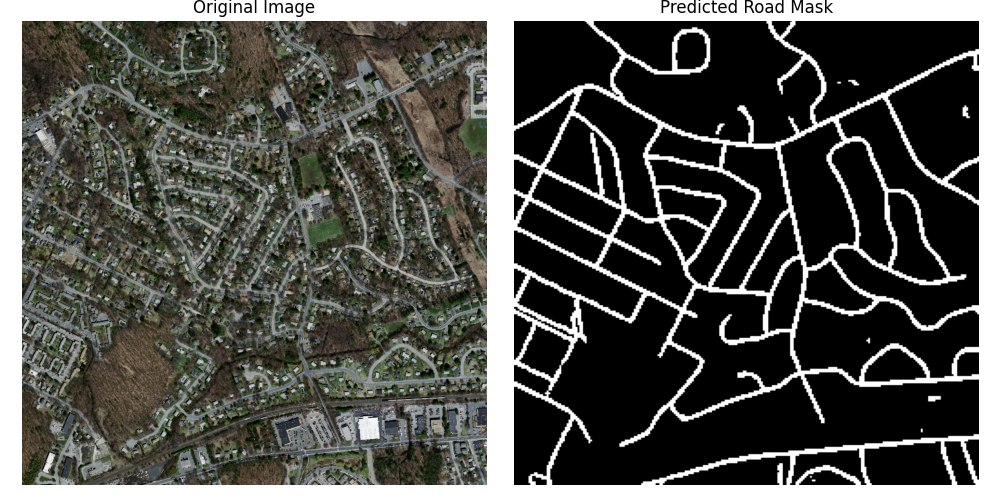 |
|
|  |
| 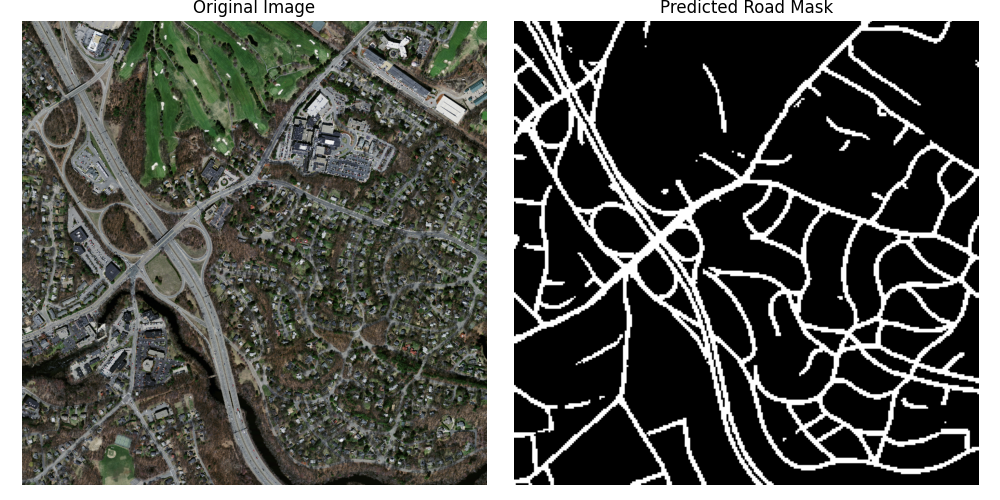 |
|
| 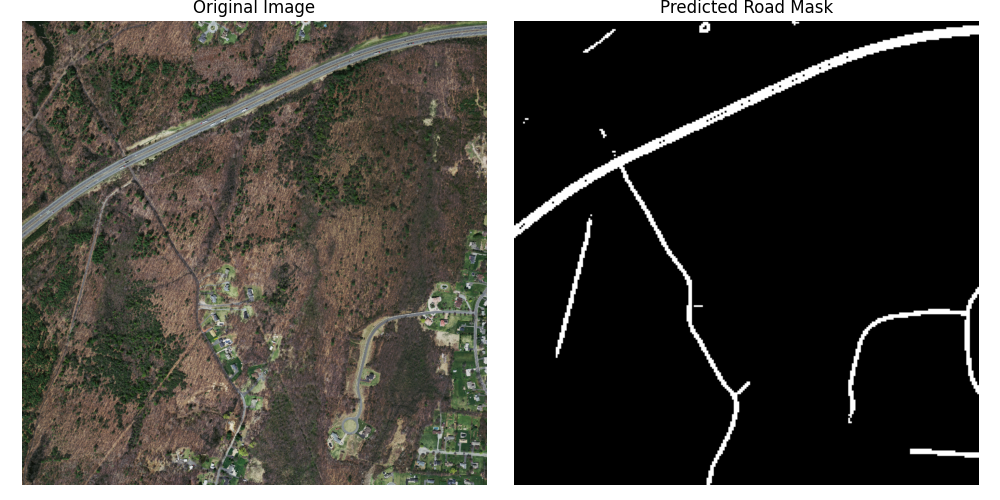 |
|  |
|
### رویکرد
سه نسخه مختلف از این معماری پیادهسازی و نتایج آنها با یکدیگر مقایسه شد:
-
UNet معمولی (Vanilla UNet): پیادهسازی پایهی معماری UNet.
-
Attention UNet: افزودن مکانیزم توجه (Attention Gates) برای تمرکز شبکه روی نواحی مهمتر تصویر.
-
Residual UNet: در این نسخه، بلوکهای کانولوشنی استاندارد با بلوکهای باقیمانده (Residual Blocks) جایگزین شدند؛ که شامل Skip Connection هستند. این کار به بهبود جریان گرادیان در طول شبکه کمک کرده و امکان آموزش مدلهای عمیقتر بدون مشکل محو شدگی گرادیان (Vanishing Gradient) را فراهم میکند.
### ویدئوی ارائه
در ویدیوی زیر، توضیحات کلی معماری UNet، تابع زیان استفاده شده، کاربردهای دیگر آن و نقش Skip-Connection ها به طور کامل توضیح داده شده و کد پروژه مرور میشود:
[لینک به گوگل درایو](https://drive.google.com/drive/folders/1O-__YnY3zfOrR-QeRyhTsEkUzPzxL8RA?usp=sharing)
## فاز دوم پروژه
### هدف
فاز دوم پروژه به یادگیری تقویتی (Reinforcement Learning) اختصاص دارد. در این فاز، الگوریتم **Soft Actor-Critic (SAC)** برای آموزش راه رفتن به یک ایجنت **HalfCheetah** در محیط شبیهسازی شده `Gymnasium` با موتور فیزیک `MuJoCo` به کار گرفته شد.
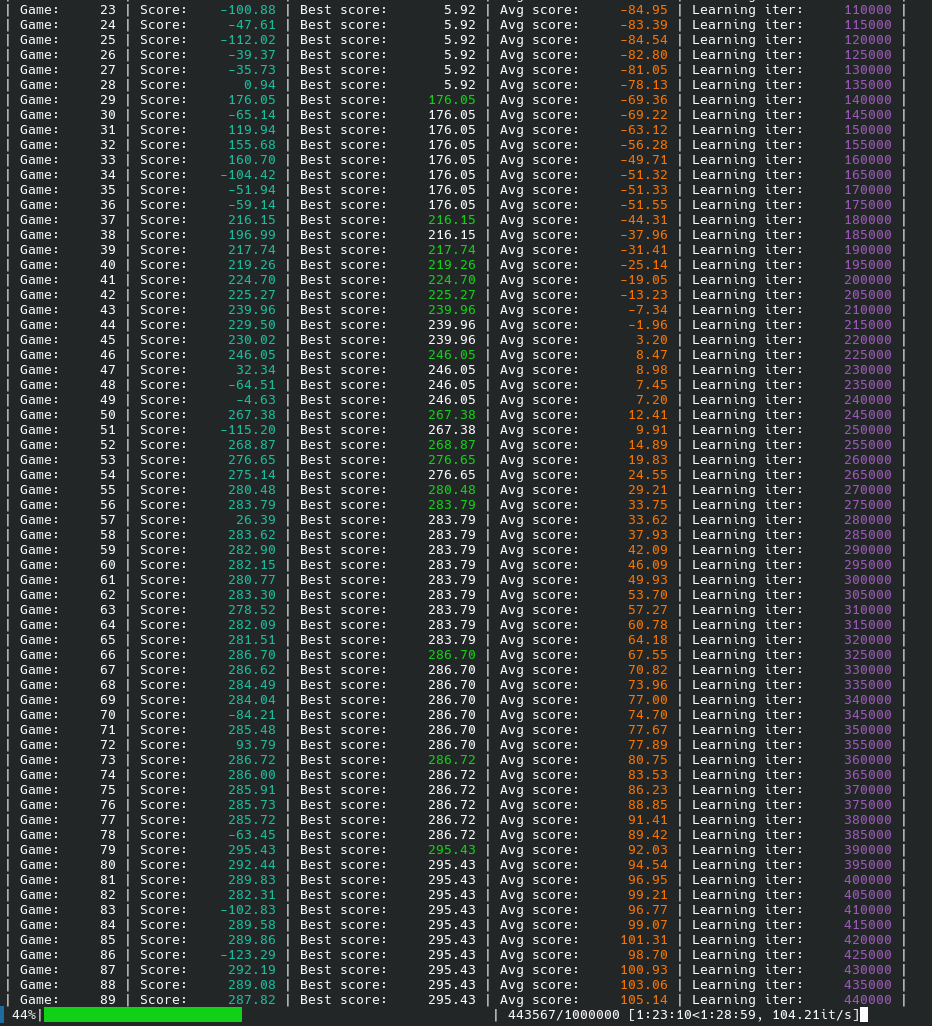
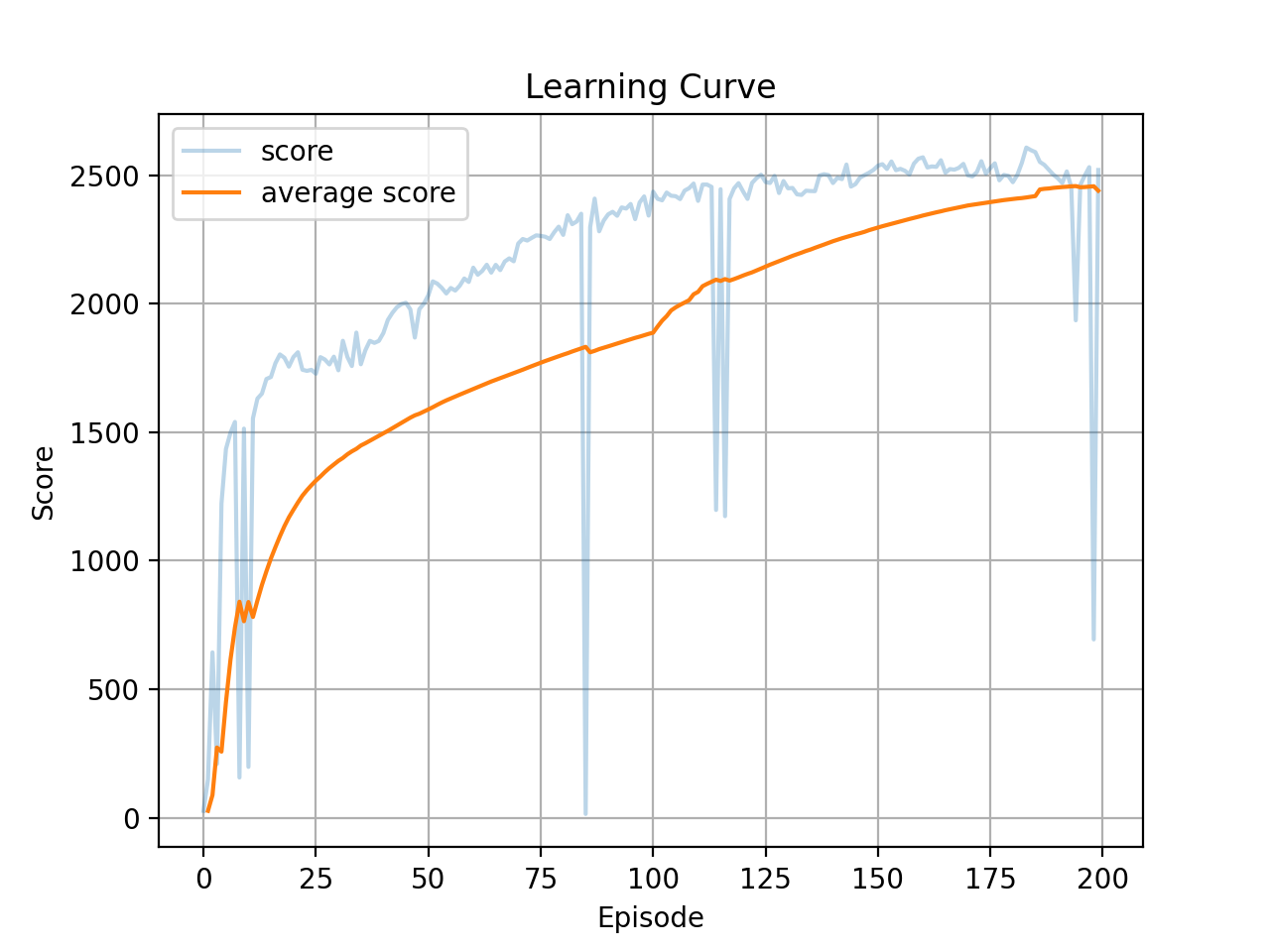
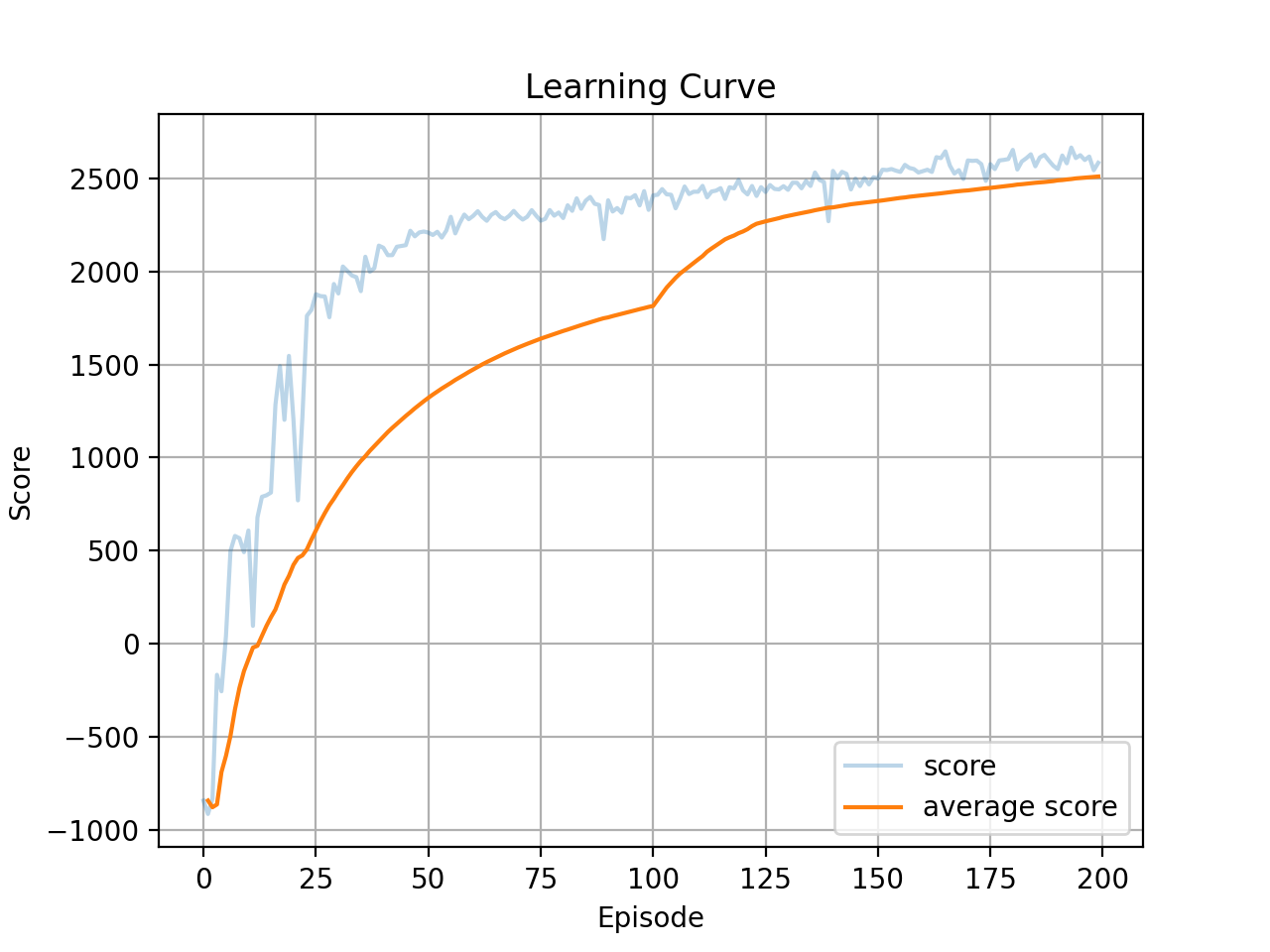
### رویکرد
الگوریتم SAC به عنوان یک الگوریتم **Off-Policy** و مبتنی بر **Maximum Entropy**، برای وظایف کنترلی با فضای عمل پیوسته (Continuous Action Space) بسیار مناسب است. هدف ایجنت، یادگیری سیاستی (Policy) است که هم پاداش تجمعی را ماکزیمم کند و هم انتروپی (تصادفی بودن) رفتار خود را، که منجر به کاوش بهتر و پایداری بیشتر میشود.
**معماری شبکهها:**
-
Actor (Policy Network): یک شبکه عصبی پیشخور (MLP) که وضعیت (State) را به عنوان ورودی دریافت کرده و پارامترهای یک توزیع گوسی (میانگین و انحراف معیار) را برای فضای عمل خروجی میدهد.
-
Critic (Q-Networks): از تکنیک Clipped Double Q-Learning با دو شبکه Q مجزا برای کاهش بیشتخمینی (Overestimation) مقادیر Q استفاده شد. هر دو شبکه نیز MLP هستند.
**فرآیند آموزش:**
-
Replay Buffer: تجربیات ایجنت در یک حافظه ذخیره شده و در هر مرحله از آموزش، یک بچ (Batch) تصادفی از آن برای بهروزرسانی شبکهها نمونهگیری میشود.
-
بهروزرسانی پارامترها: شبکههای Actor، Critic و پارامتر دمای انتروپی (α) به صورت متناوب با استفاده از بهینهساز Adam آپدیت میشوند.
### ویدئوی ارائه
در این ویدیو، الگوریتم SAC، نقش انتروپی در تابع هدف، مفهوم اپراتور بلمن soft و جزئیات پیادهسازی پالیسی و توابع Q به طور کامل شرح داده شده است.
[لینک به گوگل درایو](https://drive.google.com/drive/folders/1YTZiOaZV2pDgBDafB7sCj0g5Lixa63-a?usp=sharing)